openstack虚拟机热迁移和冷迁移的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openstack虚拟机热迁移和冷迁移的区别相关的知识,希望对你有一定的参考价值。
参考技术A 就是一个关机迁移,一个不关机迁移。OpenStack迁移虚拟机流程分析
在OpenStack中,虚拟机的迁移类似分为三种,分别是冷迁移、热迁移和故障迁移。
1.冷迁移
实现原理:使用原来所需的资源在目标节点上重新创建一个虚拟机。
云主机冷迁移流程图:
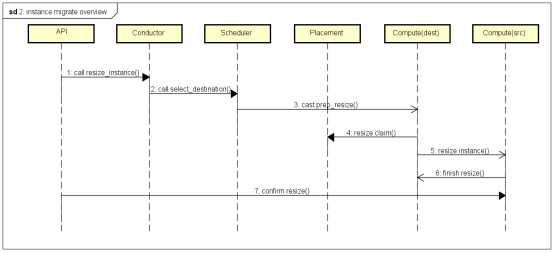
更详细的过程图:
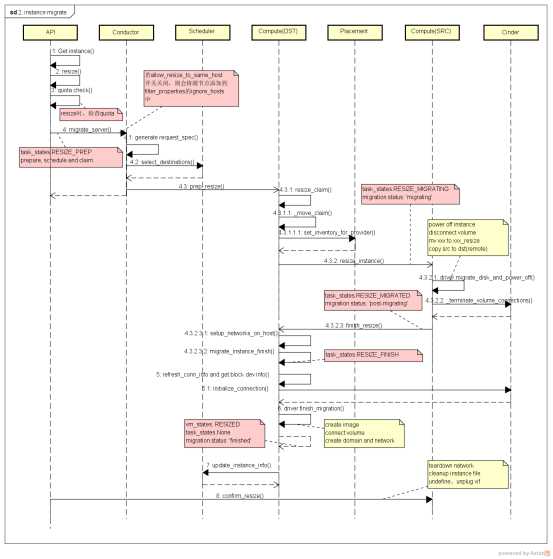
发起云主机冷迁移后,首先调用到的是nova/api/openstack/compute/migrate_server.py的_migrate函数:
@wsgi.response(202) @extensions.expected_errors((400, 403, 404, 409)) @wsgi.action(‘migrate‘) def _migrate(self, req, id, body): """Permit admins to migrate a server to a new host.""" context = req.environ[‘nova.context‘] context.can(ms_policies.POLICY_ROOT % ‘migrate‘) host = body["migrate"]["host"] instance = common.get_instance(self.compute_api, context, id) try: self.compute_api.resize(req.environ[‘nova.context‘], instance, host=host) ........
这里的核心代码是调用到了resize函数,openstack本身还有个resize功能,它的作用是对云主机的配置进行升级,但只能往上升,冷迁移的流程跟resize工作流程一样,只不过是flavor没有发生改变。实现代码是在nova/compute/api.py:
@check_instance_lock @check_instance_cell @check_instance_state(vm_state=[vm_states.ACTIVE, vm_states.STOPPED]) def resize(self, context, instance, flavor_id=None, clean_shutdown=True, host=None, **extra_instance_updates): # 检查flavor是否是新flavor,如果是resize则进行配额预留分配、修改虚拟机的状态、 # 提交迁移记录和生成目的宿主机需满足的条件对象specrequest ........ self.compute_task_api.resize_instance(context, instance, extra_instance_updates, scheduler_hint=scheduler_hint, flavor=new_instance_type, reservations=quotas.reservations or [], clean_shutdown=clean_shutdown, request_spec=request_spec, host=host)
这里的核心是调用resize_instance函数进行处理,该函数实现在nova/conductor/api.py,该函数再调用了nova/conductor/rpcapi.py文件中的migrate_server函数:
def migrate_server(self, context, instance, scheduler_hint, live, rebuild, flavor, block_migration, disk_over_commit, reservations=None, clean_shutdown=True, request_spec=None, host=None): # 根据版本号构建kw参数 return cctxt.call(context, ‘migrate_server‘, **kw)
通过远程调用conductor进程的migrate_server函数,此时进入nova/conductor/manage.py文件中的migrate_server函数:
def migrate_server(self, context, instance, scheduler_hint, live, rebuild, flavor, block_migration, disk_over_commit, reservations=None, clean_shutdown=True, request_spec=None, host=None): # 一些条件判断,判断是进行冷迁移还是热迁移 if not live and not rebuild and flavor: # 冷迁移走这个逻辑 instance_uuid = instance.uuid with compute_utils.EventReporter(context, ‘cold_migrate‘, instance_uuid): self._cold_migrate(context, instance, flavor, scheduler_hint[‘filter_properties‘], reservations, clean_shutdown, request_spec, host=host) else: raise NotImplementedError()
核心代码是调用了_cold_migrate函数:
@wrap_instance_event(prefix=‘conductor‘) def _cold_migrate(self, context, instance, flavor, filter_properties, reservations, clean_shutdown, request_spec, host=None): image = utils.get_image_from_system_metadata( instance.system_metadata) task = self._build_cold_migrate_task(context, instance, flavor, request_spec, reservations, clean_shutdown, host=host) task.execute()
构建迁移任务,然后执行任务:
def _build_cold_migrate_task(self, context, instance, flavor, request_spec, reservations, clean_shutdown, host=None): # nova/conductor/tasks/migrate.py return migrate.MigrationTask(context, instance, flavor, request_spec, reservations, clean_shutdown, self.compute_rpcapi, self.scheduler_client, host=host)
这里是返回了MigrationTask类实例,该类继承的TaskBase基类的execute函数会调用_execute函数,所以我们直接看该MigrationTask类的execute函数实现即可:
def _execute(self): # 选择一个宿主机 self.compute_rpcapi.prep_resize( self.context, self.instance, legacy_spec[‘image‘], self.flavor, host, self.reservations, request_spec=legacy_spec, filter_properties=legacy_props, node=node, clean_shutdown=self.clean_shutdown)
这里调用到了nova/compute/rpcapi.py中的prep_resize函数:
def prep_resize(self, ctxt, instance, image, instance_type, host, reservations=None, request_spec=None, filter_properties=None, node=None, clean_shutdown=True): image_p = jsonutils.to_primitive(image) msg_args = {‘instance‘: instance, ‘instance_type‘: instance_type, ‘image‘: image_p, ‘reservations‘: reservations, ‘request_spec‘: request_spec, ‘filter_properties‘: filter_properties, ‘node‘: node, ‘clean_shutdown‘: clean_shutdown} version = ‘4.1‘ client = self.router.by_host(ctxt, host) if not client.can_send_version(version): version = ‘4.0‘ msg_args[‘instance_type‘] = objects_base.obj_to_primitive( instance_type) cctxt = client.prepare(server=host, version=version) # 远程调用到宿主机上让其准备将要迁移过去的虚拟机的资源 cctxt.cast(ctxt, ‘prep_resize‘, **msg_args)
这里远程调用到了nova/compute/manager.py中的prep_resize函数,该函数的核心代码是调用了_prep_resize:
def _prep_resize(self, context, image, instance, instance_type, quotas, request_spec, filter_properties, node, clean_shutdown=True): ......... rt = self._get_resource_tracker() # 这里进行了资源的检查和预留分配并更新数据库宿主机更新后的资源 with rt.resize_claim(context, instance, instance_type, node, image_meta=image, limits=limits) as claim: LOG.info(_LI(‘Migrating‘), instance=instance) self.compute_rpcapi.resize_instance( context, instance, claim.migration, image, instance_type, quotas.reservations, clean_shutdown)
分配好资源后调用self.compute_rpcapi.resize_instance函数:
def resize_instance(self, ctxt, instance, migration, image, instance_type, reservations=None, clean_shutdown=True): msg_args = {‘instance‘: instance, ‘migration‘: migration, ‘image‘: image, ‘reservations‘: reservations, ‘instance_type‘: instance_type, ‘clean_shutdown‘: clean_shutdown, } version = ‘4.1‘ client = self.router.by_instance(ctxt, instance) if not client.can_send_version(version): msg_args[‘instance_type‘] = objects_base.obj_to_primitive( instance_type) version = ‘4.0‘ cctxt = client.prepare(server=_compute_host(None, instance), version=version) # 到源主机的nova/compute/manager.py中执行resize_instance函数 cctxt.cast(ctxt, ‘resize_instance‘, **msg_args)
进入源主机的resize_instance函数中:
def resize_instance(self, context, instance, image, reservations, migration, instance_type, clean_shutdown): # 获取要迁移的云主机网卡信息 # 修改数据库云主机状态 # 迁移事件通知 # 关机并进行磁盘迁移 disk_info = self.driver.migrate_disk_and_power_off( context, instance, migration.dest_host, instance_type, network_info, block_device_info, timeout, retry_interval) # 开始为虚拟机迁移网络 self.network_api.migrate_instance_start(context, instance, migration_p) self.compute_rpcapi.finish_resize(context, instance, migration, image, disk_info, migration.dest_compute, reservations=quotas.reservations)
此时远程调用目的主机的finish_resize函数:
def finish_resize(self, context, disk_info, image, instance, reservations, migration): # 提交配额 ..... self._finish_resize(context, instance, migration, disk_info, image_meta) def _finish_resize(self, context, instance, migration, disk_info, image_meta): # 初始化网络 self.network_api.setup_networks_on_host(context, instance, migration[‘dest_compute‘]) migration_p = obj_base.obj_to_primitive(migration) self.network_api.migrate_instance_finish(context, instance, migration_p) # 获取当前云主机的网络信息 network_info = self.network_api.get_instance_nw_info(context, instance) # 更新数据库状态 instance.task_state = task_states.RESIZE_FINISH instance.save(expected_task_state=task_states.RESIZE_MIGRATED) # nova/virt/libvirt/driver.py self.driver.finish_migration(context, migration, instance, disk_info, network_info, image_meta, resize_instance, block_device_info, power_on)
最后还要再出发一次confirm resize函数完成整个冷迁移过程,该函数是确认在源主机上删除云主机的数据和网络数据等,函数文件在nova/api/openstack/compute/servers.py:
@wsgi.action(‘confirmResize‘) def _action_confirm_resize(self, req, id, body): self.compute_api.confirm_resize(context, instance) def confirm_resize(self, context, instance, migration=None): """Confirms a migration/resize and deletes the ‘old‘ instance.""" # 修改迁移状态和更新配额 ...... self.compute_rpcapi.confirm_resize(context, instance, migration, migration.source_compute, quotas.reservations or [])
@wsgi.action(‘confirmResize‘) def _action_confirm_resize(self, req, id, body): self.compute_api.confirm_resize(context, instance) def confirm_resize(self, context, instance, migration=None): """Confirms a migration/resize and deletes the ‘old‘ instance.""" # 修改迁移状态和更新配额 ...... self.compute_rpcapi.confirm_resize(context, instance, migration, migration.source_compute, quotas.reservations or [])
通过rpc调用到源宿主机上进行confirm_resize,这函数中比较核心的部分是调用了_confirm_resize函数:
def _confirm_resize(self, context, instance, quotas, migration=None): """Destroys the source instance.""" self._notify_about_instance_usage(context, instance, "resize.confirm.start") # NOTE(tr3buchet): tear down networks on source host # 断掉网络 self.network_api.setup_networks_on_host(context, instance, migration.source_compute, teardown=True) network_info = self.network_api.get_instance_nw_info(context, instance) # TODO(mriedem): Get BDMs here and pass them to the driver. # 删除虚拟机 self.driver.confirm_migration(context, migration, instance, network_info) # 更新迁移状态 migration.status = ‘confirmed‘ with migration.obj_as_admin(): migration.save() # 更新资源 rt = self._get_resource_tracker() rt.drop_move_claim(context, instance, migration.source_node, old_instance_type, prefix=‘old_‘) instance.drop_migration_context()
2.热迁移
实现原理:热迁移与冷迁移工作流程类似,但热迁移由于是在运行中迁移,进行了比较多的兼容性判断,比如两个宿主机之间的cpu兼容性等。热迁移其实并非没有业务中断,只是在迁移的最后时刻,虚拟机会有短暂挂起,快速完成最后一次内存复制。
影响热迁移的关键因素有两个:
(1)虚拟机内存脏页的速度,迭代复制是以页为单位的;
(2)网络带宽,如果脏页的速度远大于迭代复制内存页的速度,在一段时间内迁移是不成功的。
libvirtd数据迁移逻辑:
(1)标记所有的脏内存;
(2)传输所有的脏内存,然后开始重新计算新产生的脏内存,如此迭代,知道某一个条件退出;
(3)暂停虚拟机,传输剩余数据;
第(2)步的某个条件可以是:
(1)50%或者更少的内存需要迁移;
(2)迭代次数不超过多少次;
热迁移流程图:
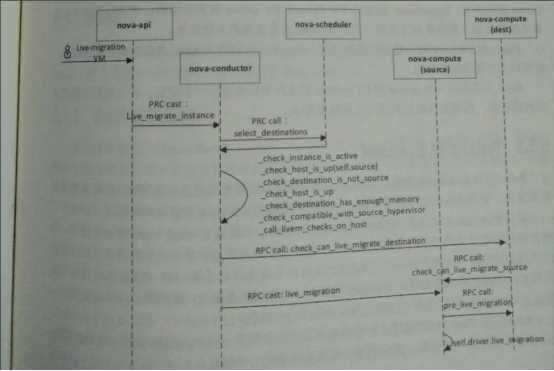
发起热迁移请求后,nova中的入口函数是nova-api的migrate_server.py文件中的_migrate_live函数:
@wsgi.action(‘os-migrateLive‘) @validation.schema(migrate_server.migrate_live, "2.0", "2.24") @validation.schema(migrate_server.migrate_live_v2_25, "2.25", "2.29") @validation.schema(migrate_server.migrate_live_v2_30, "2.30") def _migrate_live(self, req, id, body): self.compute_api.live_migrate(context, instance, block_migration, disk_over_commit, host, force, async)
调用到nova/compute/api.py中:
def live_migrate(self, context, instance, block_migration, disk_over_commit, host_name, force=None, async=False): # 修改虚拟机状态 # 生成request_spec ...... # nova/conductor/api.py self.compute_task_api.live_migrate_instance(context, instance, host_name, block_migration=block_migration, disk_over_commit=disk_over_commit, request_spec=request_spec, async=async)
live_migrate_instance又调用到了同级下的rpcapi.py中的live_migrate_instance函数:
def live_migrate_instance(self, context, instance, scheduler_hint, block_migration, disk_over_commit, request_spec): kw = {‘instance‘: instance, ‘scheduler_hint‘: scheduler_hint, ‘block_migration‘: block_migration, ‘disk_over_commit‘: disk_over_commit, ‘request_spec‘: request_spec, } version = ‘1.15‘ cctxt = self.client.prepare(version=version) # 交到conductor进程中处理 cctxt.cast(context, ‘live_migrate_instance‘, **kw) @wrap_instance_event(prefix=‘conductor‘) def live_migrate_instance(self, context, instance, scheduler_hint, block_migration, disk_over_commit, request_spec): self._live_migrate(context, instance, scheduler_hint, block_migration, disk_over_commit, request_spec) def _live_migrate(self, context, instance, scheduler_hint, block_migration, disk_over_commit, request_spec): destination = scheduler_hint.get("host") # 初始化一个热迁移任务跟踪对象 migration = objects.Migration(context=context.elevated()) migration.dest_compute = destination migration.status = ‘accepted‘ migration.instance_uuid = instance.uuid migration.source_compute = instance.host migration.migration_type = ‘live-migration‘ if instance.obj_attr_is_set(‘flavor‘): migration.old_instance_type_id = instance.flavor.id migration.new_instance_type_id = instance.flavor.id else: migration.old_instance_type_id = instance.instance_type_id migration.new_instance_type_id = instance.instance_type_id migration.create() # 创建热迁移任务 task = self._build_live_migrate_task(context, instance, destination, block_migration, disk_over_commit, migration, request_spec) task.execute() def _build_live_migrate_task(self, context, instance, destination, block_migration, disk_over_commit, migration, request_spec=None): # nova/conductor/tasks/live_migrate.py return live_migrate.LiveMigrationTask(context, instance, destination, block_migration, disk_over_commit, migration, self.compute_rpcapi, self.servicegroup_api, self.scheduler_client, request_spec)
我们可以直接看nova/conductor/tasks/live_migrate.py文件中的类LiveMigrationTask中的_execute函数实现:
def _execute(self): # 检查云主机是否active状态 self._check_instance_is_active() # 检查源主机宿主机是否可用状态 self._check_host_is_up(self.source) # 如果没有指定目的主机,则调用scheduler去选择合适的目的主机 if not self.destination: self.destination = self._find_destination() self.migration.dest_compute = self.destination self.migration.save() else: # 如果指定了还需要对它做一些条件检查,判断是否目的主机满足热迁移 self._check_requested_destination() # TODO(johngarbutt) need to move complexity out of compute manager # TODO(johngarbutt) disk_over_commit? return self.compute_rpcapi.live_migration(self.context, host=self.source, instance=self.instance, dest=self.destination, block_migration=self.block_migration, migration=self.migration, migrate_data=self.migrate_data) def _check_requested_destination(self): # 确保源主机和宿主机不是同一物理主机 self._check_destination_is_not_source() # 检查目的主机是否可用 self._check_host_is_up(self.destination) # 检查目的主机是否有足够的内存 self._check_destination_has_enough_memory() # 检查两个源主机和宿主机之间是否兼容 self._check_compatible_with_source_hypervisor(self.destination) # 检查下是否可以对目的主机执行热迁移操作 self._call_livem_checks_on_host(self.destination)
其中_call_livem_checks_on_host函数会远程调用到目的主机上去执行check_can_live_migrate_destination函数来检验目的主机是否满足热迁移,同时目的主机也会远程调用check_can_live_migrate_source函数检查源主机是否支持热迁移。
def _do_check_can_live_migrate_destination(self, ctxt, instance, block_migration, disk_over_commit): src_compute_info = obj_base.obj_to_primitive(self._get_compute_info(ctxt, instance.host)) dst_compute_info = obj_base.obj_to_primitive(self._get_compute_info(ctxt, CONF.host)) # nova/virt/libvirt/driver.py dest_check_data = self.driver.check_can_live_migrate_destination(ctxt, instance, src_compute_info, dst_compute_info, block_migration, disk_over_commit) LOG.debug(‘destination check data is %s‘, dest_check_data) try: # 远程调用回源主机上检查源主机是否可热迁移 migrate_data = self.compute_rpcapi. check_can_live_migrate_source(ctxt, instance, dest_check_data) finally: # 删除一些检查时产生的临时文件 self.driver.cleanup_live_migration_destination_check(ctxt, dest_check_data) return migrate_data
接着便是调用到了nova/compute/rpcapi.py中的live_migration函数,该函数远程调用了nova-compute服务的live_migrate方法,交给nova-compute服务来进行处理:
def live_migration(self, context, dest, instance, block_migration, migration, migrate_data): self._do_live_migration(*args, **kwargs) def _do_live_migration(self, context, dest, instance, block_migration, migration, migrate_data): # nova/compute/rpcapi.py migrate_data = self.compute_rpcapi.pre_live_migration( context, instance, block_migration, disk, dest, migrate_data) self.driver.live_migration(context, instance, dest, self._post_live_migration, self._rollback_live_migration, block_migration, migrate_data)
_do_live_migration函数中的核心代码是pre_live_migration和live_migration的调用。先看pre_live_migration函数,其是远程调用到目的主机上执行pre_live_migration函数:
def pre_live_migration(self, context, instance, block_migration, disk, migrate_data): block_device_info = self._get_instance_block_device_info( context, instance, refresh_conn_info=True) network_info = self.network_api.get_instance_nw_info(context, instance) self._notify_about_instance_usage( context, instance, "live_migration.pre.start", network_info=network_info) # 做连接上磁盘和挂载上网络的工作等 migrate_data = self.driver.pre_live_migration(context, instance, block_device_info, network_info, disk, migrate_data) LOG.debug(‘driver pre_live_migration data is %s‘, migrate_data) # NOTE(tr3buchet): setup networks on destination host # 初始化好网络 self.network_api.setup_networks_on_host(context, instance, self.host) # Creating filters to hypervisors and firewalls. # An example is that nova-instance-instance-xxx, # which is written to libvirt.xml(Check "virsh nwfilter-list") # This nwfilter is necessary on the destination host. # In addition, this method is creating filtering rule # onto destination host. # 在热迁移进行前在目的主机上创建好那些网络过滤规则 self.driver.ensure_filtering_rules_for_instance(instance, network_info)
在目的主机上执行完pre_live_migration函数后,源主机上调用live_migration开始执行热迁移操作,调用到nova/virt/libvirt/driver.py中的live_migration函数,再调用到_live_migration函数:
def _live_migration(self, context, instance, dest, post_method, recover_method, block_migration, migrate_data): opthread = utils.spawn(self._live_migration_operation, context, instance, dest, block_migration, migrate_data, guest, device_names) self._live_migration_monitor(context, instance, guest, dest, post_method, recover_method, block_migration, migrate_data, finish_event, disk_paths)
这里主要有两个核心调用,一个是_live_migration_operation进行迁移操作,一个是调用_live_migration_monitor函数用以监控迁移进度。
def _live_migration_operation(self, context, instance, dest, block_migration, migrate_data, guest, device_names): # 里面调用libvirt的api来实现迁移 # nova/virt/libvirt/guest.py guest.migrate(self._live_migration_uri(dest), migrate_uri=migrate_uri, flags=migration_flags, params=params, domain_xml=new_xml_str, bandwidth=CONF.libvirt.live_migration_bandwidth) def migrate(self, destination, migrate_uri=None, params=None, flags=0, domain_xml=None, bandwidth=0): # 调用了libvirt的python接口virDomainMigrateToURI来实现从当前云主机迁移domain对象到给定的目标主机 if domain_xml is None: self._domain.migrateToURI( destination, flags=flags, bandwidth=bandwidth) else: if params: if migrate_uri: # In migrateToURI3 this paramenter is searched in # the `params` dict params[‘migrate_uri‘] = migrate_uri self._domain.migrateToURI3( destination, params=params, flags=flags) else: self._domain.migrateToURI2( destination, miguri=migrate_uri, dxml=domain_xml, flags=flags, bandwidth=bandwidth)
_live_migration_monitor的主要实现则是调用了libvirt的job_info函数获取进度情况。
实现原理:根据在数据库中保存的配置,重新生成一个一样的云主机,前提是需要能访问到故障云主机的磁盘数据,所以使用共享存储可以实现云主机故障迁移。
函数代码文件:nova/api/openstack/compute/evacuate.py
发起故障迁移请求后进入的函数是:
def _evacuate(self, req, id, body): """Permit admins to evacuate a server from a failed host to a new one. """ self.compute_api.evacuate(context, instance, host, on_shared_storage, password, force)
执行nova/compute/api.py中的evacuate函数:
def evacuate(self, context, instance, host, on_shared_storage, admin_password=None, force=None): # 检查源宿主机是否可用,可用则停止继续执行 # 修改云主机状态和生成request_spec ..... # nova/conductor/api.py return self.compute_task_api.rebuild_instance(context, instance=instance, new_pass=admin_password, injected_files=None, image_ref=None, orig_image_ref=None, orig_sys_metadata=None, bdms=None, recreate=True, on_shared_storage=on_shared_storage, host=host, request_spec=request_spec, )
通过rpc调用会直接调用到目的宿主机的nova/compute/manager.py中的rebuild_instance的方法进行处理:
def rebuild_instance(self, context, instance, orig_image_ref, image_ref, injected_files, new_pass, orig_sys_metadata, bdms, recreate, on_shared_storage=None, preserve_ephemeral=False, migration=None, scheduled_node=None, limits=None): # 获取物理主机资源 # 获取镜像元数据 self._do_rebuild_instance_with_claim( claim_ctxt, context, instance, orig_image_ref, image_ref, injected_files, new_pass, orig_sys_metadata, bdms, recreate, on_shared_storage, preserve_ephemeral)
_do_rebuild_instance_with_claim函数会调用到_do_rebuild_instance函数:
def _do_rebuild_instance(self, context, instance, orig_image_ref, image_ref, injected_files, new_pass, orig_sys_metadata, bdms, recreate, on_shared_storage, preserve_ephemeral): orig_vm_state = instance.vm_state # 传进来的recreate和on_shared_storage参数都是true # 检查是否是共享存储 ..... if recreate: # nova/network/api.py # 设置主机上的网络 self.network_api.setup_networks_on_host( context, instance, self.host) # For nova-network this is needed to move floating IPs # For neutron this updates the host in the port binding # TODO(cfriesen): this network_api call and the one above # are so similar, we should really try to unify them. self.network_api.setup_instance_network_on_host( context, instance, self.host) network_info = compute_utils.get_nw_info_for_instance(instance) # 获取云主机磁盘信息 if bdms is None: bdms = objects.BlockDeviceMappingList.get_by_instance_uuid( context, instance.uuid) block_device_info = self._get_instance_block_device_info( context, instance, bdms=bdms) def detach_block_devices(context, bdms): for bdm in bdms: if bdm.is_volume: self._detach_volume(context, bdm.volume_id, instance, destroy_bdm=False) files = self._decode_files(injected_files) kwargs = dict( context=context, instance=instance, image_meta=image_meta, injected_files=files, admin_password=new_pass, bdms=bdms, detach_block_devices=detach_block_devices, attach_block_devices=self._prep_block_device, block_device_info=block_device_info, network_info=network_info, preserve_ephemeral=preserve_ephemeral, recreate=recreate) try: # 避免错误的资源追踪 with instance.mutated_migration_context(): # libvirt驱动没有重载rebuild函数,因此会调用到下面的_rebuild_default_impl默认实现 self.driver.rebuild(**kwargs) except NotImplementedError: # NOTE(rpodolyaka): driver doesn‘t provide specialized version # of rebuild, fall back to the default implementation # 处理磁盘断开连接和重新连接后,最后调用self.driver.spawn重新生成一个云主机 self._rebuild_default_impl(**kwargs) # 生成成功后更新云主机在数据库中的状态数据 self._update_instance_after_spawn(context, instance) instance.save(expected_task_state=[task_states.REBUILD_SPAWNING]) if orig_vm_state == vm_states.STOPPED: LOG.info(_LI("bringing vm to original state: ‘%s‘"), orig_vm_state, instance=instance) instance.vm_state = vm_states.ACTIVE instance.task_state = task_states.POWERING_OFF instance.progress = 0 instance.save() self.stop_instance(context, instance, False) self._update_scheduler_instance_info(context, instance) self._notify_about_instance_usage( context, instance, "rebuild.end", network_info=network_info, extra_usage_info=extra_usage_info)
以上是关于openstack虚拟机热迁移和冷迁移的区别的主要内容,如果未能解决你的问题,请参考以下文章