MySQL 数据表优化设计(三):CHAR 和 VARCHAR 怎么选?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 数据表优化设计(三):CHAR 和 VARCHAR 怎么选?相关的知识,希望对你有一定的参考价值。
参考技术AVARCHAR 和 CHAR 是两种主要的字符串类型,用于存储字符。不幸的是,由于实现的方式依赖于存储引擎,因此很难解释这些字符串在磁盘和内存中如何存储,除了除了常用的 InnoDB 和 MyISAM 外,假设你使用了其他存储引擎,应当仔细阅读存储引擎的文档。
VARCHAR 存储可变长度的字符串,也是最常用的字符数据类型。相比固定长度的类型,VARCHAR 所需的存储空间更小,它会尽可能少地使用存储空间(例如,短的字符串占据的空间)。对于 MyISAM 来说,如果创建表的时候指定了 ROW_FORMAT=FIXED 的话,那么会使用固定的空间存储字段而导致空间浪费。VARCHAR 使用1-2个额外的字节存储字符串的长度:当最大长度低于255字节的时候使用1个字节,如果更多的话就使用2个字节。因此,拉丁字符集的 VARCHAR(10)会使用11个字节的存储空间,而 VARCHAR(1000)则会使用1002个字节的存储空间。
VARCHAR 由于能够节省空间,因此可以改善性能。但是,由于长度可变,当更新数据表的时候数据行的存储空间会变化,这一定程度上会带来额外的开销。如果数据行的长度导致原有的存储位置无法存放,那么不同的存储引擎会做不同的处理。例如 MyISAM 可能产生数据行的碎片,而 InnoDB 需要进行磁盘分页来存放更新后的数据行。
通常,如果最大的列长度远远高于平均长度的话(例如可选的备注字段),使用 VARCHAR 是划算的,同时如果更新的频次很低,那么碎片化也不会是一个问题。需要注意的是,如果使用的是 UTF-8字符集,则实际存储的字节长度是根据字符定的。对于中文,推荐的存储字符集是 utf8mb4。
CHAR 类型的长度是固定的,mysql 会对每个字段分配足够的存储空间。 存储CHAR 类型值的时候,MySQL 会移除后面多出来的空字符 。值是使用空字符进行对齐以便进行比较。对于短的字符串来说,使用 CHAR 更有优势,而如果所有的值的长度几乎一致的话,就可以使用 CHAR。例如存储用户密码的MD5值时使用 CHAR 就更合适,这是因为 MD5的长度总是固定的。同时,对于字段值经常改变的数据类型来说,CHAR 相比 VARCHAR 也更有优势,因为 CHAR 不会产生碎片。对于很短的数据列,使用 CHAR 比 VARCHAR更高效,例如使用CHAR(1)存储逻辑值的 Y 和 N,这种情况下只需要1个字节,而 VARCHAR 需要2个字节。
对于移除空字符这个特性会感觉奇怪,我们举个例子:
按上面的结果插入数据表后,string2中的前置空格不会移除,但使用 CHAR 类型存储时,string3尾随空格会被移除,使用 SQL 查询结果来检验一下:
得出来的结果如下,可以看到 CHAR 类型的 string3后面的空格被移除了,而 VARCHAR类型的没有。这种情况大多数时候不会有什么问题,实际在应用中也经常会使用 trim 函数移除两端的空字符,但是如果确实需要存储空格的时候,那就需要注意不要选择使用 CHAR 类型:
数据如何存储是由存储引擎决定的,而且存储引擎处理固定长度和可变长度的数据的方式并不相同。Memory 引擎使用固定大小的行,因此它需要分配最大可能的存储空间——即便数据长度是可变的。但是,对于字符串的对齐和空字符截断是由 MySQL 服务端完成的,因此所有存储引擎都是一样的。
与 CHAR 和 VARCHAR 相似的是 BINARY和 VARBINARY,用于存储二进制字节字符,BINARY 的对齐使用字符0的字节值来对齐,并且再获取值的时候不会截断。如果需要使用字符的字节值而不是字符的话,使用 BINARY 会更高效,这是因为比较时,一方面不需要考虑大小写,另一方面是MySQL一次只比较一个字节。
MySQL优化
A数据库可以优化层面
1数据库结构的优化(硬件升级,读写分离,分表技术,,添加缓存数据库)
2表结构的优化(3范式设计,反三范式的设计,使用合适的存储引擎)
3语句的优化(使用存储过程和触发器,合理使用索引)
B优化的思路:
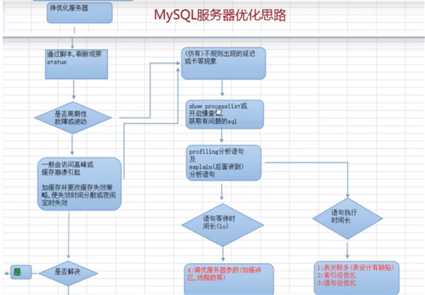
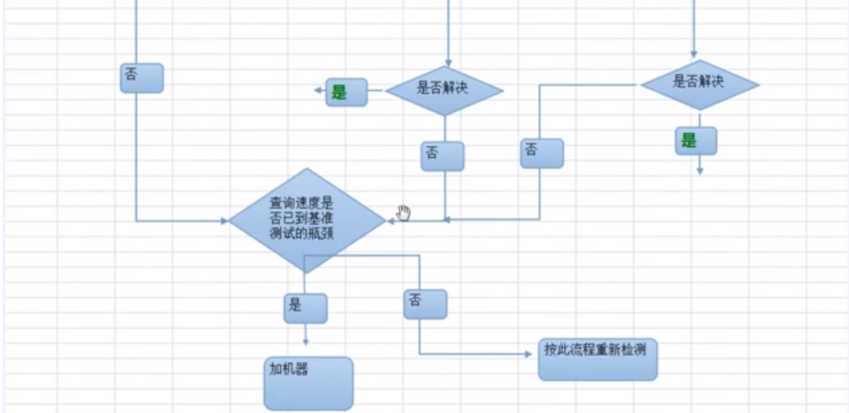
如果是周期性波动,则需要调整缓存的缓存清除策略,防止内存穿透,击穿和雪崩
如果不是周期性的问题,则需要通过processlist去分析是语句等待的时间问题还是语句的执行问题
语句的等待时间问题,则需调整数据库服务器的缓冲区和线程数
如果是语句问题,可以使用show profile for query,和explain去分析语句的具体执行细节。
数据库结构的优化:
。。。。。。。。。。。。。。。
2表结构的优化
表的设计,首先需要按照三范式去设计
- 确保每列的原子性(约束表的所有字段)(规范话所有字段,都不可再分如(中国广东,必须要分开))
- 非键字段必须依赖于键字段(一个表只描述一件事(如老师表,不存放学生表的信息))(主键时表的关键字段,非主键是具体描述这个表的信息)
- 消除传递依赖(非主键字段中,如果一个字段可以推导出另外一个字段,这叫传递依赖)
在次基础上,为了提高查询效率,可以适当增加表冗余,以减低表查询时,在关联表的时候,耗费的时间(具体需要结合业务场景)
存储引擎的选择:
innodb
mymisan
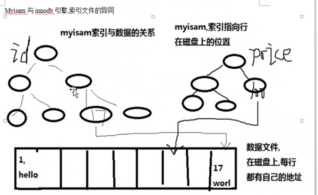
Myisam不支持事务,查询效率高,碎片化多(使用了)
Myisam的次索引和主索引 都指向物理行(根据数的节点信息,使用指针到物理地址找出信息)
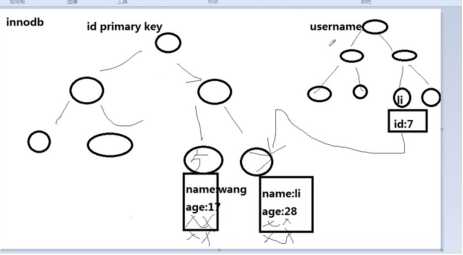
Innodb.支持视物,数据的修改优
innodb的次索引指向对主键的引用(主索引的叶子节点已存在具体的行信息)
3语句的优化
存储过程和触发器。是已经在数据库服务器编译好的语句,直接执行返回结果即可,节省了传输语句和编译语句耗费的时间
建立索引。
以上是关于MySQL 数据表优化设计(三):CHAR 和 VARCHAR 怎么选?的主要内容,如果未能解决你的问题,请参考以下文章