HashMap面试问题整理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap面试问题整理相关的知识,希望对你有一定的参考价值。
参考技术A 拉链法
创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
头插
尾插
在 transfer() 方法中,因为新的 Table 顺序和旧的不同,所以在多线程同时扩容情况下,会导致第二个扩容的线程next混乱,本来是 A -> B ,但t1线程已经 B -> A 了,所以就 成环 了。
1.8扔掉了 transfer() 方法,用 resize() 扩容:
使用 do while 循环一次将一个链表上的所有元素加到链表上,然后再放到新的 Table 上对应的索引位置。
JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)
1.8的索引 只用了一次移位,一次位运算就确定了索引,计算过程优化。
二者的 hash 扰动函数也不同,1.7有4次移位和5次位运算,1.8只有一次移位和一次位运算
初始容量和加载因子会影响 HashMap 的性能:
常说的capacity指的是 DEFAULT_INITIAL_CAPACITY (初始容量),值是 1<<4 ,即16;
capacity() 是个方法,返回数组的长度。
在hashMap构造函数中,赋值为 DEFAULT_LOAD_FACTOR(0.75f)
加载因子可设为>1,即永不会扩容,(牺牲性能节省内存)
Map中现在有的键值对数量,每 put 一个entry, ++size
数组扩容阈值。
即:HashMap数组总容量 * 加载因子(16 * 0.75 = 12)。当前 size 大于或等于该值时会执行扩容 resize() 。扩容的容量为当前 HashMap 总容量的两倍。比如,当前 HashMap 的总容量为 16 ,那么扩容之后为 32
获取哈希码, object 的 hashCode() 方法是个本地方法,是由C实现的。
理论上hashCode是一个int值,这个int值范围在-2147483648和2147483648之间,如果直接拿这个hashCode作为HashMap中数组的下标来访问的话,正常情况下是不会出现hash碰撞的。
但是这样的话会导致这个HashMap的数组长度比较长,长度大概为40亿,内存肯定是放不下的,所以这个时候需要把这个hashCode对数组长度取余,用得到的余数来访问数组下标。
高低位异或,避免高位不同,低位相同的两个 hashCode 值 产生碰撞。
为什么 重写 equals 时必须重写 hashCode 方法?
equals()既然已能对比的功能了,为什么还要hashCode()呢? 因为重写的equals()里一般比较的比较全面比较复杂,这样效率就比较低,而利用hashCode()进行对比,则只要生成一个hash值进行比较就可以了,效率很高。
hashCode()既然效率这么高为什么还要equals()呢? 因为hashCode()并不是完全可靠,有时候不同的对象他们生成的hashcode也会一样(生成hash值得公式可能存在的问题),所以hashCode()只能说是大部分时候可靠,并不是绝对可靠,
A:两个时候
Node[] table,即哈希桶数组,哈希桶数组table的长度length大小必须为2的n次方
0.75 * 2^n 得到的都是整数。
把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中
hashCode是很长的一串数字,<font color = orange>(换成二进制,此元素的位置就是后四位组成的 ( 数组的长度为16,即4位 ))</font>
eg.
<font color = gray>1111 1111 1111 1111 0000 1111 0001</font> 1111 (原索引是后面四个,索引是15)
扩容后:
<font color = gray>1111 1111 1111 1111 0000 1111 000</font> 1 1111 (新的索引多了一位)(多出来这个,或1或0 随机,完全看hash)
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于 新增的1bit是0还是1可以认为是随机的 (hashCode里被作为索引的数往前走了一个,走的这个可能是0,也可能是1),因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
用Iterator有两种方式,分别把迭代器放到entry和keyset上,第一种更推荐,因为不需要再 get(key)
可减少哈希碰撞
可以,null的索引被设置为0,也就是Table[0]位置
在JDK7中,调用了 putForNullKey() 方法,处理空值
JDK8中,则修改了hash函数,在hash函数中直接把 key==null 的元素hash值设为0,
再通过计算索引的步骤
得到索引为0;
对key的hashCode()做hash运算,计算index; 如果在bucket里的第一个节点里直接命中,则直接返回; 如果有冲突,则通过key.equals(k)去查找对应的Entry;
调用 putValue :
是以31为权,每一位为字符的ASCII值进行运算,用int的自然溢出来等效取模。
假设String是ABC,
可以使用ConcurrentHashmap,Hashtable等线程安全等集合类。
Divenier总结:
要看作为key的元素的类如何实现的,如果修改的部分导致其 hashcode 变化,则修改后不能 get() 到;
如修改部分对 hashcode 无影响,则可以修改。
开放定址法、链地址法(拉链法)、再Hash法
部分参考资料:
https://tech.meituan.com/2016/06/24/java-hashmap.html
https://zhuanlan.zhihu.com/p/76735726
https://zhuanlan.zhihu.com/p/111501405
java红黑树hashmap,原理+实战讲解
性能优化专栏
1.Tomcat性能优化整理

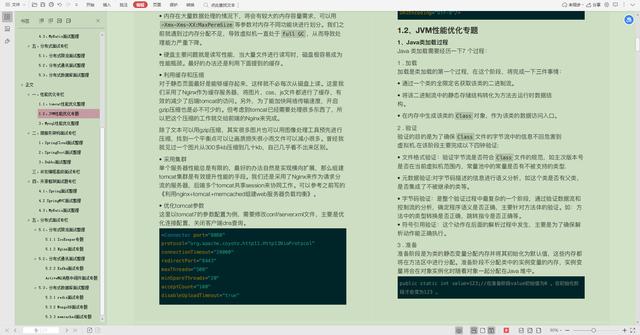
2.JVM性能优化专题
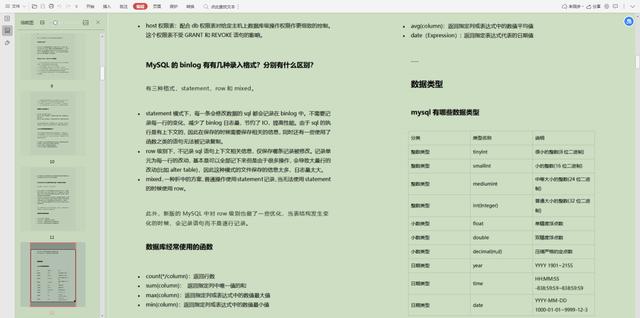
3.Mysql性能优化整理
微服务架构面试专栏
1.SpringCloud面试整理

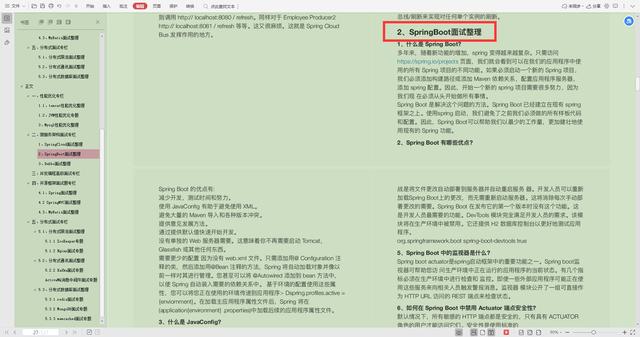
2.SpringBoot面试整理
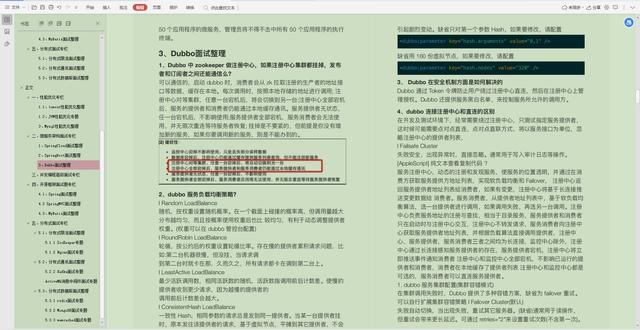
3.Dubbo面试整理
并发编程高级面试专栏

开源框架面试题专栏
1.Spring面试整理
2.SpringMVC面试整理
3.MyBatis面试整理
分布式面试专栏
1.分布式限流面试整理
- ZooKeeper专题
- Nginx面试专题


2.分布式通讯面试整理
- Kafka面试专题
- ActiveMQ消息中间件面试专题

分布式数据库面试整理
1.redis面试专题

2.MongoDB面试专题
3.memcached面试专题
总结
面试建议是,一定要自信,敢于表达,面试的时候我们对知识的掌握有时候很难面面俱到,把自己的思路说出来,而不是直接告诉面试官自己不懂,这也是可以加分的。
以上就是蚂蚁技术四面和HR面试题目,以下最新总结的最全,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考
*,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考
[外链图片转存中…(img-cCsqExwj-1625203635137)]
以上是关于HashMap面试问题整理的主要内容,如果未能解决你的问题,请参考以下文章