逻辑回归解决啥问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归解决啥问题相关的知识,希望对你有一定的参考价值。
参考技术A 问题一:逻辑回归和SVM的区别是什么?各适用于解决什么问题 两种方法都是常见的分类算法,从目标函数来看,区别在于逻辑回归采用的是logistical loss,svm采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重.SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器.而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重.两者的根本目的都是一样的.此外,根据需要,两个方法都可以增加不同的正则化项,如l1,l2等等.所以在很多实验中,两种算法的结果是很接近的.但是逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便.而SVM的理解和优化相对来说复杂一些.但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础,虽然一般使用的人不太会去关注.还有很重要的一点,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算
svm 更多的属于非参数模型,而logistic regression 是参数模型,本质不同.其区别就可以参考参数模型和非参模型的区别就好了.
logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了
问题二:逻辑回归适用于什么样的分类问题 两种方法都是常见的分类算法,从目标函数来看,区别在于逻辑回归采用的是logistical loss,svm采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重.SVM的处理方法是只考虑
问题三:哪些问题可以使用logistic回归分析 Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
问题四:逻辑回归 和 朴素贝叶斯 两者间的区别 区别如下:
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
解决这个问题的方法一般是建立一个属性模型,对于不相互独立的属性,把他们单独处理。例如中文文本分类识别的时候,我们可以建立一个字典来处理一些词组。如果发现特定的问题中存在特殊的模式属性,那么就单独处理。
问题五:机器学习中的逻辑回归到底是回归还是分类 逻辑回归:y=sigmoid(w'x)
线性回归:y=w'x
也就是逻辑回归比线性回归多了一个sigmoid函数,sigmoid(x)=1/(1+exp(-x)),其实就是对x进行归一化操作,使得sigmoid(x)位于0~1逻辑回归通常用于二分类模型,目标函数是二类交叉熵,y的值表示属于第1类的概率,用户可以自己设置一个分类阈值。
线性回归用来拟合数据,目标函数是平法和误差
问题六:逻辑回归,如何处理多元共线性问题 将所有回归中要用到的变量依次作为因变量、其他变量作为自变量进行回归分析,可以得到各个变量的膨胀系数VIF以及容忍度tolerance,如果容忍度越接近0,则共线性问题越严重,而VIF是越大共线性越严重,通常VIF小于5可以认为共线性不严重,宽泛一点的标准小于10即可。
问题七:机器学习之逻辑回归算法的一些疑问 第一, 参数为theta, 观察到x向量,判断为y标签的概率。
第二, h(x)为sigmoid function, 用来将 (-inf,inf)映射至(0,1]作为概率分布
第三 , 虽然不知道你在说什么,但是y是标签,所以在这里只有二值,1或-1
问题八:多重线性回归,logistic回归,cox回归各自解决什么问题 影响因素研究的
问题九:逻辑回归和神经网络之间有什么关系 神经网络的设计要用到遗传算法,遗传算法在神经网络中的应用主要反映在3个方面:网络的学习,网络的结构设计,网络的分析。
1.遗传算法在网络学习中的应用
在神经网络中,遗传算法可用于网络的学习。这时,它在两个方面起作用
(1)学习规则的优化
用遗传算法对神经网络学习规则实现自动优化,从而提高学习速率。
(2)网络权系数的优化
用遗传算法的全局优化及隐含并行性的特点提高权系数优化速度。
2.遗传算法在网络设计中的应用
用遗传算法设计一个优秀的神经网络结构,首先是要解决网络结构的编码问题;然后才能以选择、交叉、变异操作得出最优结构。编码方法主要有下列3种:
(1)直接编码法
这是把神经网络结构直接用二进制串表示,在遗传算法中,“染色体”实质上和神经网络是一种映射关系。通过对“染色体”的优化就实现了对网络的优化。
(2)参数化编码法
参数化编码采用的编码较为抽象,编码包括网络层数、每层神经元数、各层互连方式等信息。一般对进化后的优化“染色体”进行分析,然后产生网络的结构。
(3)繁衍生长法
这种方法不是在“染色体”中直接编码神经网络的结构,而是把一些简单的生长语法规则编码入“染色体”中;然后,由遗传算法对这些生长语法规则不断进行改变,最后生成适合所解的问题的神经网络。这种方法与自然界生物地生长进化相一致。
3.遗传算法在网络分析中的应用
遗传算法可用于分析神经网络。神经网络由于有分布存储等特点,一般难以从其拓扑结构直接理解其功能。遗传算法可对神经网络进行功能分析,性质分析,状态分析。
遗传算法虽然可以在多种领域都有实际应用,并且也展示了它潜力和宽广前景;但是,遗传算法还有大量的问题需要研究,目前也还有各种不足。首先,在变量多,取值范围大或无给定范围时,收敛速度下降;其次,可找到最优解附近,但无法精确确定最扰解位置;最后,遗传算法的参数选择尚未有定量方法。对遗传算法,还需要进一步研究其数学基础理论;还需要在理论上证明它与其它优化技术的优劣及原因;还需研究硬件化的遗传算法;以及遗传算法的通用编程和形式等。
问题十:逻辑回归模型的回归因子怎么得到 线性回归,是统计学领域的方法,用的时候需要关注假设条件是否满足、模型拟合是否达标,参数是否显著,自变量之间是否存在多重共线性等等问题因为统计学是一个过程导向的,需要每一步都要满足相应的数学逻辑。
下面讲讲我对线性回归的体会(只讲体会,原理的内容就不多说了,因为不难,而且网上相应资料很多!~):
1、linear regression 是最原始的回归,用来做数值类型的回归(有点绕,是为了区别“分类”),比如你可以利用它构建模型,输入你现在的体重、每天卡路里的摄入量、每天运动量等,预测你一个月的体重会是多少,从模型的summary中,查看模型对数据解释了多少,哪些自变量在影响你体重变化中更重要(事先对变量做了standardize),还可以看出在其它自变量不变的适合,其中一个自变量每变化1%,你的体重会变化多少(事先对自变量没做standardize)。 当问题是线性,或者偏向线性,假设条件又都满足(很难),又做好了数据预处理(工作量可能很大)时,线性回归算法的表现是挺不错的,而且在对模型很容易解释!但是,当问题不是线性问题时,普通线性回归算法就表现不太好了。
2、曲线回归,我更喜欢称之为“多项式回归”,是为了让弥补普通线性回归不擅长处理非线性问题而设计的,它给自变量加上一些适合当前问题的非线性特征(比如指数等等),让模型可以更好地拟合当前非线性问题。虽然有一些方法来帮助判断如何选择非线性特征,可以保证模型更优秀。但动手实践过的人,都知道,那有点纸上谈兵了,效果不好,而且有些非线性很难简单地表示出来!!
3、logistic regression,我感觉它应该属于机器学习领域的方法了(当你不去纠结那些繁琐的假设条件时),它主要是用来分析当因变量是分类变量的情况,且由于本身带有一丝的非线性特征,所以在处理非线性问题时,模型表现的也挺好(要用好它,需要做好数据预处理工作,把数据打磨得十分“漂亮”)。企业十分喜欢用它来做数据挖掘,原因是算法本身表现良好,而且对模型的输出结果容易解释(领导们都听得懂),不像其它高端的机器学习算法,比如Multiboost、SVM等,虽然很善于处理非线性问题,对数据质量的要求也相对较低,但它们总是在黑盒子里工作,外行人根本看不懂它是怎么运行的,它的输出结果应该怎么解释!(好吧,其实内行人也很难看懂!- - )
逻辑回归-6.解决多分类问题
逻辑回归是使用回归的方式,来解决分类问题。之前说过,逻辑回归只能解决二分类问题,为了解决多分类问题,可以使用OVR和OVO方法

OVR(One Vs Rest)
某个分类算法有N类,将某一类和剩余的类比较作为二分类问题,N个类别进行N次分类,得到N个二分类模型,给定一个新的样本点,求出每种二分类对应的概率,概率最高的一类作为新样本的预测结果。
OVO(One Vs One)
某个分类算法有N类,将某一类和另一类比较作为二分类问题,总共可分为\\(C^2_n\\)种不同的二分类模型,给定一个新的样本点,求出每种二分类对应的概率,概率最高的一类作为新样本的预测结果。
加载鸢尾花数据集(数据集有三类结果):
import numpy
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
# 为了数据可视化,只取数据集的前两个特征
x = iris.data[:,:2]
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)scikit-learn中默认支持多分类,且多分类方法默认为OVR
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
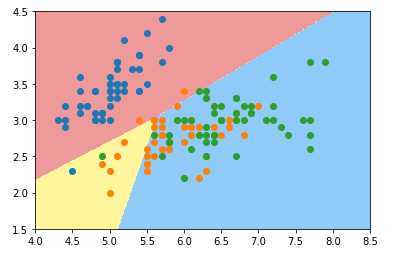
log_reg.fit(x_train,y_train)画出决策边界:
使用OVO多分类方法:
log_reg2 = LogisticRegression(multi_class='multinomial',solver='newton-cg')
log_reg2.fit(x_train,y_train)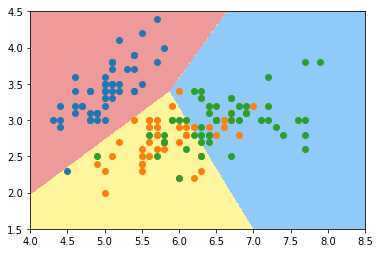
scikit-learn中的OVR和OVO类?
from sklearn.multiclass import OneVsRestClassifier,OneVsOneClassifier
# 使数据所有的特征值参与运算
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)- OVR
log_reg1 = LogisticRegression()
OVR = OneVsRestClassifier(log_reg1)
OVR.fit(x_train,y_train)准确率:

- OVO
log_reg2 = LogisticRegression()
OVR = OneVsRestClassifier(log_reg2)
OVR.fit(x_train,y_train)准确率:

以上是关于逻辑回归解决啥问题的主要内容,如果未能解决你的问题,请参考以下文章