SQL查询,如何去除重复的记录?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL查询,如何去除重复的记录?相关的知识,希望对你有一定的参考价值。
现在有一个文章评论系统,每篇文章每个用户只有一条评论有效,多回复不进行统计,比如:
评论ID 文章AID 用户UID
1 20 1
2 20 2
3 30 1
4 30 3
5 30 1
6 40 5
如果想得到某个文章aid对应有多少条有效评论,sql查询怎么写?请注意,每个AID每个用户重复评论只计算一条有效,比如上面的数据应该是5条有效评论,aid为30的文章有一个用户发了2条评论,去掉一个重复。
首先,先说明一个问题。这样的结果出现,说明系统设计是有问题的。
其次
删除重复数据,你要提供你是什么数据库。
不同数据库会有不同的解决方案。
关键字Distinct 去除重复,如下列SQL,去除Test相同的记录;
1. select distinct Test from Table
2. 如果是要删除表中存在的重复记录,那就逻辑处理,如下:
3. select Test from Table group by Test having count(test)>1
4. 先查询存在重复的数据,后面根据条件删除
还有一个更简单的方法可以尝试一下:
select aid, count(distinct uid) from 表名 group by aid
这是sqlserver 的写法。
如图一在数据表中有两个膀胱冲洗重复的记录。
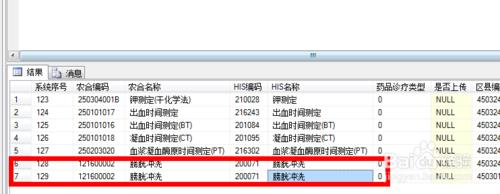
2
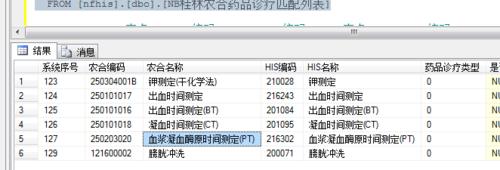
可以通过sql语句“select *from 表名 where 编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)”来查询出变种所有重复的记录如图二
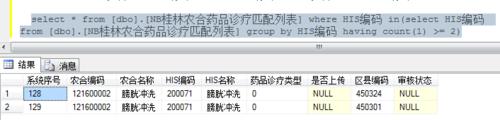
3
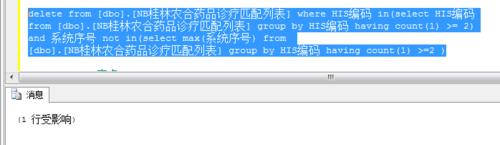
通过sql语句"
delete from 表名 where
编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)
and 编码 not in (select max(编码)from 表名 group by 编码 having count(1) >=2)
"来删除重复的记录只保留编码最大的记录
关键字Distinct 去除重复,如下列SQL,去除Test相同的记录;
select distinct Test from Table
如果是要删除表中存在的重复记录,那就逻辑处理,如下:
select Test from Table group by Test having count(test)>1
先查询存在重复的数据,后面根据条件删除
sql 单表/多表查询去除重复记录
单表distinct
多表group by
group by 必须放在 order by 和 limit之前,不然会报错
************************************************************************************
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)> 参考技术C 上面的回答可以,不过我觉得还有更简单的方法:
select aid, count(distinct uid) from 表名 group by aid
这是sqlserver 的写法。。。本回答被提问者和网友采纳 参考技术D #查询班级中名字不同的所有学生(将名字相同的学生,只取出一个)
select * from student where sid in (select max(sid) from student group by sname)
#查询班级中所有名字重复的学生姓名
select * from student where sname in (select sname from student group by sname having count(1)>=2 );
连接多个表后如何从sql查询结果中删除重复记录
【中文标题】连接多个表后如何从sql查询结果中删除重复记录【英文标题】:How to remove duplicate records from sql query result after joining multiple tables 【发布时间】:2018-02-24 17:23:13 【问题描述】:非常感谢您对以下内容的任何帮助;
使用以下脚本连接多个表以收集我需要的信息后,我现在在结果中有多个重复记录。
我无法使用 distinct,所以在导出之前如何去除 select 语句中的重复结果?
use Cohort
select *
from patients
join immunisations
on patients.patient_id = immunisations.patient_id
join titles
on patients.title_id = titles.title_id
join courses
on immunisations.course_id = courses.course_id
join departments
on patients.patient_id = departments.department_id
join employees
on patients.patient_id = employees.post_title_id
最好的问候
路易丝
【问题讨论】:
Distinct 不起作用,因为您使用的是 *.您需要指定要保留的列并再次尝试区分。 在此处发布问题之前,您需要阅读 SQL 基础知识。了解如何使用GROUP BY 子句:docs.microsoft.com/en-us/sql/t-sql/queries/…
How do I use T-SQL Group By的可能重复
为什么不能使用 distinct?样本数据和预期输出是什么?整行是重复的还是您只关注单个列?
@RossBush 当然它会“工作”——如果“工作”是指成功执行。设置不计; cte as (select * from (values (1, 's'), (2, 'b'), (1, 's'), (3, 'z')) as b(id, val)) 选择* 与 cte order by id 不同;鉴于连接和缺少列列表,distinct 在这里是否有用值得怀疑。
【参考方案1】:
@Rossbush @SMor
大家好,你们两个帮我解决了这个问题,我真的很感激。
这就是我所做的工作;
use Cohort
select distinct
patients.first_name,
patients.last_name,
patients.dob,
titles.description,
courses.description,
departments.description,
immunisations.date_due,
immunisations.date_given,
immunisations.comments
from patients
join immunisations on patients.patient_id = immunisations.patient_id
join titles on patients.title_id = titles.title_id
join courses on immunisations.course_id = courses.course_id
join departments on patients.patient_id = departments.department_id
join employees on patients.patient_id = employees.post_title_id
非常感谢
路易丝
【讨论】:
以上是关于SQL查询,如何去除重复的记录?的主要内容,如果未能解决你的问题,请参考以下文章