Java爬虫技术之HttpClient学习笔记
Posted 锅锅7533
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java爬虫技术之HttpClient学习笔记相关的知识,希望对你有一定的参考价值。
第一节、HttpClient
一、HttpClient 简介
超文本传输协议【The Hyper-Text Transfer Protocol (HTTP)】是当今互联网上使用的最重要(significant)的协议,
越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。
虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。
HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
官方站点:http://hc.apache.org/
最新版本:http://hc.apache.org/httpcomponents-client-4.5.x/
官方文档:http://hc.apache.org/httpcomponents-client-4.5.x/tutorial/html/index.html
二、Maven依赖包
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
三、HttpClient的 HelloWorld 实现
package com.guo.httpclient; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.ParseException; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; public class HelloWorld { public static void main(String args[]){ // 创建httpClient实例 CloseableHttpClient httpClient=HttpClients.createDefault(); //创建httpGet实例 HttpGet httpGet=new HttpGet("https://www.cnblogs.com/"); CloseableHttpResponse response=null; //定义个返回信息 try { response=httpClient.execute(httpGet); } catch (ClientProtocolException e) {//http协议异常 // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { //io异常 // TODO Auto-generated catch block e.printStackTrace(); }//执行http get请求 // 获取返回信息 实体 HttpEntity entity=response.getEntity(); try { System.out.println("获取网页内容"+EntityUtils.toString(entity, "utf-8"));//获取网页内容 } catch (ParseException e) { //解析异常 // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } try { response.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } try { httpClient.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
这节讲的是直接请求的 没有模拟浏览器 有些网站爬不了
下节将解决这个问题
如果爬国内网站 将上述代码的try catch去掉,抛出异常就行了
第二节、模拟浏览器抓取(以火狐浏览器为例)
有的网站设置反扒,上节的直接请求会出现如下问题

这就需要模拟浏览器来查询
一:设置请求头消息 User-Agent 模拟浏览器
1.请求头消息
打开一个网站,这里以www.tuicool.com 为例 按F12点网络
看请求头信息,是浏览器发送给目标服务器看的,目标服务器进行识别,如下图
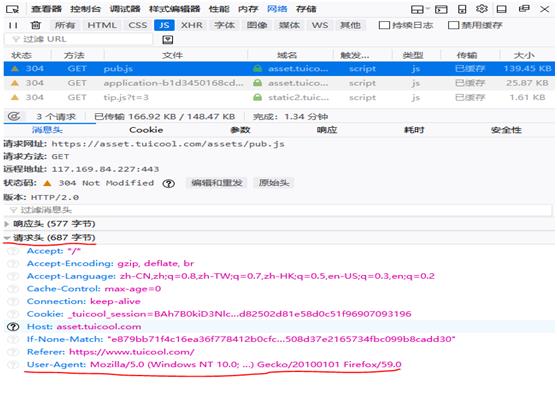
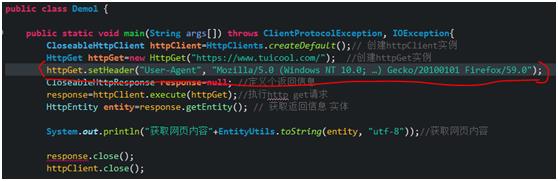
怎么模拟浏览器?
用HttpGet实例 调用 setHeader方法 设置头信息给目标服务器看的,代码如下
二:获取响应内容类型 Content-Type

获取用HttpEntity 的实体调用getContent-Type方法, 响应内容是键值对,这里我们getValue获取value值,代码如下

这里将获取网页内容注释掉,只输出响应内容信息
运行结果如下

这个带编码的utf-8,有的是不带编码的,这是根据服务器设置的
为什么要获取响应内容的类型呢?
因为我们在采集的时候,会有很多链接,要过滤掉一些无关紧要的信息
三:获取响应状态 Status
200 正常 403 拒绝 500 服务器报错 404 未找到页面
前面响应的都很顺利,响应状态为200 如下
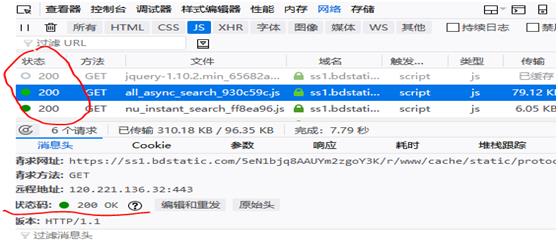
要获取响应状态,用CloseableHttpResponse 实例 调用getStatusLine方法,代码如下

这里我们只要状态200 就行了,所以加个getStatusCode方法,只获取状态码

第三节、HttpClient 抓取图片
先用上章讲的ContentType 获取下类型,代码如下

显示结果为image/jpeg 图片类型,如下

现在将这个图片放到本地,(也可以放到服务器上)
这里HttpEntity实体调用个getContent方法 这个方法是InputStream 输入流类型的,所以返回InputStream,先判断entity不为空
获取到了InputStream 输入流实例,要怎么将图片复制到本地
用传统的方法
略
简单点的话,用阿帕奇封装好的commons.io
首先maven引入jar包,然后编写代码如下

但实际开发你怎么知道是.jpg的后缀呢?开发时将地址http://xxx.com/xxx.xx 点后面的xx获取到,再拼接到保存文件。
第四节 代理IP
用髙匿代理
百度搜索代理IP,
用HttpGet实例 调用 setConfig方法。
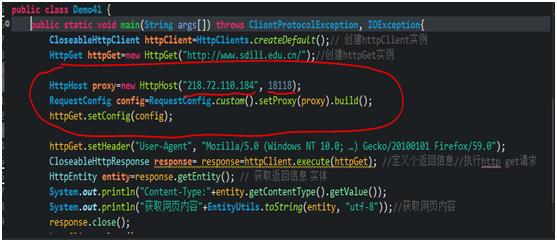
具体项目中 写个小爬虫爬 代理ip的网站 ,只需爬前十个代理ip,放到队列中。
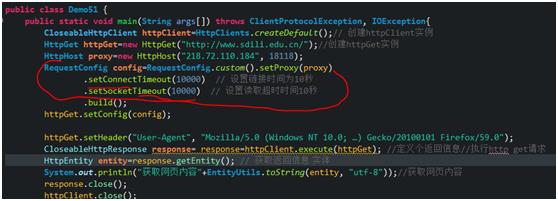
第五节 链接及读取超时
一、HttpClient连接时间
是HttpClient发送请求的地方开始到连接上目标url主机地址的时间,理论上是距离越短越快。
HttpClient的默认连接时间是1分钟,假如超过1分钟 过一会继续尝试连接。
如果一个url总是连不上,会影响其他线程的线程进去,所以我们有必要进行设置。
比如设置10秒钟 假如10秒钟没有连接上 我们就报错。用log4j日志记录相关信息。
二、HttpClient读取时间
是HttpClient已经连接到了目标服务器,然后进行内容数据的获取,一般情况 读取数据都是很快速的,
如果读取的数据量大,或是目标服务器本身的问题(比如读取数据库速度慢,并发量大等等)会影响读取时间。
还是需要设置,比如设置10秒钟 假如10秒钟还没读取完,就报错
以上是关于Java爬虫技术之HttpClient学习笔记的主要内容,如果未能解决你的问题,请参考以下文章