[ElasticSearch] Aggregation :简单聚合查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[ElasticSearch] Aggregation :简单聚合查询相关的知识,希望对你有一定的参考价值。
参考技术A ES提供的聚合接口相当灵活和丰富,值得系统的学习一下。学习方式想了下,应该跟SQL结合起来,SQL相对来说比较直观,ES官网对Aggregation描述的展开也是从SQL开始的,所以通过设计不同的SQL 聚合查询场景,分别看下ES中用Aggregation API和Java API是怎么实现的。测试数据源于 官网
测试数据是汽车的销售信息,这次实现的SQL是按颜色groupby,查询每种颜色的销售数目。
Aggregation API:
java API:
Elasticsearch:使用 Java 来对 Elasticsearch 索引进行聚合
聚合是 Elasticsearch 中一个强大的工具,它允许你计算字段的最小值、最大值、平均值等等。在我之前的文章中,我许多介绍 Elasticsearch 聚合的文章,比如 Elasticsearch: aggregation 介绍。更多关于 aggregation 的介绍,请参阅 “Elastic:菜鸟上手指南” 文章中的 “Aggregations” 章节。
有不同类型的聚合,每一种都有自己的目的。 本章将详细讨论它们。在今天的例子中,我将简单地介绍像我们在 SQL 中的那些简单的聚合:
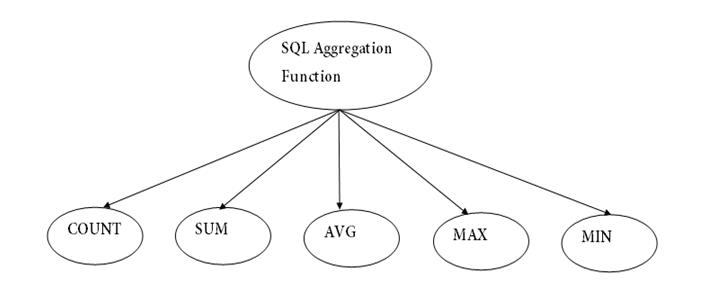
在这里,我就不详述每个聚合的具体意义了。我们着重于介绍如何使用 Jave client API 来访问并且计算相应的聚合。关于 Java client API 的介绍,你可以到 Elastic 的官方网站链接去查看。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参照如下的文章来进行安装:
创建 Java 客户端
我们首先使用一个自己的喜欢的 Java 开发工具,比如 eclipse 或者 InteliJ 来创建一个简单的 Maven 项目:
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.liuxg.demo</groupId>
<artifactId>elasticjava</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>15</maven.compiler.source>
<maven.compiler.target>15</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.11.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.11.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.11.2</version><!--$NO-MVN-MAN-VER$-->
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.11.1</version>
</dependency>
</dependencies>
</project>你需要添加相应的 dependency。
接下来,我们可以直接在 Kibana 中输入如下的命令来创建一个简单的 classindex 的索引:
POST coachingclass/_bulk
{ "index" : {"_id": 1} }
{ "classname" : "Galaxy", "cource" : "Physics","instructor":"Sheldon Kooper","language":"English","seats available":18,"fees" : 6000 }
{ "index" : {"_id": 2} }
{ "classname" : "Galaxy", "cource" : "Chemistry","instructor":"Tom Nelson","language":"English","seats available":20,"fees" : 4000}
{ "index" : {"_id": 3} }
{ "classname" : "Galaxy","cource" : "Maths","instructor":"Smith Ray","language":"English","seats available":25,"fees" : 3000 }
{ "index" : {"_id": 4} }
{ "classname" : "Galaxy", "cource" : "Biology","instructor":"Tom Nelson","language":"English","seats available":12,"fees" : 2000 }
{ "index" : {"_id": 5} }
{ "classname" : "Galaxy", "cource" : "Social Science","instructor":"Ric Johanson","language":"English","seats available":10,"fees" : 3000 }如果你对手动创建不感兴趣,你可以参考我之前的文章 “Elasticsearch:Java 运用示例” 来通过客户端应用来进行创建。
我们接下来实现一个如下的一个聚合查询:
GET classindex/_search
{
"size": 0,
"aggs": {
"sum": {
"sum": {
"field": "fees"
}
},
"avg": {
"avg": {
"field": "fees"
}
},
"min": {
"min": {
"field": "fees"
}
},
"max": {
"max": {
"field": "fees"
}
},
"cardinality": {
"cardinality": {
"field": "fees"
}
},
"count": {
"value_count": {
"field": "fees"
}
}
}
}上面显示的结果为:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min" : {
"value" : 2000.0
},
"avg" : {
"value" : 3600.0
},
"max" : {
"value" : 6000.0
},
"count" : {
"value" : 5
},
"sum" : {
"value" : 18000.0
},
"cardinality" : {
"value" : 4
}
}
}如果你对这些 min, max, avg 等聚合还不是很清楚的话,请参考我的另外一篇文章 “开始使用 Elasticsearch (3)”。
我们紧接着来创建一个叫做 Aggregation 的类:
它的内容如下:
Aggregation.java
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.metrics.Avg;
import org.elasticsearch.search.aggregations.metrics.Cardinality;
import org.elasticsearch.search.aggregations.metrics.Max;
import org.elasticsearch.search.aggregations.metrics.Min;
import org.elasticsearch.search.aggregations.metrics.Sum;
import org.elasticsearch.search.aggregations.metrics.ValueCount;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class Aggregation {
@SuppressWarnings("resource")
public static void main(String[] args) {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("classindex");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.sum("sum").field("fees"));
searchSourceBuilder.aggregation(AggregationBuilders.avg("avg").field("fees"));
searchSourceBuilder.aggregation(AggregationBuilders.min("min").field("fees"));
searchSourceBuilder.aggregation(AggregationBuilders.max("max").field("fees"));
searchSourceBuilder.aggregation(AggregationBuilders.cardinality("cardinality").field("fees"));
searchSourceBuilder.aggregation(AggregationBuilders.count("count").field("fees"));
searchRequest.source(searchSourceBuilder);
Map<String, Object> map = null;
try {
SearchResponse searchResponse = null;
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
if (searchResponse.getHits().getTotalHits().value > 0) {
SearchHit[] searchHit = searchResponse.getHits().getHits();
for (SearchHit hit : searchHit) {
map = hit.getSourceAsMap();
System.out.println("Index data:" + Arrays.toString(map.entrySet().toArray()));
}
}
Sum sum = searchResponse.getAggregations().get("sum");
double result = sum.getValue();
System.out.println("aggs Sum: " + result);
Avg aggAvg = searchResponse.getAggregations().get("avg");
double valueAvg = aggAvg.getValue();
System.out.println("aggs Avg::" + valueAvg);
Min aggMin = searchResponse.getAggregations().get("min");
double minOutput = aggMin.getValue();
System.out.println("aggs Min::" + minOutput);
Max aggMax = searchResponse.getAggregations().get("max");
double maxOutput = aggMax.getValue();
System.out.println("aggs Max::" + maxOutput);
Cardinality aggCadinality = searchResponse.getAggregations().get("cardinality");
long valueCadinality = aggCadinality.getValue();
System.out.println("aggs Cadinality::" + valueCadinality);
ValueCount aggCount = searchResponse.getAggregations().get("count");
long valueCount = aggCount.getValue();
System.out.println("aggs Count::" + valueCount);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}请注意在上面:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));我们需要根据自己的 Elasticsearch 的地址和端口地址进行相应的修改。上面的代码复制和 Elasticsearch 进行连接。
在上面,我们使用了 searchRequest.indices("classindex"); 来设置我们的索引。我们对 fee 这个字段进行了如下的聚合:
- sum
- avg
- min
- max
- cardinality
- count
编译并运行上面的代码,我们可以看到如下的输出:
Index data:[fees=6000, classname=Galaxy, instructor=Sheldon Kooper, seats available=18, cource=Physics, language=English]
Index data:[fees=4000, classname=Galaxy, instructor=Tom Nelson, seats available=20, cource=Chemistry, language=English]
Index data:[fees=3000, classname=Galaxy, instructor=Smith Ray, seats available=25, cource=Maths, language=English]
Index data:[fees=2000, classname=Galaxy, instructor=Tom Nelson, seats available=12, cource=Biology, language=English]
Index data:[fees=3000, classname=Galaxy, instructor=Ric Johanson, seats available=10, cource=Social Science, language=English]
aggs Sum: 18000.0
aggs Avg::3600.0
aggs Min::2000.0
aggs Max::6000.0
aggs Cadinality::4
aggs Count::5你可以在地址 https://github.com/liu-xiao-guo/elasticjavaaggr 下载源码。
使用 Java 程序实现 terms 桶聚合
如果你对 Bucket aggregation 还不是很熟的话,建议你阅读我之前的文章 “Elasticsearch:透彻理解 Elasticsearch 中的 Bucket aggregation”。
我们接下来实现如下的一个聚合:
GET classindex/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"DISTINCT_VALUES": {
"terms": {
"field": "instructor.keyword",
"size": 10
}
}
}
}我们使用 Kibana 进行查询,它显示的结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"DISTINCT_VALUES" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Tom Nelson",
"doc_count" : 2
},
{
"key" : "Ric Johanson",
"doc_count" : 1
},
{
"key" : "Sheldon Kooper",
"doc_count" : 1
},
{
"key" : "Smith Ray",
"doc_count" : 1
}
]
}
}
}就像在上节中显示的那样,我们修改 Aggregation.java 如下:
Aggregation.java
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class Aggregation {
public static void main(String[] args) {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("classindex");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.terms("DISTINCT_VALUES").field("instructor.keyword"));
searchRequest.source(searchSourceBuilder);
Map<String, Object> map = null;
try {
SearchResponse searchResponse = null;
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
if (searchResponse.getHits().getTotalHits().value > 0) {
SearchHit[] searchHit = searchResponse.getHits().getHits();
for (SearchHit hit : searchHit) {
map = hit.getSourceAsMap();
System.out.println("map:" + Arrays.toString(map.entrySet().toArray()));
}
}
Aggregations aggregations = searchResponse.getAggregations();
List<String> list = new ArrayList<String>();
Terms aggTerms = aggregations.get("DISTINCT_VALUES");
List<? extends Terms.Bucket> buckets = aggTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
list.add(bucket.getKeyAsString());
}
System.out.println("DISTINCT list values:" + list.toString());
} catch (IOException e) {
e.printStackTrace();
}
}
}我们编译并运行程序,它显示的结果如下:
map:[fees=6000, classname=Galaxy, instructor=Sheldon Kooper, seats available=18, cource=Physics, language=English]
map:[fees=4000, classname=Galaxy, instructor=Tom Nelson, seats available=20, cource=Chemistry, language=English]
map:[fees=3000, classname=Galaxy, instructor=Smith Ray, seats available=25, cource=Maths, language=English]
map:[fees=2000, classname=Galaxy, instructor=Tom Nelson, seats available=12, cource=Biology, language=English]
map:[fees=3000, classname=Galaxy, instructor=Ric Johanson, seats available=10, cource=Social Science, language=English]
DISTINCT list values:[Tom Nelson, Ric Johanson, Sheldon Kooper, Smith Ray]从上面我们可以看出来和在 Kibana 中显示的结果是一样的。
以上是关于[ElasticSearch] Aggregation :简单聚合查询的主要内容,如果未能解决你的问题,请参考以下文章