SQL SERVER 2008 如何将字符集更改为UTF-8
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL SERVER 2008 如何将字符集更改为UTF-8相关的知识,希望对你有一定的参考价值。
如题
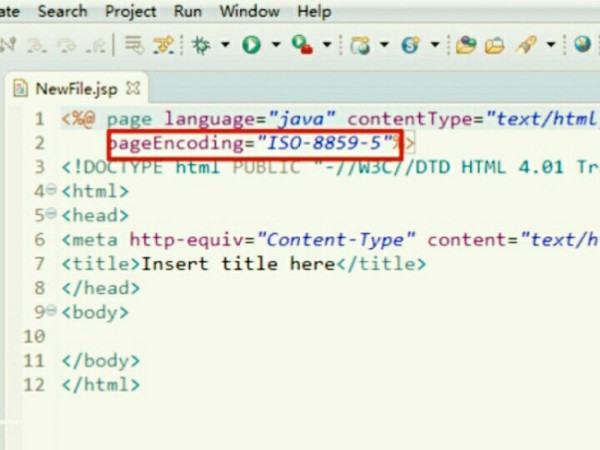
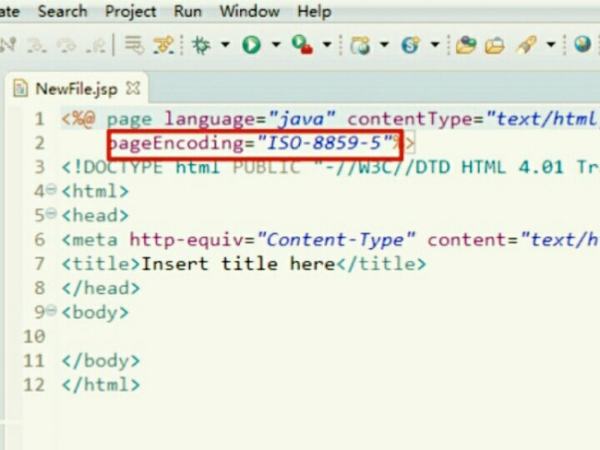
1.直接打开SQLSERVER2008的相关窗口,会看到字符集为ISO-8859-5,如下图。
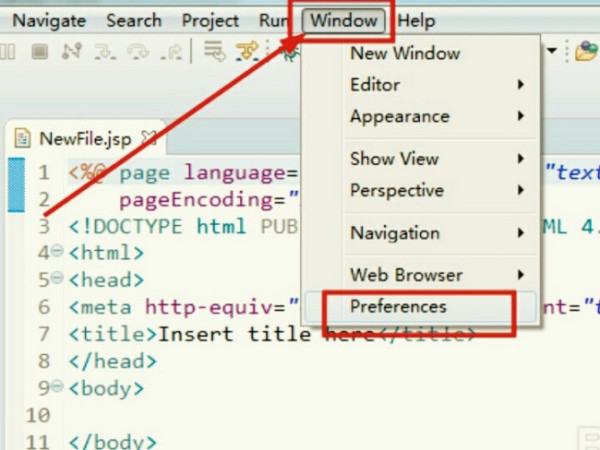
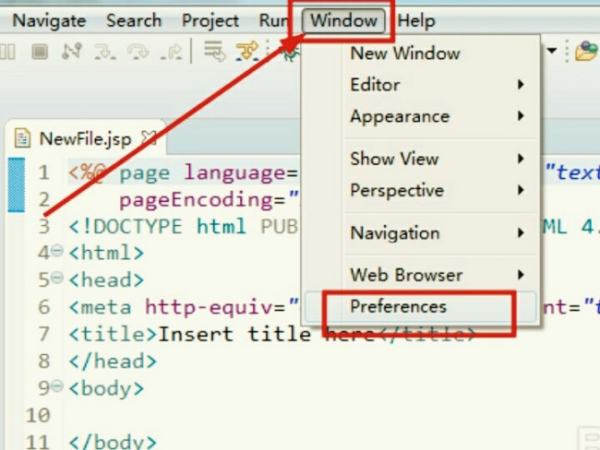
2.如果下一步是好的,继续并点击首选项跳转到窗口。
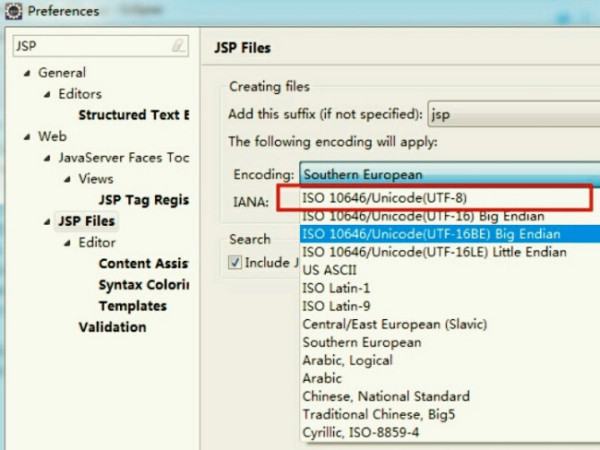
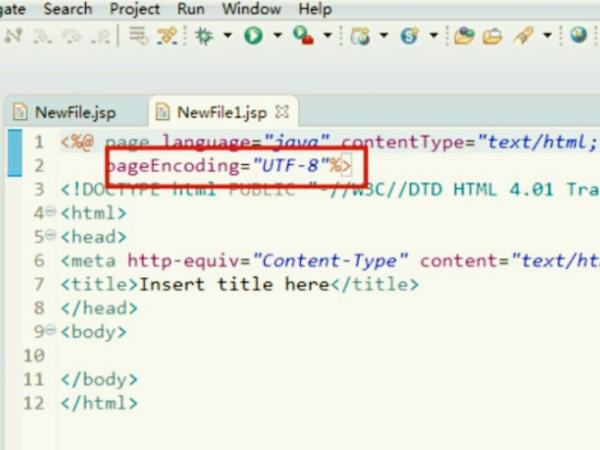
3.这时,一个新的对话框弹出。您需要选择编码为utf-8并确认更改。
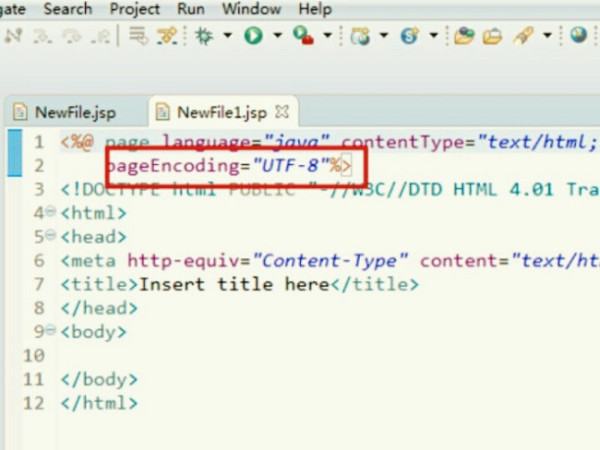
4.通过这种方式,当找到图的结果时,就可以达到目的。
属性设置。
在 SQL Server 中,下列数据类型支持 Unicode 数据:
nchar
nvarchar
ntext
Unicode 常量以 N 开头指定:N'A Unicode string'。
创建新数据库时,可以使用下列内容之一指定排序规则:
CREATE DATABASE 语句的 COLLATE 子句。
SQL Server Management Studio.
SQL 管理对象 (SMO) 中的 Database.Collation 属性。
如果未指定排序规则,则使用服务器排序规则。
可以使用 ALTER DATABASE 语句的 COLLATE 子句来更改在用户数据库中创建的任何新对象的排序规则。使用此语句不能更改任何现有用户定义的表中列的排序规则。使用 ALTER TABLE 的 COLLATE 子句可以更改这些列的排序规则。

扩展资料:
UCS字符U+0000到U+007F(ASCII)被编码为字节0×00到0x7F(ASCIⅡ兼容)。这意味着只包含7位ASCIl字符的文件在ASCIⅡ和UTF-8两种编码方式下是一样的。
所有大于0x007F的UCS字符被编码为一个有多个字节的串,每个字节都有标记位集。因此,ASCIl字节(0x00-0x7F)不可能作为任何其他字符的一部分。表示非ASCIl字符的多字节串的第一个字节总是在0xC0到0XFD的范围里,并指出这个字符包含多少个字节。多字节串的其余字节都在0x80到0xBF范围里。这使得重新同步非常容易,并使编码无国界,且很少受丢失字节的影响。
参考资料来源:百度百科-UTF-8
参考技术B1、直接打开SQL SERVER 2008的相关窗口,会看到字符集为ISO-8859-5。
2、下一步如果没问题,就继续在Window那里点击Preferences进行跳转。
3、这个时候弹出新的对话框,需要将编码选择为UTF-8并确定更改。

4、这样一来等发现图示的结果以后,即可达到目的了。
SELECT SERVERPROPERTY ('Collation')
查看你的排序规则.
不过你的这个应该和字符集有关.
2.更改服务器排序规则
更改 SQL Server 2005 实例的默认排序规则的操作可能会比较复杂,包括以下步骤:
确保具有重新创建用户数据库及这些数据库中的所有对象所需的全部信息或脚本。
使用工具(例如大容量复制)导出所有数据。
删除所有用户数据库。
重新生成在 setup 命令的 SQLCOLLATION 属性中指定新的排序规则的 master 数据库。例如:
复制代码
start /wait setup.exe /qb INSTANCENAME=MSSQLSERVER REINSTALL=SQL_Engine REBUILDDATABASE=1 SAPWD=test SQLCOLLATION=SQL_Latin1_General_CP1_CI_AI
有关重新生成 master 数据库的详细信息,请参阅如何重新生成 SQL Server 2005 的 Master 数据库。
创建所有数据库及这些数据库中的所有对象。
导入所有数据。
注意:
可以为创建的每个新数据库指定默认排序规则,而不更改 SQL Server 2005 实例的默认排序规则。
3.设置和更改数据库排序规则
创建新数据库时,可以使用下列内容之一指定排序规则:
CREATE DATABASE 语句的 COLLATE 子句。
SQL Server Management Studio.
SQL 管理对象 (SMO) 中的 Database.Collation 属性。
如果未指定排序规则,则使用服务器排序规则。
可以使用 ALTER DATABASE 语句的 COLLATE 子句来更改在用户数据库中创建的任何新对象的排序规则。使用此语句不能更改任何现有用户定义的表中列的排序规则。使用 ALTER TABLE 的 COLLATE 子句可以更改这些列的排序规则。
更改数据库排序规则时,需要更改下列内容:
数据库的默认排序规则,这一新的默认排序规则将应用于数据库中后续创建的所有列、用户定义的数据类型、变量和参数。根据数据库中定义的对象解析 SQL 语句中指定的对象标识符时,也使用新的默认排序规则。
将系统表中的任何 char、varchar、text、nchar、nvarchar 或 ntext 列更改为使用新的排序规则。
将存储过程和用户定义函数的所有现有 char、varchar、text、nchar、nvarchar 或 ntext 参数和标量返回值更改为使用新的排序规则。
将 char、varchar、text、nchar、nvarchar 或 ntext 系统数据类型和基于这些系统数据类型的所有用户定义的数据类型更改为使用新的默认排序规则。
SQL code :
1.将数据库的字符集修改为:
alter database dbname collate Chinese_PRC_CI_AS
2.
--1. 为数据库指定排序规则
CREATE DATABASE db COLLATE Chinese_PRC_CI_AS
GO
ALTER DATABASE db COLLATE Chinese_PRC_BIN
GO
/*====================================*/
--2. 为表中的列指定排序规则
CREATE TABLE tb(
col1 varchar(10),
col2 varchar(10) COLLATE Chinese_PRC_CI_AS)
GO
ALTER TABLE tb ADD col3 varchar(10) COLLATE Chinese_PRC_BIN
GO
ALTER TABLE tb ALTER COLUMN col2 varchar(10) COLLATE Chinese_PRC_BIN
GO
/*====================================*/
--3. 为字符变量和参数应用排序规则
DECLARE @a varchar(10),@b varchar(10)
SELECT @a='a',@b='A'
--使用排序规则 Chinese_PRC_CI_AS
SELECT CASE WHEN @a COLLATE Chinese_PRC_CI_AS = @b THEN '@a=@b' ELSE '@a<>@b' END
--结果:@a=@b
--使用排序规则 Chinese_PRC_BIN
SELECT CASE WHEN @a COLLATE Chinese_PRC_BIN = @b THEN '@a=@b' ELSE '@a<>@b' END
--结果:@a<>@b
3.
表
ALTER TABLE tb
ALTER COLUMN colname nvarchar(100) COLLATE Chinese_PRC_CI_AS
--不区分大小写
ALTER TABLE tb
ALTER COLUMN colname nvarchar(100) COLLATE Chinese_PRC_CS_AS
--区分大小写
数据库
ALTER DATABASE database
COLLATE Chinese_PRC_CS_AS
--区分大小写
ALTER DATABASE database COLLATE Chinese_PRC_CI_AS --不区分大小写
方法一.安装SQL时选择区分大小写
或安装完以后重建mastar,选择区分大小
C:\Program Files\Microsoft SQL Server\80\Tools\Binn\rebuildm.exe
方法二.sql server 8.0以上的版本才可以,7.0及其以下不支持
alter database 数据库 COLLATE Chinese_PRC_CS_AS
修改排序规则,改成大小写敏感的排序规则
如果只修改一个表,用alter table语句
如果修改一个库的默认排序规则,用alter datebase语句
如果修改整个服务器的默认排序规则,用Rebuildm.exe重建master库
--指定排序规则就可以了
--示例
select replace('AbacB' collate Chinese_PRC_CS_AS_WS,'B','test')
--如果你是要求表支持,则可以建表时指定排序规则,这样replace就不用写排序规则了
--示例
create table tb(a varchar(20) collate Chinese_PRC_CS_AS_WS)
insert tb values('Abac')
select replace(a,'a','test') from tb
drop table tb
指定排序规则即可
Windows 排序规则名称
在 COLLATE 子句中指定 Windows 排序规则名称。Windows 排序规则名称由排序规则指示器和比较风格构成。
语法
< Windows_collation_name > :: =
CollationDesignator_ <ComparisonStyle>
< ComparisonStyle > ::=
CaseSensitivity_AccentSensitivity
[_KanatypeSensitive [_WidthSensitive ] ]
| _BIN
参数
CollationDesignator
指定 Windows 排序规则使用的基本排序规则。基本排序规则包括:
当指定按字典排序时应用其排序规则的字母表或语言
用于存储非 Unicode 字符数据的代码页。
例如 Latin1_General 或法文,两者都使用代码页 1252,或土耳其文,它使用代码页 1254。
CaseSensitivity
CI 指定不区分大小写,CS 指定区分大小写。
AccentSensitivity
AI 指定不区分重音,AS 指定区分重音。
KanatypeSensitive
Omitted 指定不区分大小写,KS 指定区分假名类型。
WidthSensitivity
Omitted 指定不区分大小写,WS 指定区分大小写。
BIN
指定使用二进制排序次序。
如果你只是目前查询区分,那么还是不要这样改,免得又反悔,如此查询:
select * from a
/*
a_nam a_add
---------- ----------
1 aa
1 bb
2 cc
2 vv
2 kk
3 dd
3 ee
4 dd
5 ee
6 yy
6 yy
(11 row(s) affected)
*/
现在我们查询a_add = 'aa'的,'Aa'等等不行!
Example 1:
select * from a
where a_add collate Chinese_PRC_CS_AS_WS = 'aa'
/*
a_nam a_add
---------- ----------
1 aa
(1 row(s) affected)
*/
Example 2:
select * from a
where a_add collate Chinese_PRC_CS_AS_WS = 'Aa'
/*
a_nam a_add
---------- ----------
(0 row(s) affected)
*/
方法三.上面的记不住,那么就用最笨的方法,转化为ascii
select * from a
where
ascii(substring(a_add,1,1)) = ascii(substring('Aa',1,1))
and
ascii(substring(a_add,2,1)) = ascii(substring('Aa',2,1))
/*
a_nam a_add
---------- ----------
(0 row(s) affected)
*/
方法三:任何版本都可以
select * from a
where cast(a_add as varbinary(10))= cast('aa' as varbinary(10))本回答被提问者采纳
如何将此编码从 SQL Server 更改为在 PostgreSQL [关闭]
【中文标题】如何将此编码从 SQL Server 更改为在 PostgreSQL [关闭]【英文标题】:How to change this coding from SQL Server to be in PostgreSQL [closed] 【发布时间】:2020-10-25 01:30:02 【问题描述】:此查询使用 Microsoft SQL Server Management Studio 成功运行,但我无法在 PostgreSQL 中使用它。我想要一个类似的查询来使用 PostgreSQL 给出相同的结果 请注意:这将在包含 1 个初级和 2 个高级的表上运行。 如果我有更多的大三和大四,我也想使用这个查询
DECLARE @Budget Int = 50000, @Seniors int = 0, @Juniors int = 0, @SeniorSalary int = 20000, @juniorSalary int = 10000
WHILE @Budget >= @juniorSalary
BEGIN
IF @Budget >= @SeniorSalary
BEGIN
SET @Budget = @Budget - @SeniorSalary;
SET @Seniors = @Seniors + 1;
END
ELSE IF @Budget >= @juniorSalary
BEGIN
SET @Budget = @Budget - @juniorSalary;
SET @Juniors = @Juniors + 1;
END
END
SELECT @Seniors AS [Seniors], @Juniors as [Juniors], @Budget As [RemainingBudget]
【问题讨论】:
我会先修复你的 T-SQL,这意味着摆脱WHILE。 SQL 不是一种编程语言,它是一种查询语言;将其视为查询语言并使用基于集合的方法。
这不是免费的代码编写或数据库迁移服务。你试过什么?您在哪里遇到问题?
PostgreSQL中不能使用"WHILE"和"DECLARE"的问题
为什么你首先要使用WHILE?
"这将在包含 1 个初级和 2 个高级的表上运行。" - 您的示例中没有表
【参考方案1】:
您的第一个错误是假设某些东西在 SQL Server 中运行,它将 Postgres(或任何其他 DBMS)来自那个的所有流。此外,它不是查询而是脚本,psql 脚本的结构与 T-sql 脚本完全不同。我建议您花大量时间学习一些 Postgres 教程,例如 command line tutorial 和 PostgreSQLTutorial 和/或其他或 !gasp! 旧技术 - 一本书。
我很欣赏有时一个概念问题,比如期望 T-Sql 脚本在 Postgres 中运行。因此,我提供以下内容作为一次性演示,为您指明正确的方向。它是您脚本的 Postgres 翻译,当然不是唯一的,也可能不是最好的。
我把它的描述留给你研究。
create or replace
function developer_budget
( budget integer
, seniorsalary integer
, juniorsalary integer
)
returns table ( seniors integer
, juniors integer
, remaining integer
)
language plpgsql
as $$
declare
seniors integer = 0;
juniors integer = 0;
begin
while budget >= juniorsalary
loop
if budget >= seniorsalary then
budget = budget - seniorsalary;
seniors = seniors + 1;
elsif budget >= juniorsalary then
budget = budget - juniorsalary;
juniors = juniors + 1;
end if;
end loop;
return query select seniors,juniors, budget;
end;
$$;
select seniors "Seniors"
, juniors "Juniors"
, remaining "Remaining bubjet"
from developer_budget( Budget => 50000
, SeniorSalary => 20000
, JuniorSalary => 10000
);
【讨论】:
以上是关于SQL SERVER 2008 如何将字符集更改为UTF-8的主要内容,如果未能解决你的问题,请参考以下文章