自编码器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自编码器相关的知识,希望对你有一定的参考价值。
参考技术A 自编码器是输入神经元数等于输出神经元数的神经网络。自编码器由两部分组成:1.编码器:从输入层到隐层, 它可以用一个编码函数 表示;
2.解码器:从隐层到输出层,重构输入。 它可以用解码函数 表示。
完整的自编码器为:
如果隐层神经元数小于输入层神经元数,这样的自编码器称为欠完备或不完备自编码器。
1)自编码器可用于降维;
2)自编码器可作为强大的特征检测器(feature detectors),应用于深度神经网络的预训练;
3)自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型(generative model);
4)数据压缩
普通自编码器是具有一个隐藏层的三层网络,输入和输出神经元数是相同的,用于学习如何重构输入,例如使用adam优化器和均方误差损失函数。
在这里,我们看到我们有一个欠完备自编码器,因为隐藏层维(64)小于输入(784)。 这个约束将强加我们的神经网络来学习压缩的数据表示。
也称为栈式自编码器(Stacked Autoencoders)或深度自编码器。如果一个隐藏层不够用,我们显然可以将自编码器扩展到更多的隐藏层。 任何隐藏层都可以作为特征表示,但我们将使网络结构对称并使用最中间的隐藏层。
我们也可能会问自己:自编码器可以用于卷积层而不是全连接层吗?
答案是肯定的,原理是一样的,但使用图像(3D矢量)而不是平坦的1维矢量。 对输入图像进行下采样以提供较小尺寸的隐藏表示并强制自编码器学习图像的压缩版本。
还有其他一些方法可以限制自编码器的重构,而不是简单地强加一个维度比输入小的隐藏层。 正规化自编码器不是通过调整编码器和解码从而限制模型容量,而是使用损失函数,鼓励模型学习除了将输入复制到其输出之外的其他属性。 在实践中,我们通常会发现两种正规化自编码器:稀疏自编码器和去噪自编码器。
稀疏自编码器:稀疏自编码器通常用于学习分类等其他任务的特征。 稀疏自编码器必须响应数据集独特的统计特征,而不仅仅是作为标识函数。 通过这种方式,用稀疏性惩罚来执行复制任务的训练可以产生有用的特征模型。
我们可以限制自编码器重构的另一种方式是对损失函数施加约束。 例如,我们可以在损失函数中添加一个修正术语。 这样做会使我们的自编码器学习数据的稀疏表示
注意在我们的正则项中,我们添加了一个l1激活函数正则器,它将在优化阶段对损失函数应用一个惩罚。 在结果上,与正常普通自编码器相比,该表示现在更稀松。
我们可以获得一个自编码器,通过改变损失函数的重构误差项来学习一些有用的东西,而不是对损失函数加以惩罚。 这可以通过给输入图像添加一些噪声并使自编码器学会移除噪声从而来进行训练。 通过这种方式,编码器将提取最重要的特征并学习数据的更鲁棒的表示。
多层自编码器的微调
多层自编码器由多个稀疏自编码器和一个Softmax分类器构成;(其中,每个稀疏自编码器的权值可以利用无标签训练样本得到, Softmax分类器参数可由有标签训练样本得到)多层自编码器微调是指将多层自编码器看做是一个多层的神经网络,利用有标签的训练样本集,对该神经网络的权值进行调整。
1多层自编码器的结构
多层自编码器的结构如图1所示,它包含一个具有2个隐藏层的栈式自编码器和1个softmax模型;栈式自编码器的最后一个隐藏层的输出作为softmax模型的输入,softmax模型的输出作为整个网络的输出(输出的是条件概率向量)。
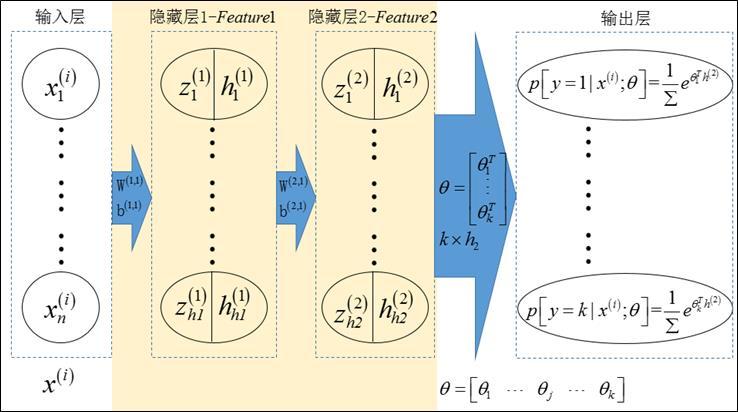
图1 多层自编码器的结构
微调多层自编码器的流程图如图2所示,该流程主要包括三部分:
(1)初始化待优化参数向量
(2)调用最优化函数,计算最优化参数向量
(3)得到最优化参数向量,可以转换为网络各结构所对应的参数
其中,最小化代价函数主要利用minFunc函数,该优化函数格式如下:

可知,为了实现优化过程,最为关键问题就是编写stackedAECost函数
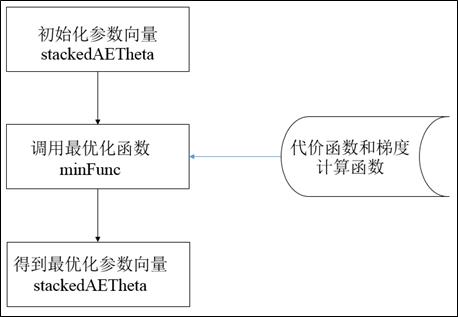
图2 多层自编码器的微调流程
2整个网络参数的初始化
整个网络的参数stackedAETheta(列向量形式)由两部分组成:softmax分类器参数向量+稀疏自编码器参数向量;他们的初始化值由稀疏自编码和softmax学习获得:
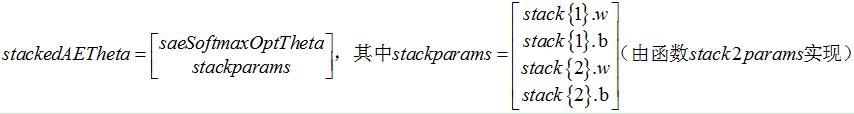

3 stackedAECost函数
3.1稀疏自编码器部分的激励值
3.1.1 稀疏自编码器部分的结构图
多层网络的稀疏自编码器部分如下图所示
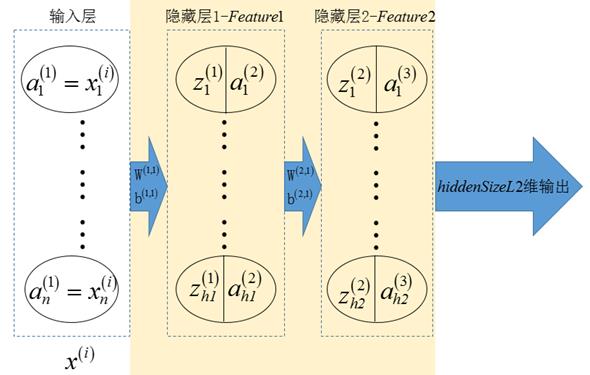
图3 多层网络的稀疏自编码器部分
3.1.2 稀疏自编码器部分各层激励值(输出)
|
单个样本 |
多个样本 |
|
|
|
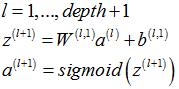
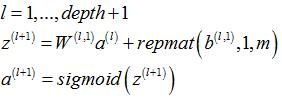
3.1.3 softmax分类器的激励值(输出)
|
单个样本 |
多个样本 |
|
|
|
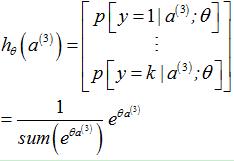
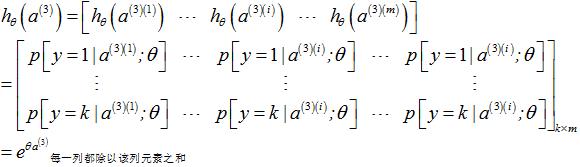
3.1.4 程序

3.2代价函数
3.2.1代价函数的计算公式
该多层网络的代价函数完全按照softmax模型的代价函数计算,并加入正则项,但要注意,这里加入的正则项必须要对整个网络的所有参数进行惩罚!
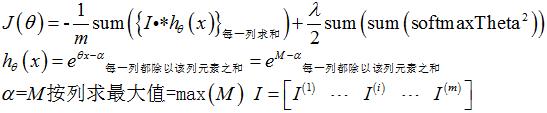
3.2.2程序如下

3.3梯度计算
3.3.1 softmax模型
该模型的梯度计算与单独使用softmxa模型的公式是相同的,即:
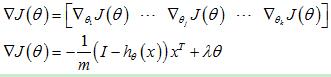
只不过这里的x为softmax自编码器最后一层的输出h(2)。

3.1.2 stack自编码器各层
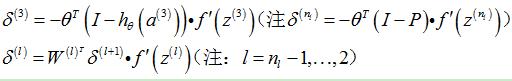
|
单个样本 |
多个样本 |
|
|
|
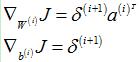
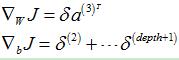
3.3.3 整个网络的梯度
最后,将整个网络的梯度(softmaxThetaGrad和stackgrad)存放在一个列向量中

以上是关于自编码器的主要内容,如果未能解决你的问题,请参考以下文章