前言
requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的。
如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间
关于requests请求的响应时间,官网上没太多介绍,并且我百度搜了下,看很多资料写的是r.elapsed.microseconds获取的,然而都是错的!!!
elapsed官方文档
requests.Response
elapsed = None
The amount of time elapsed between sending the request and the arrival of the response (as a timedelta). This property specifically measures the time taken between sending the first byte of the request and finishing parsing the headers. It is therefore unaffected by consuming the response content or the value of the stream keyword argument.
简单翻译:计算的是从发送请求到服务端响应回来这段时间(也就是时间差),发送第一个数据到收到最后一个数据之间,这个时长不受响应的内容影响
2.用help()查看elapsed里面的方法
import requests
r = requests.get("https://www.baidu.com")
help(r.elapsed)
elapsed里面几个方法介绍
-
total_seconds 总时长,单位秒
-
days 以天为单位
-
microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒
-
seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天
-
max = datetime.timedelta(999999999, 86399, 999999) 最大时间
-
min = datetime.timedelta(-999999999) 最小时间
-
resolution = datetime.timedelta(0, 0, 1) 最小时间单位
获取响应时间
1.获取elapsed不同的返回值
import requests
r = requests.get("http://www.cnblogs.com/yoyoketang/")
print(r.elapsed)
print(r.elapsed.total_seconds())
print(r.elapsed.microseconds)
print(r.elapsed.seconds)
print(r.elapsed.days)
print(r.elapsed.max)
print(r.elapsed.min)
print(r.elapsed.resolution)
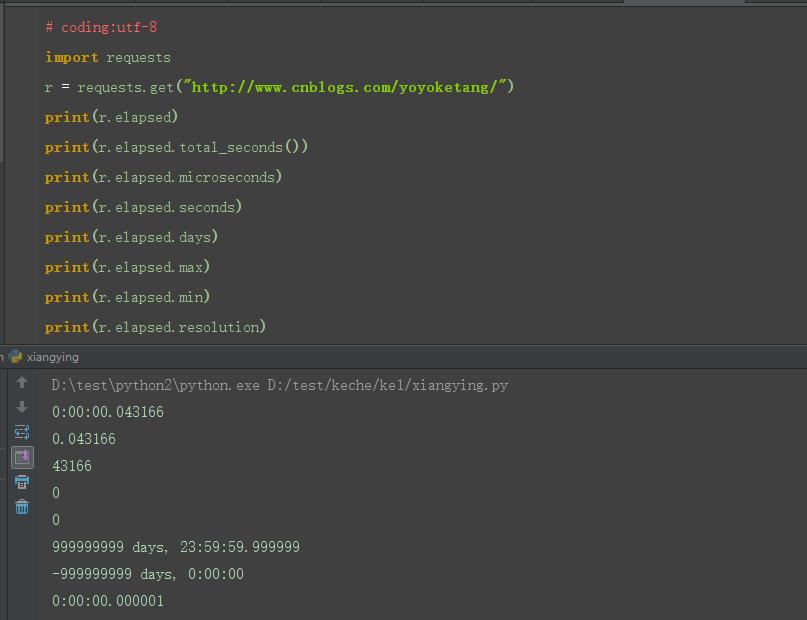
2.网上很多资料写的是用microseconds获取响应时间,再除1000*1000得到时间为秒的单位,当请求小于1s时,发现不出什么问题。如果时间超过1s,问题就来了。
(很显然,大于1s的时候,只截取了后面的小数部分)
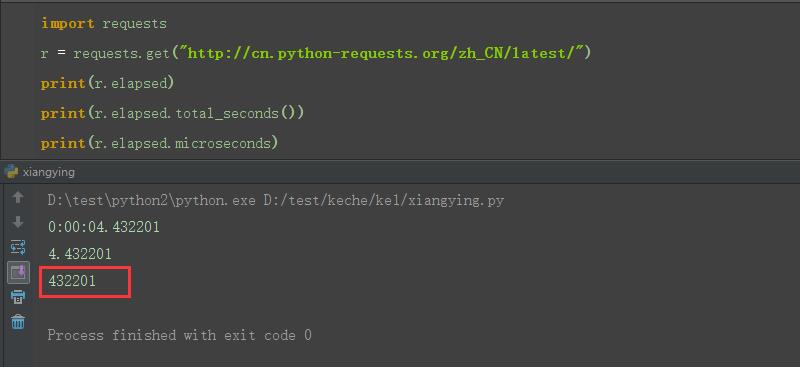
3.所以获取响应时间的正确姿势应该是:r.elapsed.total_seconds(),单位是s
timeout超时
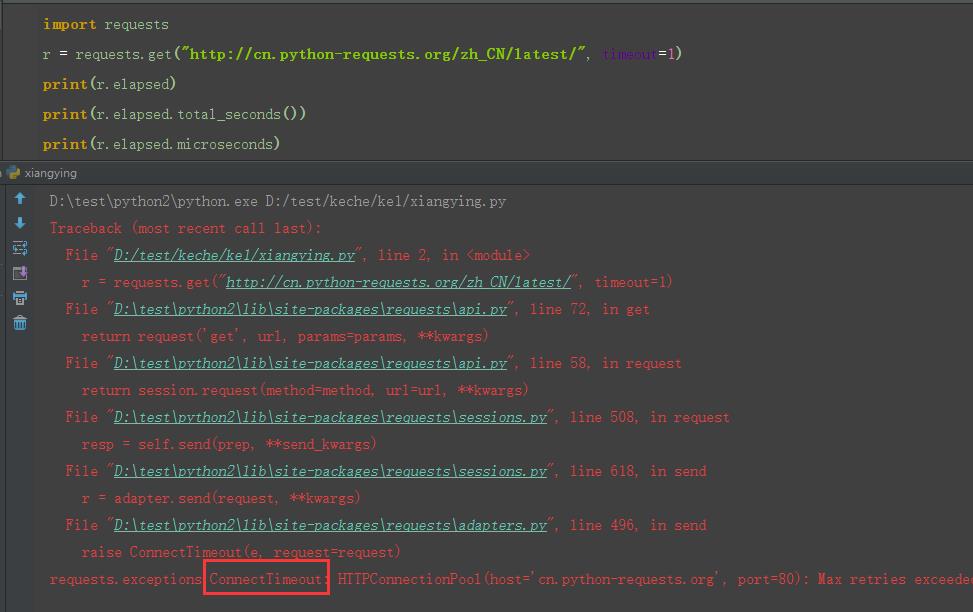
1.如果一个请求响应时间比较长,不能一直等着,可以设置一个超时时间,让它抛出异常
2.如下请求,设置超时为1s,那么就会抛出这个异常:requests.exceptions.ConnectTimeout: HTTPConnectionPool
import requests
r = requests.get("http://cn.python-requests.org/zh_CN/latest/", timeout=1)
print(r.elapsed)
print(r.elapsed.total_seconds())
print(r.elapsed.microseconds)
---------------------------------python接口自动化完整版-------------------------
全书购买地址 https://yuedu.baidu.com/ebook/585ab168302b3169a45177232f60ddccda38e695
作者:上海-悠悠 QQ交流群:588402570
也可以关注下我的个人公众号:
