生存分析(Survival Analysis)Cox风险比例回归模型(Cox proportional hazards model)及
Posted dqhl1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生存分析(Survival Analysis)Cox风险比例回归模型(Cox proportional hazards model)及相关的知识,希望对你有一定的参考价值。
生存分析(Survival Analysis)、Cox风险比例回归模型(Cox proportional hazards model)及C-index
1. 生存分析
生存分析指的是一系列用来探究所感兴趣的事件的发生的时间的统计方法。常见的有1)癌症患者生存时间分析2)工程中的失败时间分析等等。
1.1 定义
给定一个实例 i i i,我们用一个三元组来表示 ( X i , δ i , T i ) (X_i, \\delta_i, T_i) (Xi,δi,Ti),其中 X i X_i Xi表示该实例的特征向量, T i T_i Ti表示该实例的事件发生时间。
如果该实例发生了我们感兴趣的事件,那么
T
i
T_i
Ti表示的是事件发生时间点到基准时间点之间的时间,同时
δ
i
=
1
\\delta_i = 1
δi=1。
如果该实例未发生我们感兴趣的事件,那么
T
i
T_i
Ti表示的是事件发生时间点到观察结束时间点的时间,同时
δ
i
=
0
\\delta_i = 0
δi=0。
生存分析的研究目标就是对一个新的实例 X j X_j Xj,来估计它所发生感兴趣事件的时间。
1.2 删失(censored)
在生存分析研究中,对于某些实例,会出现在我们的研究期间,并没有出现任何感兴趣的时间,我们将这种情况称之为删失(censored)。
出现这种情况的可能原因有:
1)实例在研究阶段就是没有出现感兴趣的事件(right-censored)
2)在研究阶段,丢失了该实例
3)该实例经历了其他的事件导致无法继续跟踪
2 生存概率(Survival probability)
生存概率也叫作生存方程 S ( t ) = P r ( T > t ) S(t) = Pr(T>t) S(t)=Pr(T>t),生存方程指的是实例出现感兴趣的事件的时间 T T T不小于给定的时间 t t t的概率。
2.1 Kaplan-Meier survival estimate
KM方法是一种无参数方法(non-parametric)来从观察的生存时间来估计生存概率的方法。
对于研究中的第
n
n
n个时间点
t
n
t_n
tn,生存概率可以计算为:
S
(
t
n
)
=
S
(
t
n
−
1
)
(
1
−
d
n
r
n
)
S(t_n) = S(t_n-1)(1-\\fracd_nr_n)
S(tn)=S(tn−1)(1−rndn)
其中,
S
(
t
n
−
1
)
S(t_n-1)
S(tn−1)指的是在
t
n
−
1
t_n-1
tn−1时间点的生存概率;
d
n
d_n
dn指的是在时间点
t
n
t_n
tn所发生的事件数;
r
n
r_n
rn指的是在快要到时间点
t
n
t_n
tn时,还存活的人(如果在
t
n
−
1
t_n-1
tn−1和
t
n
t_n
tn之间有实例censored,那么在计算
r
n
r_n
rn时应该将该患者剔除出去);
t
0
=
0
,
S
(
0
)
=
1
t_0=0, S(0)=1
t0=0,S(0)=1。
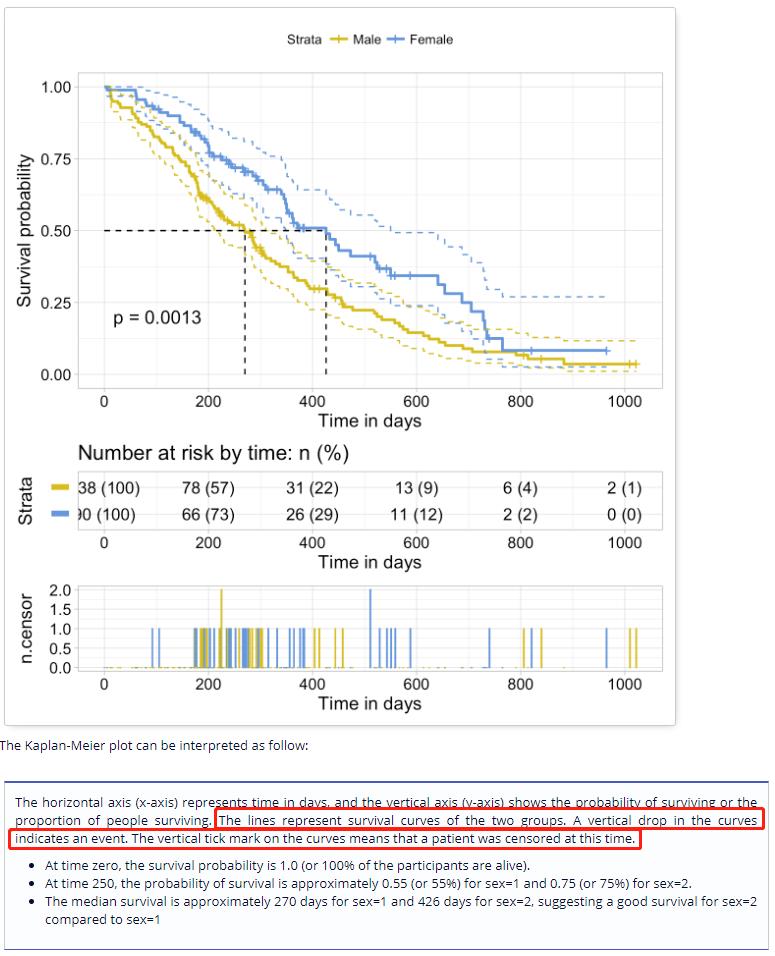
上图为构建的KM生存分析模型可视化结果。其中,
1)曲线上垂直下降的部分表明,在该时刻有感兴趣的事件发生(通过观察 S ( t n ) S(t_n) S(tn)我们能够看到,只有当 d n d_n dn不为零的时候,才会从 S ( t n − 1 ) S(t_n-1) S(tn−1)的值才会减小得到 S ( t n ) S(t_n) S(tn);否则,没有事件发生, S ( t n − 1 ) = S ( n ) S(t_n-1)=S(n) S(tn−1)=S(n))
2)曲线上的垂直stick表示的是,在该时刻,有实例成为了censored,如果在 t n − 1 t_n-1 tn−1和 t n t_n tn之间有实例censored,那么在计算 r n r_n rn时应该将该患者剔除出去
2.2 Log-Rank test 比较不同的生存曲线
在利用KM方法得到多条生存曲线后,只通过直接的观察来确定多条曲线之间是否具有显著性差异是不充分的。因此,log-rank test被广泛的用来比较两条或多条生存曲线。
1)log-rank test是一种非参数检验,因此对于生存概率的分布没有任何假设;
2)同时,log-rank test 的null hypothesis(原假设)为两个曲线代表的两个组之间,在生存率上没有显著性差异。
3)log-rank test比较的是每个组中观察到的事件数,与在原假设为真的情况下,每个组期望的事件数。
4)log-rank test统计量类似于卡方检验(Chi-square test)的统计量
3 风险概率(hazard probability)
风险概率指的是在时间
t
t
t之前还没有发生任何事件的情况下,在时间
t
t
t发生感兴趣的时间的概率。
h
(
t
)
=
lim
δ
(
t
)
→
0
P
r
(
t
≤
T
≤
t
+
δ
(
t
)
∣
T
≥
t
)
δ
(
t
)
h(t) = \\lim_\\delta(t)\\rightarrow0\\fracPr(t\\leq T\\leq t+\\delta(t)|T\\geq t)\\delta(t)
h(t)=δ(t)→0limδ(t)Pr(t≤T≤t+δ(t)∣T≥t)
3.1 累积风险(cummulative hazard)
在针对单因子进行生存分析时,我们已经得到了生存方程
S
(
t
)
S(t)
S(t),那么,根据
S
(
t
)
S(t)
S(t),累积风险为:
H
(
t
)
=
−
log
(
S
(
t
)
)
H(t) = -\\log(S(t))
H(t)=−log(S(t))
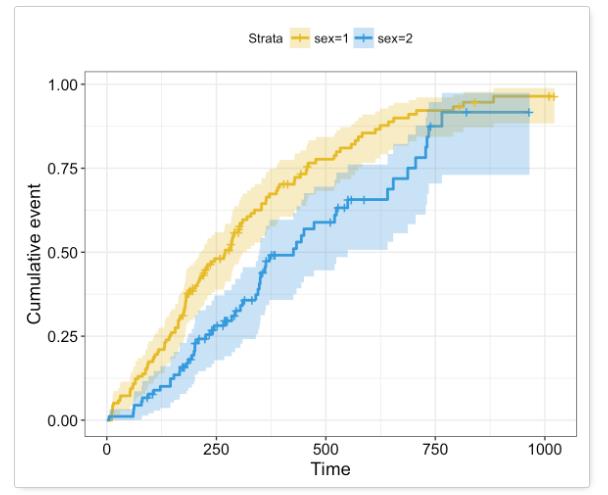
下图为上述生存方程
S
(
t
)
S(t)
S(t)变换得到的累积风险
H
(
t
)
H(t)
H(t)
4 Cox 比例风险回归模型
4.1 为什么要用Cox 比例风险回归
上述生存分析模型,即Kaplan-Meier survival estimate,是单变量分析(univariable analysis),在做单变量分析时,模型只描述了该单变量和生存之间的关系而忽略其他变量的影响。(为什么要考虑multi-variables?比如在比较两组病人拥有和不拥有某种基因型对生存率的影响,但是其中一组的患者年龄较大,所以生存率可能受到基因型 或/和 年龄的共同影响)
同时,Kaplan-Meier方法只能针对分类变量(治疗A vs 治疗B,男 vs 女),不能分析连续变量对生存造成的影响。
为了解决上述两种问题,Cox比例风险回归模型(Cox proportional hazards regression model)就被提了出来。
4.2 Cox 模型的定义
h
(
t
,
X
i
)
=
h
0
(
t
)
×
exp
(
X
i
β
)
h(t, X_i) = h_0(t) \\times \\exp(X_i \\beta)
h(t,Xi)=h0(t)×exp(Xiβ)
其中,
h
0
(
t
)
h_0(t)
h0(t)是基准风险方程,可以是任意一个针对时间
t
t
t的非负方程;
X
i
X_i
Xi是实例
i
i
i的特征向量;
β
\\beta
β是参数向量,该向量是通过最大化cox部分似然得到的。
4.3 partial likelihood
实例
i
i
i以及其所发生事件的时间
T
i
T_i
Ti,那么实例
i
i
i发生事件的概率为: 以上是关于生存分析(Survival Analysis)Cox风险比例回归模型(Cox proportional hazards model)及的主要内容,如果未能解决你的问题,请参考以下文章