Adaboost算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Adaboost算法相关的知识,希望对你有一定的参考价值。
参考技术A 链接:
1. 线性回归总结
2. 正则化
3. 逻辑回归
4. Boosting
5. Adaboost算法
转自: 原地址
提升方法(boosting)是一种常用的统计学习方法,应用广泛且有效。在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。
本章首先介绍提升方法的思路和代表性的提升算法AdaBoost,然后通过训练误差分析探讨AdaBoost为什么能够提高学习精度,并且从前向分布加法模型的角度解释AdaBoost,最后叙述提升方法更具体的事例——提升术(boosting tree)。AdaBoost算法是1995年由Freund和Schapire提出的,提升树是2000年由Friedman等人提出的。(开头几段内容来自《统计学习方法》)
Adaboost算法基本原理
提升方法的基本思路
提升方法是基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。通俗点说,就是”三个臭皮匠顶个诸葛亮”。
Leslie Valiant 首先提出了“强可学习(strongly learnable)”和”弱可学习(weakly learnable)”的概念,并且指出:在概率近似正确(probably approximately correct, PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的,如果正确率不高,仅仅比随即猜测略好,那么就称这个概念是弱可学习的。 2010年的图灵奖给了L. Valiant,以表彰他的PAC理论
。非常有趣的是Schapire后来证明强可学习与弱可学习是等价的,也就是说,在PAC学习的框架下,一个概念是强可学习的充要条件是这个概念是可学习的。
这样一来,问题便成为,在学习中,如果已经发现了“弱学习算法”,那么能否将它提升(boost)为”强学习算法”。大家知道,发现弱学习算法通常比发现强学习算法容易得多。那么如何具体实施提升,便成为开发提升方法时所要解决的问题。关于提升方法的研究很多,有很多算法被提出。最具代表性的是AdaBoost算法(Adaptive Boosting Algorithm),可以说,AdaBoost实现了PAC的理想。
对于分类问题而言,给定一个训练数据,求一个比较粗糙的分类器(即弱分类器)要比求一个精确的分类器(即强分类器)容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器,然后组合这些弱分类器,构成一个强分类器。大多数的提升方法都是改变训练数据的概率分布(训练数据中的各个数据点的权值分布),调用弱学习算法得到一个弱分类器,再改变训练数据的概率分布,再调用弱学习算法得到一个弱分类器,如此反复,得到一系列弱分类器。
这样,对于提升方法来说,有两个问题需要回答:一是在每一轮如何如何改变训练数据的概率分布;而是如何将多个弱分类器组合成一个强分类器。
关于第一个问题,AdaBoost的做法是,提高那些被前几轮弱分类器线性组成的分类器错误分类的的样本的权值。这样一来,那些没有得到正确分类的数据,由于权值加大而受到后一轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器”分而治之”。至于第二个问题,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
AdaBoost的巧妙之处就在于它将这些想法自然而然且有效地实现在一种算法里。
AdaBoost算法
输入:训练数据集T=(x1,y1),(x2,y2),…,(xN,yN),其中xi∈X⊆Rn,表示输入数据,yi∈Y=-1,+1,表示类别标签;弱学习算法。
输出:最终分类器G(x)。
流程:
初始化训练数据的概率分布,刚开始为均匀分布
D1=(w11,w12,…,w1N), 其中w1i=
, i=1,2,..,N . Dm表示在第m轮迭代开始前,训练数据的概率分布(或权值分布),wmi表示在第i个样本的权值,
计算Gm(x)在训练数据集上的分类误差率
更新训练数据的权值分布
这里,Zm是规范化因子
,它使Dm+1称为一个概率分布。将M个基本分类器进行线性组合
得到最终分类器
对AdaBoost算法作如下说明:
步骤(1) 初始时假设训练数据集具有均匀分布,即每个训练样本在弱分类器的学习中作用相同。
步骤(2) (c) αm表示Gm(x)在最终分类器中的重要性。由式(公式 2)可知,当em ≤1/2时,αm≥0,并且αm随着em的减小而增大,即意味着误差率越小的基本分类器在最终分类器中的作用越大。
(d) 式可以写成:
由此可知,被弱分类器Gm(x)误分类的样本的权值得以扩大,而被正确分类的样本的权值得以缩小。因此误分类样本在下一轮学习中起到更大的作用。不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用,这是AdaBoost的一个特点。
步骤(3) 这里,αm之和并不等于1。f(x)的符号决定实例x的类别,f(x)的绝对值表示分类的确信度。利用基本分类器进行线性组合得到最终分类器是AdaBoost的另一个特点。
AdaBoost的例子
例 1 给定如表 1所示训练数据。假设弱分类器由G(x)=sign(x-v)产生,其中v为常量,表示阀值。试用AdaBoost算法学习一个强分类器。
表 1 训练数据样本
序号 1 2 3 4 5 6 7 8 9 10
x 0 1 2 3 4 5 6 7 8 9
y 1 1 1 -1 -1 -1 1 1 1 -1
解
初始化训练数据的权值分布
当m=1,进行第一轮迭代
在权值分布为D1的情况下,用一根垂直扫描线从左到右扫描,会发现,阀值v取2.5时分类误差率最低,故基本分类器G1(x)=sign(x-2.5)。
,第7,8,9个实例被误分类。
=0.4236。
更新训练数据的权值分布:
分类器sign[f1(x)]在训练数据集上有3个误分类点,因此,继续迭代。
当m=2,进行第二轮迭代
在权值分布为D2的情况下,阀值v取8.5时分类误差率最低,故基本分类器G2(x)=sign(x-8.5)。
G2(x)在训练数据集上的误差率e2=0.07143+0.07143+0.07143+0.07143,第4,5,6个实例被错误分类。
计算G2(x)的系数:α2=0.6496。
更新训练数据的权值分布:
分类器sign[f2(x)]在训练数据集上有3个误分类点,因此,继续迭代。
当m=3,进行第三轮迭代
在权值分布为D3的情况下,阀值v取5.5时分类误差率最低,故基本分类器G3(x)=-sign(x-5.5),注意,这里符号反向了。
G3(x)在训练数据集上的误差率e3=0.0455+0.0455+0.0455+0.0455=0.1820,第1,2,3,10个实例被误分类。
计算G3(x)的系数:α2=0.7514。
更新训练数据的权值分布:
分类器sign[f3(x)]在训练数据集上的误分类点个数为0,因此,终止迭代。
于是,最终分类器为
注意,G1(x),G2(x)和G3(x),是一个sign函数,从图像看是一个方波图,而最终分类器G(x)也是一个方波图,由三个波形图叠加合成。从信号的角度看,这是振幅叠加。G1(x),G2(x)和G3(x)都是弱分类器,分类正确率仅大于0.5,但线性组合而成的分类器G(x)正确率是100%,是一个强分类器。
AdaBoost算法的训练误差分析
AdaBoost最基本的性质是它能在学习过程中不断减少训练误差,关于这个问题有下面的两个定理:
**定理 1 (AdaBoost的训练误差界****) **AdaBoost算法的最终分类器的训练误差界为
先推导如下:
( 定理**** 1 的证明@特级飞行员舒克有很大贡献)
这一定理说明,可以在每一轮选取最适当的Gm使得Zm最小,从而使训练误差下降最快。对二类分类问题,有如下结果:
定理 2 (二类分类问题AdaBoost的训练误差界)
因此等式
提升树之Adaboost算法的介绍
主要内容:
- 模型介绍
- 损失函数的介绍
- Adaboost分类算法步骤
- Adaboost回归算法步骤
- Adaboost函数语法
- 提升树之Adaboost算法的应用——信用卡是否违约的识别
1.模型介绍
提升树算法与线性回归模型的思想类似,所不同的是该算法实现了多棵基础决策树??(??)的加权运算,最具代表的提升树为AdaBoost算法,即

2.损失函数的介绍
对于Adaboost算法而言,每一棵基础决策树都是基于前一棵基础决策树的分类结果对样本点设置不同的权重,如果在前一棵基础决策树中将某样本点预测错误,就会增大该样本点的权重,否则会相应降低样本点的权重,进而再构建下一棵基础决策树,更加关注权重大的样本点。
所以,AdaBoost算法需要解决三大难题,即样本点的权重??????如何确定、基础决策树??(??)如何选择以及每一棵基础决策树所对应的权重????如何计算。



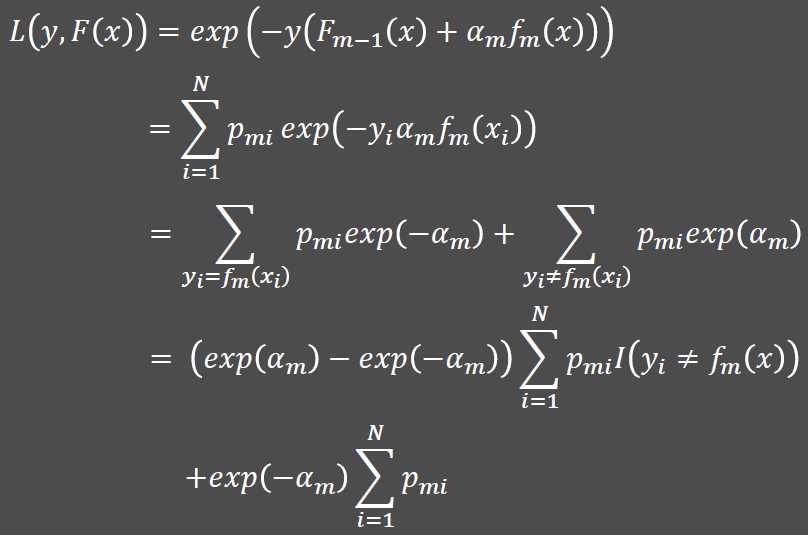

3.Adaboost分类算法步骤

4.Adaboost回归算法步骤

5.Adaboost函数语法


6.提升树之Adaboost算法的应用——信用卡是否违约的识别
数据集下载(下载后需要把第一行删除!):https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients
全部源代码为:
代码参考博客:https://www.cnblogs.com/tszr/p/10060935.html
以上是关于Adaboost算法的主要内容,如果未能解决你的问题,请参考以下文章