JAVA基础知识|java虚拟机(JVM)
Posted 无聊的三文鸡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA基础知识|java虚拟机(JVM)相关的知识,希望对你有一定的参考价值。
一、JVM简介
java语言是跨平台的,兼容各种操作系统。实现跨平台的基石就是虚拟机(JVM),虚拟机不是跨平台的,所以不同的操作系统需要安装不同的jdk版本(jre=jvm+类库;jdk=jre+开发工具)。
1.1、JAVA程序执行流程
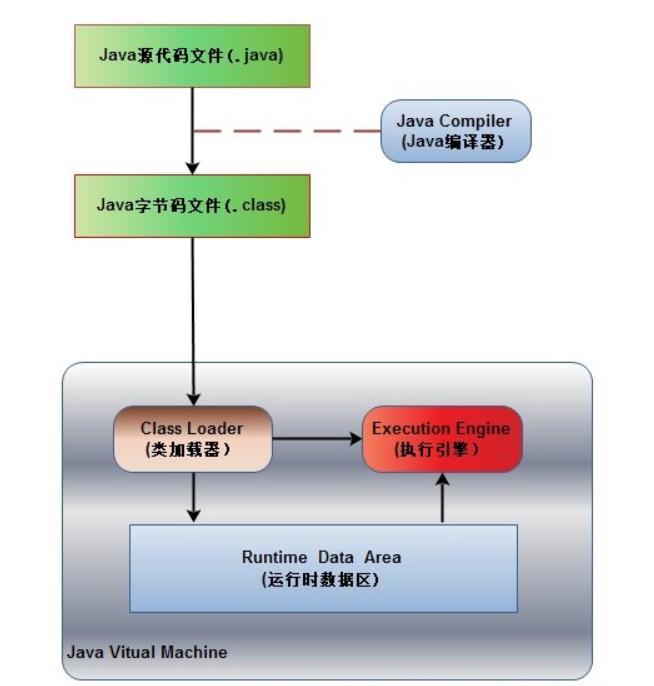
首先由java编译器将源码文件(.java)编译成字节码文件(.class),再由类加载器加载生成好的字节码文件,加载完毕后,交由执行引擎执行。运行时数据区用于存储执行过程中产生的数据和信息,也就是我们常说的JVM内存空间。
类加载器:在JVM启动时或者类在运行时将需要的class加载到JVM中。
执行引擎:负责执行class文件中的字节码指令,相当于CPU。
运行时数据区:将内存划分成若干个区,分别完成不同的任务。
1.2、JVM生命周期
- 启动:启动一个Java程序时,一个JVM实例就产生了,任何一个拥有public static void main(String[] args)函数的类都可以作为JVM实例运行的起点。
- 运行:main()作为该程序初始线程的起点,任何其他线程均由该线程启动。
- 消亡:当程序中所有非守护线程的都终止时,JVM才退出。Java中的线程分为两种:守护线程 (daemon)和普通线程(non-daemon)。守护线程是Java虚拟机自己使用的线程,比如负责垃圾收集的线程就是一个守护线程。当然,你也可以把自己的程序设置为守护线程。包含main()方法的初始线程不是守护线程。
二、运行时数据区
根据 JVM 规范,JVM 内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。
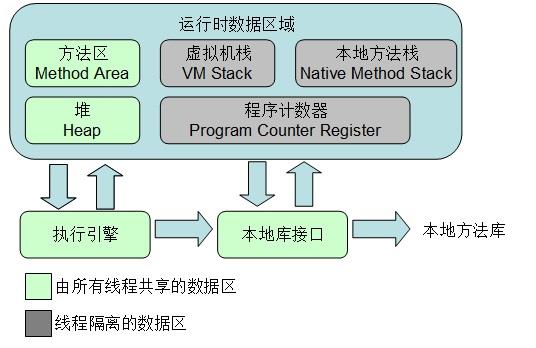
2.1、程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie 方法,这个计数器值则为空(Undefined)。
此内存区域是唯一一个在Java 虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
2.2、方法区
方法区:是java虚拟机规范中定义的一种概念上的区域,具有什么功能,但并没有规定这个区域到底应该位于何处,因此对于实现者来说,如何来实际方法区是有着很大自由度的。主要用于存储被虚拟机加载的类信息、常量池(final)、静态变量(static)、即时编译后的代码。当内存空间不足,会抛出OutOfMemoryError 异常。
【永生代】
永生代是hotspot中的一个概念,其他jvm实现未必有,例如jrockit就没这东西。java8之前,hotspot使用在内存中划分出一块区域来存储类的元信息、类变量以及内部字符串(interned string)等内容,称之为永生代,把它作为方法区来使用。方法区和永久代的区别,前者是JVM的规范,而后者则是JVM规范的一种实现,并且只有HotSpot才有“PermGen space”。
HotSpot VM,是Sun JDK和OpenJDK中所带的虚拟机,也是目前使用范围最广的Java虚拟机。
从JDK1.7开始,移除永久代的功能已经开始。JDK1.8后,永久代就被删除了,取而代之的就是元空间,将类的元数据放到本地内存中,另外,将常量池和静态变量放到Java堆里。
【元空间】
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
为什么使用元空间替换永生代?
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
2.3、虚拟机栈
线程私有,生命周期与线程同步。每个方法执行的时候,都会在栈中创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出入口等。每个方法从调用到完成,就是一个栈帧入栈到出栈的过程。
局部变量表:方法相关的局部变量,包括基本类型(int、float、double、char、bool等)、对象引用(reference)、引用地址(returnAddress )等。
两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError 异常;如果虚拟机栈可以动态扩展(当前大部分的Java 虚拟机都可动态扩展,只不过Java 虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError 异常。
一个本地变量可能是原始类型,在这种情况下,它总是“呆在”线程栈上。
一个本地变量也可能是指向一个对象的一个引用。在这种情况下,引用(这个本地变量)存放在线程栈上,但是对象本身存放在堆上。
一个对象可能包含方法,这些方法可能包含本地变量。这些本地变量任然存放在线程栈上,即使这些方法所属的对象存放在堆上。
一个对象的成员变量可能随着这个对象自身存放在堆上。不管这个成员变量是原始类型还是引用类型。
静态成员变量跟随着类定义一起也存放在堆上。
存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。
如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
2.4、本地方法栈
线程私有,与虚拟机栈的执行过程基本相同,唯一的区别就是虚拟机栈执行java方法,本地方法栈执行Native方法。当内存空间不足,会抛出OutOfMemoryError 异常。
2.5、堆
线程共享,主要用于存储对象实例,垃圾回收器作用的主要区域。当内存空间不足,会抛出OutOfMemoryError 异常。
三、栈与堆
相同点:都用于存储数据
不同点:
1)栈用于存放基本数据类型的变量和对象、数组的引用,堆用于存放new出来的对象
2)栈中存放的数据,大小和生存期必须确定,灵活性不足。堆中存放的数据,不必知道数据大小,也不必知道生命周期,灵活性较高,导致速度较慢
3)生命周期
当一个方法执行时,每个方法都会建立自己的内存栈,在这个方法中定义的变量将会放到这块栈内存里,随着方法的结束而销毁(不需要使用GC)。
当执行new对象的时候,数据才会在堆中生成,只有当一个对象没有任何引用变量去引用它时,系统的垃圾回收器(GC)才会在合适的时候回收它。
4)栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
/** * 汽车类 */ public class Car { //编号 private int id; //车名 private String name; //车速 private double speed; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getSpeed() { return speed; } public void setSpeed(double speed) { this.speed = speed; } public Car(int id, String name, double speed) { this.id = id; this.name = name; this.speed = speed; } public Car() { } @Override public String toString() { return "Car{" + "id=" + id + ", name=\'" + name + \'\\\'\' + ", speed=" + speed + \'}\'; } }
int i = 1; Car car = new Car(1, "bmw", 200);
图形化分析:
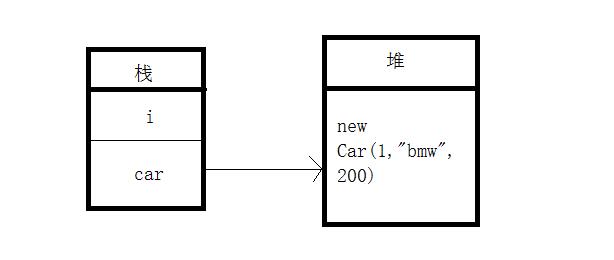
继续看下面代码,并思考输出值
int i = 1; Car car = new Car(1, "bmw", 200); Car newCar = car; newCar.setSpeed(300); System.out.println(car.toString()); System.out.println(newCar.toString());
图形化分析:
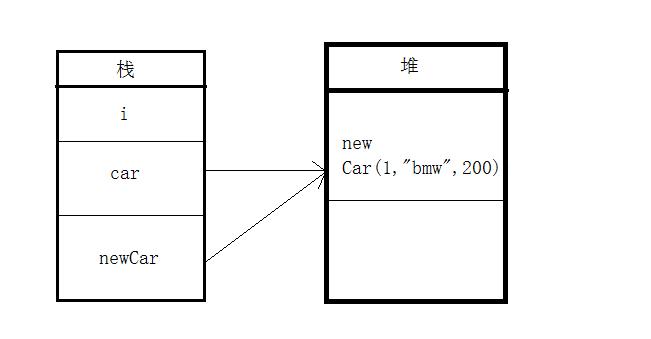
代码中Car newCar = car;只是将引用的地址给了newCar,他们指向堆中同一个对象,所以当newCar对对象做出改变的时候,car所指向的对象也同样发生了变化。
有时候在代码中,我们不希望两个变量指向同一个对象,可以使用clone的方式,重新在堆中生成一个相同的对象。
四、实例分析
尝试对具体实例进行分析,有不对的地方,恳请指点。
package src; import java.util.ArrayList; //类信息会被存放在方法区 public class Person { private String name;//存放在堆中,因为该类被实例化后存放在堆中,当然也包含它的属性 private int age;//存放在堆中 public static String country;//存放在方法区 public final String world = "地球";//存放在方法区 //当方法被调用的时候,会创建一个栈帧用于存储方法中的局部变量表,方法出口等信息 public void getMessge(String name, String age) { int a = 0;//存储在虚拟栈 //arrayList 存放在虚拟栈,new ArrayList<>()存放在堆中 ArrayList<String> arrayList = new ArrayList<>(); } }
以上是关于JAVA基础知识|java虚拟机(JVM)的主要内容,如果未能解决你的问题,请参考以下文章