MySQL索引的Index method中btree和hash的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引的Index method中btree和hash的区别相关的知识,希望对你有一定的参考价值。
当分片索引不是纯整型的字符串时,只接受整型的内置 hash 算法是无法使用的。为此,stringhash 按照用户定义的起点和终点去截取分片索引字段中的部分字符,根据当中每个字符的二进制 unicode 值换算出一个长整型数值,然后就直接调用内置 hash 算法求解分片路由:先求模得到逻辑分片号,再根据逻辑分片号直接映射到物理分片。
用户需要在 rule.xml 中定义 partitionLength[] 和 partitionCount[] 两个数组和 hashSlice 二元组。
在 DBLE 的启动阶段,点乘两个数组得到模数,也是逻辑分片的数量
并且根据两个数组的叉乘,得到各个逻辑分片到物理分片的映射表(物理分片数量由 partitionCount[] 数组的元素值之和)
此外根据 hashSlice 二元组,约定把分片索引值中的第 4 字符到第 5 字符(字符串以 0 开始编号,编号 3 到编号 4 等于第 4 字符到第 5 字符)字符串用于 “字符串->整型”的转换
在 DBLE 的运行过程中,用户访问使用这个算法的表时,WHERE 子句中的分片索引值会被提取出来,取当中的第 4 个字符到第 5 字符,送入下一步
设置一个初始值为 0 的累计值,逐个取字符,把累计值乘以 31,再把这个字符的 unicode 值当成长整型加入到累计值中,如此类推直至处理完截取出来的所有字符,此时的累计值就能够代表用户的分片索引值,完成了 “字符串->整型” 的转换
对上一步的累计值进行求模,得到逻辑分片号
再根据逻辑分片号,查映射表,直接得到物理分片号
与MyCat的类似分片算法对比
请点击输入图片描述
两种算法在string转化为int之后,和 hash 分区算法相同,区别也继承了 hash 算法的区别。
开发注意点
【分片索引】1. 必须是字符串
【分片索引】2. 最大物理分片配置方法是,让 partitionCount[] 数组和等于 2880
例如:
<property name="partitionLength">1</property><property name="partitionCount">2880</property>
或
<property name="partitionLength">1,1</property><property name="partitionCount">1440,1440</property>
【分片索引】3. 最小物理分片配置方法是,让 partitionCount[] 数组和等于 1
例如
<property name="partitionLength">2880</property><property name="partitionCount">1</property>
【分片索引】4. partitionLength 和 partitionCount 被当做两个逗号分隔的一维数组,它们之间的点乘必须在 [1, 2880] 范围内
【分片索引】5. partitionLength 和 partitionCount 的配置对顺序敏感
<property name="partitionLength">512,256</property><property name="partitionCount">1,2</property>
和
<property name="partitionLength">256,512</property><property name="partitionCount">2,1</property>
是不同的分片结果
【分片索引】6. 分片索引字段长度小于用户指定的截取长度时,截取长度会安全减少到符合分片索引字段长度
【数据分布】1. 分片索引字段截取越长则越有利于数据均匀分布
【数据分布】2. 分片索引字段的内容重复率越低则越有利于数据均匀分布
运维注意点
【扩容】1. 预先过量分片,并且不改变 partitionCount 和 partitionLength 点乘结果,也不改变截取设置 hashSlice 时,可以避免数据再平衡,只需进行涉及数据的迁移
【扩容】2. 若需要改变 partitionCount 和 partitionLength 点乘结果或改变截取设置 hashSlice 时,需要数据再平衡
【缩容】1. 预先过量分片,并且不改变 partitionCount 和 partitionLength 点乘结果,也不改变截取设置 hashSlice 时,可以避免数据再平衡,只需进行涉及数据的迁移
【缩容】2. 若需要改变 partitionCount 和 partitionLength 点乘结果或改变截取设置 hashSlice 时,需要数据再平衡
配置注意点
【配置项】1. 在 rule.xml 中,可配置项为 <property name="partitionLength"> 、<property name="partitionCount"> 和 <property name="hashSlice">
【配置项】2.在 rule.xml 中配置 <property name="partitionLength"> 标签
内容形式为:<物理分片持有的虚拟分片数>[,<物理分片持有的虚拟分片数>,...<物理分片持有的虚拟分片数>]
物理分片持有的虚拟分片数必须是整型,物理分片持有的虚拟分片数从左到右与同顺序的物理分片数对应,partitionLength 和partitionCount 的点乘结果必须在 [1, 2880] 范围内
【配置项】3. 在 rule.xml 中配置 <property name="partitionCount"> 标签内容形式为:<物理分片数>[,<物理分片数>,...<物理分片数>]
其中物理分片数必须是整型,物理分片数按从左到右的顺序与同顺序的物理分片持有的虚拟分片数对应,物理分片的编号从左到右连续递进,partitionLength 和 partitionCount 的点乘结果必须在 [1, 2880] 范围内
【配置项】4. partitionLength 和 partitionCount 的语义是:持有partitionLength[i] 个虚拟分片的物理分片有 partitionCount[i] 个
例如
<property name="partitionLength">512,256</property><property name="partitionCount">1,2</property>
语义是持有 512 个逻辑分片的物理分片有 1 个,紧随其后,持有 256 个逻辑分片的物理分片有 2 个
【配置项】5.partitionLength 和 partitionCount 都对书写顺序敏感,
例如
<property name="partitionLength">512,256</property><property name="partitionCount">1,2</property>
分片结果是第一个物理分片持有头512个逻辑分片,第二个物理分片持有紧接着的256个逻辑分片,第三个物理分片持有最后256个逻辑分片,相对的
<property name="partitionLength">256,512</property><property name="partitionCount">2,1</property>
分片结果则是第一个物理分片持有头 256 个逻辑分片,第二个物理分片持有紧接着的 256 个逻辑分片,第三个物理分片持有最后 512 个逻辑分片
【配置项】6.partitionLength[] 的元素全部为 1 时,这时候partitionCount 数组和等于 partitionLength 和 partitionCount 的点乘,物理分片和逻辑分片就会一一对应,该分片算法等效于直接取余
【配置项】7.在 rule.xml 中配置标签,从分片索引字段的第几个字符开始截取到第几个字符:
若希望从首字符开始截取 k 个字符( k 为正整数),配置的内容形式可以为“ 0 : k ”、“ k ”或“ : k ”;
若希望从末字符开始截取 k 个字符( k 为正整数),则配置的内容形式可以为“ -k : 0 ”、“ -k ”或“ -k : ”;
若希望从头第 m 个字符起算截取 n 个字符( m 和 n 都是正整数),则先计算出 i = m - 1 和 j = i + n - 1,配置的内容形式为“ i : j ”;
若希望从尾第 m 个字符起算截取从尾算起的 n 个字符( m 和 n 都是正整数),则先计算出 i = -m + n - 1,配置的内容形式可以为“ -m : i ”;
若希望不截取,则配置的内容形式可以为“ 0 : 0 ”、“ 0 : ”、“ : 0 ”或 “ : ”
所以,对于 聚集索引 来说,你创建主键的时候,自动就创建了主键的聚集索引。
而普通索引(非聚集索引)的语法,大多数数据库都是通用的:
CREATE INDEX Syntax
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[index_type]
ON tbl_name (index_col_name,...)
[index_type]
index_col_name:
col_name [(length)] [ASC | DESC]
index_type:
USING BTREE | HASH | RTREE
[java] view plaincopy
-- 创建无索引的表格
create table testNoPK (
id int not null,
name varchar(10)
);
-- 创建普通索引
create index IDX_testNoPK_Name on testNoPK (name);本回答被提问者采纳
MySQL 5.6 Index Condition Pushdown
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作。ICP的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的where条件(pushed index condition,推送的索引条件),如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。ICP(优化器)尽可能的把index condition的处理从server层下推到storage engine层。storage engine使用索引过过滤不相关的数据,仅返回符合index condition条件的数据给server层。也是说数据过滤尽可能在storage engine层进行,而不是返回所有数据给server层,然后后再根据where条件进行过滤。使用ICP(mysql 5.6版本以前)和没有使用ICP的数据访问和提取过程如下(插图来在MariaDB Blog)
优化器没有使用ICP时,数据访问和提取的过程如下:
1) 当storage engine读取下一行时,首先读取索引元组(index tuple),然后使用索引元组在基表中(base table)定位和读取整行数据。
2) sever层评估where条件,如果该行数据满足where条件则使用,否则丢弃。
3) 执行1),直到最后一行数据。
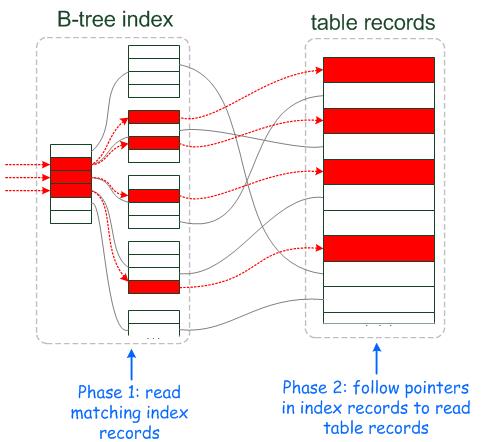
优化器使用ICP时,server层将会把能够通过使用索引进行评估的where条件下推到storage engine层。
数据访问和提取过程如下:
1) storage engine从索引中读取下一条索引元组。
2) storage engine使用索引元组评估下推的索引条件。如果没有满足where条件,storage engine将会处理下一条索引元组(回到上一步)。只有当索引元组满足下推的索引条件的时候,才会继续去基表中读取数据。
3) 如果满足下推的索引条件,storage engine通过索引元组定位基表的行和读取整行数据并返回给server层。
4) server层评估没有被下推到storage engine层的where条件,如果该行数据满足where条件则使用,否则丢弃。
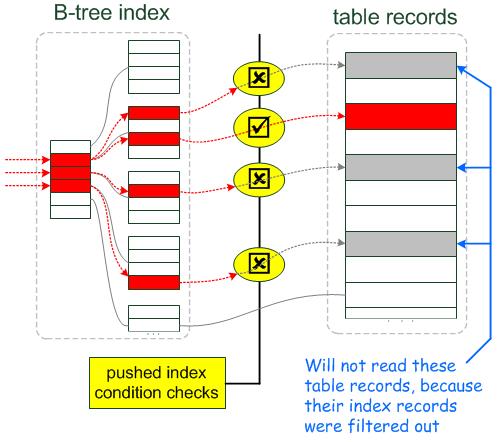
而使用ICP时,如果where条件的一部分能够通过使用索引中的字段进行评估,那么mysql server把这部分where条件下推到storage engine(存储引擎层)。存储引擎通过索引元组的索引列数据过滤不满足下推索引条件的数据行。
索引条件下推的意思就是筛选字段在索引中的where条件从server层下推到storage engine层,这样可以在存储引擎层过滤数据。由此可见,ICP可以减少存储引擎访问基表的次数和mysql server访问存储引擎的次数。
注意一下ICP的使用条件:
1.只能用于二级索引(secondary index)。
2.explain显示的执行计划中type值(join 类型)为range、 ref、 eq_ref或者ref_or_null。且查询需要访问表的整行数据,即不能直接通过二级索引的元组数据获得查询结果(索引覆盖)。
3.ICP可以用于MyISAM和InnnoDB存储引擎,不支持分区表(5.7将会解决这个问题)。
ICP的开启优化功能与关闭
MySQL5.6可以通过设置optimizer_switch([global|session],dynamic)变量开启或者关闭index_condition_push优化功能,默认开启。
mysql > set optimizer_switch=\'index_condition_pushdown=on|off\'
用explain查看执行计划时,如果执行计划中的Extra信息为"using index condition",表示优化器使用的index condition pushdown。
在mysql5.6以前,还没有采用ICP这种查询优化,where查询条件中的索引条件在某些情况下没有充分利用索引过滤数据。假设一个组合索引(多列索引)K包含(c1,c2,…,cn)n个列,如果在c1上存在范围扫描的where条件,那么剩余的c2,…,cn这n-1个上索引都无法用来提取和过滤数据(不管不管是唯一查找还是范围查找),索引记录没有被充分利用。即组合索引前面字段上存在范围查询,那么后面的部分的索引将不能被使用,因为后面部分的索引数据是无序。比如,索引key(a,b)中的元组数据为(0,100)、(1,50)、(1,100) ,where查询条件为 a < 2 and b = 100。由于b上得索引数据并不是连续区间,因为在读取(1,50)之后不再会读取(1,100),mysql优化器在执行索引区间扫描之后也不再扫描组合索引其后面的部分。
接下来我们来看看一个例子:

mysql> select version(); +-------------+ | version() | +-------------+ | 5.5.25a-log | +-------------+ 1 row in set (0.00 sec) mysql>
mysql> show create table rental\\G
*************************** 1. row ***************************
Table: rental
Create Table: CREATE TABLE `rental` (
`rental_id` int(11) NOT NULL AUTO_INCREMENT,
`rental_date` datetime NOT NULL,
`inventory_id` mediumint(8) unsigned NOT NULL,
`customer_id` smallint(5) unsigned NOT NULL,
`return_date` datetime DEFAULT NULL,
`staff_id` tinyint(3) unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`rental_id`),
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`),
KEY `idx_fk_inventory_id` (`inventory_id`),
KEY `idx_fk_customer_id` (`customer_id`),
KEY `idx_fk_staff_id` (`staff_id`),
CONSTRAINT `fk_rental_customer` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`customer_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_staff` FOREIGN KEY (`staff_id`) REFERENCES `staff` (`staff_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=16050 DEFAULT CHARSET=utf8
1 row in set (0.03 sec)
mysql>
在没有使用ICP情况下的查询:
mysql> explain select * from rental where rental_date = \'2006-02-14 15:16:03\' and customer_id >= 300 and customer_id <= 400; +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ | 1 | SIMPLE | rental | ref | rental_date,idx_fk_customer_id | rental_date | 8 | const | 181 | Using where | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ 1 row in set (0.00 sec) mysql>
优化器首先使用复合索引rental_date的首字段rental_date过滤出符合条件rental_date=\'2006-02-14 15:16:03\'的记录(执行计划中key字段显示rental_date),然后根据复合索引rental_date回表获取记录后,最终根据条件customer_id >= 300 and customer_id <= 400来过滤出最后的查询结果(执行计划中Extra字段显示为Using where)
下面看看开启ICP的情况(MySQL 5.6支持)
mysql> select version(); +-----------+ | version() | +-----------+ | 5.6.10 | +-----------+ 1 row in set (0.01 sec) mysql>
mysql> explain select * from rental where rental_date = \'2006-02-14 15:16:03\' and customer_id >= 300 and customer_id <= 400; +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ | 1 | SIMPLE | rental | ref | rental_date,idx_fk_customer_id | rental_date | 5 | const | 181 | Using index condition | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql>
Using index condition 就表示MySQL使用了ICP来优化查询,在检索的时候把条件customer_id的过滤操作下推到存储引擎层来完成。这样能降低不必要的IO访问。
1.首先存储引擎根据条件rental_date = \'2006-02-14 15:16:03\'和customer_id >= 300 and customer_id <= 400来过滤索引,在索引上过滤customer_id条件
2.根据索引过滤后的记录获取数据
参考资料
http://olavsandstaa.blogspot.co.uk/2011/04/mysql-56-index-condition-pushdown.html
以上是关于MySQL索引的Index method中btree和hash的区别的主要内容,如果未能解决你的问题,请参考以下文章