深入浅出iOS系统内核(3)— 内存管理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出iOS系统内核(3)— 内存管理相关的知识,希望对你有一定的参考价值。
参考技术A 本文参考《Mac OS X and ios Internals: To the Apple’s Core》 by Jonathan Levin文章内容主要是阅读这本书的读书笔记,建议读者掌握《操作系统》,了解现代操作系统的技术特点,再阅读本文可以事半功倍。
虽然iOS系统内核使用极简的微内核架构,但内容依然十分庞大,所以会分
系统架构 、 进程调度 、 内存管理 和 文件系统 四个部分进行阐述。
操作系统管理所有的硬件资源,操作系统内核管理最核心的资源CPU和内存。上一篇阐述了Mach通过进程管理CPU,本文主要阐述XNU和Mach如何高效的管理内存
按照传统,栈一般都是保存自动变量,正常情况栈由系统管理,但是在iOS中某些情况下,程序员也可以选择用栈来动态分配内存,方法是使用鲜为人知的alloca( ) 这个函数的原型和malloc( )是一样的,区别在于这个函数返回的指针是栈上的地址而不是堆中的地址。
从实现角度,alloca( )从两方面优于malloc( )
堆是由C语言运行时维护的用户态数据结构,通过堆的使用,程序可以不用直接在页面的层次处理内存分配。Darwin的libC 采用了一个基于分配区域(allocation zone)的特殊分配算法
在iOS中内存的管理是由在Mach层中进行的,BSD只是对Mach接口进行了POSIX封装,方便用户态进程调用。
XNU内存管理的核心机制是虚拟内存管理,在Mach 层中进行的,Mach 控制了分页器,并且向用户态导出了各种 vm_ 和 mach_vm_ 消息接口。 为方便用户态进程使用BSD对Mach 调用进行了封装,通过current_map( ) 获得当前的Mach 内存映射,最后再调用底层的Mach 函数。
BSD 的malloc 系列函数<bsd/sys/malloc.h> 头文件中。函数名为_MALLOC、_FREE、_REALLOC、_MALLOC_ZONE、_FREE_ZONE
mcache机制是BSD 提供的基于缓存的非常高效的内存分配方法。默认实现基于mach zone,通过mach zone提供预分配好的缓存内存。
mcache具有可扩展架构,可以使用任何后端 slab 分配器。
使用mcache 机制的主要优点是速度:内存分配和维护是在每一个 CPU 自有的cache中进行的,因此可以映射到CPU的物理cache,从而极大地提升访问速度。
Mach VM层支持VM pressure 的机制,这个机制是可用RAM量低到危险程度的处置,下面我们会详细讲,这里不展开。
当RAM量低到危险时,Mach的pageout 守护程序会查询一个进程列表,查询驻留页面数,然后向驻留页面数最高的进程发送NOTE_VM_PRESSURE ,会在进程队列中发出一个事件。被选中的进程会响应这个压力通知,iOS中的运行时会调用 didReceiveMemoryWarning 方法。
然而有些时候这些操作没有效果,当内存压力机制失败之后,** 非常时间要用非常手段 **, Jetsam机制介入。
当进程不能通过释放内存缓解内存压力时,Jestam机制开始介入。这是iOS 实现的一个低内存清理的处理机制。也称为Memorystatus,这个机制有点类似于Linux的“Out-of-Memory”杀手,最初的目的就是杀掉消耗太多内存的进程。Memorystatus维护了两个列表:
在iOS的用户态可以通过 sysctl(2)查询这些列表,优先级列表可以在用户态进行设置。
在iOS 5中,Jestsam/Memorystatus 和默认的freezer 结合在一起,实现了对进程的冷冻而不是杀死。通过这种方式可以提供更好的用户体验,因为数据不会丢失,而且当内存情况好转时进程可以安全恢复。(感谢@易步指出本段错误)
用户态也可以通过pid_suspend( ) 和 pid_resume( )控制进程的休眠。
iOS 定义了 pid_hibernate,通过发送kern_hibernation_wakeup信号唤醒kernel_hibernation_thread 线程,这个线程专用于对进程冷冻操作。
实际的进程休眠操作是由jestsam_hibernate_top_proc 完成的,这个函数通过task_freeze冷冻底层的任务。
冷冻操作需要遍历任务的vm_map,然后将vm_map 传递给默认的 freezer。
VM是Darwin系统内存管理的核心机制。
VM 机制主要通过内存对象(memory object)和分页器(pager)的形式管理内存。
Mach 虚拟内存的实现非常全面而且通用。这部分由两个层次构成:一层是和硬件相关的部分,另一层构建在这一层之上和硬件无关的公共层。OS X 和 iOS 使用的几乎一样的底层机制,硬件无关层以及之上的BSD 层中的机制都是一样的。
Mach 的 VM子系统可以说是和其要管理的内存一样复杂和充满了各种细节。然后从高层次看,可以看到两个层次:
虚拟内存这一层完全以一种机器无关的方式来管理虚拟内存。这一层通过几种关键的抽象表示虚拟内存:
Mach 允许使用多个分页器。事实上,默认就存在3~4个分页器。Mach 的分页器以外部实体的形式存在:是专业的任务,有点类似于其他系统上的内核交换(kernel-swapping)线程。Mach 的设计允许分页器和内核任务隔离开,设置允许用户态任务作为分页器。类似地,底层的后备存储也可以驻留在磁盘交换文件中(通过OS X 中的 default_pager 处理),可以映射到一个文件(由vnode_pager处理),可以是一个设备(由device_pager 处理)。注意:在Mach 中,每一个分页器处理的都是属于这个分页器的页面的请求,但是这些请求必须通过pageout 守护程序发出。这些守护程序(实际上就是内核线程)维护内核的页面表,并且判定哪些页面需要被清除出去。因此,这些守护程序维护的分页策略和分页器实现的分页操作是分开的。
物理内存的页面处理的是虚拟内存到物理内存的映射,因为虚拟内存中的内容最终总要存储在某个地方。这一层面只有一个抽象,那就是pmap,不过这个抽象非常重要,因为提供了机器无关的接口。这个接口隐藏了底层平台的细节,底层的细节需要在处理器层次进行分页操作,其中要处理的对象包括硬件页表项(page table entry,PTE)、翻译查找表(translation lookaside buffer,TLB)等。
每一个Mach 任务都要自己的虚拟内存空间,任务的struct task 中的 map 字段保存的就是这个虚拟内存空间。
vm_page_entry 中最关键的元素是vm_map_object,这是一个联合体,既可以包含另一个vm_map(作为子映射),也可以包含一个vm_object_t(由于这是一个联合体,所以具体的内容需要用布尔字段is_sub_map 来判断)。vm_object 是一个巨大的数据结构,其中包含了处理底层虚拟内存所需要的所有数据。vm_object的数据结构中的大部分字段都是用位表示的标志。这些字段表示了底层的内存状态(联动、物理连续和持久化等状态)和一些计数器(引用计数、驻留计数和联动计数等)。不过有3个字段需要特别注意:
memq:vm_page 对象的链表,每一项都表示一个驻留内存的虚拟内存页面。尽管一个对象可以表示一个单独的页面,但是多数情况下一个对象可以包含多个页面,所以每一个页面关联到一个对象时都会有一个偏移值
page:memory_object 对象,这是指向分页器的Mach 端口。分页器将未驻留内存的页面关联到后备存储,后备存储可以是内存映射的文件、设备和交换文件,后备存储保存了没有驻留内存的页面。换句话说,分页器(可以有多个)负责将数据从后备存储移入内存以及将数据从内存移出到后备存储。分页器对于虚拟内存子系统来说极为重要
internal:vm_page 中众多标志位之一,如果这个位为真,那么表示这个对象是由内核内部使用的。这个标志位的值决定了对象中的页面会进入哪一个pageout队列
尽管内核和用户空间一样,基本上只在虚拟地址空间内操作,但是虚拟内存最终还是要翻译为物理地址的。机器的RAM 实际上是虚拟内存中开的窗口,允许程序访问虚拟内存是有限的,而且通常是不连续的区域,这些区域的上线就是机器上安装的内存。而虚拟内存中其他部分则要么延迟分配,要么共享,要么被交换到外部存储中,外部存储通常是磁盘。
然而虚拟内存和具体的底层架构相关。尽管虚拟内存和物理内存的概念在所有架构上本周都是一样的,但是具体的实现细节则各有千秋。XNU 构建与Mach 的物理内存抽象层之上,这个的抽象层成为pmap。pmap 从设计上对物理内存提供了一个统一的接口,屏蔽了架构相关的区别。这对于XNU来说非常有用,因为XNU支持的物理内存的架构包括以前的PowerPC,现在主要是Intel,然后在iOS 中还支持ARM。
Mach 的pmap 层逻辑上由一下两个子层构成:
Mach Zone的概念相当于Linux的内存缓存(memory cache)和Windows 的Pool。Zone 是一种内存区域,用于快速分配和是否频繁使用的固定大小的对象。Zone的API是内核内部使用的,在用户态不能访问。Mach中Zone的使用非常广泛。
所有的zone 内存实际上都是在调用zinit( )时预先分配好的(zinit( )通过底层内存分配器kernel_memory_allocate( )分配内存)zalloc( )实际上是对REMOVE_FROM_ZONE 宏的封装,作用是返回zone的空闲列表中的下一个元素(如果zone已满,则调用kernel_memory_allocate( )分配这个zone在定义的alloc_size字节)。zfree( ) 使用的是相反功能的宏 ADD_TO_ZONE。这两个函数都会执行合理数量的参数检查,不过这些检查帮助不大:过去zone分配相关的bug已经导致了数据可以被黑客利用的内存损坏。zalloc( ) 最重要的客户是内核中的kalloc( ),这个函数从kalloc.*系列zone中分配内存。BSD的mcache机制也会从自己的zone中分配内存。BSD内核zone也是如此,BSD内核zone直接构建与Mach的zone之上。
进程的内存需求早晚会超过可用的RAM,系统必须有一种方法能够将不活动的页面备份起来,并且从RAM中删除,腾出更多的RAM给活动的页面使用,至少暂时能够满足活动页面的需求。在其他操作系统中,这个工作专门是由专门的内核线程完成的。在Mach 中,这些专门的任务称为分页器(pager),分页器可以是内核线程,设置建议是外部的用户态服务程序。
Mach分页器是一个内存管理器,负责将虚拟内存备份到某个特定类型的后备存储中。当内存容量不足,内存页面需要被交换出内存是,后备存储保存内存页面的内容:当换出的内存页面需要被使用时,将内存的页面恢复到RAM中。只有“脏”页面才需要进行上述的换出和换入,因为“脏”页面是在内存中修改过的页面,要从RAM中剔除时必须保存到磁盘中防止数据丢失。
要注意的是,这里提到的分页器仅仅实现了各自负责的内存对象的分页操作,这些分页器不会控制系统的分页策略。分页策略是有vm_pageout 守护线程负责的。
iOS 和 OS X 中XNU 包含的分页器种类都是一样的。下表是XNU中的内存分页器的多种类型:
pageout 守护程序其实不是一个真的守护程序,而是一个线程。而且不是一般的线程:当kernel_bootstarp_thread( ) 完成内核初始化工作并且没有其他事情可做时,就调用vm_pageout( ) 成为了pageour 守护程序, vm_pageout( ) 永远不返回。这个线程管理页面交换的策略,判断哪些页面需要写回到其后备存储。
vm_pageout( ) 函数讲kernel_bootstrap_thread 线程转变为pageout 守护程序,这个函数实际上重新设置了这个线程。设置完成后,调用vm_pageout_continute( ),这个函数周期性地唤醒并执行vm_page_scan( ),维护4个页面表(称为页面队列)。系统中的每一个vm_page 都通过pageq字段绑定这4个队列中的一个:
垃圾回收线程(vm_pageout_garbage_collect( ))偶尔会被vm_pageout_scan( ) 通过其续体唤醒。垃圾回收机制线程处理4个方面的垃圾回收工作:
vm_pageout( ) 守护程序处理的只是交换的一个方向,从物理内存换出到后备存储。而另外一个方向是页面换入,则是发生在页面错误的时候处理的。这个逻辑非常复杂,简化为一下步骤:
页错误有很多种,上述只是其中一种,其他类型的也错误还包括:
VM系统是Mach中最重要最复杂而且最不好理解的子系统。Mach的内存管理核心是分页器,分页器允许将虚拟内存扩展到各种后背存储介质上:交换文件、内存映射文件、设备、甚至远程主机。
iOS中提高内存使用率的Freezer,以及处理内存耗尽的pageout守护程序。
https://www.amazon.com/Mac-OS-iOS-Internals-Apples/dp/1118057651/ref=sr_1_2?ie=UTF8&qid=1331298923&sr=8-2
https://developer.apple.com/library/content/documentation/Darwin/Conceptual/KernelProgramming/About/About.html
第一次作业:基于Linux操作系统深入源码进程模型分析
1.Linux操作系统的简易介绍
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。
(1)内核
内核是操作系统的核心,具有很多最基本功能,如虚拟内存、多任务、共享库、需求加载、可执行程序和TCP/IP网络功能。Linux内核的模块分为以下几个部分:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信、系统的初始化和系统调用等。
(2)shell
shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行,是一个命令解释器。另外,shell编程语言具有普通编程语言的很多特点,用这种编程语言编写的shell程序与其他应用程序具有同样的效果。
(3)文件系统
文件系统是文件存放在磁盘等存储设备上的组织方法。Linux系统能支持多种目前流行的文件系统,如EXT2、EXT3、FAT、FAT32、VFAT和ISO9660。
(4)应用程序
标准的Linux系统一般都有一套都有称为应用程序的程序集,它包括文本编辑器、编程语言、XWindow、办公套件、Internet工具和数据库等。
2.Linux操作系统的进程组织
(1)什么是进程
进程是处于执行期的程序以及它所包含的所有资源的总称,包括虚拟处理器,虚拟空间,寄存器,堆栈,全局数据段等。
在Linux中,每个进程在创建时都会被分配一个数据结构,称为进程控制(Process Control Block,简称PCB)。PCB中包含了很多重要的信息,供系统调度和进程本身执行使用。所有进程的PCB都存放在内核空间中。PCB中最重要的信息就是进程PID,内核通过这个PID来唯一标识一个进程。PID可以循环使用,最大值是32768。init进程的pid为1,其他进程都是init进程的后代。
除了进程控制块(PCB)以外,每个进程都有独立的内核堆栈(8k),一个进程描述符结构,这些数据都作为进程的控制信息储存在内核空间中;而进程的用户空间主要存储代码和数据。
查看进程:
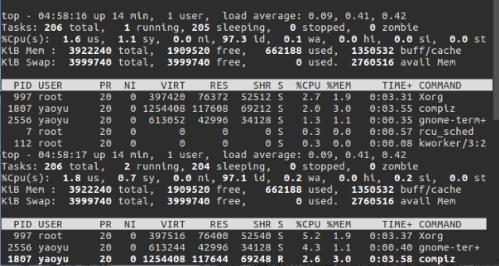
(2)进程创建
进程是通过调用::fork(),::vfork()【只复制task_struct和内核堆栈,所以生成的只是父进程的一个线程(无独立的用户空间)。】和::clone()【功能强大,带了许多参数。::clone()可以让你有选择性的继承父进程的资源,既可以选择像::vfork()一样和父进程共享一个虚拟空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系。】系统调用创建新进程。在内核中,它们都是调用do_fork实现的。传统的fork函数直接把父进程的所有资源复制给子进程。而Linux的::fork()使用写时拷贝页实现,也就是说,父进程和子进程共享同一个资源拷贝,只有当数据发生改变时,数据才会发生复制。通常的情况,子进程创建后会立即调用exec(),这样就避免复制父进程的全部资源。
#fork():父进程的所有数据结构都会复制一份给子进程(写时拷贝页)。当执行fork()函数后,会生成一个子进程,子进程的执行从fork()的返回值开始,且代码继续往下执行
以下代码中,使用fork()创建了一个子进程。返回值pId有两个作用:一是判断fork()是否正常执行;二是判断fork()正常执行后如何区分父子进程。
1 #代码示例: 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <unistd.h> 5 6 int main (int argc, char ** argv) { 7 int flag = 0; 8 pid_t pId = fork(); 9 if (pId == -1) { 10 perror("fork error"); 11 exit(EXIT_FAILURE); 12 } else if (pId == 0) { 13 int myPid = getpid(); 14 int parentPid = getppid(); 15 16 printf("Child:SelfID=%d ParentID=%d \\n", myPid, parentPid); 17 flag = 123; 18 printf("Child:flag=%d %p \\n", flag, &flag); 19 int count = 0; 20 do { 21 count++; 22 sleep(1); 23 printf("Child count=%d \\n", count); 24 if (count >= 5) { 25 break; 26 } 27 } while (1); 28 return EXIT_SUCCESS; 29 } else { 30 printf("Parent:SelfID=%d MyChildPID=%d \\n", getpid(), pId); 31 flag = 456; 32 printf("Parent:flag=%d %p \\n", flag, &flag); // 连地址都一样,说明是真的完全拷贝,但值已经是不同的了.. 33 int count = 0; 34 do { 35 count++; 36 sleep(1); 37 printf("Parent count=%d \\n", count); 38 if (count >= 2) { 39 break; 40 } 41 } while (1); 42 } 43 44 return EXIT_SUCCESS; 45 }
(3)进程撤销
进程通过调用exit()退出执行,这个函数会终结进程并释放所有的资源。父进程可以通过wait4()查询子进程是否终结。进程退出执行后处于僵死状态,直到它的父进程调用wait()或者waitpid()为止。父进程退出时,内核会指定线程组的其他进程或者init进程作为其子进程的新父进程。当进程接收到一个不能处理或忽视的信号时,或当在内核态产生一个不可恢复的CPU异常而内核此时正代表该进程在运行,内核可以强迫进程终止。
(4)进程管理
内核把进程信息存放在叫做任务队列(task list)的双向循环链表中(内核空间)。链表中的每一项都是类型为task_struct,称为进程描述符结构(process descriptor),包含了一个具体进程的所有信息,包括打开的文件,进程的地址空间,挂起的信号,进程的状态等。

Linux通过slab分配器分配task_struct,这样能达到对象复用和缓存着色(通过预先分配和重复使用task_struct,可以避免动态分配和释放所带来的资源消耗)。

struct task_struct { volatile long state; pid_t pid; unsigned long timestamp; unsigned long rt_priority; struct mm_struct *mm, *active_mm }
对于向下增长的栈来说,只需要在栈底(对于向上增长的栈则在栈顶)创建一个新的结构struct thread_info,使得在汇编代码中计算其偏移量变得容易。
#在x86上,thread_info结构在文件<asm/thread_info.h>中定义如下:
struct thread_info{ struct task_struct *任务 struct exec_domain *exec_domain; unsigned long flags; unsigned long status; __u32 cpu; __s32 preempt_count; mm_segment_t addr_limit; struct restart_block restart_block; unsigned long previous_esp; _u8 supervisor_stack[0]; };
内核把所有处于TASK_RUNNING状态的进程组织成一个可运行双向循环队列。调度函数通过扫描整个可运行队列,取得最值得执行的进程投入执行。避免扫描所有进程,提高调度效率。
#进程调度使用schedule()函数来完成,下面我们从分析该函数开始,代码如下: 1 asmlinkage __visible void __sched schedule(void) 2 { 3 struct task_struct *tsk = current; 4 5 sched_submit_work(tsk); 6 __schedule(); 7 } 8 EXPORT_SYMBOL(schedule);
#在第4段进程调度中将具体讲述功能实现
(5)进程内核堆栈
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:thread_info和进程的内核堆栈。
进程处于内核态时使用不同于用户态堆栈,内核控制路径所用的堆栈很少,因此对栈和描述符来说,8KB足够了。

3.Linux操作系统的进程状态转换
有以下进程状态:
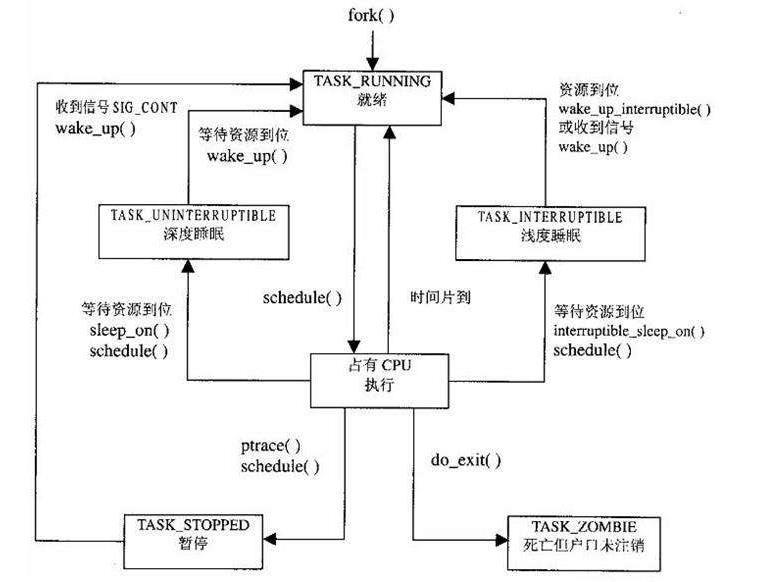
进程状态的转换:
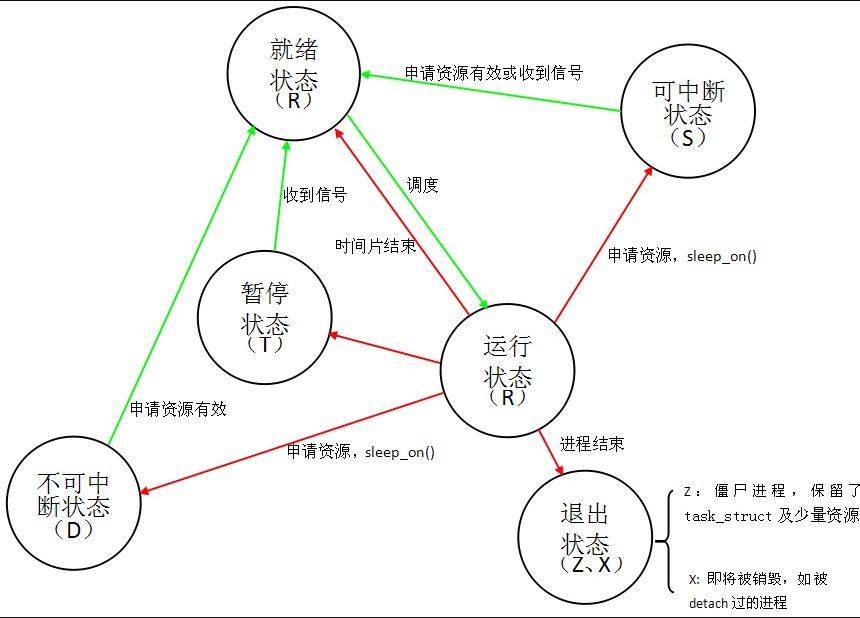
具体转换分析:
(1)进程的初始状态
进程是通过fork系列的系统调用(fork、clone、vfork)来创建的,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有。)那么既然调用进程处于TASK_RUNNING状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于TASK_RUNNING状态。另外,在系统调用调用clone和内核函数kernel_thread也接受CLONE_STOPPED选项,从而将子进程的初始状态置为 TASK_STOPPED。
(2)进程状态变迁
进程自创建以后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向——从TASK_RUNNING状态变为非TASK_RUNNING状态、或者从非TASK_RUNNING状态变为TASK_RUNNING状态。也就是说,如果给一个TASK_INTERRUPTIBLE状态的进程发送SIGKILL信号,这个进程将先被唤醒(进入 TASK_RUNNING状态),然后再响应SIGKILL信号而退出(变为TASK_DEAD状态)。并不会从TASK_INTERRUPTIBLE状态直接退出。进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
而进程从TASK_RUNNING状态变为非TASK_RUNNING状态,则有两种途径:
- 响应信号而进入TASK_STOPED状态、或TASK_DEAD状态;
- 执行系统调用主动进入TASK_INTERRUPTIBLE状态(如nanosleep系统调用)、或TASK_DEAD状态(如exit 系统调用);或由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
4.Linux操作系统的进程调度
毋庸置疑,我们使用schedule()函数来完成进程调度,接下来就来看看进程调度的代码以及实现过程吧。
1 asmlinkage __visible void __sched schedule(void) 2 { 3 struct task_struct *tsk = current; 4 5 sched_submit_work(tsk); 6 __schedule(); 7 } 8 EXPORT_SYMBOL(schedule);
第3行获取当前进程描述符指针,存放在本地变量tsk中。第6行调用__schedule(),代码如下(kernel/sched/core.c):


1 static void __sched __schedule(void) 2 { 3 struct task_struct *prev, *next; 4 unsigned long *switch_count; 5 struct rq *rq; 6 int cpu; 7 8 need_resched: 9 preempt_disable(); 10 cpu = smp_processor_id(); 11 rq = cpu_rq(cpu); 12 rcu_note_context_switch(cpu); 13 prev = rq->curr; 14 15 schedule_debug(prev); 16 17 if (sched_feat(HRTICK)) 18 hrtick_clear(rq); 19 20 /* 21 * Make sure that signal_pending_state()->signal_pending() below 22 * can\'t be reordered with __set_current_state(TASK_INTERRUPTIBLE) 23 * done by the caller to avoid the race with signal_wake_up(). 24 */ 25 smp_mb__before_spinlock(); 26 raw_spin_lock_irq(&rq->lock); 27 28 switch_count = &prev->nivcsw; 29 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { 30 if (unlikely(signal_pending_state(prev->state, prev))) { 31 prev->state = TASK_RUNNING; 32 } else { 33 deactivate_task(rq, prev, DEQUEUE_SLEEP); 34 prev->on_rq = 0; 35 36 /* 37 * If a worker went to sleep, notify and ask workqueue 38 * whether it wants to wake up a task to maintain 39 * concurrency. 40 */ 41 if (prev->flags & PF_WQ_WORKER) { 42 struct task_struct *to_wakeup; 43 44 to_wakeup = wq_worker_sleeping(prev, cpu); 45 if (to_wakeup) 46 try_to_wake_up_local(to_wakeup); 47 } 48 } 49 switch_count = &prev->nvcsw; 50 } 51 52 if (prev->on_rq || rq->skip_clock_update < 0) 53 update_rq_clock(rq); 54 55 next = pick_next_task(rq, prev); 56 clear_tsk_need_resched(prev); 57 clear_preempt_need_resched(); 58 rq->skip_clock_update = 0; 59 60 if (likely(prev != next)) { 61 rq->nr_switches++; 62 rq->curr = next; 63 ++*switch_count; 64 65 context_switch(rq, prev, next); /* unlocks the rq */ 66 /* 67 * The context switch have flipped the stack from under us 68 * and restored the local variables which were saved when 69 * this task called schedule() in the past. prev == current 70 * is still correct, but it can be moved to another cpu/rq. 71 */ 72 cpu = smp_processor_id(); 73 rq = cpu_rq(cpu); 74 } else 75 raw_spin_unlock_irq(&rq->lock); 76 77 post_schedule(rq); 78 79 sched_preempt_enable_no_resched(); 80 if (need_resched()) 81 goto need_resched; 82 }
第9行禁止内核抢占。第10行获取当前的cpu号。第11行获取当前cpu的进程运行队列。第13行将当前进程的描述符指针保存在prev变量中。第55行将下一个被调度的进程描述符指针存放在next变量中。第56行清除当前进程的内核抢占标记。第60行判断当前进程和下一个调度的是不是同一个进程,如果不是的话,就要进行调度。第65行,对当前进程和下一个进程的上下文进行切换(调度之前要先切换上下文)。下面看看该函数(kernel/sched/core.c):
1 context_switch(struct rq *rq, struct task_struct *prev, 2 struct task_struct *next) 3 { 4 struct mm_struct *mm, *oldmm; 5 6 prepare_task_switch(rq, prev, next); 7 8 mm = next->mm; 9 oldmm = prev->active_mm; 10 /* 11 * For paravirt, this is coupled with an exit in switch_to to 12 * combine the page table reload and the switch backend into 13 * one hypercall. 14 */ 15 arch_start_context_switch(prev); 16 17 if (!mm) { 18 next->active_mm = oldmm; 19 atomic_inc(&oldmm->mm_count); 20 enter_lazy_tlb(oldmm, next); 21 } else 22 switch_mm(oldmm, mm, next); 23 24 if (!prev->mm) { 25 prev->active_mm = NULL; 26 rq->prev_mm = oldmm; 27 } 28 /* 29 * Since the runqueue lock will be released by the next 30 * task (which is an invalid locking op but in the case 31 * of the scheduler it\'s an obvious special-case), so we 32 * do an early lockdep release here: 33 */ 34 #ifndef __ARCH_WANT_UNLOCKED_CTXSW 35 spin_release(&rq->lock.dep_map, 1, _THIS_IP_); 36 #endif 37 38 context_tracking_task_switch(prev, next); 39 /* Here we just switch the register state and the stack. */ 40 switch_to(prev, next, prev); 41 42 barrier(); 43 /* 44 * this_rq must be evaluated again because prev may have moved 45 * CPUs since it called schedule(), thus the \'rq\' on its stack 46 * frame will be invalid. 47 */ 48 finish_task_switch(this_rq(), prev); 49 }
上下文切换一般分为两个,一个是硬件上下文切换(指的是cpu寄存器,要把当前进程使用的寄存器内容保存下来,再把下一个程序的寄存器内容恢复),另一个是切换进程的地址空间(说白了就是程序代码)。进程的地址空间(程序代码)主要保存在进程描述符中的struct mm_struct结构体中,因此该函数主要是操作这个结构体。第17行如果被调度的下一个进程地址空间mm为空,说明下个进程是个线程,没有独立的地址空间,共用所属进程的地址空间,因此第18行将上个进程所使用的地址空间active_mm指针赋给下一个进程的该域,下一个进程也使用这个地址空间。第22行,如果下个进程地址空间不为空,说明下个进程有自己的地址空间,那么执行switch_mm切换进程页表。第40行切换进程的硬件上下文。 switch_to函数代码如下(arch/x86/include/asm/switch_to.h):
1 __visible __notrace_funcgraph struct task_struct * 2 __switch_to(struct task_struct *prev_p, struct task_struct *next_p) 3 { 4 struct thread_struct *prev = &prev_p->thread, 5 *next = &next_p->thread; 6 int cpu = smp_processor_id(); 7 struct tss_struct *tss = &per_cpu(init_tss, cpu); 8 fpu_switch_t fpu; 9 10 /* never put a printk in __switch_to... printk() calls wake_up*() indirectly */ 11 12 fpu = switch_fpu_prepare(prev_p, next_p, cpu); 13 14 /* 15 * Reload esp0. 16 */ 17 load_sp0(tss, next); 18 19 /* 20 * Save away %gs. No need to save %fs, as it was saved on the 21 * stack on entry. No need to save %es and %ds, as those are 22 * always kernel segments while inside the kernel. Doing this 23 * before setting the new TLS descriptors avoids the situation 24 * where we temporarily have non-reloadable segments in %fs 25 * and %gs. This could be an issue if the NMI handler ever 26 * used %fs or %gs (it does not today), or if the kernel is 27 * running inside of a hypervisor layer. 28 */ 29 lazy_save_gs(prev->gs); 30 31 /* 32 * Load the per-thread Thread-Local Storage descriptor. 33 */ 34 load_TLS(next, cpu); 35 36 /* 37 * Restore IOPL if needed. In normal use, the flags restore 38 * in the switch assembly will handle this. But if the kernel 39 * is running virtualized at a non-zero CPL, the popf will 40 * not restore flags, so it must be done in a separate step. 41 */ 42 if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl)) 43 set_iopl_mask(next->iopl); 44 45 /* 46 * If it were not for PREEMPT_ACTIVE we could guarantee that the 47 * preempt_count of all tasks was equal here and this would not be 48 * needed. 49 */ 50 task_thread_info(prev_p)->saved_preempt_count = this_cpu_read(__preempt_count); 51 this_cpu_write(__preempt_count, task_thread_info(next_p)->saved_preempt_count); 52 53 /* 54 * Now maybe handle debug registers and/or IO bitmaps 55 */ 56 if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV || 57 task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT)) 58 __switch_to_xtra(prev_p, next_p, tss); 59 60 /* 61 * Leave lazy mode, flushing any hypercalls made here. 62 * This must be done before restoring TLS segments so 63 * the GDT and LDT are properly updated, and must be 64 * done before math_state_restore, so the TS bit is up 65 * to date. 66 */ 67 arch_end_context_switch(next_p); 68 69 this_cpu_write(kernel_stack, 70 (unsigned long)task_stack_page(next_p) + 71 THREAD_SIZE - KERNEL_STACK_OFFSET); 72 73 /* 74 * Restore %gs if needed (which is common) 75 */ 76 if (prev->gs | next->gs) 77 lazy_load_gs(next->gs); 78 79 switch_fpu_finish(next_p, fpu); 80 81 this_cpu_write(current_task, next_p); 82 83 return prev_p; 84 }
该函数主要是对刚切换过来的新进程进一步做些初始化工作。比如第34将该进程使用的线程局部存储段(TLS)装入本地cpu的全局描述符表。第84行返回语句会被编译成两条汇编指令,一条是将返回值prev_p保存到eax寄存器,另外一个是ret指令,将内核栈顶的元素弹出eip寄存器,从这个eip指针处开始执行,也就是上个函数第17行所压入的那个指针。一般情况下,被压入的指针是上个函数第20行那个标号1所代表的地址,那么从__switch_to函数返回后,将从标号1处开始运行。
需要注意的是,对于已经被调度过的进程而言,从__switch_to函数返回后,将从标号1处开始运行;但是对于用fork(),clone()等函数刚创建的新进程(未调度过),将进入ret_from_fork()函数,因为do_fork()函数在创建好进程之后,会给进程的thread_info.ip赋予ret_from_fork函数的地址,而不是标号1的地址,因此它会跳入ret_from_fork函数。后边我们在分析fork系统调用的时候,就会看到。
5.对于Linux操作系统进程模型的一些个人看法
有一个形象的比喻:想象一位知识渊博、经验丰富的工程建筑设计师正在为一个公司设计总部。他有公司建筑的设计图,有所需的建筑材料和工具:水泥、钢筋、木板、挖掘机、吊升机、石钻头等。在这个比喻中,设计图就是程序(即用适当形式描述的算法),工程建筑师就是处理器(CPU),而建筑的各种材料就是输入数据。进程就是建筑工程设计师阅读设计图、取来各种材料和工具以及管理工人员工和分配资源、最后施工等一系列动作的总和,在过程中工程建筑师还需要遵循许多设计的规范和理念(模型),最后完成的公司总部就是软件或者可以实现某种功能的源代码。
这里说明的是进程是某种类型的一个活动,它有程序、输入、输出以及状态。单个处理器可以被若干进程共享,它使用某种调度算法决定何时停止一个进程的工作,并转而为另一个进程提供服务。那么Linux操作系统进程模型就是活动的规范,规范的出现创新让许多实现过程更加系统完整、安全可靠、速度效率等。
就像人类基于理论实践伟大的工程设计智慧经验结晶,Linux操作系统是系统、效率、安全的,而且通过商业公司、庞大的社区群体、操作系统爱好者是在往前改善的,但如果有一天Linux操作系统闭源了,只有国内开放了源代码,还尚未掌握核心技术,卡住脖子怎么办?我们不能拥有完完全全拿来即用的心态,还需扎实掌握基础知识,提高自我创新意识。对于Linux操作系统进程模型,深入理解它,你会发现在Linux操作系统的应用实践上会愈加效率,同时通过它你可以实现更多好玩的操作。
6.参考资料
源码地址(https://elixir.bootlin.com/linux/v4.6/source)
脚本之家(http://www.jb51.net/)
CSDN博客(https://blog.csdn.net/)
百度知道(https://zhidao.baidu.com/)
以上是关于深入浅出iOS系统内核(3)— 内存管理的主要内容,如果未能解决你的问题,请参考以下文章