java中大量数据如何提高性能?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java中大量数据如何提高性能?相关的知识,希望对你有一定的参考价值。
在jsp页面中,如果从后台读取大量数据(如3万行)填充前台的下拉列表值(<select>标签),怎么优化性能问题,让客户感觉不到慢?
通过使用一些辅助性工具来找到程式中的瓶颈,然后就能对瓶颈部分的代码进行优化。一般有两种方案:即优化代码或更改设计方法。我们一般会选择后者,因为不去调用以下代码要比调用一些优化的代码更能提高程式的性能。而一个设计良好的程式能够精简代码,从而提高性能。????下面将提供一些在JAVA程式的设计和编码中,为了能够提高JAVA程式的性能,而经常采用的一些方法和技巧。
????1.对象的生成和大小的调整。
????JAVA程式设计中一个普遍的问题就是没有好好的利用JAVA语言本身提供的函数,从而常常会生成大量的对象(或实例)。由于系统不仅要花时间生成对象,以后可能还需花时间对这些对象进行垃圾回收和处理。因此,生成过多的对象将会给程式的性能带来非常大的影响。
????例1:关于String ,StringBuffer,+和append
????JAVA语言提供了对于String类型变量的操作。但如果使用不当,会给程式的性能带来影响。如下面的语句:
????String name=new String("HuangWeiFeng");
????System.out.println(name+"is my name");
????看似已非常精简了,其实并非如此。为了生成二进制的代码,要进行如下的步骤和操作:
????(1) 生成新的字符串 new String(STR_1);
????(2) 复制该字符串;
????(3) 加载字符串常量"HuangWeiFeng"(STR_2);
????(4) 调用字符串的构架器(Constructor);
????(5) 保存该字符串到数组中(从位置0开始);
????(6) 从java.io.PrintStream类中得到静态的out变量;
????(7) 生成新的字符串缓冲变量new StringBuffer(STR_BUF_1);
????(8) 复制该字符串缓冲变量;
????(9) 调用字符串缓冲的构架器(Constructor);
????(10) 保存该字符串缓冲到数组中(从位置1开始);
????(11) 以STR_1为参数,调用字符串缓冲(StringBuffer)类中的append方法;
????(12) 加载字符串常量"is my name"(STR_3);
????(13) 以STR_3为参数,调用字符串缓冲(StringBuffer)类中的append方法;
????(14) 对于STR_BUF_1执行toString命令;
????(15) 调用out变量中的println方法,输出结果。
????由此能看出,这两行简单的代码,就生成了STR_1,STR_2,STR_3,STR_4和STR_BUF_1五个对象变量。这些生成的类的实例一般都存放在堆中。堆要对所有类的超类,类的实例进行初始化,同时还要调用类极其每个超类的构架器。而这些操作都是非常消耗系统资源的。因此,对对象的生成进行限制,是完全有必要的。
????经修改,上面的代码能用如下的代码来替换。
????StringBuffer name=new StringBuffer("HuangWeiFeng");
????System.out.println(name.append("is my name.").toString());
????系统将进行如下的操作:
????(1) 生成新的字符串缓冲变量new StringBuffer(STR_BUF_1);
????(2) 复制该字符串缓冲变量;
????(3) 加载字符串常量"HuangWeiFeng"(STR_1);
????(4) 调用字符串缓冲的构架器(Constructor);
????(5) 保存该字符串缓冲到数组中(从位置1开始);
????(6) 从java.io.PrintStream类中得到静态的out变量;
????(7) 加载STR_BUF_1;
????(8) 加载字符串常量"is my name"(STR_2);
????(9) 以STR_2为参数,调用字符串缓冲(StringBuffer)实例中的append方法;
????(10) 对于STR_BUF_1执行toString命令(STR_3);
????(11)调用out变量中的println方法,输出结果。
????由此能看出,经过改进后的代码只生成了四个对象变量:STR_1,STR_2,STR_3和STR_BUF_1.你可能觉得少生成一个对象不会对程式的性能有非常大的提高。但下面的代码段2的执行速度将是代码段1的2倍。因为代码段1生成了八个对象,而代码段2只生成了四个对象。
????代码段1:
????String name= new StringBuffer("HuangWeiFeng");
????name+="is my";
????name+="name";
????代码段2:
????StringBuffer name=new StringBuffer("HuangWeiFeng");
????name.append("is my");
????name.append("name.").toString();
????因此,充分的利用JAVA提供的库函数来优化程式,对提高JAVA程式的性能时非常重要的.其注意点主要有如下几方面;
????(1) 尽可能的使用静态变量(Static Class Variables)
????如果类中的变量不会随他的实例而变化,就能定义为静态变量,从而使他所有的实例都共享这个变量。
????例:
????public class foo
????
??????SomeObject so=new SomeObject();
????
????就能定义为:
????public class foo
????
??????static SomeObject so=new SomeObject();
????
????(2) 不要对已生成的对象作过多的改动。
????对于一些类(如:String类)来讲,宁愿在重新生成一个新的对象实例,而不应该修改已生成的对象实例。
????例:
????String name="Huang";
????name="Wei";
????name="Feng";
????上述代码生成了三个String类型的对象实例。而前两个马上就需要系统进行垃圾回收处理。如果要对字符串进行连接的操作,性能将得更差,因为系统将不得为此生成更多得临时变量,如上例1所示。
????(3) 生成对象时,要分配给他合理的空间和大小JAVA中的非常多类都有他的默认的空间分配大小。对于StringBuffer类来讲,默认的分配空间大小是16个字符。如果在程式中使用StringBuffer的空间大小不是16个字符,那么就必须进行正确的初始化。
????(4) 避免生成不太使用或生命周期短的对象或变量。对于这种情况,因该定义一个对象缓冲池。以为管理一个对象缓冲池的开销要比频繁的生成和回收对象的开销小的多。
????(5) 只在对象作用范围内进行初始化。JAVA允许在代码的所有地方定义和初始化对象。这样,就能只在对象作用的范围内进行初始化。从而节约系统的开销。
????例:
????SomeObject so=new SomeObject();
????If(x==1) then
????
??????Foo=so.getXX();
????
????能修改为:
????if(x==1) then
????
??????SomeObject so=new SomeObject();
??????Foo=so.getXX();
????
????2.异常(Exceptions)
????JAVA语言中提供了try/catch来发方便用户捕捉异常,进行异常的处理。不过如果使用不当,也会给JAVA程式的性能带来影响。因此,要注意以下两点:
????(1) 避免对应用程式的逻辑使用try/catch
????如果能用if,while等逻辑语句来处理,那么就尽可能的不用try/catch语句。
????(2) 重用异常
????在必须要进行异常的处理时,要尽可能的重用已存在的异常对象。以为在异常的处理中,生成一个异常对象要消耗掉大部分的时间。
????3. 线程(Threading)
????一个高性能的应用程式中一般都会用到线程。因为线程能充分利用系统的资源。在其他线程因为等待硬盘或网络读写而 时,程式能继续处理和运行。不过对线程运用不当,也会影响程式的性能。
????例2:正确使用Vector类
????Vector主要用来保存各种类型的对象(包括相同类型和不同类型的对象)。不过在一些情况下使用会给程式带来性能上的影响。这主要是由Vector类的两个特点所决定的。第一,Vector提供了线程的安全保护功能。即使Vector类中的许多方法同步。不过如果你已确认你的应用程式是单线程,这些方法的同步就完全不必要了。第二,在Vector查找存储的各种对象时,常常要花非常多的时间进行类型的匹配。而当这些对象都是同一类型时,这些匹配就完全不必要了。因此,有必要设计一个单线程的,保存特定类型对象的类或集合来替代Vector类.用来替换的程式如下(StringVector.java):
????public class StringVector
????
??????private String [] data;
??????private int count;
??????public StringVector()
??????
????????this(10); // default size is 10
??????
??????public StringVector(int initialSize)
??????
????????data = new String[initialSize];
??????
??????public void add(String str)
??????
??????// ignore null strings
??????if(str == null) return;
??????ensureCapacity(count + 1);
??????data[count++] = str;
??????
??????private void ensureCapacity(int minCapacity)
??????
????????int oldCapacity = data.length;
????????if (minCapacity > oldCapacity)
????????
??????????String oldData[] = data;
??????????int newCapacity = oldCapacity * 2;
??????????data = new String[newCapacity];
??????????System.arraycopy(oldData, 0, data, 0, count);
????????
??????
??????public void remove(String str)
??????
??????if(str == null) return; // ignore null str
??????for(int i = 0; i < count; i++)
??????
????????// check for a match
????????if(data[i].equals(str))
????????
??????????System.arraycopy(data,i+1,data,i,count-1); // copy data
??????????// allow previously valid array element be gc�0�7d
??????????data[--count] = null;
??????????return;
????????
??????
??????
??????public final String getStringAt(int index)
??????
??????if(index < 0) return null;
??????else if(index > count) return null; // index is > # strings
??????else return data[index]; // index is good
??????
????
????因此,代码:
????Vector Strings=new Vector();
????Strings.add("One");
????Strings.add("Two");
????String Second=(String)Strings.elementAt(1);
????能用如下的代码替换:
????StringVector Strings=new StringVector();
????Strings.add("One");
????Strings.add("Two");
????String Second=Strings.getStringAt(1);
????这样就能通过优化线程来提高JAVA程式的性能。用于测试的程式如下(TestCollection.java):
????import java.util.Vector;
????public class TestCollection
????
??????public static void main(String args [])
??????
????????TestCollection collect = new TestCollection();
????????if(args.length == 0)
????????
??????????System.out.println("Usage: java TestCollection [ vector | stringvector ]");
??????????System.exit(1);
????????
????????if(args[0].equals("vector"))
????????
??????????Vector store = new Vector();
??????????long start = System.currentTimeMillis();
??????????for(int i = 0; i < 1000000; i++)
??????????
????????????store.addElement("string");
??????????
??????????long finish = System.currentTimeMillis();
??????????System.out.println((finish-start));
??????????start = System.currentTimeMillis();
??????????for(int i = 0; i < 1000000; i++)
??????????
????????????String result = (String)store.elementAt(i);
??????????
??????????finish = System.currentTimeMillis();
??????????System.out.println((finish-start));
????????
????????else if(args[0].equals("stringvector"))
????????
??????????StringVector store = new StringVector();
??????????long start = System.currentTimeMillis();
??????????for(int i = 0; i < 1000000; i++) store.add("string");
??????????long finish = System.currentTimeMillis();
??????????System.out.println((finish-start));
??????????start = System.currentTimeMillis();
??????????for(int i = 0; i < 1000000; i++)
????????????String result = store.getStringAt(i);
??????????
??????????finish = System.currentTimeMillis();
??????????System.out.println((finish-start));
????????
??????
????
????关于线程的操作,要注意如下几个方面:
????(1) 防止过多的同步
????如上所示,不必要的同步常常会造成程式性能的下降。因此,如果程式是单线程,则一定不要使用同步。
????(2) 同步方法而不要同步整个代码段
????对某个方法或函数进行同步比对整个代码段进行同步的性能要好。
????(3) 对每个对象使用多”锁”的机制来增大并发。
????一般每个对象都只有一个”锁”,这就表明如果两个线程执行一个对象的两个不同的同步方法时,会发生”死锁”。即使这两个方法并不共享所有资源。为了避免这个问题,能对一个对象实行”多锁”的机制。如下所示:
????class foo
????
??????private static int var1;
??????private static Object lock1=new Object();
??????private static int var2;
??????private static Object lock2=new Object();
??????public static void increment1()
??????
????????synchronized(lock1)
????????
??????????var1++;
????????
??????
??????public static void increment2()
??????
????????synchronized(lock2)
????????
??????????var2++;
????????
??????
????
????4.输入和输出(I/O)
????输入和输出包括非常多方面,但涉及最多的是对硬盘,网络或数据库的读写操作。对于读写操作,又分为有缓存和没有缓存的;对于数据库的操作,又能有多种类型的JDBC驱动器能选择。但无论怎样,都会给程式的性能带来影响。因此,需要注意如下几点:
????(1) 使用输入输出缓冲
????尽可能的多使用缓存。但如果要经常对缓存进行刷新(flush),则建议不要使用缓存。
????(2) 输出流(Output Stream)和Unicode字符串
当时用Output Stream和Unicode字符串时,Write类的开销比较大。因为他要实现Unicode到字节(byte)的转换.因此,如果可能的话,在使用Write类之前就实现转换或用OutputStream类代替Writer类来使用。
????(3) 当需序列化时使用transient
当序列化一个类或对象时,对于那些原子类型(atomic)或能重建的原素要表识为transient类型。这样就不用每一次都进行序列化。如果这些序列化的对象要在网络上传输,这一小小的改动对性能会有非常大的提高。
????(4) 使用高速缓存(Cache)
对于那些经常要使用而又不大变化的对象或数据,能把他存储在高速缓存中。这样就能提高访问的速度。这一点对于从数据库中返回的结果集尤其重要。
????(5) 使用速度快的JDBC驱动器(Driver)
JAVA对访问数据库提供了四种方法。这其中有两种是JDBC驱动器。一种是用JAVA外包的本地驱动器;另一种是完全的JAVA驱动器。具体要使用哪一种得根据JAVA布署的环境和应用程式本身来定。
????5.一些其他的经验和技巧
????(1) 使用局部变量。
????(2) 避免在同一个类中动过调用函数或方法(get或set)来设置或调用变量。
????(3) 避免在循环中生成同一个变量或调用同一个函数(参数变量也相同)。
????(4) 尽可能的使用static,final,private等关键字。 参考技术A 三万行的数据 第一在关键查询的列上增加索引第二最好不要把所有的数据全部显示在select中第三 做一个模糊的查询,也就是条件查询,如用户可以根据自己输入的条件查询第四 最好做个分页的显示 不然3万的数据要把页面弄多大呢? 参考技术B 数据库添加索引 前台如果是list弄分页 如果有搜索 要用快的算法 二分法什么的下拉列表的话里有3W个选项么?那得拖多长。。。。。
微服务架构的稳定性与数据一致性能如何快速提高?
微服务架构解决了很多问题,但是同时引入了很多问题。本文要探讨的是如何解决下面这几个问题。
有大量的同步 RPC 依赖,如何保证自身的可靠性?
依赖的微服务调用失败了,我应该失败,还是成功。依赖很多外部服务之后,自身如何保障稳定性。如果所有依赖的服务成功,我才算成功,自身的稳定性就堪忧了。
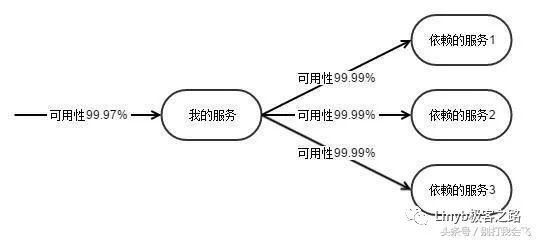
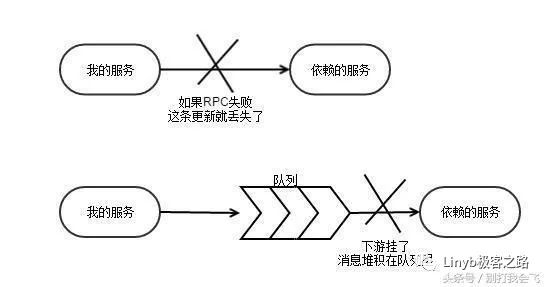
RPC 调用失败,降级处理之后如何保证数据可修复?
如果调用失败时,选择跳过。那么因此产生的数据不一致性问题如何修复?平时毛毛雨,可以忽略。但是大故障之后,人工还是要来擦屁股的,这个成本就特别高。使用消息队列的最大的意义是在让消息可以在故障的时候堆积起来,等故障恢复了再慢慢来处理,减少人工介入的成本。
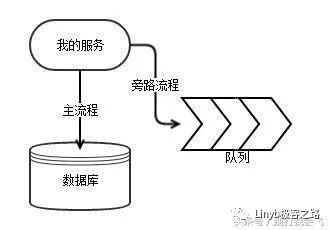
消息队列是一个RPC主流程的旁路流程,怎么保证可靠性?
依赖消息队列做系统解耦的时候,怎么确保消息自身是可靠入队列的?消息是否需要先可靠写入队列,然后再提交数据库事务?如果消息必须先写入队列,比如 Kafka。但是 Kafka 挂了怎么办?那我在线业务岂不被离线的队列给连累了?
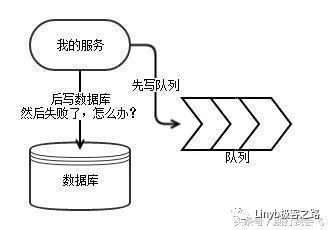
消息队列怎么保持与数据库的事务一致?
如果消息是先写入队列,然后数据库提交事务。那么就会有因为并发修改的情况下,数据库提交失败,但是消息已经写入到队列的情况。如果队列后面挂了奖励等业务流程,这个时候就会导致错发,或者要求奖励那边去再查一遍数据库的状态。但是如果先提交数据库事务,后写入队列,又无法严格保证队列里的消息是没有丢失的。
这些问题是所有混用了 RPC 和异步队列的业务都会遇到的普遍问题。这里我给一个提案来解决以上的所有问题。
同步转异步,解决稳定性问题
在平时的时候,都是 RPC 同步调用。如果调用失败了,则自动把同步调用降级为异步的。消息此时进入队列,然后异步被重试。所以处理下游依赖就变成了三种可能性:
完全强依赖,下游不能挂。
因为我的返回值依赖了某个下游的处理结果,我必须同步调用它。但是不是强依赖,可降级。降级时不返回这部分的数据。同步调用降级时转为异步的。
完全异步化。下游服务只是消费我写入的队列,我不与之直接RPC通信。
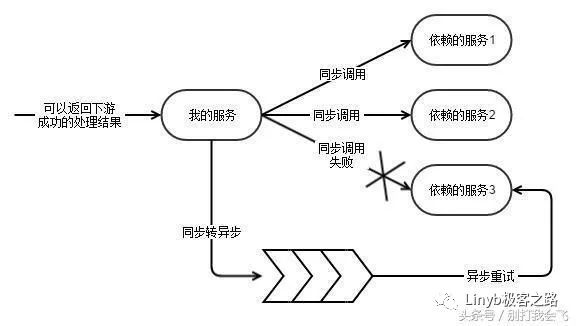
把消息队列放入到主流程
如果要把重要的业务逻辑挂在消息队列后面。必须要保证消息队列里的数据的完整性,不能有丢失的情况。所以不能是把消息队列的写入作为一个旁路的逻辑。如果消息队列写入失败或者超时,都应该直接返回错误,而不是允许继续执行。
Kafka 的稳定性和延迟时常不能满足在线服务的需要。比如如果要可靠写入三副本,Kafka 需要等待多个 broker 的应答,这个延迟可能会有比较大的波动。在无法及时写入的情况,我们需要使用本地文件充当一个缓冲。实际上是通过引入本地文件队列结合远程分布式队列构成一个可用性更高,延迟更低的组合队列方案。这个本地的队列如果能封装到一个 Kafka 的 Agent 作为本地写入的代理,那是最理想的实现方式。
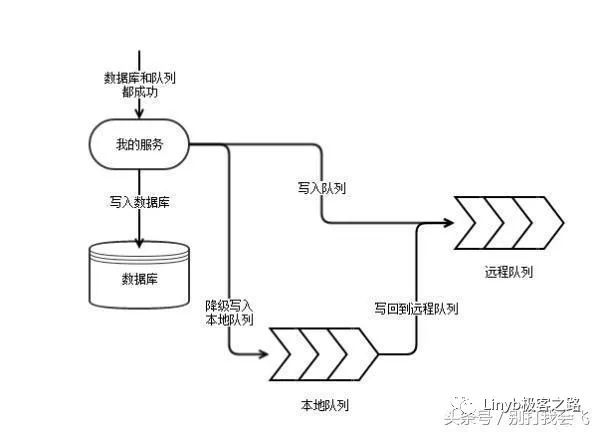
保障数据库与队列的事务一致性
需求是当数据库的事务成功时,消息一定要保证写入了队列里。如果数据库的事务失败,消息不应该出现在队列里。所以肯定不能先写队列,再写数据库,否则要让 Kafka 支持消息的回滚,这会是一个很麻烦的事情。那么就要防范这么两种情况:
数据库写入成功。然后写队列,但是队列写入失败。返回错误,让上游重试。但是上游可能会放弃,导致消息丢失。
数据库写入成功。然后全机房断电了。
这两种情况下都会出现消息没有写入队列的情况。如何仅仅依靠 Kafka 和 MySQL 这两个组件,实现数据库与队列的事务一致性呢?构想如下:
所有请求,先写入到 write-ahead-queue 这个 topic。如果这个消息就写入失败,直接返回错误给调用方,让其重试。
处理数据库事务。
如果数据库事务失败。则移动 write-ahead-queue 的 offset,代表这个请求已经被处理完毕。
如果数据库事务成功。则接下来写 business-event-queue 这个 topic。
如果写入队列成功。则移动 write-ahead-queue 的 offset,代表这个请求已经被处理完毕。
如果写入队列失败,返回成功给调用方。然后异步去重试写入 business-event-queue 这个 topic。
在数据库事务成功到消息写入到business-event-queue这个topic中间,write-ahead-queue 的 offset 都是没有被移动的。也就是如果这个过程被中断,可以从 write-ahead-queue 恢复回来。
经过重试,最终 business-event-queue 写入成功。这个时候移动 write-ahead-queue 的 offset,标记这个请求被处理完毕。
也就是说,通过引入 write-ahead-queue,以及控制这个 topic 的 offset 位置,来标记完整的分布式事务是否已经被处理完成。在过去,这个处理是否完成是以数据库的事务为标准的,没有办法保障数据库事务之后发生的事情的必然发生。
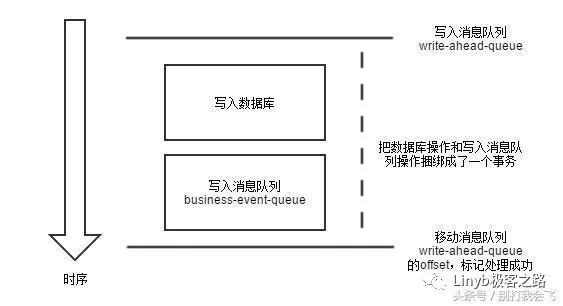
虽然看上去很复杂。但是这个连两阶段提交都不是,因为没有回滚的需求,只要数据库写入成功,消息队列写入无论如何都要成功。整个方案的关键是通过 write-ahead-queue 的写入和offset的移动这两个动作,标记了一个分布式事务的范围。只要这个过程没有完全做完,就会通过不断重试 write-ahead-queue 的方式保证其最终会被完整执行。
在没有 write-ahead-queue 的时候,我们的 RPC 执行过程是这样的:
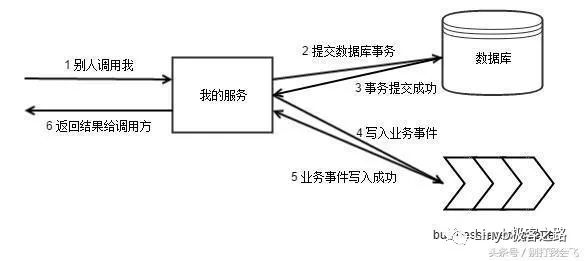
这个串行过程,因为没有保护,所以可能被中断,不能被确保完整执行。引入 write-ahead-queue 的目的就是让这个过程变得可靠。
Write-Ahead-Queue 的 Offset 管理
前面的事务方案的假设是整个处理过程,对于一个 Kafka 的 Partition 是独占的。这也就意味着有多少个 RPC 的并发处理线程(或者协程)就需要有多少个对应的 Partition 来跟踪对应线程的处理状态。这样就会变得很不经济,需要开大量的 Kafka Partition。但是如果让多个 RPC 线程共享一个 Kafka Partition,那么由谁来移动 Offset 来标记事务的执行成功呢?这里就需要引入一个 Offset 管理者,来去协调多个 RPC 线程的 Offset 的移动。
RPC 线程1,写入了 WAL1(Write-Ahead-Log),其 Offset 为 1
RPC 线程2,写入了 WAL2,其 Offset 为 2
RPC 线程3,写入了 WAL3,其 Offset 为 3
RPC 线程3执行完毕,欲把WAL3标记为执行成功,移动Offset到3。但是因为前面1和2,还没有执行成功,这个时候Offset不能被移动。
RPC 线程1执行完毕,欲把WAL1标记为执行成功,移动Offset到1。因为前面没有尚未执行完成的WAL,所以这个时候Offset被移动到1成功。
RPC 线程2执行完毕,欲把WAL2标记为执行成功,移动Offset到2。因为后面的3已经被执行完了,所以Offset被直接更新为3。
这个处理逻辑和 TCP 的窗口移动逻辑是非常类似的。用这种方式,大概就是一个RPC的进程,对应一个Kafka的partition去跟踪它的处理流程。相当于给 RPC 框架,加了一个 WAL 的保护,用于保证 RPC 流量会被完整地跑完。
其他方案
实现跨数据库和消息队列的事务一致性,还有两种做法:
去哪儿网,利用数据库作为队列,然后用数据库的多表事务来保障一致性:设
淘宝 Notify,利用两阶段提交的消息 broker 来实现:
两种实现都需要用 MySQL 来作为消息中间件,引入了比较高的运维成本。
总结
前面给了三个独立的技术方案:
使用同步转异步的方案,提高同步 RPC 的可用性,同时提高数据一致性。
引入本地队列作为兜底,提高消息队列的总体可用性,以及降低延迟。
通过引入两级队列,让 Write-Ahead-Queue 来保证 Business-Event-Queue 一定会在数据库事务成功之后被写入。
我们只需要把这三个独立的方案结合到一起,就可以把队列技术应用到纯 RPC 同步组合的微服务集群里,用于提高可用性和数据的一致性。同时可以保证这份消息数据是可靠的,从而给其他的业务逻辑把自己放在队列后面,建立了前提条件。
以上是关于java中大量数据如何提高性能?的主要内容,如果未能解决你的问题,请参考以下文章