Flink的standAlone模式的HA环境
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink的standAlone模式的HA环境相关的知识,希望对你有一定的参考价值。
参考技术A 在上一节当中,我们实现了flink的standAlone模式的环境安装,并且能够正常提交任务到集群上面去,我们的主节点是jobManager,但是唯一的问题是jobmanager是单节点的,必然会有单节点故障问题的产生,所以我们也可以在standAlone模式下,借助于zk,将我们的jobManager实现成为高可用的模式首先停止Flink的standAlone模式,并启动zk和hadoop集群服务
node01执行以下命令修改Flink的配置文件
cd /kkb/install/flink-1.8.1/conf
vim flink-conf.yaml
jobmanager.rpc.address: node01
high-availability: zookeeper
high-availability.storageDir: hdfs://node01:8020/flink
high-availability.zookeeper.path.root: /flink
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:218
node01执行以下命令修改master配置文件
cd /kkb/install/flink-1.8.1/conf
vim masters
node01:8081
node02:8081
node01执行以下命令修改slaves配置文件
cd /kkb/install/flink-1.8.1/conf
vim slaves
node01
node02
node03
node01执行以下命令,在hdfs上面创建文件夹
hdfs dfs -mkdir -p /flink
将node01服务器修改后的配置文件拷贝到其他服务器上面去
node01执行以下命令拷贝配置文件
cd /kkb/install/flink-1.8.1/conf
scp flink-conf.yaml masters slaves node02:$PWD
scp flink-conf.yaml masters slaves node03:$PWD
node01执行以下命令启动flink集群
cd /kkb/install/flink-1.8.1
bin/start-cluster.sh
访问node01服务器的web界面
http://node01:8081/#/overview
访问node02服务器的web界面
http://node02:8081/#/overview
注意:一旦访问node02的web界面,会发现我们的web界面会自动跳转到node01的web界面上,因为此时,我们的node01服务器才是真正的active状态的节点
将node01服务器的jobManager进程杀死,然后过一段时间之后查看node02的jobManager是否能够访问
注意: JobManager发生切换时,TaskManager也会跟着发生重启,这其实是一个隐患问题
在HA这种模式下,提交任务与standAlone单节点模式提交任务是一样的,即使JobManager服务器宕机了也没有关系,会自动进行切换
node01执行以下命令启动socket服务,输入单词
nc -lk 9000
node01启动flink的自带的单词统计程序,接受输入的socket数据并进行统计
cd /kkb/install/flink-1.8.1
bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname node01 --port 9000
node01服务器执行以下命令查看统计结果
cd /kkb/install/flink-1.8.1/log
tail -200f flink-hadoop-taskexecutor-0-node01.kaikeba.com.out
flink的standalone模式环境搭建
一.standalone模式
所有的资源都由flink自己管理
flink的jar包:flink-1.11.2-bin-scala_2.11.tgz
把安装包放到linux中

bin #服务或命令
conf #配置文件
examples #实例,案例
lib #jar包
log #日志1.解压缩
tar -xzvf flink-1.11.2-bin-scala_2.11.tgz
修改名字
mv flink-1.11.2/ flink2.配置环境变量
#回到家目录下
cd
#修改环境变量
vi .bashrc
export FLINK_HOME=/path/flink
PATH=$PATH:$FLINK_HOME/bin
source .bashrc
3.修改配置文件
standalone模式不需要修改配置文件
4.启动服务
进去到 bin/ 目录下
#开启集群
start-cluster.sh
5.验证
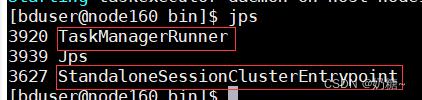
1) jps验证,出现standaloneSessionClusterEntrypoint和TaskManagerRunner服务
2)验证WebUI
在浏览器访问 :host:8081
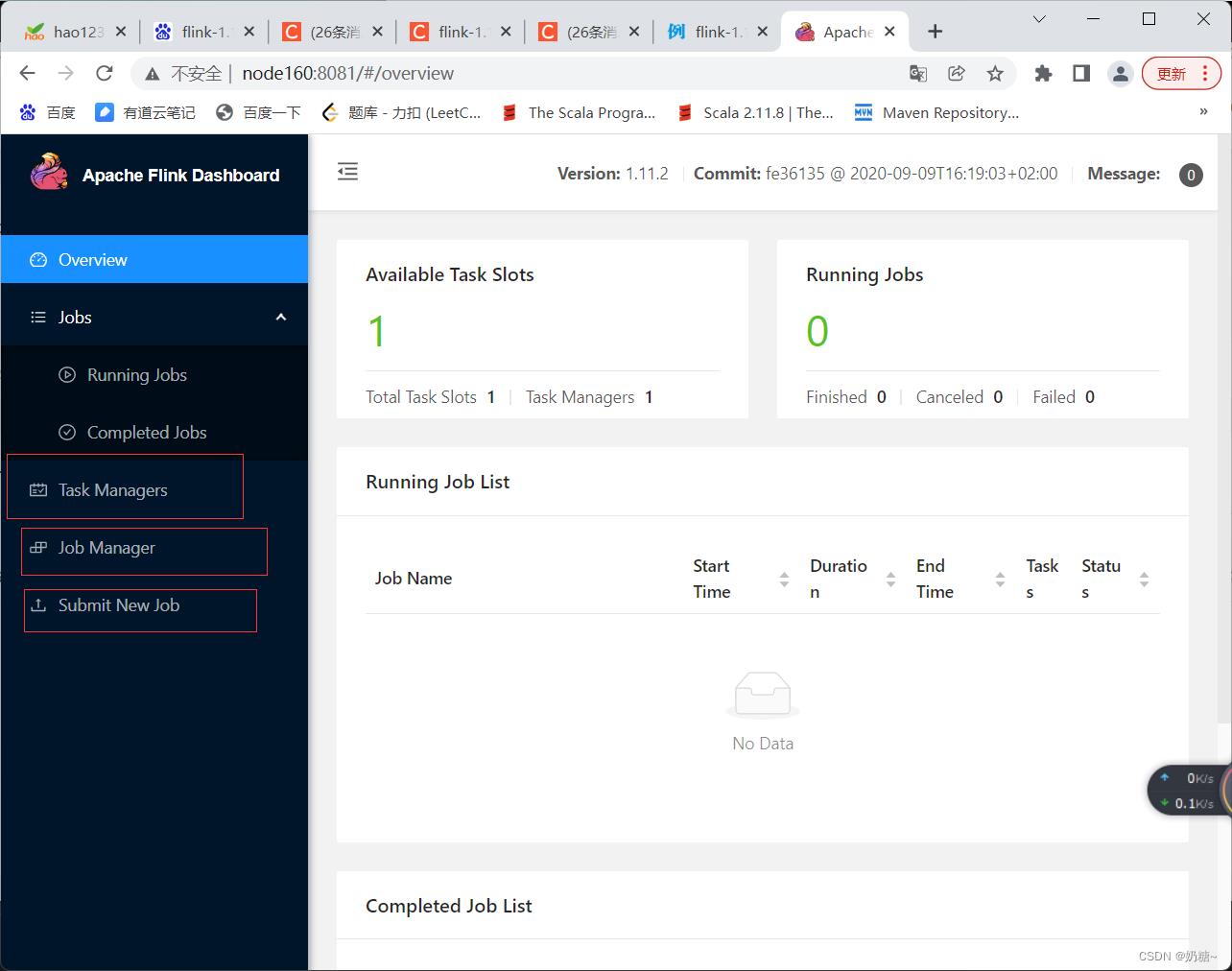
Running Jobs:正在运行的job
completed Jobs:已经完成的job
task Managers: 从节点
Job manager: 主节点
Submit New Job : 提交新任务Job
另一种提交方式:打成jar包,放在linux里面,通过命令行的形式进行提交
task slots: 静态资源 ,默认为1
6.两个验证都出现,则成功搭建flink
7.提交任务
1)WebUI直接提交job任务
并行度必须小于slots的数量,否则无法执行,报超时
a.在ide中把代码打成jar包
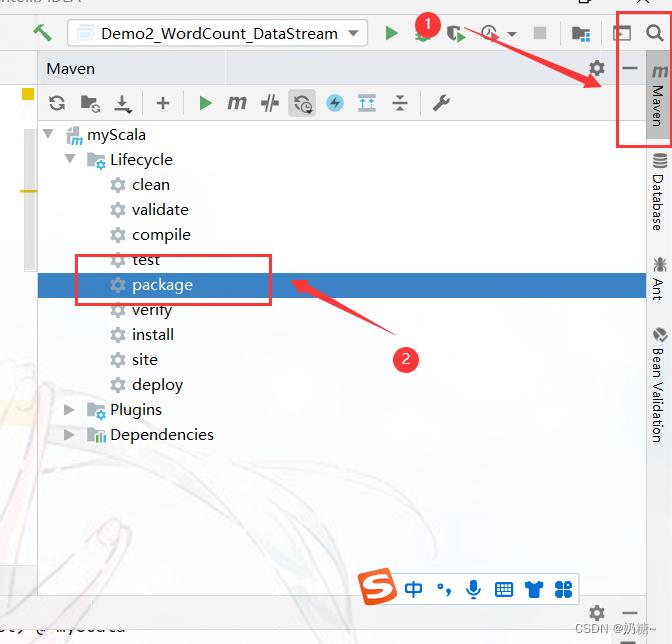
b. 在webUI上进入submit new job --> add new -->选择这个jar包
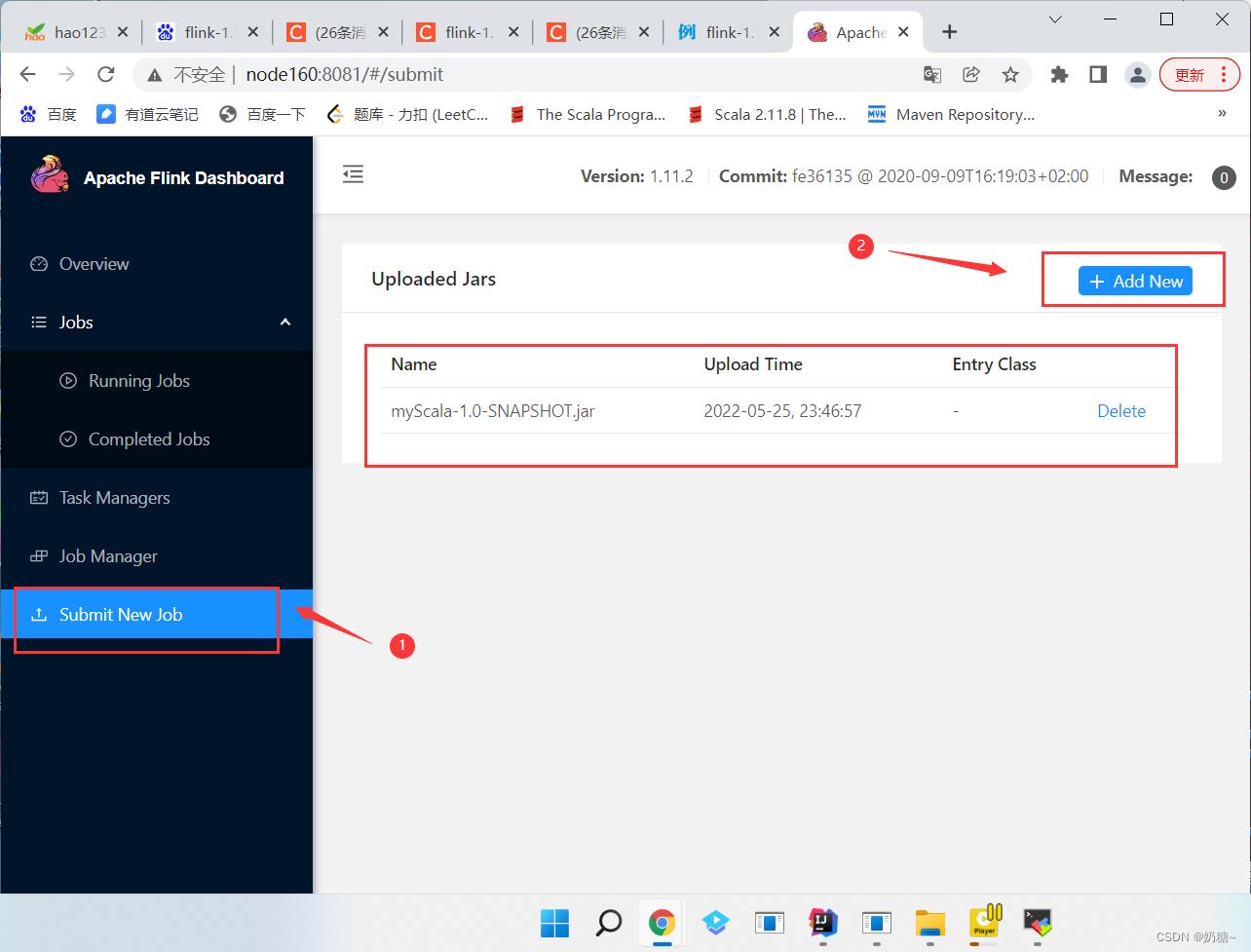
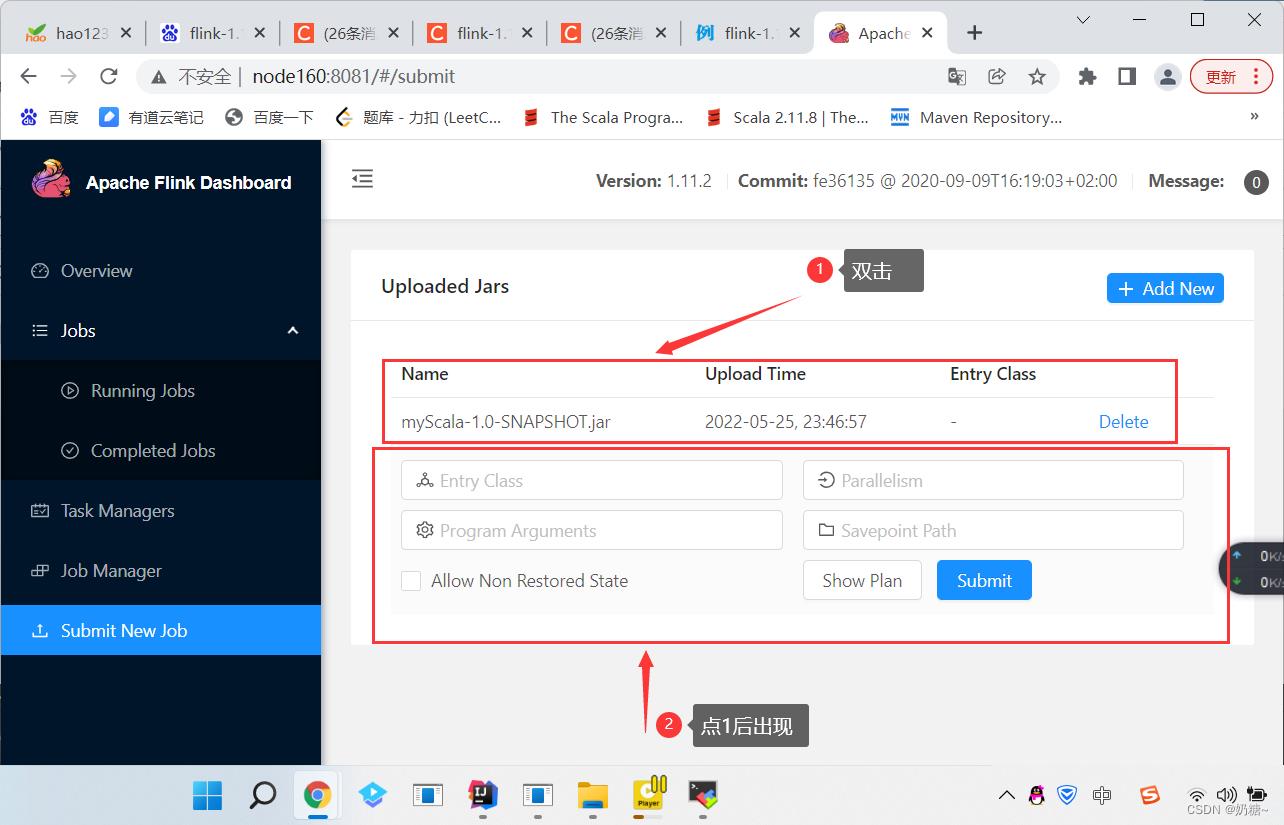
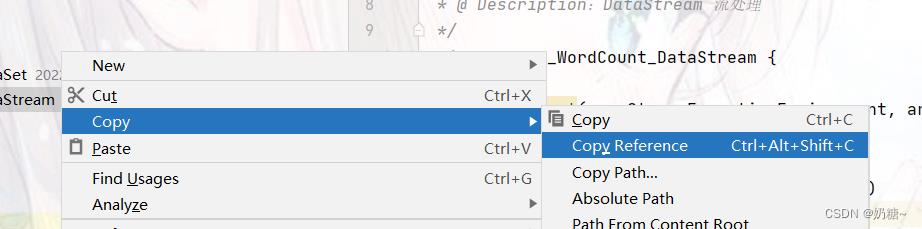
Entry Class:打开idea,右击添加的class类,copy reference
Program Arguments: 文件路径 --input D:/wordCount.txt
Parallelism: 并行度
c. 提交
在WebUI -->TestManager --> stdOut 查看结果(需要刷新)
在WebUI -->Job Manager --> log 查看运行日志,也可以取消任务
2)使用命令行直接提交
a.在ide中把代码打成jar包
b.把jar包拽到linux环境下
mkdir flink
#查看帮助文档
flink
#命令行 -c 文件路径 -p 并行度 --host --port 参数
flink run -c Demo2_WordCount_DataStream -p 1 ./file/flink/myScala-1.0-SNAPSHOT.jar --host node160 --port 8888
c.开启实时数据
nc -lk 8888
#在窗口中输入数据 在WebUI中查看数据d.查看flink状态
#Running 正在运行
flink list
#查看所有job任务
flink list -a
#查看结果
webUI-> TaskMaranger -> stdout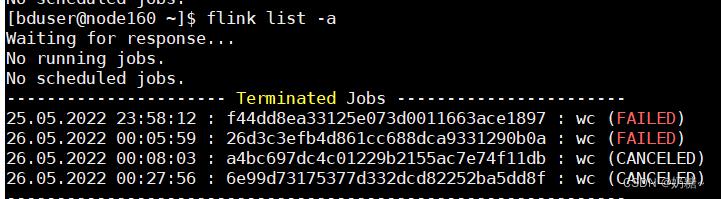

e.取消命令
#6e99d73175377d332dcd82252ba5dd8f id
flink cancel jobid(6e99d73175377d332dcd82252ba5dd8f )
f.关闭集群服务
stop-cluster.sh
以上是关于Flink的standAlone模式的HA环境的主要内容,如果未能解决你的问题,请参考以下文章