linux下jupyter 配置spark,出现jupyter notebook requires javascript怎么处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux下jupyter 配置spark,出现jupyter notebook requires javascript怎么处理相关的知识,希望对你有一定的参考价值。
参考技术A linux下jupyter 配置spark,出现jupyter notebook requires javascript,没有找到js包,看导入jar包没有呀,。本回答被提问者采纳jupyter中安装scala和spark内核详细教程
jupyter中安装scala和spark内核
jupyter中安装scala和spark内核
文章目录
在jupyter中安装scala和spark的内核,主要是通过jupyter来编写scala和spark的代码,安装成功后就可以编写一些scala、SparkSQL、Spark的代码。
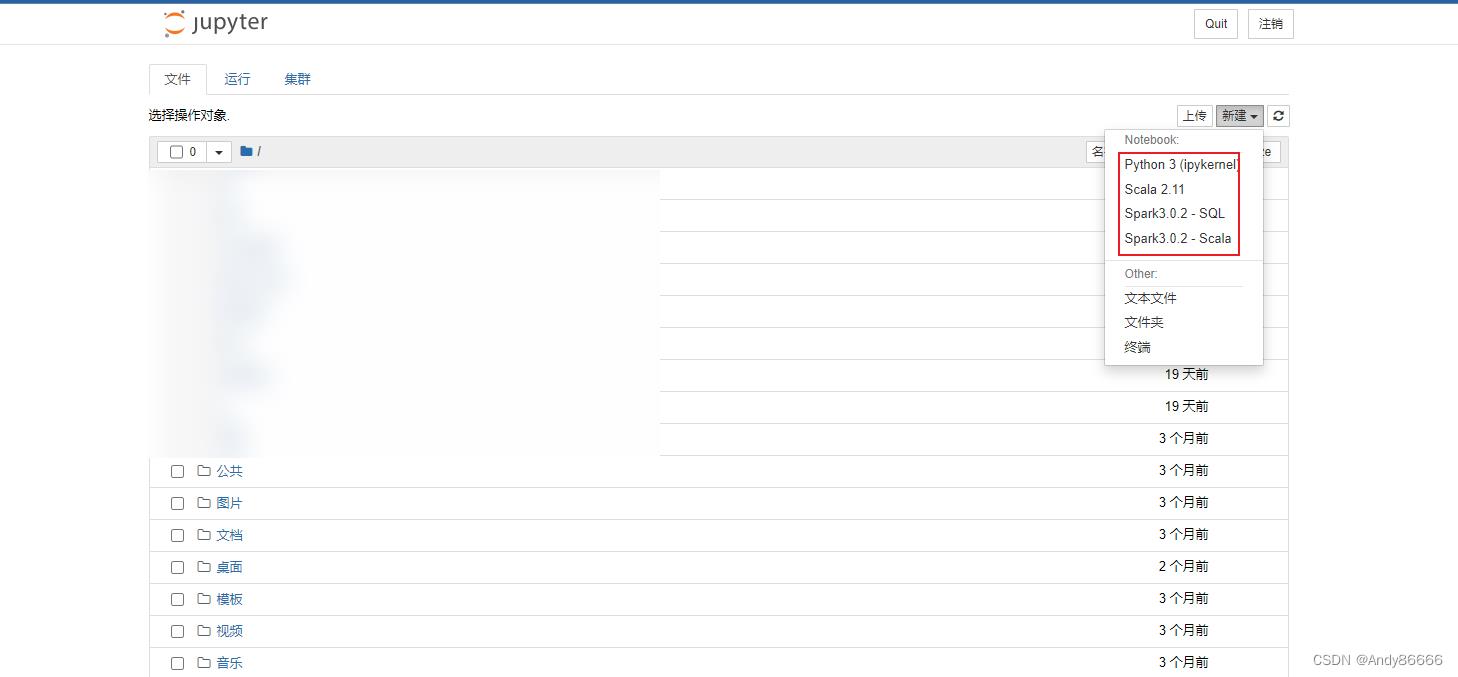
一、前期准备
提前下载:
- Anaconda3-5.3.1-Linux-x86_64.sh
- anaconda清华大学开源软件镜像站 ,可以选择自己需要下载版本
- jupyter-scala_2.11.6-0.2.0-SNAPSHOT.tar.xz 这里我准备的是最新
scala 内核的文件
提前安装好spark,并且启动
二、安装
(一)Anaconda
使用Anaconda中自带的jupyter,而且Anaconda中集成了众多包
1、文件上传到Linux系统上
方法一:
将提前下载好的Anacoda,通过rz命令上传到centos中,我是使用的是SecureCRT来连接centos
我一般将文件上传到/opt/software中
[andy@hadoop1 ~]$ cd /opt/software/
[andy@hadoop1 software]$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
选择文件就可以上传

方法二:使用wget
使用wget在centos中下载Anaconda
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh
2、安装Anaconda
执行安装命令
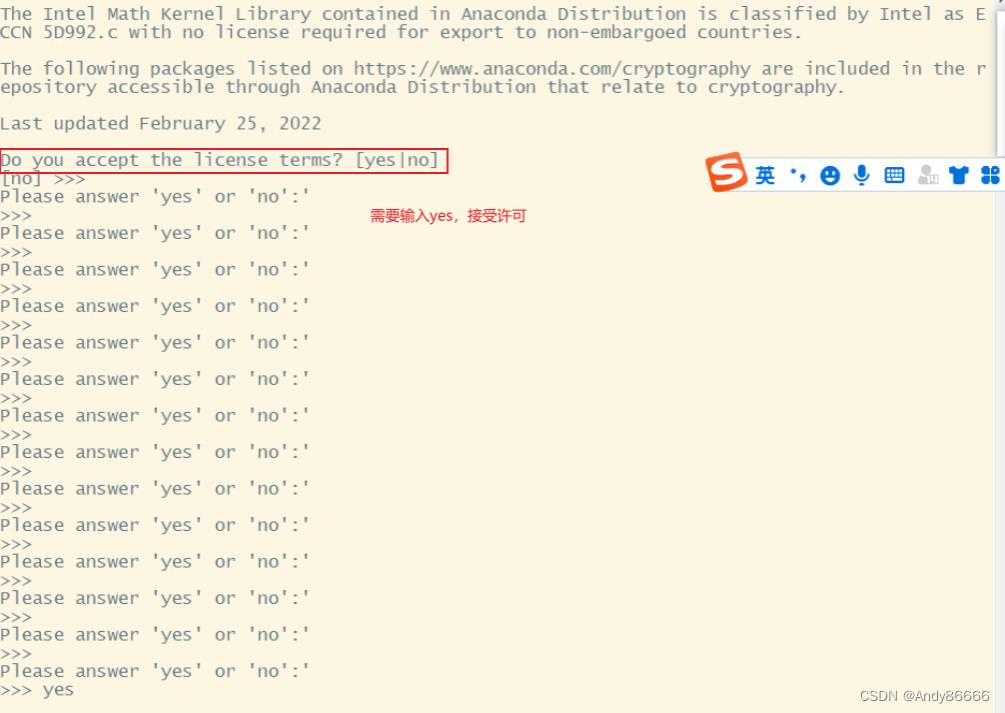
bash Anaconda3-5.3.1-Linux-x86_64.sh
可以一直按Enter,一直到需要输入yes或者no的时候,输入yes
选择Anaconda的安装位置,默认是在执行安装命令的用户家目录下,可以更换位置或者不更换。

然后是Anaconda的初始化,一定要输入yes
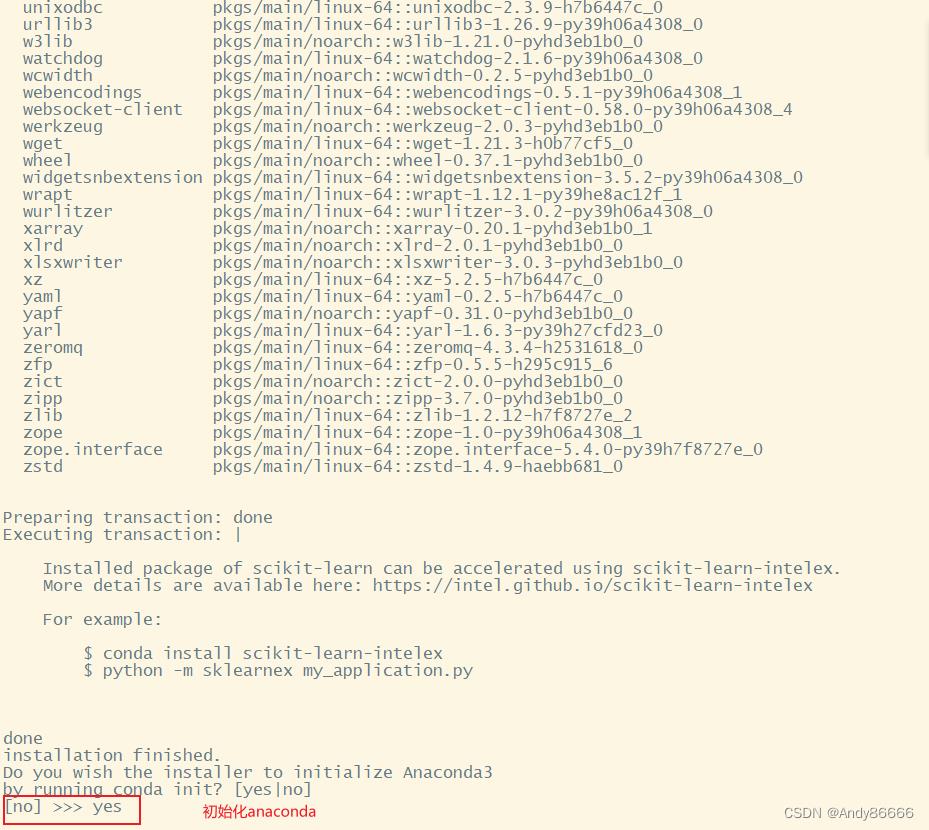
就此安装成功
3、激活环境
命令:
source activate base
[andy@hadoop1 software]$ source activate base
(base) [andy@hadoop1 software]$
激活成功后,会出现(base)
注意:这点环境一定要激活,后面的安装需要使用到
4、jupyter
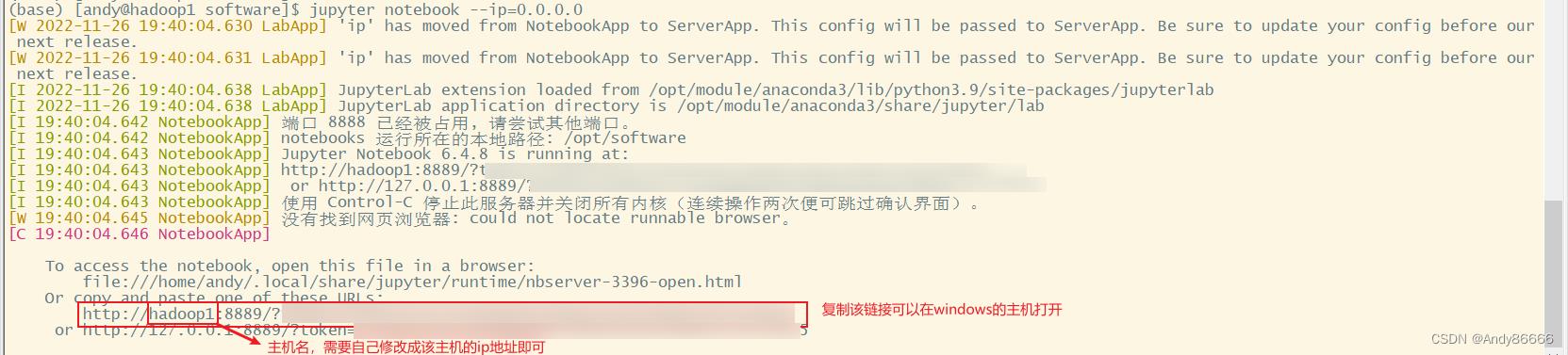
如果直接执行jupyter notebook,只能在本地运行,但是想过将jupyter在windows上运行,需指定ip地址
jupyter notebook --ip=0.0.0.0
(二)Scala内核
安装scala内核,主要是为了练习scala时使用,如果用spark的scala来练习scala,内核需要消耗大量的资源,因此安装scala内核
1、文件上传到Linux系统上
方法一:
将下载好的jupyter-scala_2.11.6-0.2.0-SNAPSHOT.tar.xz,通过rz命令上传到centos中
一般将文件上传到/opt/software中
cd /opt/software
rz
方法二:使用wget
wget https://oss.sonatype.org/content/repositories/snapshots/com/github/alexarchambault/jupyter/jupyter-scala-cli_2.11.6/0.2.0-SNAPSHOT/jupyter-scala_2.11.6-0.2.0-SNAPSHOT.tar.xz
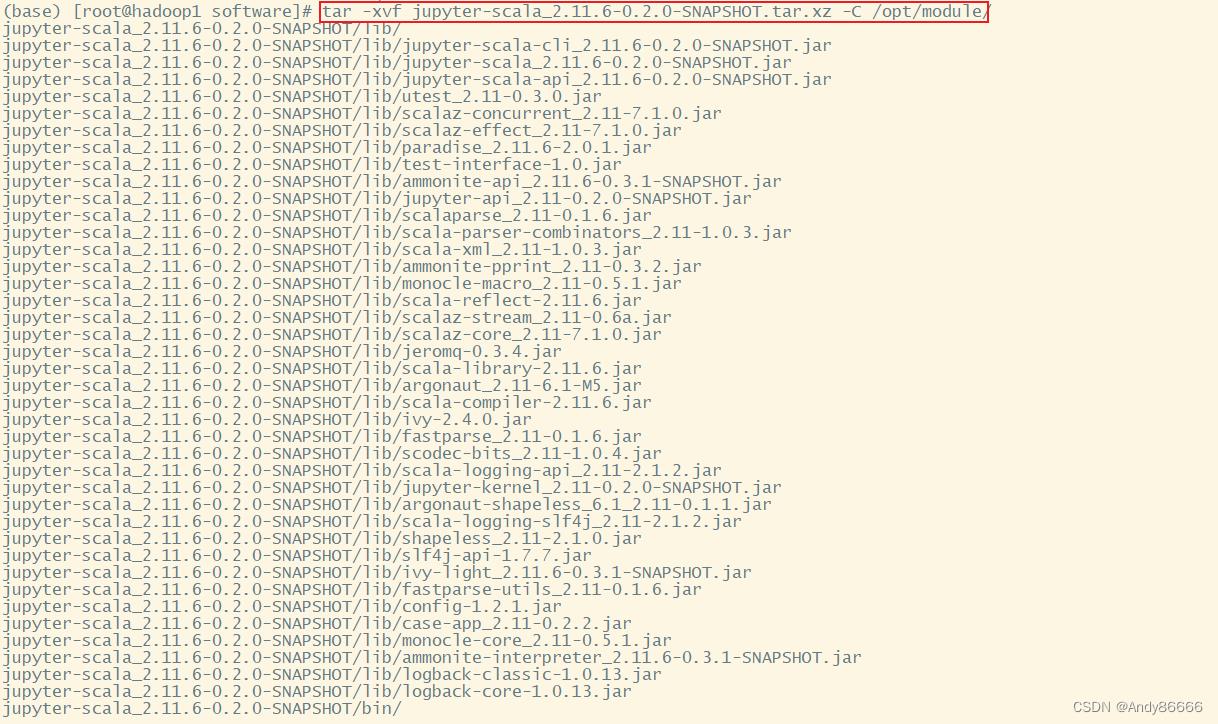
2、将文件进行解压
将文件解压到/opt/module/中
tar -zxvf jupyter-scala_2.11.6-0.2.0-SNAPSHOT.tar.xz -C /opt/module/
3、安裝scala内核
执行命令:
进入到解压路径中
cd /opt/module/
jupyter-scala_2.11.6-0.2.0-SNAPSHOT/bin/jupyter-scala
运行情况:
(base) [andy@hadoop1 ~]$ cd /opt/module/
(base) [andy@hadoop1 module]$ jupyter-scala_2.11.6-0.2.0-SNAPSHOT/bin/jupyter-scala

4、验证内核
查看jupyter中的内核:
jupyter kernelspec list

(三)spark内核
安装spark和sparkSQL
需要提前安装toree
pip install toree
1、安装spark内核
jupyter toree install --spark_opts='--master=spark://hadoop1:7077' --user --kernel_name=Spark3.0.2 --spark_home=/opt/module/spark-yarn
-
spark_opts:是指spark使用的方法,这点是standalone模型(独立部署),这点可以看spark教程
-
kernel_name:是spark的版本
-
可以通过
spark-shell来查看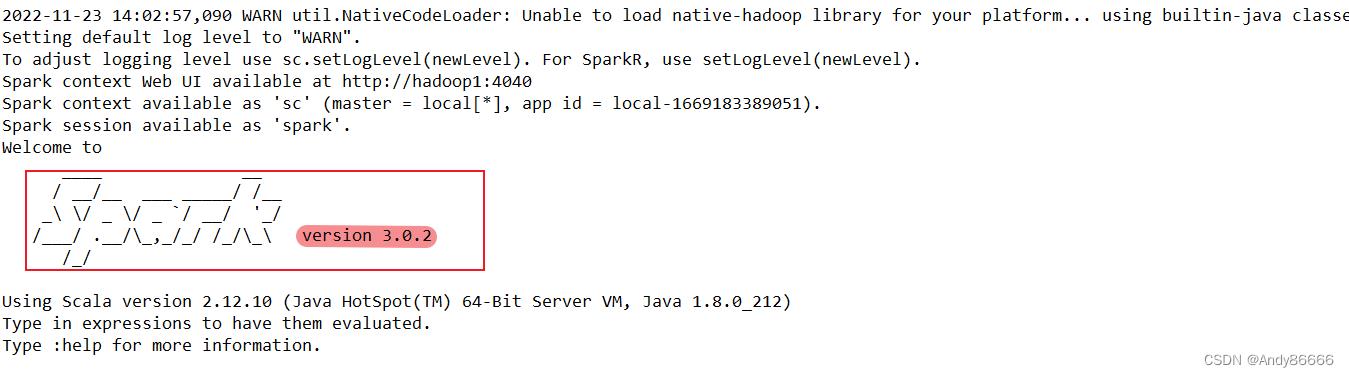
-
-
spark_home:spark的安装位置
需要修改成自己的
2、安装sparkSQL内核
jupyter toree install --spark_opts='--master=spark://hadoop1:7077' --user --kernel_name=Spark3.0.2 --spark_home=/opt/module/spark-yarn --interpreters=SQL
3、验证内核
查看jupyter中的内核:
jupyter kernelspec list
补充知识:
-
删除内核
jupyter kernelspec remove 环境名
以上是关于linux下jupyter 配置spark,出现jupyter notebook requires javascript怎么处理的主要内容,如果未能解决你的问题,请参考以下文章