如何把windows10系统默认默认字符集从gbk修改为gb2312
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何把windows10系统默认默认字符集从gbk修改为gb2312相关的知识,希望对你有一定的参考价值。
Windows XP、Windows7操作系统自带的都是GBK字符集(含2万余汉字),是完全兼容GB2312(仅含0.67万汉字)的。
检查和修改字符集的方法是:
1.【开始】→【运行】→输入cmd
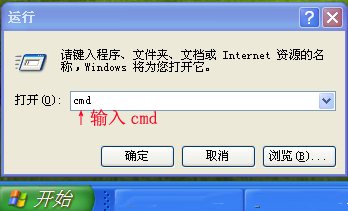
2.【确定】→输入chcp
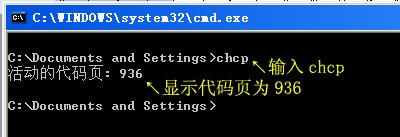
显示出活动的代码页是936。
3.【开始】→【控制面板】→【日期、时间、语言和区域设置】→【区域和语言选项】
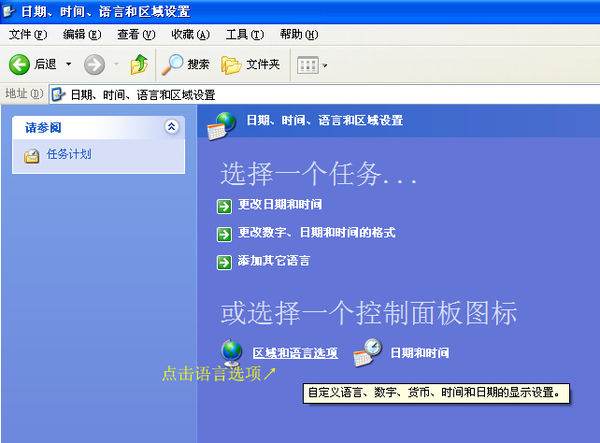
4.【高级】→在代码页转换表中可找到936是简体中文GBK字符集,若不要它的话,可以点击前面小框中的勾,即把勾去掉。

5.继续寻找简体中文GB2312字符集,即代码页是20936,点击前面的小框打上勾。【应用】→【确定】即可。

这样修改后,Windows操作系统自带的就变成GB2312字符集了。
字符集:
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。中文文字数目大,而且还分为简体中文和繁体中文两种不同书写规则的文字,而计算机最初是按英语单字节字符设计的,因此,对中文字符进行编码,是中文信息交流的技术基础。
GB2312:
1.名称由来:
GB2312又称为GB2312-80字符集,全称为《信息交换用汉字编码字符集·基本集》,由原中国国家标准总局发布,1981年5月1日实施。
2.特点:
GB2312是中国国家标准的简体中文字符集。它所收录的汉字已经覆盖99.75%的使用频率,基本满足了汉字的计算机处理需要。在中国大陆和新加坡获广泛使用。
3.包含内容:
GB2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
4.技术特征:
(1)分区表示:
GB2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
各区包含的字符如下:01-09区为特殊符号;16-55区为一级汉字,按拼音排序;56-87区为二级汉字,按部首/笔画排序;10-15区及88-94区则未有编码。
(2)双字节表示
两个字节中前面的字节为第一字节,后面的字节为第二字节。习惯上称第一字节为“高字节” ,而称第二字节为“低字节”。
“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上0xA0)。
参考技术A Windows95、 XP……7操作系统自带的都是GBK字符集(含2万余汉字),是完全兼容GB2312(仅含0.67万汉字)的。不必将GBK字符集改为小字符集,否则会导致GBK字符集的大量字符不能显示。检查和修改字符集的方法是:
➀【开始】→【运行】→输入cmd
➁【确定】→输入chcp
显示出活动的代码页是936。
➂【开始】→【控制面板】→【日期、时间、语言和区域设置】→【区域和语言选项
➃【高级】→在代码页转换表中可找到936是简体中文GBK字符集,若不要它的话,可以点击前面小框中的勾,即把勾去掉。
➄继续寻找简体中文GB2312字符集,即代码页是20936,点击前面的小框打上勾。【应用】→【确定】即可。
这样修改后,Windows操作系统自带的就变成GB2312字符集了。
如果仅出现乱码,是否字库有问题,建议查一下文件夹windows\fonts中的字库。本回答被提问者采纳
ubuntu中文乱码--添加中文字符集
在Ubuntu支持中文后(方法见上篇文章),默认是UTF-8编码,而Windows中文版默认是GBK编码。为了一致性,通常要把Ubuntu的默认 编码改为GBK。当然你也可以不改,但这会导致我们在两个系统之间共享文件变得非常不方便,Samba共享的文件也总会有乱码出现。总不能每次传完文件都 人肉转码一次吧。
ubuntu转码需要分为几个部分分别进行:
1. 系统级
Ubuntu默认是不支持GBK的。这里若不更改,则后续步骤均无法生效。
添加中文字符编码:
- $sudo vim /var/lib/locales/supported.d/local
#添加下面的中文字符集
- zh_CN.GBK GBK
- zh_CN.GB2312 GB2312
- zh_CN.GB18030 GB18030
使其生效:
- $sudo dpkg-reconfigure locales
2. vim
虽然Ubuntu已经支持GBK了,但默认的输入/显示方式仍然是UTF-8,要想改变就需要我们逐一去设定。VIM首当其冲。
打开vim的配置文件,位置在/etc/vim/vimrc
在其中加入
- set fileencodings=utf-8,gb2312,gbk,gb18030
- set termencoding=utf-8
- set encoding=gbk
保存退出
- source /etc/vim/vimrc
此时vim就能正确显示中文了。
--------------------------------------------------------------‘
3. 让Terminal默认GBK
虽然VIM已经能够编写/打开GBK文件,但cat <filename>时我们发现仍然是乱码。此时我们需要更改Terminal的默认编码方式。
在terminal面板上选择菜单栏中的termianl-->set character encoding-->add or remove,然后在左侧选择GB2312或GBK,添加到右侧,关闭。
然后在terminal面板上的 termianl-->set
character encoding选定增加的中文编码,然后就可以正常显示中文了。
4. pdf
- $sudo apt-get install xpdf-chinese-simplifiedxpdf-chinese-traditional #安装pdf的中文字体
- $sudo apt-get install poppler-data #安装解决pdf中文显示乱码的软件
- $cd /etc/fonts/conf.d
- $sudo cp 49-sansserif.conf 49-sansserif.conf_backup #先备份下
- $sudo rm 49-sansserif.conf #删除
在打开pdf文件,就能呢个正常显示中文了
5. gedit
缺省配置下,用 Ubuntu 的文本编辑器(gedit)打开 GB18030/GBK/GB2312 等类型的中文编码文本文件时,将会出现乱码。
出现这种情况的原因是,gedit 使用一个编码匹配列表,只有在这个列表中的编码才会进行匹配,不在这个列表中的编码将显示为乱码。您要做的就是将 GB18030 加入这个匹配列表。
命令行方式,适用于所有 Ubuntu 用户。
复制以下命令到终端中,然后回车即可:
gconftool-2 --set --type=list --list-type=string
/apps/gedit-2/preferences/encodings/auto_detected
"[UTF-8,CURRENT,GB18030,BIG5-HKSCS,UTF-16]"
图形化方式,适用于 Ubuntu 用户,而不适用于 KUbuntu/XUbuntu 用户。
您可以遵循以下步骤,使您的 gedit 正确显示中文编码文件。
按下 Alt-F2,打开“运行应用程序”对话框。
在文本框中键入“gconf-editor”,并按下回车键,打开“配置编辑器”。
展开左边的树节点,找到 /apps/gedit-2/preferences/encodings 节点并单击它。
双击右边的 auto_detected 键,打开“编辑键”对话框。
单击列表右边的“添加”按钮,输入“GB18030”,单击确定按钮。
列表的最底部新增加了一个“GB18030”。单击选中它,并单击右边的 “向上” 按钮直到 “GB18030” 位于列表的顶部为止。
单击确定按钮,关闭配置编辑器。
gedit3.x版本设置
终端输入dconf-editor
展开org/gnome/gedit/preferences/encodings
auto-detected的value中加入’GB18030′,加在uft8后面;
show-in-menu的value中加入’GB18030′
现在,您的 gedit 应该能够顺利打开 GB18030 编码的文本文件了。
gedit 3.X版本命令设置:gsettings set org.gnome.gedit.preferences.encodings
auto-detected
"[‘UTF-8‘,‘GB18030‘,‘GB2312‘,‘GBK‘,‘BIG5‘,‘CURRENT‘,‘UTF-16‘]"
6. 中文文件名乱码转换
因为以前使用zh_CN.GB* 现在使用zh_CN.UTF-8,所以文件名编码有问题。
convmv -f gbk -t utf-8 -r --notest /filePath
参考:
http://blog.csdn.net/zbunix/article/details/8948139
以上是关于如何把windows10系统默认默认字符集从gbk修改为gb2312的主要内容,如果未能解决你的问题,请参考以下文章
如何把windows系统默认字符集从GBK修改为GB2312?
如何把windows系统默认字符集从GBK修改为GB2312?
Windows系统下Eclipse下默认的编码格式是啥?GBK?已有的工程文件转换为UTF-8之后为何不能正确读取?