用python参加Kaggle的些许经验总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python参加Kaggle的些许经验总结相关的知识,希望对你有一定的参考价值。
参考技术A
最近挤出时间,用python在kaggle上试了几个project,有点体会,记录下。
EDA,也就是对数据进行探索性的分析,一般就用到pandas和matplotlib就够了。EDA一般包括:
在这步完成之后,要对以下几点有大致了解
数据预处理,就是将数据处理下,为模型输入做准备,其中包括:
理论上来说,特征工程应该也归属于上一步,但是它太重要了,所以将它单独拿出来。kaggle社区对特征工程的重要性已经达成了共识,可以说最后结果的好坏,大部分就是由 特征工程 决定的,剩下部分应该是 调参 和 Ensemble 决定。特征工程的好坏主要是由 domain knowledge 决定的,但是大部分人可能并不具备这种知识,那么只能尽可能多的根据原来feature生成新的feature,然后让模型选择其中重要的feature。这里就又涉及到 feature selection ,
有很多方法,比如backward,forward selection等等。我个人倾向于用 random forest的feature importance , 这里 有论文介绍了这种方法。
Model Ensemble有 Bagging , Boosting , Stacking ,其中Bagging和Boosting都算是 Bootstraping 的应用。 Bootstraping 的概念是对样本每次有放回的抽样,抽样K个,一共抽N次。
最后是我的两点心得吧
这篇文章是参加kaggle之后的第一次总结,描述了下kaggle的步骤,通用的知识点和技巧。希望在未来一个月中,能把xgboost和stacking研究应用下,然后再来update。希望大家有什么想法都能跟我交流下~~
update: 更新了关于类别特征的处理方式以及Boosting和Bagging的看法,还有stacking的内容。
比赛教程-如何参加Kaggle数据科学比赛(上)
引言:上篇Kagging金大叔的数据科学之路(一)提到我加入Kaggle3个月又27天,拿下两枚银牌成为Expert,全球排名Top2.5%。今天来撸一撸如何Kaggle比赛。(为什么要参加Kaggle比赛,再作探讨#TODO#)
万物皆数据,数据科学特别是机器学习正在改变世界。说到数据科学就绕不开Kaggle-Google旗下全球最大的数据科学平台(Kaggle-Your Home for Data Science)。
Google首席经济师哈尔·范里安称Kaggle提供了一种“将全世界最有才能的数据科学家组织起来并使各种规模的机构都能够触及”的方式。
Kaggle平台大牛云集,吸引了全球顶级数据科学家,Kaggle比赛是数据科学爱好者的入门实战首选(我是Kaggle,翻我牌子)。
Kaggle比赛多是机器学习类型的,通常有大量的现金奖品(有些高达百万美金??3,000,000),公开的排行榜,并涉及复杂的数据,第一次登录Kaggle会让人望而生畏。然而,我们真的认为所有的数据科学家都可以从机器学习竞赛中快速学习,并为数据科学社区做出有意义的贡献。为了清楚地了解Kaggle平台是如何工作的,以及可以在Kaggle上进行的学习类型的心理模型,我们借助数据科学最经典的一个比赛-泰坦尼克比赛创建一个“入门”教程。
它将引导您完成在排行榜上获得第一份像样的提交文件所需的初始步骤。在本教程结束时,还将对如何使用Kaggle的在线编码环境有一个扎实的了解,以此在线训练自己的机器学习模型。
如果这是你第一次参加Kaggle竞赛,无论你是否:
Part 1: Get started开工
在本节中,将了解更多有关比赛的信息,并完成你的第一份提交(submission)。
# Join the competition!接受挑战:
首先要做的就是参加比赛(join the competition)!用[竞赛页面]打开一个新窗口,如果还没有,请单击“加入竞赛”(join Competition)按钮。(如果您看到的是“提交预测”("Submit Predictions")按钮而不是“join Competition”按钮,则表示您已经加入比赛,无需再次加入。)
这("join Competition")将带您进入规则接受页面,你必须接受比赛规则才能参加。这些规则规定你每天可以提交多少份提交,最大的团队规模和其他比赛细节(也可在“Rules”中查看)。然后,点击“我理解并接受”("I Understand and Accept")表示您将遵守竞赛规则。
# The challenge挑战开始:
泰坦尼克比赛挑战很简单:使用泰坦尼克号乘客数据(姓名、年龄、票价等)来预测谁将幸存,谁将死亡。这是一个回归挑战?分类挑战?
# The data获取数据:
要查看竞赛数据,请单击竞赛页面顶部的“Data“数据选项卡。然后,向下滚动以查找文件列表。
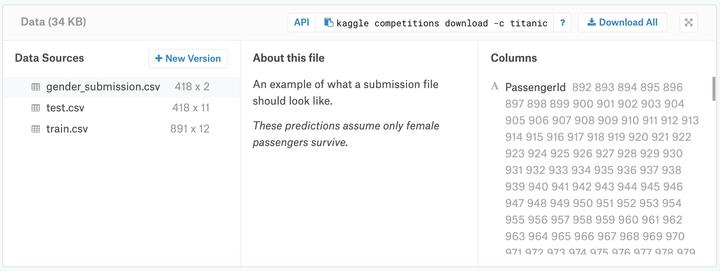
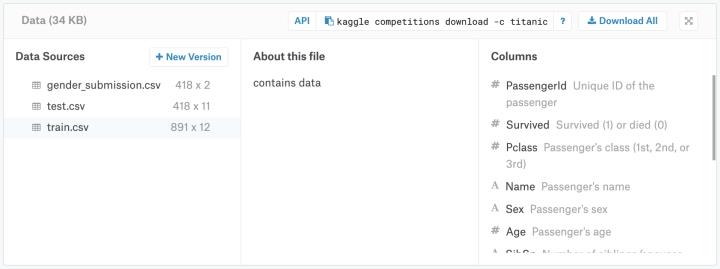
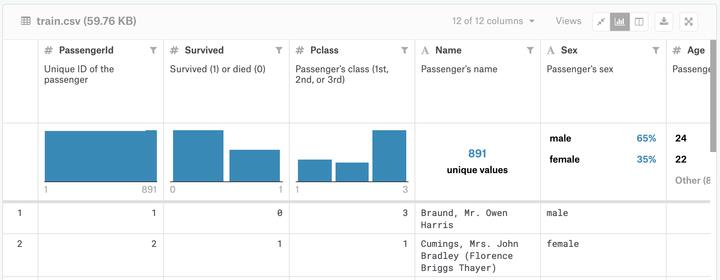
数据中有三个文件:(1)训练数据集train.csv,(2)测试数据集test.csv,(3)提交文件gender_submission.csv。
包含乘客子集的详细信息(确切地说,是891名乘客——每个乘客在表中得到不同的行)。要调查此数据,请单击“数据源”("Data Sources")列(屏幕左侧)下的文件名。完成此操作后,屏幕右侧的“Columns”标题下会列出所有列名(以及它们包含的内容的简要说明)。
第二列中的值(“存活”"Survived")可用于确定每位乘客是否存活:
例如,在train.csv中列出的第一位乘客是Owen Harris Braund先生。他在泰坦尼克号上去世时22岁。
使用在train.csv中找到的模式,您必须预测机上其他418名乘客(在test.csv)是否幸存。
单击test.csv(在“数据源”("Data Sources")列下)检查其内容。请注意,test.csv没有“Survived”列-此信息对您隐藏,您预测这些隐藏值的能力将决定您在比赛中的分数!
(3)提交文件gender_submission.csv
Kaggle提供gender_submission.csv文件作为示例,说明如何构建预测。它预测所有女性乘客都存活下来,所有男性乘客都死亡。你关于生存的假设可能不同,这将导致不同的提交文件。但是,就像这个文件一样,你的提交应该有:
-一个“PassengerId”列,包含来自test.csv的每个乘客的ID。
-一个“幸存”的列(由您创建"Survived"!)在您认为乘客幸存的行中加上“1”,在您预测乘客死亡的行中加上“0”。
# Your first submission完成第一个提交:
作为基准,您将下载gender_submission.csv文件并提交给比赛后台。
-点击竞赛页面右上角的蓝色“提交预测”("Submit Predictions")按钮。(这个按钮现在出现在“加入比赛”("join Competition")按钮所在的位置。
-向下滚动至“步骤1:“上传提交文件”(“Upload submission file")。上传你刚刚下载的文件。然后,单击蓝色的“Make Submission”按钮。
几秒钟后,您提交的内容将得到评分,您将在排行榜上获得一个位置。下一步,我们将引导您了解如何超越这一初步提交!
以上是关于用python参加Kaggle的些许经验总结的主要内容,如果未能解决你的问题,请参考以下文章
求kaggle 手机验证的经验
7次KDD Cup&Kaggle冠军的经验分享:从多领域优化到AutoML框架
Happywhale -我的第一次Kaggle Solo经验分享,纯纯的都是经验,初学者友好~
刚参加完阿里Java P6面试归来,6点面试经验总结!(含必考题答案)
刚参加完阿里Java P6面试归来,6点面试经验总结!(含必考题答案)
阿ken经验总节要考英语四六级的你一定要知道的!