python爬虫下载音乐?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫下载音乐?相关的知识,希望对你有一定的参考价值。
我要用爬虫在这个网站(https://music.163.com/song/media/outer/url?id=1456443773.mp3)下载音乐该怎么下?

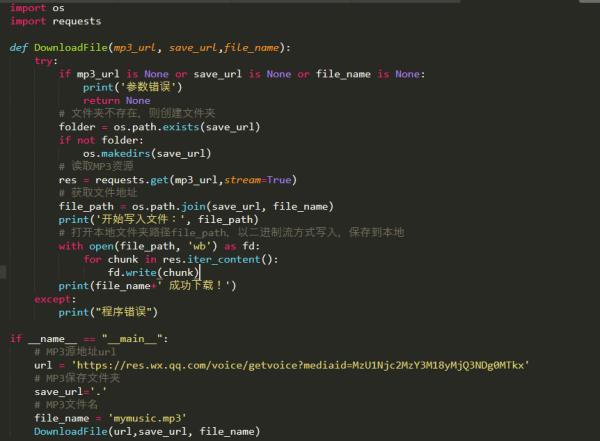
import requests
from playsound import playsound
class Music:
def save(self,url):
res=requests.get(url)
with open('music.mp3','wb') as f:
f.write(res.content)
if __name__ == '__main__':
url="https://music.163.com/song/media/outer/url?id=1456443773.mp3"
music=Music().save(url)
playsound("music.mp3")追问
运行后下载下来的文件只有51字节,为什么?


下载下来的文件只有51字节,为什么?
Python爬虫案例:下载酷某音乐文件
文章目录
1、Python爬虫案例下载音乐
1.1、前期准备
要有rquests、re、json包,如果不存在,先用pip install安装
1.2、分析
1.2.1、第一步
首先我们先进入首页并搜索你要查询的歌手,进入查询的页面,查看页面源代码,发现并没有这个列表数据,这里就不展示了,页面源代码没有发现想要的数据,那就来看network网络请求中的数据
1.2.2、第二步
打开网络请求,刷新页面,找到需要的请求
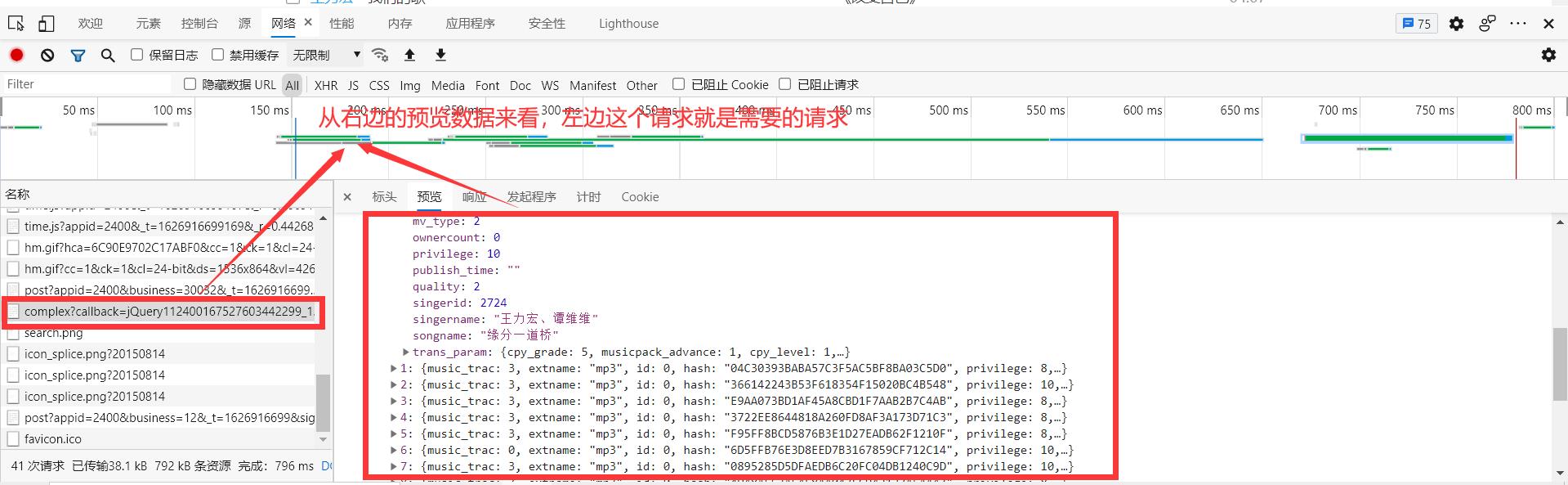
打开标头查看url中携带的数据
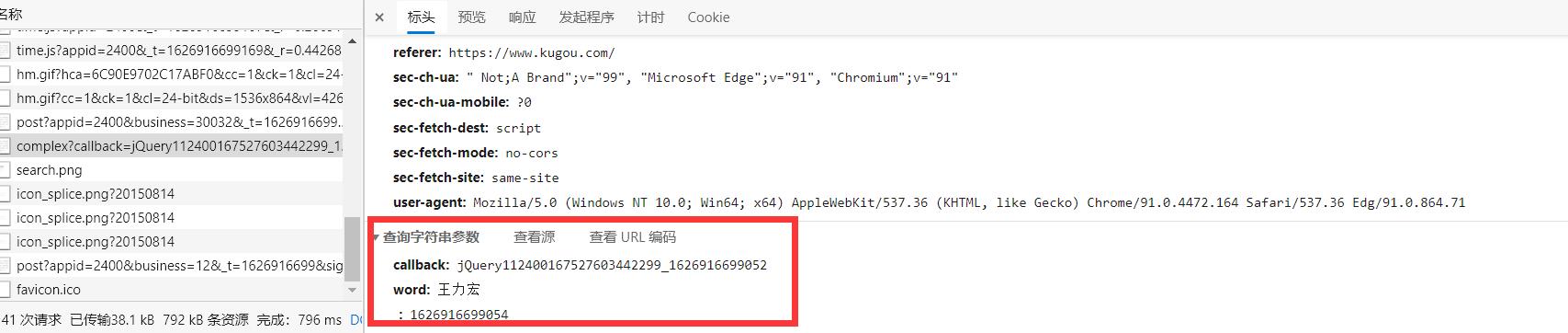
通过查看参数可知,不仅仅存在着我们搜索的内容,还有两个其它的参数callback 和 _ 两个参数,这乍一看还挺懵的,想着是不是有什么脚本进行了加密什么的,后面通过测试,发现这两给参数是一个随机给出的随机值,将这两个参数固定修改搜索的歌手,发现能够查询到我们需要的内容。所有接下来可以进行我们的第三步
1.2.3、第三步
随便点击一首歌曲,进入听歌页面,发现还是老套路,在页面源代码中没有发现需要的MP3音乐文件,所有又需要看network网络请求中的数据
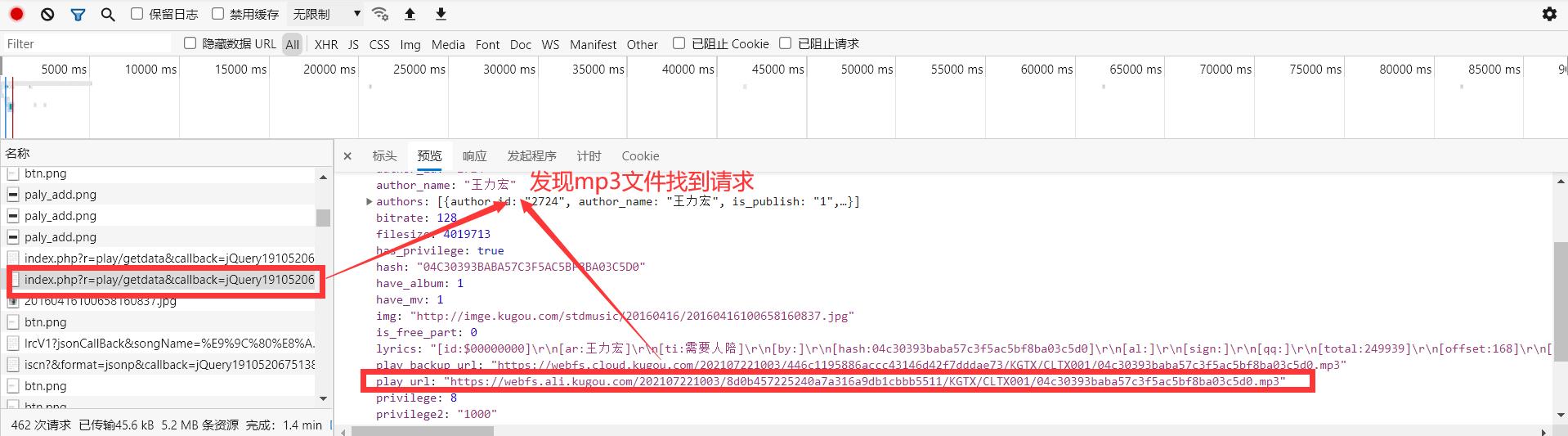
打开标头查看url中携带的数据
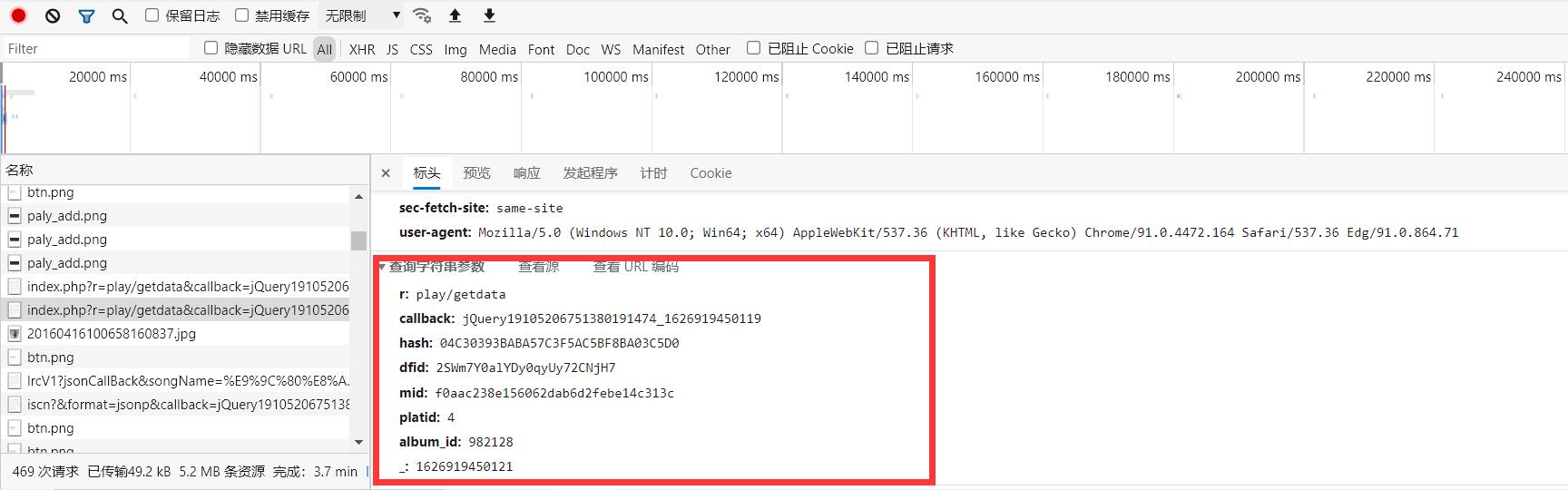
查看携带的参数,发现有很多,不过没事,通过分析可以发现只有hash和album_id是变值,其它的都是跟第二步中的callback 和 _ 这个参数一样,是可以固定下来的,我们只需关心hash和album_id这两个参数
通过分析可以知道,第二步中的请求中有我们需要的这两个参数,如下
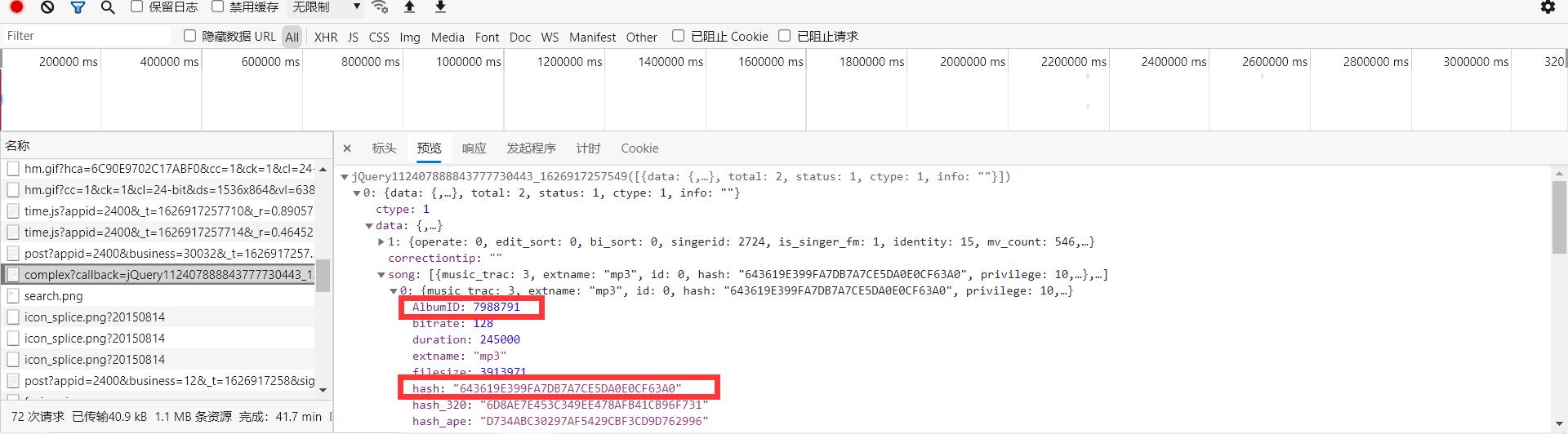
找到了要下载音乐的所有需要的东西,接下来可以进行我们的第四步
1.2.4、第四步
访问找的两个求,查看返回的数据信息
第二步的请求
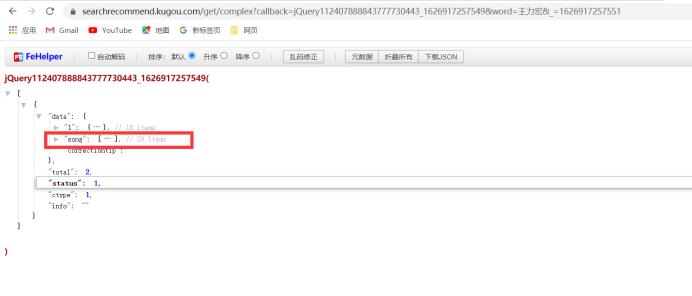

通过分析发现hash和album_id这两个参数存在song中所有我们需要将这个song给取出来
第三步的请求
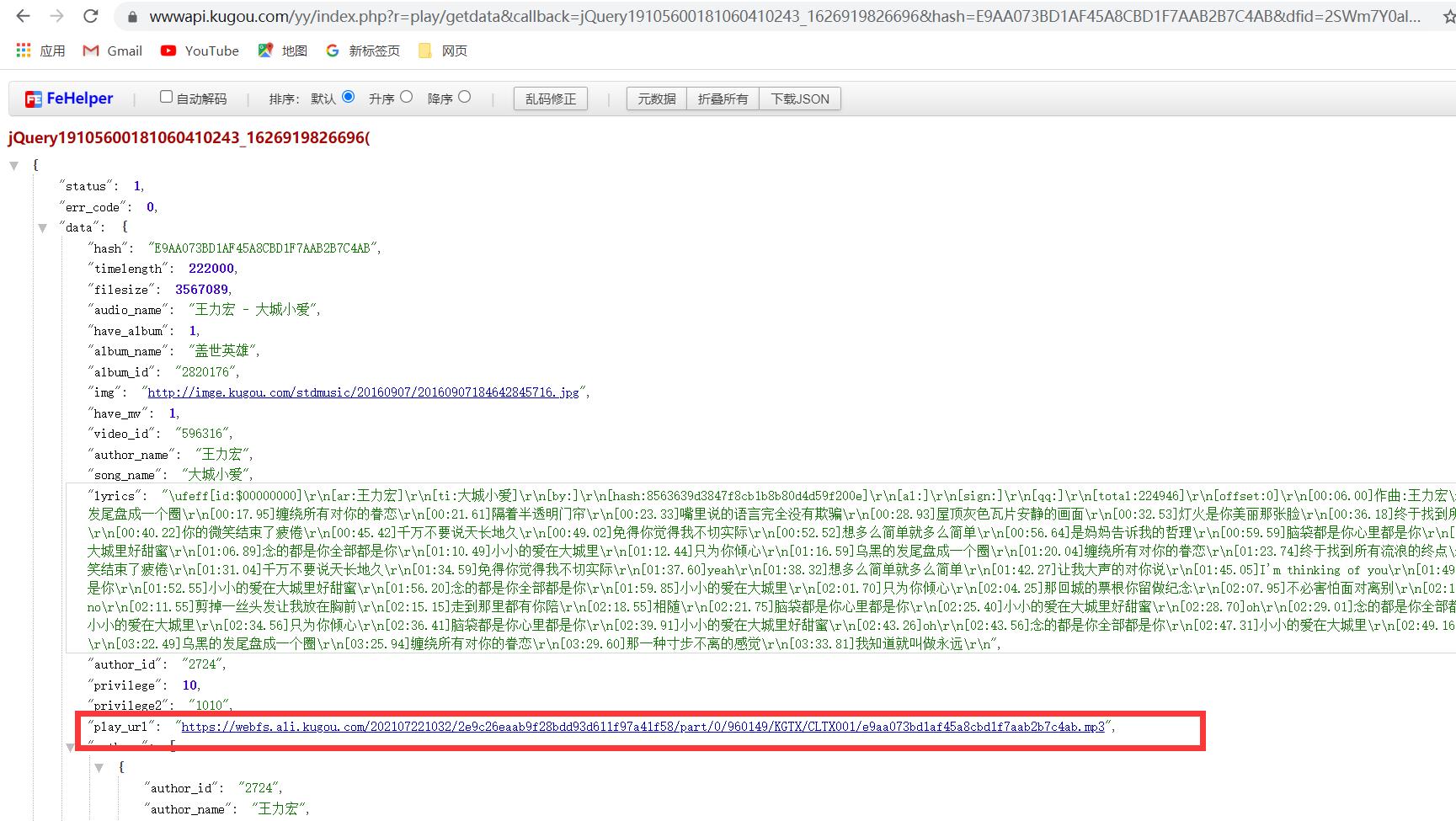
通过分析发现mp3文件在data中,所有需要将data提取出来
至此所有的分析都完成了,可以直接上代码了
1.3、代码实现
import requests
import json
import re
url = "https://searchrecommend.kugou.com/get/complex?callback=jQuery112409589811716312686_1626852436130&word=周杰伦&_=1626852436132"
headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70",
"referer": "https://www.kugou.com/"
resp = requests.get(url, headers=headers)
p1 = re.compile(r'jQuery.*?[(].*?"data":.*?"song":(.*?),"correctiontip"', re.S)
songs = re.findall(p1, resp.text)[0]
songs = json.loads(songs)
for song in songs:
title = song['songname']
AlbumID = song['AlbumID']
song_hash = song['hash']
child_url = f"https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191053318263960215_1626866592344&hash=song_hash&dfid=1tXkst0i97Rq4RW0pz15GjrP&mid=3196606d7d3ff0207a473da58e0b44b3&platid=4&album_id=AlbumID&_=1626866592346"
child_resp = requests.get(child_url, headers=headers)
child_resp.encoding="utf-8"
obj = re.compile(r'jQuery.*?[(].*?"data":(.*?)[)]', re.S)
child_song = re.findall(obj, child_resp.text)[0]
child_song = child_song.replace("\\\\", "")
child_song_src = json.loads(child_song)["play_url"]
child_song_resp = requests.get(child_song_src)
with open("音乐/"+title+".mp3", mode="wb") as f:
f.write(child_song_resp.content)
print(title+"下载完成!!!")
print("okok")
1.4、运行结果
下载周杰伦的歌,改变url去查询你喜欢的歌手
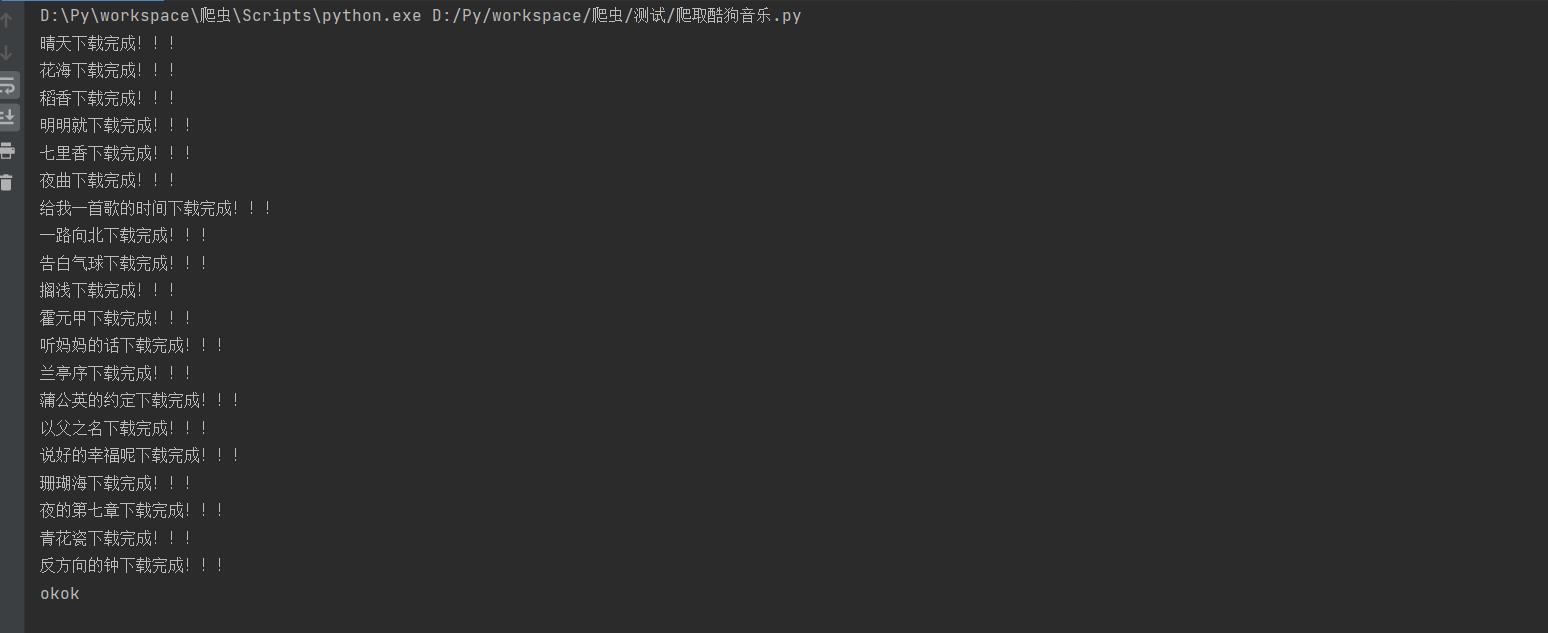
因为网页版只有20首歌,所以就只有这么多
在本地文件中查看
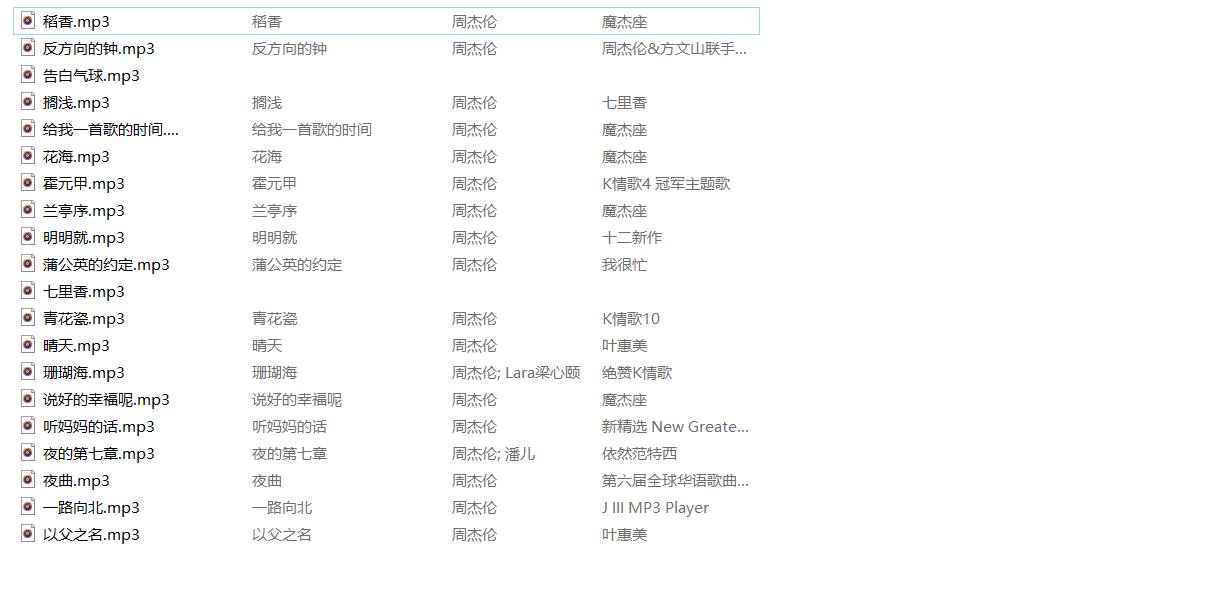
测试完成,歌曲下载成功
以上是关于python爬虫下载音乐?的主要内容,如果未能解决你的问题,请参考以下文章