一个python中嵌套列表的问题,下图中的两种写法,结果不一样,这是为啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个python中嵌套列表的问题,下图中的两种写法,结果不一样,这是为啥?相关的知识,希望对你有一定的参考价值。
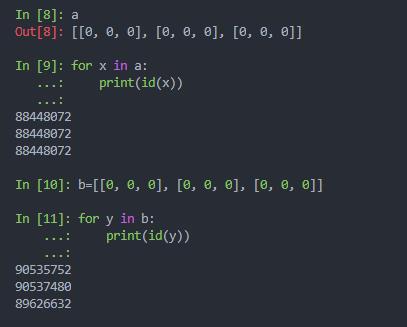
题主你好,我说下我的理解, 这个要从内存分配上去看了.
[0]* 3 得到的结果是: [0,0,0], 这里面3个0是被分配的不同内存地址,而
[[0]] * 3,得到的结果是: [[0],[0],[0]],这里面3个[0]在内存中指的其实是一个地址,你可以将后两个[0]理解为第1个[0]的两个别名.
换个说法: [0]* 3 得到的结果[0,0,0]你将里面的3个0理解为: 张三,李四,王五,这是3个人, 你改其中的一个对另两个人是没有影响的. 而
[[0]]*3 得到的结果[[0],[0],[0]]你可以理解为:张三,小张,阿三,其中小张和阿三是张三的两个小名, 这三个[0]其实是1个人, 所以你改变其中一个[0],另外的两个[0]肯定也会跟着变.
而你直接写[[0],[0],[0]],可以理解为这三个[0]是三个不同的人.
至于为什么[[0]]*3得到的是[[0],[0],[0]], 而直接定义[[0],[0],[0]]看着是一样, 但当修改元素值的时候,得到的结果却不同,这就是python的实现机制了,不用太纠结这个,因为python就是这样设计的,你只需要明白这个逻辑,用的时候会用就好.
写在最后: 这只是我自己的理解, 没有理论依据,希望不会误导题主.
希望可以帮到题主, 欢迎追问. 参考技术A
python统计文本中的单词数和print的两种写法
#!/usr/bin/python
# - * - coding: utf-8 - * -
#作用,分别计算每个文本的单词数,并且输出所有文本的单词总数
a = []
sum = 0
def count_words(filename):
#filename = ‘1.txt‘
try:
with open(filename) as file_object:
t = file_object.read()
except IOError:
print ‘you have‘ + ‘ ‘ + filename + ‘ is not exist!‘
else:
words = t.split()
numbers = len(words)
a.append(numbers)
#print的两种写法,可以带逗号,后面直接跟参数值。也可以不带逗号,后面直接跟%参数值
print ‘danci de geshi yigong shi %d‘ %numbers
# #print ‘danci de geshi yigong shi‘ , numbers
filenames = [ ‘1.txt‘,‘2.txt‘,‘3.txt‘ ]
for filename in filenames:
count_words(filename)
for i in a:
sum += int(i)
print sum
#两种写法,一个是用sum计数,一个用sum函数,
#sum的参数是一个list,这里a就是list
#print ‘所有单词总数为‘ + str(sum(a))以上是关于一个python中嵌套列表的问题,下图中的两种写法,结果不一样,这是为啥?的主要内容,如果未能解决你的问题,请参考以下文章