Java爬虫
Posted Qiao_Zhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java爬虫相关的知识,希望对你有一定的参考价值。
上一篇简单的实现了获取url返回的内容,在这一篇就要第返回的内容进行提取,并将结果保存到html中。而且这个爬虫是基于python爬虫的java语言实现,其逻辑大致相同。
一 、 需求:
抓取主页面:百度百科Python词条 https://baike.baidu.com/item/Python/407313
分析上面的源码格式,便于提取:
- 关键词分析:位于class为lemmaWgt-lemmaTitle-title的dd元素的第一个h1标签内

- 简介分析(位于class为lemma-summary的div的text内容)

- 其他相关联的标签的分析(是a标签,且href以/item/开头)

二、抓取过程流程图:
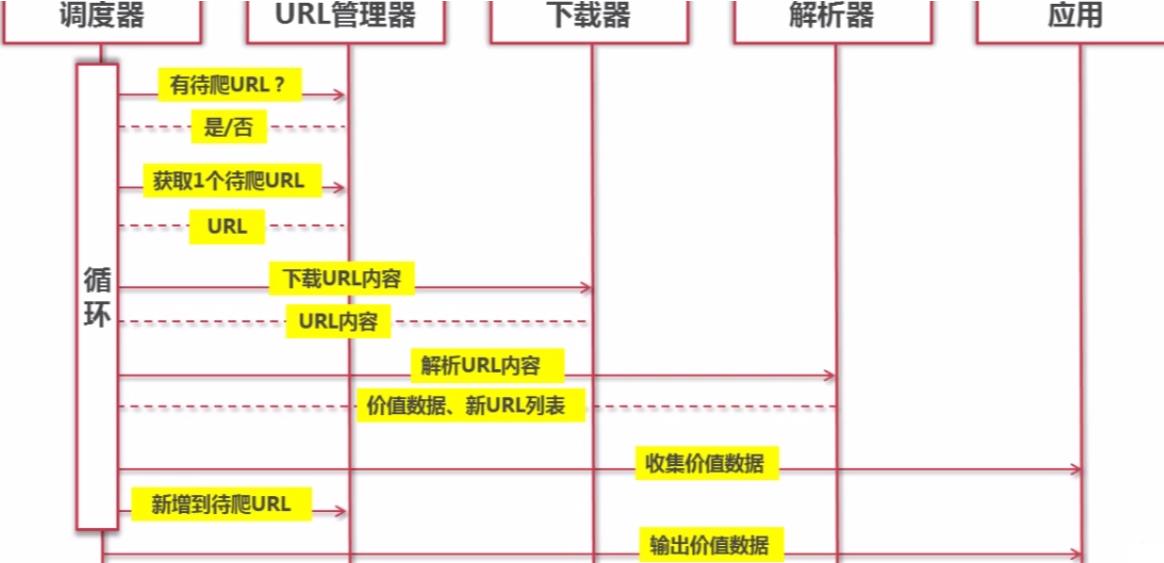
三、代码实现:
1.SpiderManager.java
构造函数中创建Url管理器,html加载器,html解析器,html输出器
craw()方法中是爬虫的主要业务逻辑。
package cn.qlq.craw.JsoupBaike; import java.io.IOException; import java.util.List; import java.util.Map; /** * 爬虫的入口 * @author liqiang * */ public class SpiderManager { private UrlManager urlManager; private HtmlLoader htmlLoader; private HtmlOutputer htmlOutputer; private HtmlParser htmlParser; public SpiderManager() { super(); this.urlManager =new UrlManager(); this.htmlLoader =new HtmlLoader(); this.htmlOutputer =new HtmlOutputer(); this.htmlParser =new HtmlParser(); } /** * 爬虫的主要逻辑 * @param url 需要爬的网站地址 */ public void craw(String url){ if(url == null || "".equals(url)){ return; } int count = 0;//记录爬取了几个页面 urlManager.addNewUrl(url); while (urlManager.hasNewUrl()){ try { String newUrl = urlManager.getNewUrl();//获取需要爬取的网站url String htmlContent = htmlLoader.loadUrl(newUrl);//爬取网站内容 Map<String,Object> datas = htmlParser.parseHtml(newUrl,htmlContent);//提取到爬到的网页中需要的信息 urlManager.addNewUrls((List<String>) datas.get("urls"));//将提取到的url信息保存到urlManager htmlOutputer.collectData(datas);//将提取到的数据收集起来 if(count == 10){ break; } count++; } catch (Exception e) { System.out.println("发生异常"+e.getMessage()); } } try { htmlOutputer.outputDatas(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public UrlManager getUrlManager() { return urlManager; } public void setUrlManager(UrlManager urlManager) { this.urlManager = urlManager; } public HtmlLoader getHtmlLoader() { return htmlLoader; } public void setHtmlLoader(HtmlLoader htmlLoader) { this.htmlLoader = htmlLoader; } public HtmlOutputer getHtmlOutputer() { return htmlOutputer; } public void setHtmlOutputer(HtmlOutputer htmlOutputer) { this.htmlOutputer = htmlOutputer; } public HtmlParser getHtmlParser() { return htmlParser; } public void setHtmlParser(HtmlParser htmlParser) { this.htmlParser = htmlParser; } }
2.UrlManager.java
维护两个list,一个用于存放未被爬取的url地址
一个用于存储已经爬取的url地址,并且两者不能有重复元素
package cn.qlq.craw.JsoupBaike; import java.util.ArrayList; import java.util.LinkedList; import java.util.List; /** * url管理器 * @author liqiang * */ @SuppressWarnings("all") public class UrlManager { /** * 存放未被访问的url的list */ private List<String> new_urls; /** * 存放已经访问过的url的list */ private List<String> old_urls; public UrlManager() { this.new_urls = new LinkedList<String>(); this.old_urls = new LinkedList<String>(); } /** * 添加一个url到list中 * @param url */ public void addNewUrl(String url) { if(url == null || "".equals(url)){ return; } if(!new_urls.contains(url) && !old_urls.contains(url) ){ new_urls.add(url); } } /** * 判断是否有新的url * @return */ public boolean hasNewUrl() { return new_urls.size()>0; } /** * 弹出一个新的url * @return */ public String getNewUrl() { if(new_urls.size() == 0){ return null; } String newUrl = new_urls.get(0);//从未访问的集合中获取一个数据 new_urls.remove(0);//移除第一个元素 old_urls.add(newUrl);//将移除的数据添加到旧的已经访问过的集合中 return newUrl; } /** * 批量添加url * @param urls 需要添加的url集合 */ public void addNewUrls(List<String> urls) { if(urls == null || urls.size()==0){ return; } for(String url:urls){ this.addNewUrl(url); } } public List<String> getNew_urls() { return new_urls; } public void setNew_urls(List<String> new_urls) { this.new_urls = new_urls; } public List<String> getOld_urls() { return old_urls; } public void setOld_urls(List<String> old_urls) { this.old_urls = old_urls; } }
3.HtmlLoader.java
主要就是利用JSoup去读取url的内容
package cn.qlq.craw.JsoupBaike; import java.io.IOException; import org.jsoup.Jsoup; /** * 读取url的内容 * @author liqiang * */ public class HtmlLoader { public String loadUrl(String newUrl) { try { return Jsoup.connect(newUrl).post().toString(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return ""; } }
4.HtmlParser.java
主要就是提取页面的主要内容(a标签,标题和简介)
package cn.qlq.craw.JsoupBaike; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * 解析器 * @author liqiang * */ public class HtmlParser { /** * 提取网站信息 * * @param newUrl * @param htmlContent * @return map中应该包含该网页上提取到的url地址(set集合)和关键字 */ public Map<String, Object> parseHtml(String newUrl, String htmlContent) { // 0.将返回的htmlContent转换成DOM树 // Document document = Jsoup.parse(htmlContent); // 1.获取到所有的a标签,且a标签的href属性包含/item List<String> urls = this.getUrls(newUrl, htmlContent); // 2.获取指定的标题和介绍 Map<String, Object> titleAndSummary = this.getTitleAndSummary(newUrl, htmlContent); // 创建一个map,将提取到的urls和标题和简介装到map中返回去 Map<String, Object> result = new HashMap<String, Object>(); result.put("urls", urls); result.put("titleAndSummary", titleAndSummary); return result; } /** * 获取标题和简介 * * @param newUrl * 传下来的访问的url * @param htmlContent * 传下来的获取到的html内容 * @return */ private Map<String, Object> getTitleAndSummary(String newUrl, String htmlContent) { Document document = Jsoup.parse(htmlContent);// 转换成DOM文档 // 1.获取标题 // first查找下面的第一个h1元素,get(index)可以获取指定位置的标签 Element title_ele = document.select("dd.lemmaWgt-lemmaTitle-title").select("h1").first(); String title_text = title_ele.text(); // 2.获取简介 Element summary_ele = document.select("div.lemma-summary").first(); String summary_text = summary_ele.text(); //将3.数据加入map返回 Map<String, Object> titleAndSummary = new HashMap<String, Object>(); titleAndSummary.put("title", title_text); titleAndSummary.put("summary", summary_text); titleAndSummary.put("url", newUrl); return titleAndSummary; } /** * 获取到所有的a标签,且a标签的href属性包含/item * * @param newUrl * @param htmlContent * @return */ private List<String> getUrls(String newUrl, String htmlContent) { Document document = Jsoup.parse(htmlContent);// 转换成DOM文档 Elements elements = document.select("a[href^=\'/item\']");// 查找以/item开头的元素的标签 List<String> urls = new ArrayList<String>(); for (Element ele : elements) { String url = newUrl.substring(0, newUrl.indexOf("/item")) + ele.attr("href"); urls.add(url); } return urls; } }
5.HtmlOutputer.java
主要作用有两个:一个是保存每次提取的信息
一个是最后爬虫完毕将提取的信息输出到html中。
package cn.qlq.craw.JsoupBaike; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * 输出器 * * @author liqiang * */ public class HtmlOutputer { private List<Map<String, Object>> collected_datas; public HtmlOutputer() { this.collected_datas = new ArrayList<Map<String, Object>>(); } /** * 收集数据 * * @param datas */ public void collectData(Map<String, Object> datas) { collected_datas.add(datas);// 将数据 添加到集合中 } /** * 最后处理所有的数据,写出到html或者保存数据库 * * @throws IOException */ public void outputDatas() throws IOException { if (collected_datas != null && collected_datas.size() > 0) { File file = new File("C:\\\\Users\\\\liqiang\\\\Desktop\\\\实习\\\\python\\\\JavaCraw\\\\out.html"); // 如果文件不存在就创建文件 if (!file.exists()) { file.createNewFile(); } // 构造FileWriter用于向文件中输出信息(此构造方法可以接收file参数,也可以接收fileName参数) FileWriter fileWriter = new FileWriter(file); // 开始写入数据 fileWriter.write("<html>"); fileWriter.write("<head>"); fileWriter.write("<title>爬取结果</title>"); fileWriter .write("<style>table{width:100%;table-layout: fixed;word-break: break-all; word-wrap: break-word;}" + "table td{border:1px solid black;width:300px}</style>"); fileWriter.write("</head>"); fileWriter.write("<body>"); fileWriter.write("<table cellpadding=\'0\' cellspacing=\'0\'>"); for (Map<String, Object> datas : collected_datas) { @SuppressWarnings("unchecked") Map<String, Object> data = (Map<String, Object>) datas.get("titleAndSummary"); String url = (String) data.get("url"); String title = (String) data.get("title"); String summary = (String) data.get("summary"); fileWriter.write("<tr>"); fileWriter.write("<td><a href=" + url + ">" + url + "</a></td>"); fileWriter.write("<td>" + title + "</td>"); fileWriter.write("<td>" + summary + "</td>"); fileWriter.write("</tr>"); } fileWriter.write("</table>"); fileWriter.write("</body>"); fileWriter.write("</html>"); // 关闭文件流 fileWriter.close(); } } }
至此代码编写基本完成,下面进行测试:
package cn.qlq.craw.JsoupBaike; import java.io.FileWriter; public class MainClass { public static void main(String[] args) { String url = "https://baike.baidu.com/item/Python/407313"; SpiderManager sm = new SpiderManager(); sm.craw(url); } }
结果:(会生成out.html)
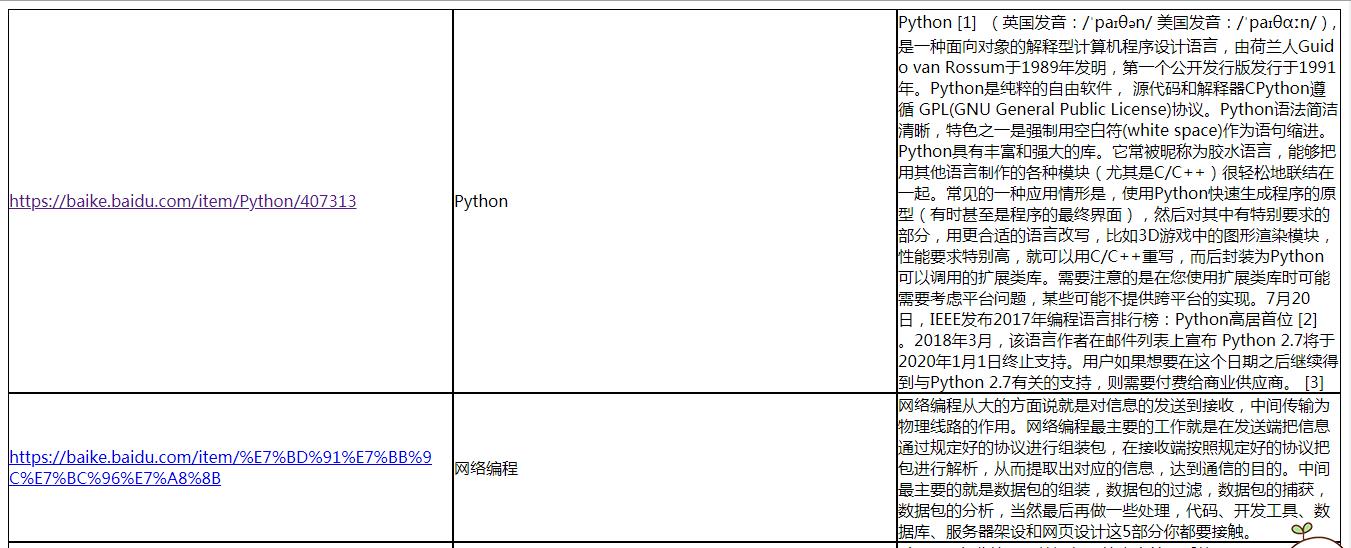
Jsoup中文API网址:http://www.open-open.com/jsoup/
python同样功能的爬虫实现:http://www.cnblogs.com/qlqwjy/p/8877705.html
以上是关于Java爬虫的主要内容,如果未能解决你的问题,请参考以下文章