mysql查询统计数量
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql查询统计数量相关的知识,希望对你有一定的参考价值。
CREATE TABLE `pl_org_region` (
`region_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '区域自增ID',
`parent_id` int(11) NOT NULL DEFAULT '0' COMMENT '父区域ID 对应自身数据表 0表示顶级区域',
`region_sn` varchar(10) NOT NULL COMMENT '区域编号',
`region_name` varchar(20) NOT NULL COMMENT '区域名称',
`comments` varchar(255) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`region_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COMMENT='区域表'
CREATE TABLE `pl_store` (
`store_id` int(11) NOT NULL COMMENT '门店自增ID',
`store_sn` varchar(10) NOT NULL COMMENT '门店编号',
`region_id` int(11) NOT NULL COMMENT '区域ID 对应org_region表',
`region_name` varchar(15) NOT NULL COMMENT '区域名称 对应org_region表',
PRIMARY KEY (`store_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='门店表'
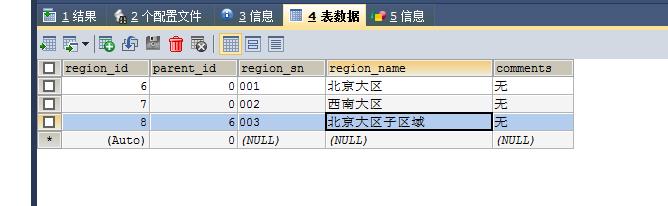
如建表语句的2张表。
如何统计当前区域下的门店数量?为0 也需要显示区域信息处理,谢谢!
SELECT p.region_id,COUNT(p.region_id) AS cnt,r.* FROM pl_org_region r, pl_store p WHERE r.region_id=p.region_id GROUP BY p.region_id;
这样查询只显示出来统计结果不为0 的情况。。
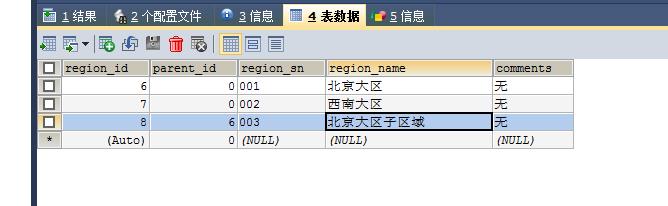
一共加了三条数据
insert into pl_org_region(parent_id,region_sn,region_name,comments) values (0,\'001\',\'北京大区\',\'无\');insert into pl_org_region(parent_id,region_sn,region_name,comments) values (0,\'002\',\'西南大区\',\'无\');
insert into pl_store (store_sn,region_id,region_name) values (\'P001\',6,\'北京大区\');
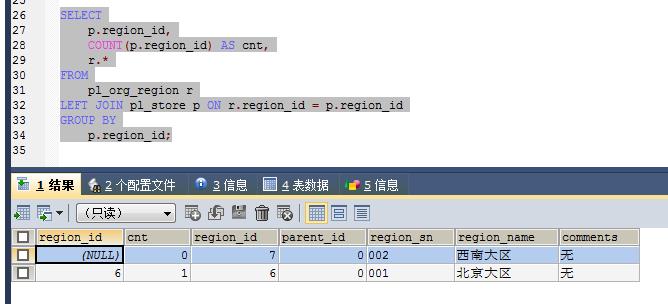
查询语句改成:
SELECTp.region_id,
COUNT(p.region_id) AS cnt,
r.*
FROM
pl_org_region r
LEFT JOIN pl_store p ON r.region_id = p.region_id
GROUP BY
p.region_id;
查询结果:
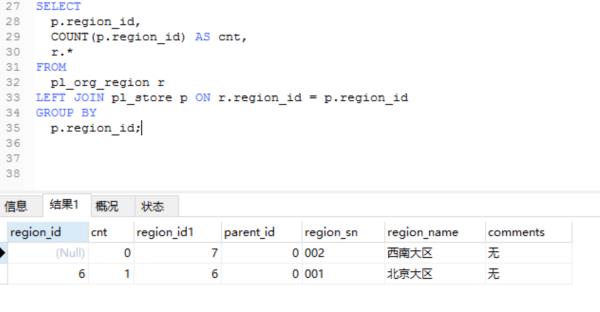
INSERT INTO pl_org_region(parent_id,region_sn,region_name,comments) VALUES (对应的北京大区ID,\'003\',\'北京大区子区域\',\'无\');
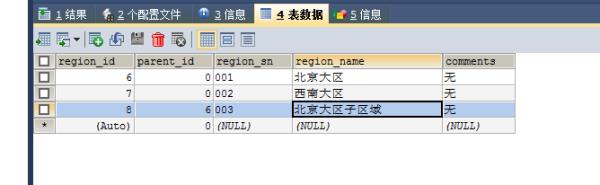
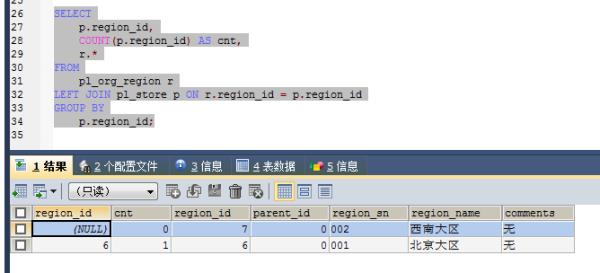
子区域的可否也分别查询出来呢?
在子区域下 加一个pl_store 记录 统计子区域的数量 和 主区域的数量.
非持久化统计信息
统计信息没有保存在磁盘上,而是频繁的实时计算统计信息;
每次对表的访问都会重新计算其统计信息;
假设针对一张大表的频繁查询,那么每次都要重新计算统计信息,很耗费资源。
持久化统计信息
把一张表在某一时刻的统计信息值保存在磁盘上;
避免每次查询时重新计算;
如果表更新不是很频繁,或者没有达到 mysql 必须重新计算统计信息的临界值,可直接从磁盘上获取;
即使 MySQL 服务重启,也可以快速的获取统计信息值;
统计信息的持久化可以针对全局设置也可以针对单表设置。
接下来,详细说 MySQL 统计信息如何计算,何时计算,效果评估等问题。在 MySQL Server 层来控制是否自动计算统计信息的分布,并且来决策是持久化还是非持久化。
MySQL优化COUNT()查询
COUNT()聚合函数,以及如何优化使用了该函数的查询,很可能是最容易被人们误解的知识点之一
COUNT()的作用
COUNT()是一个特殊的函数,有两种非常不同的作用:
- 统计某个列值的数量
- 统计行数
统计列值
在统计列值时,要求列值是非空的,即不统计NULL。如果在COUNT()的括号中指定了列或者列的表达式,则统计的就是这个表达式有值的结果数。
统计结果集的行数
当MySQL确认括号内的表达式的值不可能为空时,实际上就是在统计行数,最简单的就是当我们使用COUNT(*)的时候,这种情况下通配符 * 并不会像我们猜想的那样拓展成所有的列,实际上,它会忽略所有的列而直接统计所有的行数。
因此会有一个常见的错误就是,在括号内指定了一个列却希望统计结果集的行数。如果希望知道的是结果集的行数,那么最好使用COUNT(*)。这样写意义清晰,性能也会更好。
关于MyISAM的神话
一个很容易产生的误解就是:MyISAM的COUONT()函数总是非常快的,但其实这是有一个前提条件的,即只有没有任何WHERE条件的COUNT(*)才非常快,因为此时无需实际地计算表的行数。MySQL可以利用存储引擎的特性直接获得这个值。
当统计带有WHERE子句的结果集行数时,可以是统计某个列值的数量时,MyISAM的COUNT()和其他存储引擎没有任何不同,也就不再是神话般的速度了。
简单的优化
有时候我们可以使用MyISAM在 COUNT(*) 全表非常快的这个特性,来加速一些特定条件的 COUNT() 查询。比如:
SELECT COUNT(*) FROM world.City WHERE ID > 5;该查询查找所有ID大于5的城市,这需要扫描4097行数据。但是如果我们把条件反转一下,查找ID小于等于5的城市的数量,然后用总城市的数量一减就可以得到同样的结果,但是却可以把扫描的行数控制在5行以内:
SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*)
FROM world.City WHERE ID <= 5;使用近似值
有些时候并不需要完全精确的COUNT的值,此时可以用近似值来代替。EXPLAIN出来的优化器估算的行数就是一个不错的近似值,执行EXPLAIN并不需要真正去执行查询,所以成本很低。
以上是关于mysql查询统计数量的主要内容,如果未能解决你的问题,请参考以下文章