TensorFlow学习笔记
Posted 江湖人称小白哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow学习笔记相关的知识,希望对你有一定的参考价值。
最近致力于深度学习,希望在移动领域能够找出更多的应用点.其中TensorFlow作为目前的一个热点值得我们重点关注.
机器学习
机器学习是人工智能的一个分支,也是用来实现人工只能的一种方法。简单来说,机器学习就是通过算法,使得机器能从大量历史数据中学习规律,从而对新的样本做智能识别或对未来做预测,与传统的使用特定指令集手写软件不同,我们使用大量数据和算法来“训练”机器,由此带来机器学习如何完成任务.从1980年代末期以来,机器学习的发展大致经历了两次浪潮:浅层学习(Shallow Learning)和深度学习(Deep Learning)。
浅层学习
90年代,各种各样的浅层机器学习模型相继被提出,比如SVM、Boosting、最大熵方法等。这些模型在是理论分析或者工程应用领域都获得了巨大的成功最成功的应用,比如搜索广告系统的广告点击率CTR预估、网页搜索排序、垃圾邮件过滤系统、基于内容的推荐系统等。
深度学习
深度学习是实现机器学习的一种技术,现在所说的深度学习很大层次上是指神经网络。神经网络是受人类大脑的启发:神经元之间的相互连接。对比看来,人类大脑中的神经元与特定范围内的任意神经元连接,而人工神经网络中数据传播要经历不同的层,且传播方向也不同.
现在来说说在神经网络算法中,每个神经元的作用:每个神经元都会给其输入指定一个权重:相对于执行的任务该神经元的正确和错误程度。最终的输出由这些权重共同决定。

现在来看看上面提到的停止标志示例。一张停止标志图像的属性,被一一细分,然后被神经元“检查”:形状、颜色、字符、标志大小和是否运动。神经网络的任务是判断这是否是一个停止标志。它将给出一个“概率向量”,这其实是基于权重做出的猜测结果。
为什么需要深度学习
浅层模型有一个重要特点,就是假设靠人工经验来抽取样本的特征,在模型的运用不出差错的前提下(如假设互联网公司聘请的是机器学习的专家),特征的好坏就成为整个系统性能的瓶颈。要发现一个好的特征,就要求开发人员对待解决的问题要有很深入的理解。
深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。换句话说,深度学习的目的是为了特征学习。
区别于传统的浅层学习,深度学习的不同在于:1. 强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;2. 明确突出了特征学习的重要性,也就是说,同过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,使分类或预测更加容易。
与人工规则构造特征的方法相比,利用大数据来学习特征,更能刻画数据丰富的内在信息,目前来看,深度学习在搜索广告CRT预估,自然语言处理,图像识别,语音识别以及无人驾驶上有了广泛的应用.
TensorFlow基础
是Google开源的机器学习库,基于DistDelief进行研发的第二代人工智能系统,用来帮助我们快速的实现DL和CNN等各种算法公式,.其名字本身描述了它自身的执行原理:Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算.数据流图中的图就是我们所说的有向图,我们知道,在图这种数据结构中包含两种基本元素:节点和边.这两种元素在数据流图中有自己各自的作用.节点用来表示要进行的数学操作,另外,任何一种操作都有输入/输出,因此它也可以表示数据的输入的起点/输出的终点.边表示节点与节点之间的输入/输出关系,一种特殊类型的数据沿着这些边传递.这种特殊类型的数据在TensorFlow被称之为tensor,即张量,所谓的张量通俗点说就是多维数组.当我们向这种图中输入张量后,节点所代表的操作就会被分配到计算设备完成计算.
到现在,你应该对TensorFlow有了一个浅显的人是,下面我们再来看一张图,他会帮助你更好的认识TensorFlow工作过程.
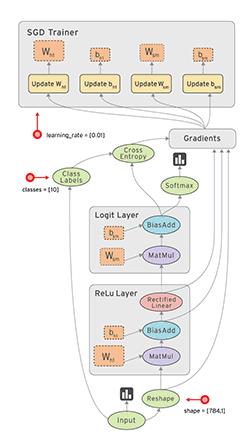
到现在,我们只是认识了TensorFlow,接下来我总结了TensorFlowd的四个特性,来说明我们为什么要使用TensorFlow:
- 灵活性: 非严格的“神经网络”库。这意味这我们的计算只要能够表示为数据流图,就能够使用.
- 可移植性:底层核心采用C++便宜,可以运行在台式机、服务器、手机移动等设备上,提供对分布式的支持,能够快速构建深度学习集群.
- 多语言支持:前端支持Python,C/C++,Java以及Go,以及非官方支持的Scala,但是目前对Python接口支持最好.
- 高效:提供对线程、队列、异步操作支持,同时支持运行在CPU和GPU上,能够充分发挥硬件潜力.
可以说正是由于以上四个特性,使得TensorFlow的使用逐渐流行开来.其中我认为tensorflow最关键的一点是允许我们将计算的过程描述为一张图(Graph),我将其称这张图为”计算图”,能让我们很容易的操作其中的网络结构.
现在我们对Tensor的特性有了基本的了解,但是如何利用TensorFlow呢?为了能够容易的理解,我用下水管道结构图来类比.
如果你是一名城市管道设计者,当你想要解决这个城市排水问题时,你会做点什么呢?(这个例子来自早期看到一位作者的解释)

不出意外,你的脑海中隐约的浮现出管道图.如果能到这一步,说明什么呢?这意味着你已经开始触及TensorFlow领域,看吧,其实TensorFlow的工作过程我们天生就懂.
TensorFlow中的计算图就像此处的管道结构,我们考虑设计管道结构的过程就是在构建计算图.
现在来看管道中的阀门.阀门可以用来控制水流动的强度和方向,这和神经网络中的权重和偏移的作用一致.唯一的不同是,管道中阀门需要人为调整,而神经网络的”阀门”会根据数据自我调整/更新.
我们知道在管道中是水在流动,那么计算图流动的是什么呢?
计算图流动的就是我们上文说到的tensor,tensor本质上就是多维数组.(其实每一个tensor包含又一个静态类型,一个rank和一个shape,关于这点我们就不做解释了,有兴趣的同学可以查阅相关paper)
和管道不同,在计算图中,我们可以从任意一个节点处取出”液体”,也就是获得当前tensor.
现在,我们来个稍微正规点的解释:
TensorFlow使用Graph来描述计算任务,图中的节点被称之为op.一个op可以接受0或多个tensor作为输入,也可产生0或多个tensor作为输出.任何一个Graph要想运行,都必须借助上下文Session.通过Session启动Graph,并将Graph中的op分发到CPU或GPU上,借助Session提供执行这些op.op被执行后,将产生的tensor返回.借助Session提供的feed和fetch操作,我们可以为op赋值或者获取数据.计算过程中,通过变量(Variable)来维护计算状态.
为了方便大家理解TensorFlow中相关的概念,这里我列了一张表格:
| 类型 | 描述 | 用途 |
|---|---|---|
| Session | 会话 | 图必须在称之为“会话”的上下文中执行。会话将图的op分发到诸如CPU或者GPU上计算 |
| Graph | 描述计算过程 | 必须在Session中启动 |
| tensor | 数据 | 数据类型之一,代表多维数组 |
| op | 操作 | 图中的节点被称之为op,一个op获得0或者多个Tensor,执行计算,产生0或者多个Tensor |
| Variable | 变量 | 数据类型之一,运行过程中可以被改变,用于维护状态 |
| feed | 赋值 | 为op的tensor赋值 |
| fetch | 取值 | 从op的tensor中取值 |
| Constant | 常量 | 数据类型之一,不可变 |
TensorFlow环境
TensorFlow目前支持三种平台:Linux系列,Mac OS以及Window.并提供了多种安装方式,目前常见的安装方式有三种:pip,docker,Anacona,和源码编译安装.TensorFlow支持CPU计算和GPU计算:
- CPU 支持 :系统没有 NVIDIA CUDA® GPU,我们只能安装该版本。
- GPU 支持: TensorFlow 程序通常在 GPU 比在 CPU 上运行快得多。如果系统具有 NVIDIA CUDA GPU 那么可以安装该版本
为了方便,这里只演示CPU.更多的资料你可以在TensorFlow官网官网上找到答案.
window上通过安装
在开始之前首先确保我们安装了python3.
pip3 install tensorflow
pip3 install tensorflow-gpu
pip3 install tensorlayer //上面二选一,后安装tensorlayer,也可以不装一般来说,你会遇到以下两个错误:
错误1:
return importlib.import_module(mname)
File "C:\\Users\\liudongdong-iri\\AppData\\Local\\Programs\\Python\\Python35\\lib\\impo
ib\\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 986, in _gcd_import
File "<frozen importlib._bootstrap>", line 969, in _find_and_load
File "<frozen importlib._bootstrap>", line 958, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 666, in _load_unlocked
File "<frozen importlib._bootstrap>", line 577, in module_from_spec
File "<frozen importlib._bootstrap_external>", line 906, in create_module
File "<frozen importlib._bootstrap>", line 222, in _call_with_frames_removed
mportError: DLL load failed: 找不到指定的模块。 错误2:
File "<frozen importlib._bootstrap>", line 222, in _call_with_frames_removed
ImportError: DLL load failed: 找不到指定的模块。此时只需要下载https://www.microsoft.com/en-us/download/details.aspx?id=53587 安装后重新使用pip命令安装.
Mac OS X 通过pi安装
在mac上通过pip来安装,python 2.7和python 3.3+二者选一即可
pip install tensorflow如果是python3使用以下命令:
pip3 install tensorflow注意:如果在之前安装过TensorFlow<0.71的版本,首先要使用pip uninstall卸载TensorFlow以及protobuf.
检测安装
在安装成功后,先来运行个简单Hello,TensorFlow程序一睹风采:
import tensorflow as tf
hello = tf.constant('Hello,TensorFlow')
sess = tf.Session()
print(sess.run(hello))不出意外,我们将看到如下输出:
Hello,TensorFlowTensorFlow实践
上面我们简单的介绍了TensorFlow的工作原理以及相关的概念,接下来呢,我们从实践的角度触发,来进一步解释相关概念,在这之前先来说明构建TensorFlow程序的基本过程.,通常分为两步:构建阶段和一个执行阶段。在构建阶段,我们组织多个op,最终形成Graph。在执行阶段,使用会话执行op.
先来看个简单的示例,来大体有个了解:
import tensorflow as tf
# 定义‘符号’变量,也称为占位符
a = tf.placeholder("int32")
b = tf.placeholder("int32")
# 构造一个op节点
y = tf.multiply(a, b)
# 建立会话
sess = tf.Session()
# 运行会话,输入数据,并计算节点,同时打印结果
print(sess.run(y, feed_dict=a: 3, b: 3))
# 任务完成, 关闭会话.
sess.close()构建阶段
构造阶段的主要目的是为了构建一张计算图.构建图的第一步是创建源op.源op不需要任何输入,源op的输出被传递给其他op作为输入.例如常量(Constant).Python 库中, op 构造器的返回值代表被构造出的 op 的输出, 这些返回值可以传递给其它 op 构造器作为输入..在TensorFlow中存在一个默认图(defalut graph).op构造器可以为其增加节点.很多时候我们会直接使用该图,可以通过tf.Graph.as_default()来获取.
Graph
Graph:要组装的结构,由许多操作组成,其中的每个连接点代表一种操作
| 方法 | 用途 |
|---|---|
| tf.Graph.as_graph_def() | 返回一个图的序列化的GraphDef,表示序列化的GraphDef可以导入到另外一个图(使用import_graph_def()) |
| tf.Graph.get_operations() | 返回图中的操作节点列表 |
| tf.Operation.name | 操作节点op的名称 |
| tf.Operation.type | 操作节点op的类型 |
| tf.Operation.inputs | 操作节点的输入与输出 |
| tf.Operation.run(session=None,feed_dict=None) | 在会话中执行该操作 |
| tf.add_to_collection(name,value) | 基于默认的图,其功能便为Graph.add_to_collection() |
| tf.get_collection(key,scope=None) | 基于默认的图,其功能便为Graph.get_collection() |
op
op:接受(流入)零个或多个输入(液体),返回(流出)零个或多个输出
数据类型
数据类型:主要分为tensor,variable,constant.
tensor:多维array或list
# 创建
tensor_name=tf.placeholder(type, shape, name)variable:通常可以将一个统计模型中的参数表示为一组变量。例如,你可以将一个神经网络的权重当作一个tensor存储在变量中。在训练图的重复运行过程中去更新这个tensor
# 创建变量
name_variable = tf.Variable(value, name)
# 初始化单个变量
init_op=variable.initializer()
# 初始化所有变量
init_op=tf.initialize_all_variables()
# 更新操作
update_op=tf.assign(variable to be updated, new_value)简单示例
这里我们来创建一个包含三个op的图,其中两个constant op,一个matmul op.
import tensorflow as tf
# 创建作为第一个常量op,该op会被加入到默认的图中
# 1*2的矩阵,构造器的返回值代表该常量op的返回值
matrix_1 = tf.constant([[3., 3.]])
# 创建第二个常量op,该op会被加入到默认的图中
# 2*1的矩阵
matrix_2 = tf.constant([[2.], [2.]])
# 创建第三个op,为矩阵乘法op,接受matrix_1和matrix_2作为输入,product代表乘法矩阵结果
product = tf.matmul(matrix_1, matrix_2)到现在我们已经创建好了包含三个op的图.下面我们要通启动该图,执行运算.
执行阶段
在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU). 一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测. 如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作. 但是今天我们暂时不关注该部分.
Session
首先我们需要创建一个Session对象.在不传参数的情况下,该Session的构造器将启动默认的图.之后我们可以通过Session对象的run(op)来执行我们想要的操作.
| 方法 | 用途 |
|---|---|
| tf.Session.run(fetches,feed-dict=Noe,options=Node,run_metadata=None) | 运行fetches中的操作节点并求其 |
| tf.Session.close() | 关闭会话 |
| tf.Session.graph | 返回加载该会话的图() |
| tf.Session.as_default() | 设置该对象为默认会话,并返回一个上下文管理器 |
简单示例
# 创建会话
sess = tf.Session()
# 赋值操作
sess.run([output], feed_dict=input1:value1, input2:value1)
# 用创建的会话执行操作
sess.run(op)
# 取值操作
# 关闭会话
sess.close()完整示例
最终结合构建阶段和执行阶段,完整代码如下:
import tensorflow as tf
# 创建作为第一个常量op,该op会被加入到默认的图中
# 1*2的矩阵,构造器的返回值代表该常量op的返回值
matrix_1 = tf.constant([[3., 3.]])
# 创建第二个常量op,该op会被加入到默认的图中
# 2*1的矩阵
matrix_2 = tf.constant([[2.], [2.]])
# 创建第三个op,为矩阵乘法op,接受matrix_1和matrix_2作为输入,product代表乘法矩阵结果
product = tf.matmul(matrix_1, matrix_2)
# 获取sess
sess = tf.Session()
# 来执行矩阵乘法op
result = sess.run(product)
# 输出矩阵乘法结果
print("result:",result)
# 任务完毕,关闭Session
sess.close()除了通过Session的close()的手动关闭外,也可以使用with代码块:
with tf.Session() as sess:
result=sess.run(product)
print("result:",result)现在来运行该代码,不出意外我们将获得结果:
result: [[ 12.]]其他
通过上面的过程,我们只需要了解了tensorflow的构建过程和执行过程,进一步了解了Graph,op以及Session各自所担当的职责,但是仍然有很多点我们无法一一细聊.
为了方便起见,这里我将对一些概念再次进行解释.
Tensor
在TensorFlow中,用tensor来表示其所使用的数据结构,简单点理解tensor就是一个多维数组.任何一个物体,我们都可以用几个特征来描述它.每个特征可以划分成一个维度.比如:一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height,width, channels].
| 方法 | 用途 |
|---|---|
| tf.Tensor.dtype | tensor中数据类型 |
| tf.Tensor.name | tensor名称 |
| tf.Tensor.op | 产生该tensor的op |
| tf.Tensor.graph | 该tensor所在的 |
Variables
TensorFlow使用Variables来维护图执行过程中的状态信息.下面我们演示一个计数器:
import tensorflow as tf
# 创建一个变量,初始化为0
state = tf.Variable(0, name="counter")
# 创建一个常量
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 变量初始化
init_op = tf.initialize_all_variables()
sess = tf.Session()
# 运行init_op
sess.run(init_op)
# 运行state,打印state初始值
print(sess.run(state))
for _ in range(10):
sess.run(update)
print(sess.run(state))执行该程序,不出意外输出结果:
0
1
2
3
4
5
6
7
8
9
10Fetch
为了获取操作输出的内容,可以在使用Session对象的run(op)时,传入一些tensor,这些tensor用来取回我们想要的结果.
import tensorflow as tf
value_1 = tf.constant(3.0)
value_2 = tf.constant(2.0)
value_3 = tf.constant(5.0)
# 2.0+5.0
temp_value=tf.add(value_2,value_3)
# 3.0+(2.0+5.0)
result=tf.add(value_1,temp_value)
sess = tf.Session()
print(sess.run([temp_value,result]))Feed
我们可以通过TensorFlow对象的placeholder()为变量创建指定数据类型占位符,在执行run(op)时通过feed_dict来为变量赋值.
import tensorflow as tf
input_1 = tf.placeholder(tf.float32)
input_2 = tf.placeholder(tf.float32)
output = tf.add(input_1, input_2)
with tf.Session() as sess:
# 通过feed_dict来输入,outpu表示输出
print(sess.run([output],feed_dict=input_1:[7.],input_2:[2.]))placeholder
TensorFlow提供一种占位符操作,在执行时需要为其提供数据.这有点类似我们编写sql语句时使用?占位符一样,你可以理解为预编译.
| 方法 | 用途 |
|---|---|
| tf.placeholder(dtype,shape=None,name=None) | 为一个tensor插入一个占位符 |
input_value = tf.placeholder(tf.float32,shape=(1024,1024))模型保存于恢复
在tensorflow中最简单的保存与加载模型的方式是通过Saver对象.
| 方法 | 用途 |
|---|---|
| tf.train.Saver.save(sess,save_path,global_step=None,latest_filename=None,meta_graph_suffix=’meta’,write_meta_graph=True) | 保存变量 |
| tf.train.Saver.restore(sess,save_path) | 恢复变量 |
| tf.train.Saver.last_checkpoints() | 列出最近未删除的checkpoint文件名 |
| tf.train.Saver.set_last_checkpoints(last_checkpoints) | 设置checkpoint文件名列表 |
| tf.train.Saver.set_last_checkpoints_with_time(last_checkpoints_with_time) | 设置checkpoint文件名列表和时间戳 |
保存模型
import tensorflow as tf
def save_model():
v1 = tf.Variable(tf.random_normal([1, 2]), name="v1")
v2 = tf.Variable(tf.random_normal([2, 3]), name="v2")
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver_path = saver.save(sess, "./model.ckpt")
print("model saved in file: ", saver_path)加载模型
用同一个Saver对象来恢复变量,注意,当你从文件恢复变量是,不需要对它进行初始化,否则会报错。
import tensorflow as tf
def load_model():
v1 = tf.Variable(tf.random_normal([1, 2]), name="v1")
v2 = tf.Variable(tf.random_normal([2, 3]), name="v2")
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,"./model.ckpt")
print("mode restored")
移植TensorFlow到移动设备
由于TensorFlow核心代码使用C++编写的,因此我们可以很容易的将其移植到移动设备中,一般需要经过以下几步:
- PC训练模型,并将其保存为pb格式,然后导入该模型文件到android项目的assets目录中
- 导入TensorFlow的jar包以及so文件到Android项目中,jar包向我们暴露了操作接口,具体的执行引擎算法责备封装在so文件当中
- 定义相关变量,存储数据,并通过jar包提供的接口加载模型,执行运算即可.
下面我们用个简单的示例来演示整个移植的过程.
1. 训练模型
import tensorflow as tf
sess = tf.Session()
matrix_1 = tf.constant([3., 3.], name='input')
add = tf.add(matrix_1, matrix_1, name='output')
sess.run(add)
output_graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=['output'])
# 保存模型到目录下的model文件夹中
with tf.gfile.FastGFile('./model/tensorflow_matrix_graph.pb',mode='wb') as f:
f.write(output_graph_def.SerializeToString())
sess.close()
唯一注意的一点是务必要保成pb格式的文件:
- 不能使用 tf.train.write_graph()保存模型,该种方式只是保存了模型的结构,并不保存训练完毕的参数值
- 不能使用 tf.train.saver()保存模型,该种方式只是保存了网络中的参数值,并不保存模型的结构。
我们需要的是既保存模型的结构,又保存模型中每个参数的值,所以上述的两种方式都不行:因此我们用一下方式保存:
# 可以把整个sesion当作常量都保存下来,通过output_node_names参数来指定输出
graph_util.convert_variables_to_constants
# 指定保存文件的路径以及读写方式
tf.gfile.FastGFile('model/test.pb', mode='wb')
# 将固化的模型写入到文件
f.write(output_graph_def.SerializeToString())2.编译所需要的jar和so文件
这里以Mac OS X平台为例,你可以可以在linux平台编译,目前不支持window平台编译.
- 首先克隆 TensorFlow 仓库到本地:
$ git clone --recurse-submodules https://github.com/tensorflow/tensorflow--recurse-submodules 参数是必须得, 用于获取 TesorFlow 依赖的 protobuf 库.
- 安装Bazel
Bazel是Google开源的一款自动化构建工作,TensorFlow整个工程就是通过它进行构建.其安装过程也非常简单如果你和我一样使用macOS构建,那么我们可以通过包管理器Homebrew来安装Bazel
brew install bazel安装之后可以通过bazel version来查看其版本,比如当前我这里是:
Build label: 0.4.5-homebrew
Build target: bazel-out/local-opt/bin/src/main/java/com/google/devtools/build/lib/bazel/BazelServer_deploy.jar
Build time: Thu Mar 16 13:37:54 2017 (1489671474)
Build timestamp: 1489671474
Build timestamp as int: 1489671474在需要升级的时候可以通过brew upgrade bazel.如果你要在其他平台安装,查阅官网:https://bazel.build/versions/master/docs/install-os-x.html
接下来,我们需要修改TensorFlow项目的WORKSPACE文件:
修改前:
# Uncomment and update the paths in these entries to build the Android demo.
#android_sdk_repository(
# name = "androidsdk",
# api_level = 23,
# # Ensure that you have the build_tools_version below installed in the
# # SDK manager as it updates periodically.
# build_tools_version = "25.0.2",
# # Replace with path to Android SDK on your system
# path = "<PATH_TO_SDK>",
#)
#
# Android NDK r12b is recommended (higher may cause issues with Bazel)
#android_ndk_repository(
# name="androidndk",
# path="<PATH_TO_NDK>",
# # This needs to be 14 or higher to compile TensorFlow.
# # Note that the NDK version is not the API level.
# api_level=14)根据本机情况来设置正确的SDK和NDK路径.
# Uncomment and update the paths in these entries to build the Android demo.
android_sdk_repository(
name = "androidsdk",
api_level = 23,
# Ensure that you have the build_tools_version below installed in the
# SDK manager as it updates periodically.
build_tools_version = "25.0.2",
# 修改为自己系统SDK路径
path = "/Users/liudongdong/Library/Android/sdk/",
)
#
# Android NDK r12b is recommended (higher may cause issues with Bazel)
android_ndk_repository(
name="androidndk",
# 修改为自己系统NDK路径
path="/Users/liudongdong/Library/Android/ndk/",
# This needs to be 14 or higher to compile TensorFlow.
# Note that the NDK version is not the API level.
api_level=14)先编译so文件
bazel build -c opt //tensorflow/contrib/android:libtensorflow_inference.so --crosstool_top=//external:android/crosstool --host_crosstool_top=@bazel_tools//tools/cpp:toolchain --cpu=armeabi-v7a生成的so文件位于tensorflow目录下:
bazel-bin/tensorflow/contrib/android/libtensorflow_inference.so再编译jar文件
bazel build //tensorflow/contrib/android:android_tensorflow_inference_java生成的jar文件位于:
bazel-bin/tensorflow/contrib/android/libandroid_tensorflow_inference_java.jar需要注意一点:在编译出so文件后要及时地将其拷贝出来,因为在编译jar文件的时候会将上面编译出的so文件删除.
3.移植模型到Android设备
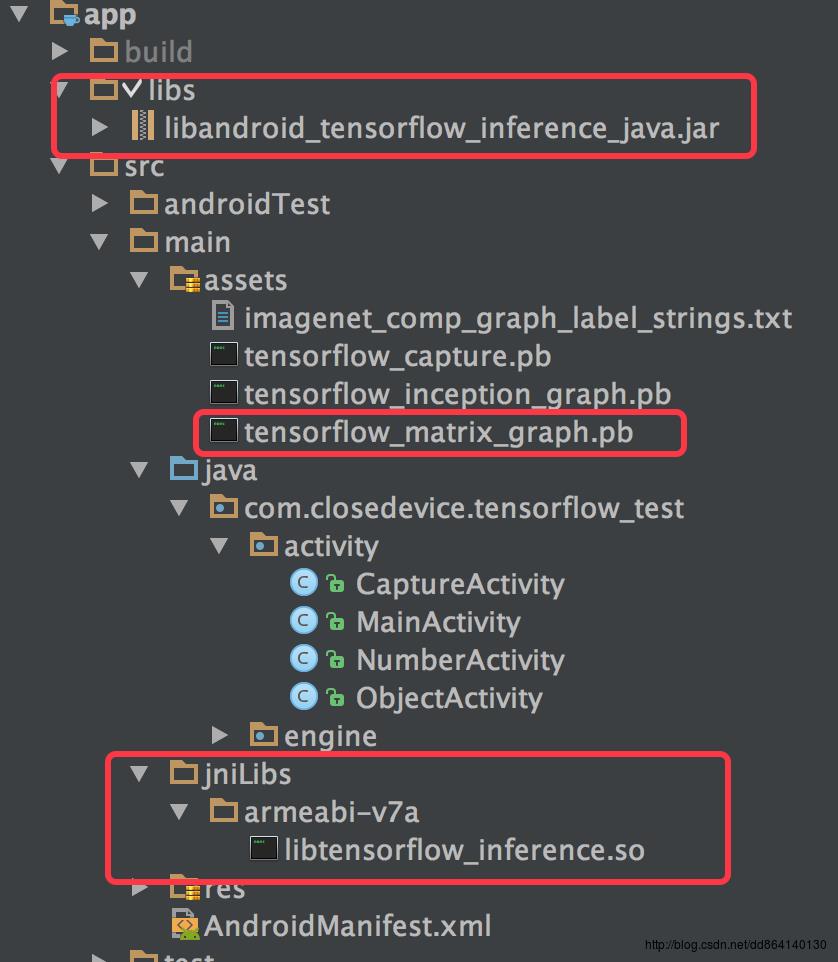
将pb模型文件放入assets目录
添加jar包到项目的libs目录下,添加so文件到jniLibs目录下:
- 定义变量,然后初始化tensorflow,调用相关api.同样,我们以刚才生成的tensorflow_matrix_graph.pb为例:
public class NumberActivity extends AppCompatActivity
// 定义模型文件路径
private static final String MODE_FILE = "file:///android_asset/tensorflow_matrix_graph.pb";
private static final int HEIGHT=1;
private static final int WIDTH =2;
// 输入
private static final String inputName = "input";
private float[] inputs = new float[HEIGHT * WIDTH];
// 输出
private static final String outputName = "output";
private float[] outputs = new float[HEIGHT * WIDTH];
//tensorflow接口
TensorFlowInferenceInterface mTensorFlowInferenceInterface;
@Override
protected void onCreate(Bundle savedInstanceState)
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_number);
findViewById(R.id.btn_matrix).setOnClickListener(new View.OnClickListener()
@Override
public void onClick(View v)
float[] result = getResult();
Toast.makeText(NumberActivity.this, result[0] + " " + result[1], Toast.LENGTH_SHORT).show();
);
mTensorFlowInferenceInterface = new TensorFlowInferenceInterface(getAssets(), MODE_FILE);
private float[] getResult()
inputs[0]=4;
inputs[1]=3;
Trace.beginSection("feed");
// 输入数据
mTensorFlowInferenceInterface.feed(inputName, inputs, WIDTH, HEIGHT);
Trace.endSection();
Trace.beginSection("run");
String[] outputNames = new String[]outputName;
// 执行数据
mTensorFlowInferenceInterface.run(outputNames);
Trace.endSection();
Trace.beginSection("fetch");
// 取出数据
mTensorFlowInferenceInterface.fetch(outputName,outputs);
Trace.endSection();
return outputs;
总结
此文更多是各前辈的总结,如有不妥之处,多多指教.
以上是关于TensorFlow学习笔记的主要内容,如果未能解决你的问题,请参考以下文章