基于python如何建立人脸库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python如何建立人脸库相关的知识,希望对你有一定的参考价值。
您好,基于Python建立人脸库的方法如下:1. 安装Python和相关包:首先,您需要安装Python和相关的包,如OpenCV、NumPy等,以便使用Python来处理图像和视频。
2. 获取人脸数据:您需要获取足够多的人脸数据,以便训练模型。
3. 提取特征:使用Python中的OpenCV库,您可以提取人脸图像中的特征,以便进行识别。
4. 训练模型:使用提取的特征,您可以训练一个机器学习模型,以便识别不同的人脸。
5. 测试模型:最后,您可以使用测试数据来测试模型的准确性,以确保它能够准确地识别不同的人脸。 参考技术A 方法一:
1.准备环境:
安装Python和OpenCV库,并将图片文件夹里的照片放入某个文件夹中。
2.建立数据库:
创建一个数据库(或称为人脸库),存储每张人脸图片所对应的标签。
3.调用OpenCV:
使用OpenCV库中的haar cascade算法检测图片中的人脸,并创建一个人脸ID,将这个ID存储到数据库中。
4.训练:
使用OpenCV库中的LBPH算法训练人脸库,该算法可以通过相似的脸来判断一张图片中的人脸是否与库中的某张相同。
方法二:
1.准备环境:
安装Python和Dlib库,并将图片文件夹里的照片放入某个文件夹中。
2.建立数据库:
创建一个数据库(或称为人脸库),存储每张人脸图片所对应的标签。
3.调用Dlib:
使用Dlib库中的HOG算法检测图片中的人脸,并创建一个人脸ID,将这个ID存储到数据库中。
4.训练:
使用Dlib库中的SVM算法训练人脸库,该算法可以通过相似的脸来判断一张图片中的人脸是否与库中的某张相同。 参考技术B 您好,基于Python建立人脸库的方法如下:
1. 首先,您需要准备一台支持Python编程的电脑,并安装Python编程环境;
2. 然后,您需要安装OpenCV库,它是一个开源的计算机视觉库,可以用来处理图像和视频;
3. 接着,您需要准备一些人脸图片,并使用OpenCV库中的人脸检测功能,将人脸图片转换为特征矩阵;
4. 最后,您可以使用Python编程语言,将特征矩阵保存到数据库中,形成一个人脸库。 参考技术C 1.首先准备好待存储的人脸图像,使用python打开一个新文件,将待存储的图像处理成相同格式,如RGB格式,并使用pickle模块将图像序列化成二进制文件。
2.将人脸图像提取有用的特征,可以使用opencv中的detectMultiScale函数对图像进行缩放,根据其图像大小参数及比率参数进行搜索,以确定指定图像的位置。
3.将提取的人脸数据用一个python字典或者列表进行存储,存储信息包括特征值以及标签,如姓名、年龄等。
4.将字典信息存到数据库中,以备后续查询和比对使用。
5.利用machine learning对人脸图像数据进行训练,以确定其特征值的范围和大小,以便检测未知图像中的人脸。
6.最后,使用python提供的一些数据库api,查询数据库中的人脸特征值,利用特征值进行比对,以此来判断未知应是否是已有的人脸。 参考技术D 您好,要建立一个基于Python的人脸库,首先需要准备一些人脸图片,然后使用Python的OpenCV库来检测和识别这些图片中的人脸,并将其存储到一个数据库中。接下来,您可以使用Python的scikit-learn库来构建一个机器学习模型,以便对新的人脸图片进行分类和识别。最后,您可以使用Python的Flask框架来构建一个Web应用程序,用于检索和查看人脸库中的信息。
基于python版本的dlib库进行人脸识别
最近冒出做人脸识别的想法,在github上正巧看到这个项目,在了解了大概思路之后打算自己独立复刻出这个人脸识别项目。由于笔者自身代码水平并不高,若有地方错误或者不合适的,还希望大神能够指出,感谢交流!写完这篇文章后感觉又收获不少东西。
项目特点
- 可自行建立人脸特征库
- 可实时对单张或多张人脸进行识别
dlib库简介
Dlib 是一个现代C++工具包,包含机器学习算法和工具,用于在C++中创建复杂的软件,以解决现实世界中的问题。按照dlib官网的叙述,其特点主要有:
- 丰富的帮助文档:dlib官网为每个类与功能都提供了完整的帮助文档,且官网提供有非常多的例程。作者在官网有说如果有东西文件没记录或者不清楚的可以联系他更改。
- 高质量的可移植代码:dlib库不需要第三方库且符合ISO C++标准,支持Windows, Linux, Mac OS X系统。
- 丰富的机器学习算法:dlib库中包括深度学习算法、SVM以及一些常用的聚类算法等。
- 图像处理:支持读写windows BMP文件、可实现各种色彩空间的图像变换、包括物体检测的一些工具以及高质量的人脸识别功能。
- 线程:提供了简单可移植的线程API。
环境建立
笔者实验时的主要环境如下:
python = 3.6.4
dlib = 19.8.1
opencv = 3.4.1.15
tqdm = 4.62.1
- 首先是建立环境。打开Anaconda Prompt,输入如下命令新建名为dlibTest(可更改,后续激活注意对应)、python版本为3.6.4的环境,这个环境专门用来存放该实验所用到的库。建立完成后输入第二行命令激活环境。
conda create -n dlibTest python=3.6.4conda activate dlibTest - 继续输入如下命令安装与实验对应版本的库,安装opencv时会自动帮我们安装numpy库。
pip install dlib==19.8.1pip install opencv-python==3.4.1.15pip install tqdm
使用dlib库进行人脸识别
一、采集人脸数据
先在代码中定义dlib用于人脸识别的检测器和特征提取器
detector = dlib.get_frontal_face_detector() # 人脸检测器
# detector = dlib.cnn_face_detection_model_v1(model_path)
predictor = dlib.shape_predictor(shape_predictor_path) # 人脸68点提取器
# shape_predictor_path = 'data_dlib/shape_predictor_68_face_landmarks.dat'
recognition_model = dlib.face_recognition_model_v1(recognition_model_path) # 基于resnet的128维特征向量提取器
# recognition_model_path = 'data_dlib/dlib_face_recognition_resnet_model_v1.dat'其中,人脸检测器detector也可用cnn进行检测。
人脸数据可以用网上的照片,也可以自己通过摄像头采集。
通过摄像头获取图像进行人脸识别的代码如下,运行过程中可收集人脸数据,检测到人脸后按下“n”可新建人脸文件夹,之后再按下“s”可对人脸图像进行保存。因为一次采集的数据均放在一个文件夹下,故一次采集应只对一人进行。
import cv2 as cv
import time
import os
import config
class face_detect():
def __init__(self):
self.start_time = 0 # 用于计算帧率
self.fps = 0 # 帧率
self.image = None
self.face_img = None
self.face_num = 0 # 这一帧的人脸个数
self.last_face_num = 0 # 上一帧的人脸个数
self.face_num_change_flag = False # 当前帧人脸数量变化的标志位,用于后续人脸识别提高帧率
self.quit_flag = False # 退出程序标志位
self.buildNewFolder = False # 按下"n"新建文件夹标志位
self.save_flag = False # 按下“s”保存人脸数据标志位
self.face_flag = False # 人脸检测标志位
self.img_num = 0 # 人脸数据文件夹内的图像个数
self.collect_face_data = True # 是否进行人脸数据的采集,只有为真时才会进行采集
def get_fps(self):
now = time.time()
time_period = now - self.start_time
self.fps = 1.0 / time_period
self.start_time = now
color = (0,255,0)
if self.fps < 15:
color = (0,0,255)
cv.putText(self.image, str(self.fps.__round__(2)), (20, 50), cv.FONT_HERSHEY_DUPLEX, 1, color)
def key_scan(self, key):
if self.collect_face_data == True:
if self.save_flag == True and self.buildNewFolder == True:
if self.face_img.size > 0:
cv.imwrite(
config.faceData_path + 'person_{}/{}.png'.format(config.num_of_person_in_lib - 1, self.img_num),
self.face_img)
self.img_num += 1
if key == ord('s'):
self.save_flag = not self.save_flag
if key == ord('n'):
os.makedirs(config.faceData_path + 'person_{}'.format(config.num_of_person_in_lib))
config.num_of_person_in_lib += 1
print("新文件夹建立成功!!")
self.buildNewFolder = True
if key == ord('q'): self.quit_flag = True
def face_detecting(self):
face_location = []
all_face_location = []
faces = config.detector(self.image, 0)
self.face_num = len(faces)
if self.face_num != self.last_face_num:
self.face_num_change_flag = True
print("脸数改变,由{}张变为{}张".format(self.last_face_num, self.face_num))
self.check_times = 0
self.last_face_num = self.face_num
else:
self.face_num_change_flag = False
if len(faces) != 0:
self.face_flag = True
for i, face in enumerate(faces):
face_location.append(face)
w, h = (face.right() - face.left()), (face.bottom() - face.top())
left, right, top, bottom = face.left() - w//4, face.right() + w//4, face.top() - h//2, face.bottom() + h//4
all_face_location.append([left, right, top, bottom])
return face_location, all_face_location
else:
self.face_flag = False
return None
def show(self, camera):
while camera.isOpened() and not self.quit_flag:
val, self.image = camera.read()
if val == False: continue
key = cv.waitKey(1)
res = self.face_detecting()
if res is not None:
_, all_face_location = res
for i in range(self.face_num):
[left, right, top, bottom] = all_face_location[i]
self.face_img = self.image[top:bottom, left:right]
cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))
if self.collect_face_data == True:
cv.putText(self.image, "Face", (int((left + right) / 2) - 50, bottom + 20), cv.FONT_HERSHEY_COMPLEX, 1,
(255, 255, 255))
self.key_scan(key)
self.get_fps()
cv.namedWindow('camera', 0)
cv.imshow('camera', self.image)
camera.release()
cv.destroyAllWindows()
def main():
try:
cam = cv.VideoCapture(0)
face_detect().show(cam)
finally:
cam.release()
cv.destroyAllWindows()
print("程序退出!!")
if __name__ == '__main__':
main()具体检测效果如下图所示,马赛克为后期增加

采集的人脸数据在工程文件夹faceData下,这里三个文件夹分别存放刘德华、王冰冰、西野七濑的图片:
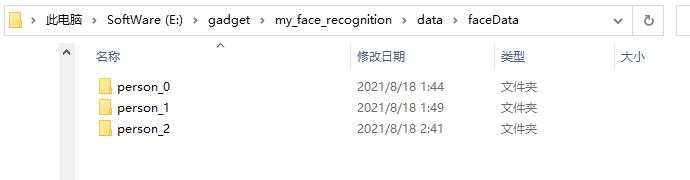



下一步再对记录人脸名字的txt文件进行修改,注意顺序与faceData内存放人脸图像的文件夹顺序对应。
二、获取128维特征向量
首先是对前一步采集到的人脸图像进行人脸检测(避免有时候cv展示的图像上检测到人脸,但保存下来的图像却检测不到而报错),再对检测到人脸的图像进行68个人脸关键点的提取,提取效果如下图所示:

之后再将这68个点的值输入到resnet模型中抽象出128维的人脸特征向量,进而保存在csv文件夹中从而建立了一个人脸数据库。
获取特征向量的函数如下:
def get_128_features(person): # person代表第几个人脸数据文件夹
num = 0
features = []
imgs_folder = config.imgs_folder_path[person]
points_faceImage_path = config.points_faceData_path + imgs_folder
imgs_path = config.faceData_path + imgs_folder + '/'
list_imgs = os.listdir(imgs_path)
imgs_num = len(list_imgs)
if os.path.exists(config.points_faceData_path + imgs_folder):
shutil.rmtree(points_faceImage_path)
os.makedirs(points_faceImage_path)
print("人脸点图文件夹建立成功!!")
with tqdm(total=imgs_num) as pbar:
pbar.set_description(str(imgs_folder))
for j in range(imgs_num):
image = cv.imread(os.path.join(imgs_path, list_imgs[j]))
faces = config.detector(image, 1) # 经查阅资料,这里的1代表采样次数
if len(faces) != 0:
for z, face in enumerate(faces):
shape = config.predictor(image, face) # 获取68点的坐标
w, h = (face.right() - face.left()), (face.bottom() - face.top())
left, right, top, bottom = face.left() - w // 4, face.right() + w // 4, face.top() - h // 2, face.bottom() + h // 4
im = image
cv.rectangle(im, (left, top), (right, bottom), (0, 0, 255))
cv.imwrite(points_faceImage_path + '/{}.png'.format(j), im)
if config.get_points_faceData_flag == True:
for p in range(0, 68):
cv.circle(image, (shape.part(p).x, shape.part(p).y), 2, (0,0,255))
cv.imwrite(points_faceImage_path + '/{}.png'.format(j), image)
the_features = list(config.recognition_model.compute_face_descriptor(image, shape)) # 获取128维特征向量
features.append(the_features)
#print("第{}张图片,第{}张脸,特征向量为:{}".format(j+1, z+1, the_features))
num += 1
pbar.update(1)
np_f = np.array(features)
#res = np.mean(np_f, axis=0)
res = np.median(np_f, axis=0)
return res三、人脸识别
建立好人脸数据库后就可开始进行人脸识别了,其过程也是和之前类似。先获取图像、对图像进行人脸检测、检测到人脸后进行特征抽象、将库内的特征向量逐个与当前的特征向量进行欧氏距离的计算、根据阈值判断是否属于库内人脸。
其中,n维空间计算欧氏距离的公式如下:

运用numpy库计算向量间欧式距离的代码如下:
def calculate_EuclideanDistance(self, feature1, feature2): # 计算欧氏距离
np_feature1 = np.array(feature1)
np_feature2 = np.array(feature2)
EuclideanDistance = np.sqrt(np.sum(np.square(np_feature1 - np_feature2)))
return EuclideanDistance人脸识别代码中进行了5次的人脸识别,之后取每个特征分量的中值得到最终预测的特征向量,尽量减少干扰。self.init_process()是进行加载库以及名字的操作:
def recognition_from_cam(self):
self.init_process()
while self.camera.isOpened() and not self.quit_flag:
val, self.image = self.camera.read()
if val == False: continue
#self.image = cv.imread('./data/test/test_bb.jpg')
key = cv.waitKey(1)
res = self.face_detecting() # 0.038s
if res is not None:
face, self.all_face_location = res
for i in range(self.face_num):
[left, right, top, bottom] = self.all_face_location[i]
self.middle_point = [(left + right) /2, (top + bottom) / 2]
self.face_img = self.image[top:bottom, left:right]
cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))
shape = config.predictor(self.image, face[i]) # 0.002s
if self.face_num_change_flag == True or self.check_times <= 5:
if self.face_num_change_flag == True: # 人脸数量有变化,重新进行五次检测
self.check_times = 0
self.last_now_middlePoint_eDistance = [99999 for _ in range(self.available_max_face_num)]
for z in range(self.available_max_face_num): self.check_features_from_cam[z] = []
if self.check_times < 5:
the_features_from_cam = list(config.recognition_model.compute_face_descriptor(self.image, shape)) # 耗时主要在这步 0.32s
if self.check_times == 0: # 初始帧
self.check_features_from_cam[i].append(the_features_from_cam)
self.last_frame_middle_point[i] = self.middle_point
else:
this_face_index = self.track_link() # 后续帧需要与初始帧的人脸序号对应
self.check_features_from_cam[this_face_index].append(the_features_from_cam)
elif self.check_times == 5:
features_after_filter = self.middle_filter(self.check_features_from_cam[i])
self.check_features_from_cam[i] = []
for person in range(config.num_of_person_in_lib):
e_distance = self.calculate_EuclideanDistance(self.all_features[person],
features_after_filter) # 几乎不耗时
self.all_e_distance[i].append(e_distance)
if min(self.all_e_distance[i]) < config.recognition_threshold:
self.person_name[i] = self.all_name[self.all_e_distance[i].index(min(self.all_e_distance[i]))]
cv.putText(self.image, self.person_name[i],
(int((left + right) / 2) - 50, bottom + 20),
cv.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255))
else:
self.person_name[i] = "Unknown"
print("预测结果为:{}, 与库中各人脸的欧氏距离为:{}".format(self.person_name[i], self.all_e_distance[i]))
else:
this_face_index = self.track_link()
#print(this_face_index, self.person_name)
cv.putText(self.image, self.person_name[this_face_index], (int((left + right) / 2) - 50, bottom + 20),
cv.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255))
self.check_times += 1
for j in range(self.available_max_face_num):
self.all_e_distance[j] = []
self.key_scan(key)
self.get_fps()
cv.namedWindow('camera', 0)
cv.imshow('camera', self.image)
self.camera.release()
cv.destroyAllWindows()具体识别效果如下图所示
单张人脸

多张人脸

由于库中没有薛之谦的人脸数据,故识别出来为Unknown。
实例给的是直接读取图片,观赏效果会比较好。也可以摄像头读取图像进行识别,但若每次都进行特征向量提取,则会浪费大量时间从而导致帧率过低。原项目作者是根据前后帧的人脸数量是否发生变化来判断是否进行特征提取的,若人脸数量发生变化,则对每张人脸进行特征提取;否则就只进行人脸检测+人脸跟踪。这样就省掉了后续帧不必要的特征提取,提高了帧率。
实际效果如下图所示(13帧左右)
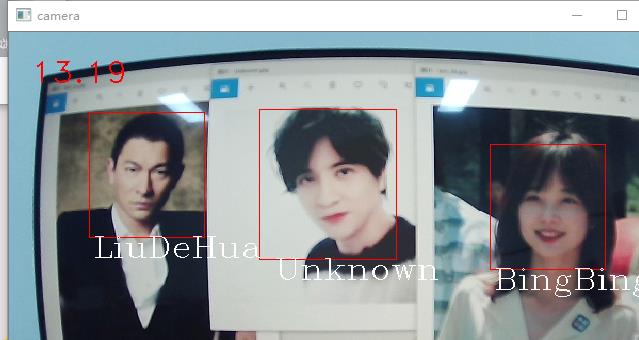
一般情况下的帧率(15帧左右)

我的代码放在consolas-K/dlib_faceRecognition: 使用dlib进行人脸识别 (github.com),原项目作者的代码在参考资料中。
参考资料
以上是关于基于python如何建立人脸库的主要内容,如果未能解决你的问题,请参考以下文章
基于Python_opencv人脸录入识别系统(应用dlib机器学习库)