Redis02 Redis客户端之Java
Posted 寻渝记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis02 Redis客户端之Java相关的知识,希望对你有一定的参考价值。
1 查看支持Java的redis客户端
本博文采用 Jedis 作为redis客户端,采用 commons-pool2 作为连接redis服务器的连接池
2 下载相关依赖与实战
2.1 到 Repository 官网下载jar包
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-pool2 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.5.0</version> </dependency>
2.2 传统使用(eclipse)
准备:创建一个普通的Java项目
2.2.1 添加jar包
在项目的根目录下创建一个lib文件夹,并将下载好的两个jar包添加到lib文件夹里面

2.2.2 将jar包添加到项目构建路径中
选中lib中的jar包 -> 右键 -> build path -> add to build path
2.2.3 在build path中查看
项目文件夹 -> 右键 -> build path -> configure build path
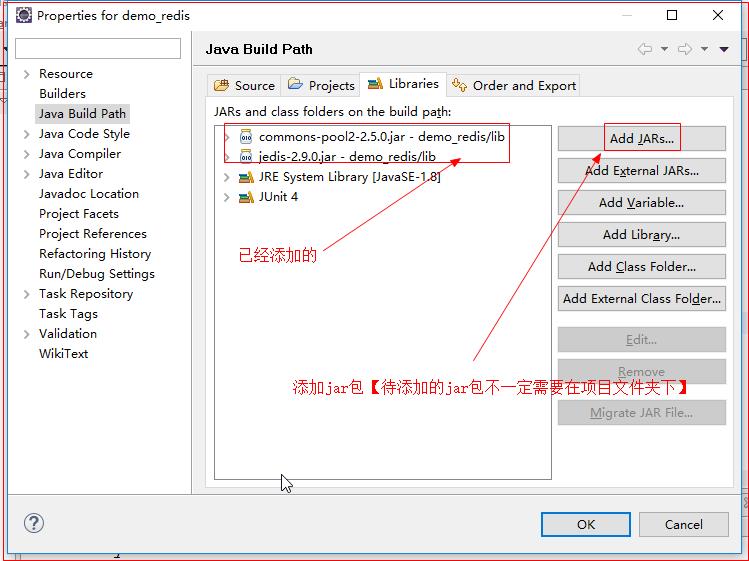
技巧01:也可以在 build path中进行添加【ps: 待添加的jar包可以在任何位置,不用将他们放到项目文件夹下的lib中,我这样做的目的是为了避免jar包被不小心删除掉】
2.3 代码实现
借助 Jedis 去对 Redis 进行操作
技巧01:其实和操作mysql的套路一样
2.3.1 单实例模式
就是不使用连接池的模式,每次要对 Redis 进行操作时先自己创建连接,在进行相关操作,操作完后自己在关闭连接;这样很消耗内存


@Test public void test01() { System.out.println("Hello Boy"); // 01 获取Jedis客户端【设置IP和端口】 Jedis jedis = new Jedis("192.168.233.134", 6379); // 02 保存数据 jedis.set("name", "王杨帅"); // 03 获取数据 String value = jedis.get("name"); System.out.println("获取到的数据为:" + value); String age = jedis.get("age"); System.out.println("获取到的年龄信息为:" + age); // 04 释放资源 jedis.close(); }
2.3.2 连接池模式
就是在项目启动时先创建一些连接,谁需要操作 Redis 时就直接拿一个空闲的连接过去就可以啦,用完再还回去即可;这样就避免了连接的重复创建和销毁,从而减少了内存的消耗。
/** * 使用连接池的方式 */ @Test public void demo02() { System.out.println("Hello Warrior"); // 01 获取连接池对象 JedisPoolConfig config = new JedisPoolConfig(); // 0101 最大连接数 config.setMaxTotal(30); // 0102 最大空闲连接数 config.setMaxIdle(10); // 02 获取连接池 JedisPool jedisPool = new JedisPool(config, "192.168.233.133", 6379); // 03 核心对象【获取Jedis客户端对象】 Jedis jedis = null; try { // 0301 通过连接池获取Jedis客户端 jedis = jedisPool.getResource(); // 0302 设置数据 jedis.set("name", "三少"); // 0303 获取数据 String value = jedis.get("name"); System.out.println(value); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (jedis != null) { jedis.close(); } if (jedisPool != null) { jedisPool.close(); } } }
package cn.xinagxu.jedis; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; /** * Jedis测试 * @author a * */ public class JedisDemo01 { /** * 单实例的测试 */ @Test public void test01() { System.out.println("Hello Boy"); // 01 获取Jedis客户端【设置IP和端口】 Jedis jedis = new Jedis("192.168.233.134", 6379); // 02 保存数据 jedis.set("name", "王杨帅"); // 03 获取数据 String value = jedis.get("name"); System.out.println("获取到的数据为:" + value); String age = jedis.get("age"); System.out.println("获取到的年龄信息为:" + age); // 04 释放资源 jedis.close(); } /** * 使用连接池的方式 */ @Test public void demo02() { System.out.println("Hello Warrior"); // 01 获取连接池对象 JedisPoolConfig config = new JedisPoolConfig(); // 0101 最大连接数 config.setMaxTotal(30); // 0102 最大空闲连接数 config.setMaxIdle(10); // 02 获取连接池 JedisPool jedisPool = new JedisPool(config, "192.168.233.133", 6379); // 03 核心对象【获取Jedis客户端对象】 Jedis jedis = null; try { // 0301 通过连接池获取Jedis客户端 jedis = jedisPool.getResource(); // 0302 设置数据 jedis.set("name", "三少"); // 0303 获取数据 String value = jedis.get("name"); System.out.println(value); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (jedis != null) { jedis.close(); } if (jedisPool != null) { jedisPool.close(); } } } }
3 传统使用(IDEA)
准备:新建一个普通的Java项目
3.1 添加jar文件
在项目的根目录下创建一个lib目录,将下载好的两个jar包复制到lib文件夹里面

3.2 将jar文件添加到项目的构建目录中
选中相应的jar包 -> 右键 -> add as library
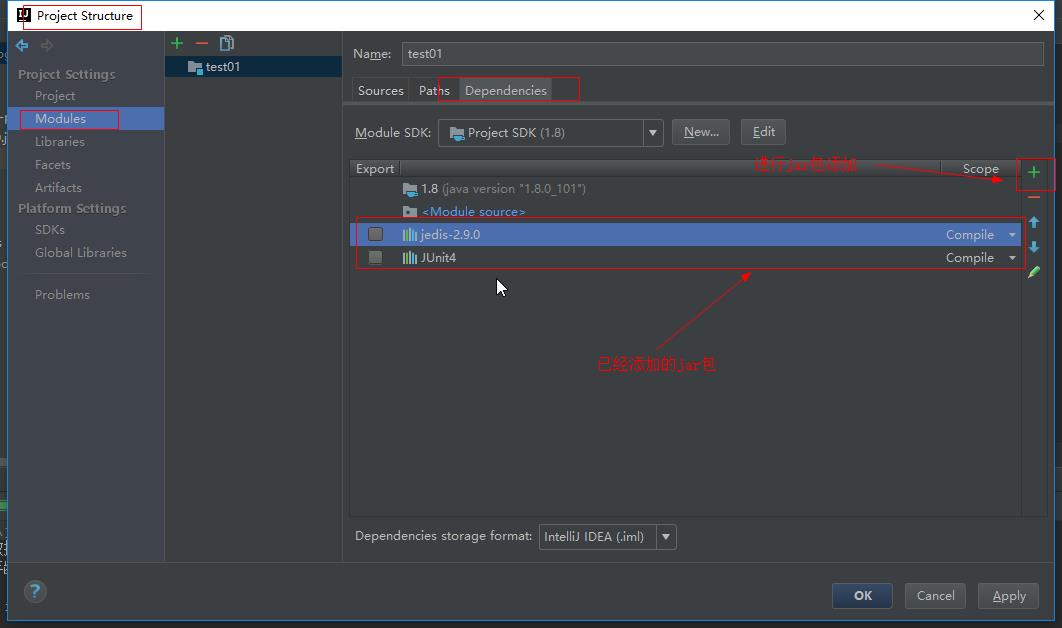
3.3 查看添加的jar包
file -> project structure -> modules -> dependencies
技巧01:peoject structure中也可以进行jar包的添加
3.4 代码实现
package hello; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; /** * @author 王杨帅 * @create 2018-06-23 21:39 * @desc **/ public class RedisTest { @Test public void test01() { // 01 获取Jedis客户端【设置IP和端口】 Jedis jedis = new Jedis("192.168.233.134", 6379); // 02 保存数据 jedis.set("name", "王杨帅"); // 03 获取数据 String value = jedis.get("name"); System.out.println("获取到的数据为:" + value); String age = jedis.get("age"); System.out.println("获取到的年龄信息为:" + age); // 04 释放资源 jedis.close(); } /** * 使用连接池的方式 */ @Test public void demo02() { System.out.println("Hello Warrior"); // 01 获取连接池对象 JedisPoolConfig config = new JedisPoolConfig(); // 0101 最大连接数 config.setMaxTotal(30); // 0102 最大空闲连接数 config.setMaxIdle(10); // 02 获取连接池 JedisPool jedisPool = new JedisPool(config, "192.168.233.133", 6379); // 03 核心对象【获取Jedis客户端对象】 Jedis jedis = null; try { // 0301 通过连接池获取Jedis客户端 jedis = jedisPool.getResource(); // 0302 设置数据 jedis.set("name", "三少"); // 0303 获取数据 String value = jedis.get("name"); System.out.println(value); } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } finally { if (jedis != null) { jedis.close(); } if (jedisPool != null) { jedisPool.close(); } } } }
4 利用 jedis 客户端时出现的Bug
4.1 Redis 服务端拒接连接
原因:Redis 服务端默认只用本机才可以连接
解决:修改 redis.conf 配置文件 -> 将 bind 127.0.0.1 注释掉即可
4.2 Redis 服务端开启了保护模式,拒绝外网访问
原因:Redis是在守护状态下运行
解决:修改 redis.conf 配置文件 -> 将 protected-mode 后面的 yes 改为 no 即可
4.3 修改后的 redis.conf 配置文件
# Redis configuration file example. # # Note that in order to read the configuration file, Redis must be # started with the file path as first argument: # # ./redis-server /path/to/redis.conf # Note on units: when memory size is needed, it is possible to specify # it in the usual form of 1k 5GB 4M and so forth: # # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes # # units are case insensitive so 1GB 1Gb 1gB are all the same. ################################## INCLUDES ################################### # Include one or more other config files here. This is useful if you # have a standard template that goes to all Redis servers but also need # to customize a few per-server settings. Include files can include # other files, so use this wisely. # # Notice option "include" won\'t be rewritten by command "CONFIG REWRITE" # from admin or Redis Sentinel. Since Redis always uses the last processed # line as value of a configuration directive, you\'d better put includes # at the beginning of this file to avoid overwriting config change at runtime. # # If instead you are interested in using includes to override configuration # options, it is better to use include as the last line. # # include /path/to/local.conf # include /path/to/other.conf ################################## NETWORK ##################################### # By default, if no "bind" configuration directive is specified, Redis listens # for connections from all the network interfaces available on the server. # It is possible to listen to just one or multiple selected interfaces using # the "bind" configuration directive, followed by one or more IP addresses. # # Examples: # # bind 192.168.1.100 10.0.0.1 # bind 127.0.0.1 ::1 # # ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the # internet, binding to all the interfaces is dangerous and will expose the # instance to everybody on the internet. So by default we uncomment the # following bind directive, that will force Redis to listen only into # the IPv4 lookback interface address (this means Redis will be able to # accept connections only from clients running into the same computer it # is running). # # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES # JUST COMMENT THE FOLLOWING LINE. # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #bind 127.0.0.1 # Protected mode is a layer of security protection, in order to avoid that # Redis instances left open on the internet are accessed and exploited. # # When protected mode is on and if: # # 1) The server is not binding explicitly to a set of addresses using the # "bind" directive. # 2) No password is configured. # # The server only accepts connections from clients connecting from the # IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain # sockets. # # By default protected mode is enabled. You should disable it only if # you are sure you want clients from other hosts to connect to Redis # even if no authentication is configured, nor a specific set of interfaces # are explicitly listed using the "bind" directive. protected-mode no # Accept connections on the specified port, default is 6379 (IANA #815344). # If port 0 is specified Redis will not listen on a TCP socket. port 6379 # TCP listen() backlog. # # In high requests-per-second environments you need an high backlog in order # to avoid slow clients connections issues. Note that the Linux kernel # will silently truncate it to the value of /proc/sys/net/core/somaxconn so # make sure to raise both the value of somaxconn and tcp_max_syn_backlog # in order to get the desired effect. tcp-backlog 511 # Unix socket. # # Specify the path for the Unix socket that will be used to listen for # incoming connections. There is no default, so Redis will not listen # on a unix socket when not specified. # # unixsocket /tmp/redis.sock # unixsocketperm 700 # Close the connection after a client is idle for N seconds (0 to disable) timeout 0 # TCP keepalive. # # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence # of communication. This is useful for two reasons: # # 1) Detect dead peers. # 2) Take the connection alive from the point of view of network # equipment in the middle. # # On Linux, the specified value (in seconds) is the period used to send ACKs. # Note that to close the connection the double of the time is needed. # On other kernels the period depends on the kernel configuration. # # A reasonable value for this option is 300 seconds, which is the new # Redis default starting with Redis 3.2.1. tcp-keepalive 300 ################################# GENERAL ##################################### # By default Redis does not run as a daemon. Use \'yes\' if you need it. # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. daemonize yes # If you run Redis from upstart or systemd, Redis can interact with your # supervision tree. Options: # supervised no - no supervision interaction # supervised upstart - signal upstart by putting Redis into SIGSTOP mode # supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET # supervised auto - detect upstart or systemd method based on # UPSTART_JOB or NOTIFY_SOCKET environment variables # Note: these supervision methods only signal "process is ready." # They do not enable continuous liveness pings back to your supervisor. supervised no # If a pid file is specified, Redis writes it where specified at startup # and removes it at exit. # # When the server runs non daemonized, no pid file is created if none is # specified in the configuration. When the server is daemonized, the pid file # is used even if not specified, defaulting to "/var/run/redis.pid". # # Creating a pid file is best effort: if Redis is not able to create it # nothing bad happens, the server will start and run normally. pidfile /var/run/redis_6379.pid # Specify the server verbosity level. # This can be one of: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably) # warning (only very important / critical messages are logged) loglevel notice # Specify the log file name. Also the empty string can be used to force # Redis to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null logfile "" # To enable logging to the system logger, just set \'syslog-enabled\' to yes, # and optionally update the other syslog parameters to suit your needs. # syslog-enabled no # Specify the syslog identity. # syslog-ident redis # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. # syslog-facility local0 # Set the number of databases. The default database is DB 0, you can select # a different one on a per-connection basis using SELECT <dbid> where # dbid is a number between 0 and \'databases\'-1 databases 16 ################################ SNAPSHOTTING ################################ # # Save the DB on disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving completely by commenting out all "save" lines. # # It is also possible to remove all the previously configured save # points by adding a save directive with a single empty string argument # like in the following example: # # save "" save 900 1 save 300 10 save 60 10000 # By default Redis will stop accepting writes if RDB snapshots are enabled # (at least one save point) and the latest background save failed. # This will make the user aware (in a hard way) that data is not persisting # on disk properly, otherwise chances are that no one will notice and some # disaster will happen. # # If the background saving process will start working again Redis will # automatically allow writes again. # # However if you have setup your proper monitoring of the Redis server # and persistence, you may want to disable this feature so that Redis will # continue to work as usual even if there are problems with disk, # permissions, and so forth. stop-writes-on-bgsave-error yes # Compress string objects using LZF when dump .rdb databases? # For default that\'s set to \'yes\' as it\'s almost always a win. # If you want to save some CPU in the saving child set it to \'no\' but # the dataset will likely be bigger if you have compressible values or keys. rdbcompression yes # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. # This makes the format more resistant to corruption but there is a performance # hit to pay (around 10%) when saving and loading RDB files, so you can disable it # for maximum performances. # # RDB files created with checksum disabled have a checksum of zero that will # tell the loading code to skip the check. rdbchecksum yes # The filename where to dump the DB dbfilename dump.rdb # The working directory. # # The DB will be written inside this directory, with the filename specified # above using the \'dbfilename\' configuration directive. # # The Append Only File will also be created inside this directory. # # Note that you must specify a directory here, not a file name. dir ./ ################################# REPLICATION ################################# # Master-Slave replication. Use slaveof to make a Redis instance a copy of # another Redis server. A few things to understand ASAP about Redis replication. # # 1) Redis replication is asynchronous, but you can configure a master to # stop accepting writes if it appears to be not connected with at least # a given number of slaves. # 2) Redis slaves are able to perform a partial resynchronization with the # master if the replication link is lost for a relatively small amount of # time. You may want to configure the replication backlog size (see the next # sections of this file) with a sensible value depending on your needs. # 3) Replication is automatic and does not need user intervention. After a # network partition slaves automatically try to reconnect to masters # and resynchronize with them. # # slaveof <masterip> <masterport> # If the master is password protected (using the "requirepass" configuration # directive below) it is possible to tell the slave to authenticate before # starting the replication synchronization process, otherwise the master will # refuse the slave request. # # masterauth <master-password> # When a slave loses its connection with the master, or when the replication # is still in progress, the slave can act in two different ways: # # 1) if slave-serve-stale-data is set to \'yes\' (the default) the slave will # still reply to client requests, possibly with out of date data, or the # data set may just be empty if this is the first synchronization. # # 2) if slave-serve-stale-data is set to \'no\' the slave will reply with # an error "SYNC with master in progress" to all the kind of commands # but to INFO and SLAVEOF. # slave-serve-stale-data yes # You can configure a slave instance to accept writes or not. Writing against # a slave instance may be useful to store some ephemeral data (because data # written on a slave will be easily deleted after resync with the master) but # may also cause problems if clients are writing to it because of a # misconfiguration. # # Since Redis 2.6 by default slaves are read-only. # # Note: read only slaves are not designed to be exposed to untrusted clients # on the internet. It\'s just a protection layer against misuse of the instance. # Still a read only slave exports by default all the administrative commands # such as CONFIG, DEBUG, and so forth. To a limited extent you can improve # security of read only slaves using \'rename-command\' to shadow all the # administrative / dangerous commands. slave-read-only yes # Replication SYNC strategy: disk or socket. # # ------------------------------------------------------- # WARNING: DISKLESS REPLICATION IS EXPERIMENTAL CURRENTLY # ------------------------------------------------------- # # New slaves and reconnecting slaves that are not able to continue the replication # process just receiving differences, need to do what is called a "full # synchronization". An RDB file is transmitted from the master to the slaves. # The transmission can happen in two different ways: # # 1) Disk-backed: The Redis master creates a new process that writes the RDB # file on disk. Later the file is transferred by the parent # process to the slaves incrementally. # 2) Diskless: The Redis master creates a new process that directly writes the # RDB file to slave sockets, without touching the disk at all. # # With disk-backed replication, while the RDB file is generated, more slaves # can be queued and served with the RDB file as soon as the current child producing # the RDB file finishes its work. With diskless replication instead once # the transfer starts, new slaves arriving will be queued and a new transfer # will start when the current one terminates. # # When diskless replication is used, the master waits a configurable amount of # time (in seconds) before starting the transfer in the hope that multiple slaves # will arrive and the transfer can be parallelized. # # With slow disks and fast (large bandwidth) networks, diskless replication # works better. repl-diskless-sync no # When diskless replication is enabled, it is possible to configure the delay # the server waits in order to spawn the child that transfers the RDB via socket # to the slaves. # # This is important since once the transfer starts, it is not possible to serve # new slaves arriving, that will be queued for the next RDB transfer, so the server # waits a delay in order to let more slaves arrive. # # The delay is specified in seconds, and by default is 5 seconds. To disable # it entirely just set it to 0 seconds and the transfer will start ASAP. repl-diskless-sync-delay 5 # Slaves send PINGs to server in a predefined interval. It\'s possible to change # this interval with the repl_ping_slave_period option. The default value is 10 # seconds. # # repl-ping-slave-period 10 # The following option sets the replication timeout for: # # 1) Bulk transfer I/O during SYNC, from the point of view of slave. # 2) Master timeout from the point of view of slaves (data, pings). # 3) Slave timeout from the point of view of masters (REPLCONF ACK pings). # # It is important to make sure that this value is greater than the value # specified for repl-ping-slave-period otherwise a timeout will be detected # every time there is low traffic between the master and the slave. # # repl-timeout 60 # Disable TCP_NODELAY on the slave socket after SYNC? # # If you select "yes" Redis will use a smaller number of TCP packets and # less bandwidth to send data to slaves. But this can add a delay for # the data to appear on the slave side, up to 40 milliseconds with # Linux kernels using a default configuration. # # If you select "no" the delay for data to appear on the slave side will # be reduced but more bandwidth will be used for replication. # # By default we optimize for low latency, but in very high traffic conditions # or when the master and slaves are many hops away, turning this to "yes" may # be a good idea. repl-disable-tcp-nodelay no # Set the replication backlog size. The backlog is a buffer that accumulates # slave data when slaves are disconnected for some time, so that when a slave # wants to reconnect again, often a full resync is not needed, but a partial # resync is enough, just passing the portion of data the slave missed while # disconnected. # # The bigger the replication backlog, the longer the time the slave can be # disconnected and later be able to perform a partial resynchronization. # # The backlog is only allocated once there is at least a slave connected. # # repl-backlog-size 1mb # After a master has no longer connected slaves for some time, the backlog # will be freed. The following option configures the amount of seconds that # need to elapse, starting from the time the last slave disconnected, for # the backlog buffer to be freed. # # A value of 0 means to never release the backlog. # # repl-backlog-ttl 3600 # The slave priority is an integer number published by Redis in the INFO output. # It is used by Redis Sentinel in order to select a slave to promote into a # master if the master is no longer working correctly. # # A slave with a low priority number is considered better for promotion, so # for instance if there are three slaves with priority 10, 100, 25 Sentinel will # pick the one with priority 10, that is the lowest. # # However a special priority of 0 marks the slave as not able to perform the # role of master, so a slave with priority of 0 will never be selected by # Redis Sentinel for promotion. # # By default the priority is 100. slave-priority 100 # It is possible for a master to stop accepting writes if there are less than # N slaves connected, having a lag less or equal than M seconds. # # The N slaves need to be in "online" state. # # The lag in seconds, that must be <= the specified value, is calculated from # the last ping received from the slave, that is usually sent every second. # # This option does not GUARANTEE that N replicas will accept the write, but # will limit the window of exposure for lost writes in case not enough slaves # are available, to the specified number of seconds. # # For example to require at least 3 slaves with a lag <= 10 seconds use: # # min-slaves-to-write 3 # min-slaves-max-lag 10 # # Setting one or the other to 0 disables the feature. # # By default min-slaves-to-write is set to 0 (feature disabled) and # min-slaves-max-lag is set to 10. # A Redis master is able to list the address and port of the attached # slaves in different ways. For example the "INFO replication" section # offers this information, which is used, among other tools, by # Redis Sentinel in order to discover slave instances. # Another place where this info is available is in the output of the # "ROLE" command of a masteer. # # The listed IP and address normally reported by a slave is obtained # in the following way: # # IP: The address is auto detected by checking the peer address # of the socket used by the slave to connect with the master. # # Port: The port is communicated by the slave during the replication # handshake, and is normally the port that the slave is using to # list for connections. # # However when port forwarding or Network Address Translation (NAT) is # used, the slave may be actually reachable via different IP and port # pairs. The following two options can be used by a slave in order to # report to its master a specific set of IP and port, so that both INFO # and ROLE will report those values. # # There is no need to use both the options if you need to override just # the port or the IP address. # # slave-announce-ip 5.5.5.5 # slave-announce-port 1234 ################################## SECURITY ################################### # Require clients to issue AUTH <PASSWORD> before processing any other # commands. This might be useful in environments in which you do not trust # others with access to the host running redis-server. # # This should stay commented out for backward compatibility and because most # people do not need auth (e.g. they run their own servers). # # Warning: since Redis is pretty fast an outside user can try up to # 150k passwords per second against a good box. This means that you should # use a very strong password otherwise it will be very easy to break. # # requirepass foobared # Command renaming. # # It is possible to change the name of dangerous commands in a shared # environment. For instance the CONFIG command may be renamed into something # hard to guess so that it will still be available for internal-use tools # but not available for general clients. # # Example: # # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 # # It is also possible to completely kill a command by renaming it into # an empty string: # # rename-command CONFIG "" # # Please note that changing the name of commands that are logged into the # AOF file or transmitted to slaves may cause problems. ################################### LIMITS #################################### # Set the max number of connected clients at the same time. By default # this limit is set to 10000 clients, however if the Redis server is not # able to configure the process file limit to allow for the specified limit # the max number of allowed clients is set to the current file limit # minus 32 (as Redis reserves a few file descriptors for internal uses). # # Once the limit is reached Redis will close all the new connections sending # an error \'max number of clients reached\'. # # maxclients 10000 # Don\'t use more memory than the specified amount of bytes. # When the memory limit is reached Redis will try to remove keys # according to the eviction policy selected (see maxmemory-policy). # # If Redis can\'t remove keys according to the policy, or if the policy is # set to \'noeviction\', Redis will start to reply with errors to commands # that would use more memory, like SET, LPUSH, and so on, and will continue # to reply to read-only commands like GET. # # This option is usually useful when using Redis as an LRU cache, or to set # a hard memory limit for an instance (using the \'noeviction\' policy). # # WARNING: If you have slaves attached to an instance with maxmemory on, # the size of the output buffers needed to feed the slaves are subtracted # from the used memory count, so that network problems / resyncs will # not trigger a loop where keys are evicted, and in turn the output # buffer of slaves is full with DELs of keys evicted triggering the deletion # of more keys, and so forth until the database is completely emptied. # # In short... if you have slaves attached it is suggested that you set a lower # limit for maxmemory so that there is some free RAM on the system for slave # output buffers (but this is not needed if the policy is \'noeviction\'). # # maxmemory <bytes> # MAXMEMORY POLICY: how Redis will select what to remove when maxmemory # is reached. You can select among five behaviors: # # volatile-lru -> remove the key with an expire set using an LRU algorithm # allkeys-lru -> remove any key according to the LRU algorithm # volatile-random -> remove a random key with an expire set # allkeys-random -> remove a random key, any key # volatile-ttl -> remove the key with the nearest expire time (minor TTL) # noeviction -> don\'t expire at all, just return an error on write operations # # Note: with any of the above policies, Redis will return an error on write # operations, when there are no suitable keys for eviction. # # At the date of writing these commands ar以上是关于Redis02 Redis客户端之Java的主要内容,如果未能解决你的问题,请参考以下文章