如何在linux中查询redis的数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在linux中查询redis的数据相关的知识,希望对你有一定的参考价值。
1、执行如图是命令,查看redis服务是否启动。
2、执行命令“redis-cli”进入redis命令行界面。

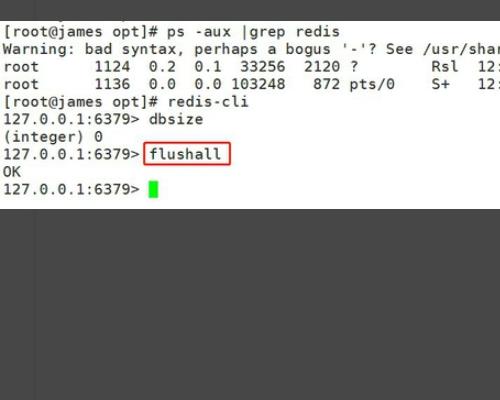
3、执行命令“dbsize”。

4、执行命令“flushall”刷新清除。
5、执行命令“ keys * ”进行验证redis是否为空,可以看到redi数据。

redis-cli
然后要通过key来查找你存的数据,相当于一个数组,有key,有value,通过key来查看value的值。
keys * 注:列出当前redis存储的全部key。
keys W* 注:列出当前redis存储的key名里第一个是“W”的全部key。
找到key名字后,就可以查看key里存了什么值了。
get WXOX 注:WXOX是你查出来的key的名字。
然后就可以看到WXOX里存了什么东西了,可能存了一个字符串,也可能存了一个对象,要是空的话,就会输出nil,意思是啥也没有!
Linux下部署redis以及相关简介
什么是redis?
Redis是一个高性能的key-value数据库。key-value分布式存储系统查询速度快、存放数据量大、支持高并发,非常适合通过主键进行查询,但不能进行复杂的条件查询。key value 根据关键字取值,key是关键字,value是值。
Redis的三个主要特点:
1、Redis将数据库完全保存在内存中,仅使用磁盘进行持久化。
2、相比于其他键值数据库,Redis有相对丰富的数据结构。
3、Redis可以将数据复制到任意数量的从机中。
Redis的五个优点:
1、一个 key-value 数据存储系统, 只支持一些基本操作, 如: SET(key, value)和 GET(key) 等;
2、分布式:多台机器(nodes)同时存储数据和状态,彼此交换消息来保持数据一致,可视为一个完整的存储系统。
3、数据一致:所有机器上的数据都是同步更新的、不用担心得到不一致的结果;
4、冗余: 所有机器 (nodes) 保存相同的数据, 整个系统的存储能力取决于单台机器 (node)的能力
5、容错:如果有少数 nodes 出错,比如重启、当机、断网、网络丢包等各种 fault/fail 都不影响整个系统的运行;
6、高可靠性:容错、冗余等保证了数据库系统的可靠性。
1、安装依赖包:# yum -y install ruby rubygems
2、下载redis:# wget http://download.redis.io/releases/redis-3.2.9.tar.gz
3、解压进入文件夹进行编译:# make
4、安装(指定路径):# make PREFIX=/home/redis install
5、复制源文件中src中的 四个可执行文件到 redis 文件夹
# cp/home/redis-3.2.9/redis.conf /home/redis
# cp/home/redis-3.2.9/redis-cli /home/redis
# cp/home/redis-3.2.9/redis-benchmark /home/redis
# cp/home/redis-3.2.9/redis-server /home/redis
6、启动关闭redis
# ./redis-server & (加上&使redis以后台程序方式运行)
# ps aux|grep redis (查看redis是否启动)
# redis-cli shutdown (关闭redis)
可配置redis.conf,将daemonize no改为yes;详情见7.1
7、配置redis:# vi redis.conf
(1). Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
(2). 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
(3). 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
(4). 绑定的主机地址
bind 127.0.0.1
(5).当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能,单位秒
timeout 0
(6). 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
(7). 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
(8). 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
(9). 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
(10). 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
(11). 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
(12). 指定本地数据库存放目录
dir ./redisdata
(13). 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
(14). 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
(15). 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
requirepass foobared
(16). 设置同一时间最大客户端连接数,默认10000,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 10000
(17). 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
(18). 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no。该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。开 启append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当redis重新启动时,会从该文件恢复出之前的状态。但是这样会造成 appendonly.aof 文件过大,所以redis还支持了BGREWRITEAOF 指令,对appendonly.aof进行重新整理
appendonly yes
(19). 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
(20). 指定更新日志条件,共有3个可选值:
appendfsync no:表示等操作系统进行数据缓存同步到磁盘(快)
appendfsync always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
appendfsync everysec:表示每秒同步一次(折衷,默认值)
(21). 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
(22). 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
(23). 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
(24). Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
(25). 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
m-pages 134217728
(26). 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
(27). 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
(28). 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
(29). 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
(30). 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
以上是关于如何在linux中查询redis的数据的主要内容,如果未能解决你的问题,请参考以下文章