如何查找数据库中的重复数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查找数据库中的重复数据相关的知识,希望对你有一定的参考价值。
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count (peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people where peopleId in (select peopleId from people group by peopleId having count (peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having
扩展资料
FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。
在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列所属的表或视图。
例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定:
SELECTusername,citytable.cityid
FROMusertable,citytable
WHEREusertable.cityid=citytable.cityid
在FROM子句中可用以下两种格式为表或视图指定别名:
表名 as 别名
表名 别名
参考资料:百度百科 SELECT语句
以WPS 2019版为例
第①步:打开需要查找重复项的表格,依次点击“数据”--->“高亮重复项”
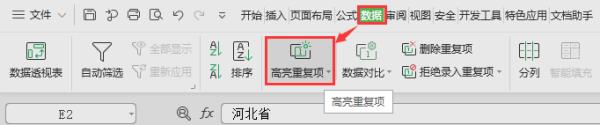
第②步:在弹出的“高亮显示重复值”中选中区域,单击确定
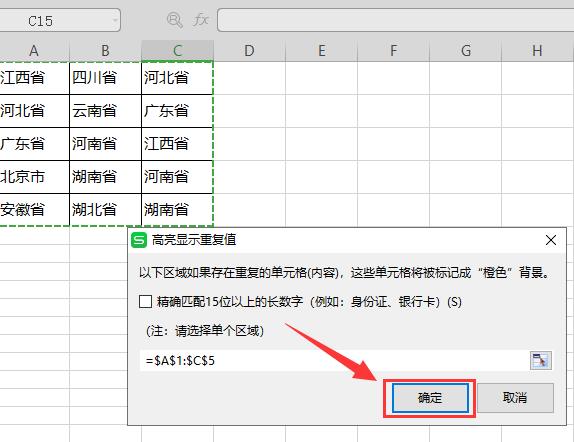
第③步:效果显示如下~
- 官方电话官方服务
- 官方网站
(数据库执行效率高)
select * from dbo.MediafileInfo as a where
(VideoDownUrl IN (SELECT VideoDownUrl FROM MediafileInfo AS B WHERE A.ProgramID <> B.ProgramID))
(数据库执行效率低)
SELECT *
FROM MediafileInfo AS A
WHERE (SELECT COUNT(*) FROM MediafileInfo WHERE VideoDownUrl=A.VideoDownUrl)>1本回答被提问者采纳 参考技术C 不要加DISTINCT 就可以了 参考技术D ========第一篇=========
在一张表中某个字段下面有重复记录,有很多方法,但是有一个方法,是比较高效的,如下语句:
select data_guid from adam_entity_datas a where a.rowid > (select min(b.rowid) from adam_entity_datas b where b.data_guid = a.data_guid)
如果表中有大量数据,但是重复数据比较少,那么可以用下面的语句提高效率
select data_guid from adam_entity_datas where data_guid in (select data_guid from adam_entity_datas group by data_guid having count(*) > 1)
此方法查询出所有重复记录了,也就是说,只要是重复的就选出来,下面的语句也许更高效
select data_guid from adam_entity_datas where rowid in (select rid from (select rowid rid,row_number()over(partition by data_guid order by rowid) m from adam_entity_datas) where m <> 1)
目前只知道这三种比较有效的方法。
第一种方法比较好理解,但是最慢,第二种方法最快,但是选出来的记录是所有重复的记录,而不是一个重复记录的列表,第三种方法,我认为最好。
========第二篇=========
select usercode,count(*) from ptype group by usercode having count(*) >1
========第三篇=========
找出重复记录的ID:
select ID from
( select ID ,count(*) as Cnt
from 要消除重复的表
group by ID
) T1
where T1.cnt>1
删除数据库中重复数据的几个方法
数据库的使用过程中由于程序方面的问题有时候会碰到重复数据,重复数据导致了数据库部分设置不能正确设置……
方法一
declare @max integer,@id integer
declare cur_rows cursor local for select 主字段,count(*) from
表名 group by 主字段 having count(*) > 1
open cur_rows
fetch cur_rows into @id,@max
while @@fetch_status=0
begin
select @max = @max -1
set rowcount @max
delete from 表名 where 主字段 = @id
fetch cur_rows into @id,@max
end
close cur_rows
set rowcount 0
方法二
有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用
select distinct * from tableName
就可以得到无重复记录的结果集。
如果该表需要删除重复的记录,可以按以下方法删除
select distinct * into #Tmp from tableName
drop table tableName
select * into tableName from #Tmp
drop table #Tmp
2、这类重复问题通常要求保留重复记录中的第一条记录,*作方法如下
假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集
select identity(int,1,1) as autoID, * into #Tmp from
tableName
select min(autoID) as autoID into #Tmp2 from #Tmp group by
Name,autoID
select * from #Tmp where autoID in(select autoID from
#tmp2)
最后一个select即得到了Name,Address不重复的结果集
更改数据库中表的所属用户的两个方法
大家可能会经常碰到一个数据库备份还原到另外一台机器结果导致所有的表都不能打开了,原因是建表的时候采用了当时的数据库用户……
========第四篇=========
如何查询数据库中的重复记录?
比如说有个表中的数据是这样:
---------
a
a
a
b
b
c
---------
查询出的结果是:
记录 数量
a 3
b 2
c 1
怎样写这个SQL语句?
-----------------------
select distinct(name),count(*) from tabname group by name;
-------------------------------------
想出来了,这样就可以排序了。
select a1,count(a1) as total from tablename group by a1 order by total desc
--------------------------------------
select distinct(a1),count(a1) as total from tablename group by a1 order by total desc
加个distinct更有效率
--------------------------------------------------------------
select p.*, m.* from table1 p left join table2 m on p.item1=m.item2 where p.item3='#$#@%$@' order by p.item3 asc limit 10
就类似这么写
========第五篇=========
如何查找数据库中的重复记录? 能在Access中用的方法
----------------------------------------------------------------------
select *
from 表 A inner join (select 字段1,字段2 from 表 group by 字段1,字段2 having Count(*)>1) B on A.字段1=B.字段1 and A.字段2=B.字段2
--------------------------------------------------------
问题:
根据其中几个字段判断重复,只保留一条记录,但是要显示全部字段,怎么查询,谢谢!!
比如
字段1 字段2 字段3 字段4
a b c 1
a b c 1
a b d 2
a b d 3
b b d 2
想得到的结果为
a b c 1
a b d 2(或者3)
b b d 2
说明,根据字段1,2,3组合不重复,字段4 不考虑,得到了3个记录
但是也要显示字段4。
方法一:
可以用临时表的方法来解决:
CurrentProject.Connection.Execute "drop table temptable"
CurrentProject.Connection.Execute "select * into temptable from 表2 where 1=2"
CurrentProject.Connection.Execute "insert into temptable(字段1,字段2,字段3) SELECT DISTINCT 表2.字段1, 表2.字段2, 表2.字段3 FROM 表2;"
CurrentProject.Connection.Execute "UPDATE temptable INNER JOIN 表2 ON (表2.字段1 = temptable.字段1) AND (表2.字段2 = temptable.字段2) AND (表2.字段3 = temptable.字段3) SET temptable.字段4 = [表2].[字段4];"
方法二:
可以直接使用一个SELECT查询筛选出需要的数据:
可以假定第四字段都选值最小的
SELECT [1],[2], [3], Min([4]) AS Min4
FROM 表1
GROUP BY 表1.[1], 表1.[2], 表1.[3];
问题:
表2
id NAME r1 r2
1 1 w ee
1 1 1 1232
1 2 123 123
1 2 12 434
1 2 123 123
2 1 123 123
ID 为数值,NAME 为字符。每条记录没有唯一标识。
要求取得 ID 和 NAME 合并后不重复的记录,如有重复保留其中一条即可,但要显示所有记录。
回答:
SELECT a.*, (select top 1 r1 from 表2 as a1 where a1.id=a.id and a1.name=a.name) AS r1, (select top 1 r2 from 表2 as a2 where a2.id=a.id and a2.name=a.name) AS r2
FROM [SELECT DISTINCT 表2.id, 表2.NAME
FROM 表2]. AS a;
SELECT a.*, dlookup("r1","表2","id=" & a.id & " and name='"& a.name & "'") AS r1, dlookup("r2","表2","id=" & a.id & " and name='"& a.name & "'") AS r2
FROM [SELECT DISTINCT 表2.id, 表2.NAME
FROM 表2]. AS a;
注意,上述代码中由于没有唯一标识列,因此显示的 R1 R2 的先后次序无从确定,一般是按输入的先后顺序,但是微软没有官方资料说明到底按哪个顺序,请网友注意。
请注意,上述表2为没有唯一标识字段,如果现在再建立一个自动编号字段“主键”则可以用以下代码
SELECT a.ID, a.name, b.r1, b.r2, b.主键
FROM (SELECT 表2.id, 表2.NAME, Min(表2.主键) AS 主键
FROM 表2
GROUP BY 表2.id, 表2.NAME) AS a inner JOIN 表2 AS b ON a.主键=b.主键;
========第六篇=========
1.查询数据库中重复的记录:
select realname,count(*) from users group by realname having count(*)>1
========第七篇=========
SELECT T0.ItemCode, T0.ItemName FROM OITM T0 WHERE exists (select 1 from OITM A where A.CODEBARS = TO.CODEBARS And A.ItemCode < > TO.ItemCode)
========第八篇=========
相信很多人在查询数据库时都会碰到检索某表中不重复记录的时候,提到检索不重复记录,马上想到的肯定是Distinct或者Group By分组,
小弟在初次使用的时候碰到了一些麻烦,这里拿出来与大家分享,希望对更多的朋友有所帮助!
先看看数据库表结构:
表名: TEST 字段: Id,A,B,C,D
其中B字段包含重复值;
Id
A B
C D
1
11 a
34 bvb
2
22 a
35 fgfg
3
33 d
ht sdf
4
44 a
345 de
5
55 c
sfsf sscv
6
66 b
rt fg
下面我们来看看用什么样的SQL语句检索出不含重复记录的数据:
使用Distinct关键字
Distinct关键字主要用来在SELECT查询记录中根据某指定字段的值去除重复记录
SELECT DISTINCT [字段名] FROM [表名] WHERE [检索条件字句]
所以用这样一句SQL就可以去掉重复项了:
[color=]SELECT DISTINCT (B) FROM TEST
但是:
这里有一个非常非常需要注意的地方:
SELECT DISTINCT [字段名]后面不能再跟其他的字段,否则检索出来的记录仍然会含有重复项;
错误写法:
SELECT DISTINCT [字段名] ,[其他字段名] FROM [表名] WHERE [检索条件字句]
实际上,我们上面SQL语句结果集里就只有B字段;(一般情况下,这种结果应该是很难满足需求的)
如果我们的记录集里还需要有其他字段值,那怎么办呢?
实际上,我们完全可以用另一种办法来解决问题;只是需要用到子查询而已!
使用GROUP BY 分组
有一点需要注意:
使用带有GROUP BY字句的查询语句时,在SELECT列表指定的列要么是GROUP BY 指定的列,要么包含聚合组函数
所以用这样一句SQL就可以去掉重复项了:
[color=]SELECT * FROM TEST WHERE id in (SELECT MIN(id) FROM TEST GROUP BY B)
这样就得到我们想要的结果集了:
Id
A B
C D
1
11 a
34 bvb
3
33 d
ht sdf
5
55 c
sfsf sscv
6
66 b
rt fg
========第九篇======mysql===
----------------------------------------------------------------------
我的mysql表中的帐号是8位的随机数,我现在想查帐号有没有重复的,应该怎样操作,
----------------------------------------------------------------------
select count(*) as num,帐号 from TABLE GROUP BY 帐号
num > 1 就有重复!
========第十篇====(着急的人直接看红字)=====
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的。所以我花了很多时间来研究这个问题,网上也查不到解决方案,期间把容容拉来帮忙,结果是我们两人都郁闷了。。。。。。。。。
下面先来看看例子:
table
id name
1 a
2 b
3 c
4 c
5 b
库结构大概这样,这只是一个简单的例子,实际情况会复杂得多。
比如我想用一条语句查询得到name不重复的所有数据,那就必须使用distinct去掉多余的重复记录。
select distinct name from table
得到的结果是:
name
a
b
c
好像达到效果了,可是,我想要得到的是id值呢?改一下查询语句吧:
select distinct name, id from table
结果会是:
id name
1 a
2 b
3 c
4 c
5 b
distinct怎么没起作用?作用是起了的,不过他同时作用了两个字段,也就是必须得id与name都相同的才会被排除。。。。。。。
我们再改改查询语句:
select id, distinct name from table
很遗憾,除了错误信息你什么也得不到,distinct必须放在开头。难到不能把distinct放到where条件里?能,照样报错。。。。。。。
很麻烦吧?确实,费尽心思都没能解决这个问题。没办法,继续找人问。
拉住公司里一JAVA程序员,他给我演示了oracle里使用distinct之后,也没找到mysql里的解决方案,最后下班之前他建议我试试group by。
试了半天,也不行,最后在mysql手册里找到一个用法,用group_concat(distinct name)配合group by name实现了我所需要的功能,兴奋,天佑我也,赶快试试。
报错。。。。。。。。。。。。郁闷。。。。。。。连mysql手册也跟我过不去,先给了我希望,然后又把我推向失望,好狠哪。。。。
再仔细一查,group_concat函数是4.1支持,晕,我4.0的。没办法,升级,升完级一试,成功。。。。。。
终于搞定了,不过这样一来,又必须要求客户也升级了。
突然灵机一闪,既然可以使用group_concat函数,那其它函数能行吗?
赶紧用count函数一试,成功,我。。。。。。。想哭啊,费了这么多工夫。。。。。。。。原来就这么简单。。。。。。
现在将完整语句放出:
select *, count(distinct name) from table group by name
结果:
id name count(distinct name)
1 a 1
2 b 1
3 c 1
最后一项是多余的,不用管就行了,目的达到。。。。。
唉,原来mysql这么笨,轻轻一下就把他骗过去了,郁闷也就我吧(对了,还有容容那家伙),现在拿出来希望大家不要被这问题折腾。
哦,对,再顺便说一句,group by 必须放在 order by 和 limit之前,不然会报错,差不多了,发给容容放网站上去,我继续忙碌。。。。。。
-----------------------------------------------------------------------------------------
更郁闷的事情发生了,在准备提交时容容发现,有更简单的解决方法。。。。。。
select id, name from table group by name
select * from table group by name
========第十一篇=========
查询及删除重复记录的方法
(一)
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
(二)
比方说
在A表中存在一个字段“name”,
而且不同记录之间的“name”值有可能会相同,
现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;
Select Name,Count(*) From A Group By Name Having Count(*) > 1
如果还查性别也相同大则如下:
Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1
(三)
方法一
declare @max integer,@id integer
declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1
open cur_rows
fetch cur_rows into @id,@max
while @@fetch_status=0
begin
select @max = @max -1
set rowcount @max
delete from 表名 where 主字段 = @id
fetch cur_rows into @id,@max
end
close cur_rows
set rowcount 0
方法二
有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用
select distinct * from tableName
就可以得到无重复记录的结果集。
如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除
select distinct * into #Tmp from tableName
drop table tableName
select * into tableName from #Tmp
drop table #Tmp
发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。
2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下
假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集
select identity(int,1,1) as autoID, * into #Tmp from tableName
select min(autoID) as autoID into #Tmp2 from #Tmp group by Name,autoID
select * from #Tmp where autoID in(select autoID from #tmp2)
最后一个select即得到了Name,Address不重复的结果集(但多了一个autoID字段,实际写时可以写在select子句中省去此列)
(四)
查询重复
select * from tablename where id in (
select id from tablename
group by id
having count(id) > 1
)
如何使用字典对象从工作表中的重复标题中查找和组合数据
【中文标题】如何使用字典对象从工作表中的重复标题中查找和组合数据【英文标题】:How do I use the dictionary object to find and combine the data from duplicate headers in a sheet 【发布时间】:2021-05-06 20:40:51 【问题描述】:我正在尝试获取第一张图像中存在的数据(带有标记),将其放入字典对象(我刚刚了解到),查找重复的标题(在本例中为“P8”条目),然后获取重复项并将它们与该标题的第一次出现组合,然后删除与重复标题关联的部分。第二张图片(无标记)是说完所有数据后的外观。请注意,“pinlables:[] 现在有多个数据实例组合在重复项中组合成一个实例。
这是我设法拼凑起来的代码(无论如何我都不是程序员,我写的最后一个 VBA 程序是 5 年前写的,我花了很长时间,我只是被这个卡住了任务,因为据我所知,它是我们小团队中最多的)我知道它缺少一些关键元素,例如正确加载密钥,那是因为我不太明白如何从我的文章和代码中做到这一点读过。我知道一般组织步骤我只是有点迷失如何使用字典对象并使其与正确的循环一起工作。所以我试图在缺失的部分发表评论,以确定我认为需要发生的事情。可能还值得注意的是,此表中的数据具有非常特定的空格、逗号、括号等格式,因为我的最终输出是一个 .yml 输入文件,该文件输入另一个程序。所以如果我能保留格式就好了。
Sub AltDictSort()
Dim Rng As Range
Dim Dn As Range
Dim n As Long
Dim nRng As Range
Dim tempDN As String
Dim TxtRng As Range
Set Rng = Range(Range("A1"), Range("A" & Rows.Count).End(xlUp))
With CreateObject("scripting.dictionary")
.CompareMode = vbTextCompare
For Each Dn In Rng
If .Exists(Dn.Value) Then
'not sure this next line does what I'm intending
tempDN = .Item(Dn.Value).Offset(2, 0) 'load Dn.Value into temp value should be something like " pinlabels: [J2-1,J2-2,J2-3]"
Dn.Value = Left(tempDN, Len(tempDN) - 15) 'Strip 15 characters from left to get "J2-1,J2-2,J2-3]"
tempDN = Dn.Value
Dn.Value = Right(tempDN, Len(tempDN) - 1) 'Strip 1 characters from right to get "J2-1,J2-2,J2-3"
tempDN = (Dn.Value + "," + Dn) 'add the two strings together to get something like this " pinlabels: [J2-1,J2-2,J2-3,J-4,J-5,J-6]"
'now I need to put the combined string back into the spot of the first occurrence of a pinlabels duplicate (in this specific case A8) but need to identify location of first occurrence
'now I need to delete the entire second occurrence ( second P8: and next two rows with mpn and pinlabels) no idea how to do this
Else
'I don't think anything needs to happen here but I'm not completely sure????
End If
Next
End With
End Sub
@JohnnieL 这是输入数据看起来像文本的样子,尽管它在发布时似乎丢失了格式。
> connectors: Startup-R-J2: mpn: 436450310 pinlabels:
> [J2-1,J2-2,J2-3]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-C,P8-D,P8-E]
>
> Startup-R-J1: mpn: 436450310 pinlabels:
> [J1-4,J1-9,J1-3,J1-6,J1-7]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-G,P8-H,P8-I,P8-J,P8-K]
>
> Startup-R-J3: mpn: 170-009-272L000 pinlabels: [J3-3,J3-2,J3-1]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-R,P8-S,P8-T]
>
> PTO1-J2: mpn: 170-009-272L000 pinlabels: [J2-5,J2-6]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-A,P8-B]
>
> PTO3-J2: mpn: 170-009-272L000 pinlabels: [J2-8,J2-7]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-N,P8-P]
>
> PTO3-J2: mpn: 170-009-272L000 pinlabels: [J2-3,J2-4]
>
> P8: mpn: D38999/20JE26PN pinlabels: [P8-R,P8-S]
>
> cables: Startup-R-J2_P8: wirecount: 3 gauge: 20 AWG length:
> 100 mm color_code: IEC
>
> Startup-R-J1_P8: wirecount: 5 gauge: 22 AWG length: 200 mm
> color_code: IEC
>
> Startup-R-J3_P8: wirecount: 3 gauge: 24 AWG length: 300 mm
> color_code: IEC
>
> PTO1-J2_P8: wirecount: 2 gauge: 26 AWG length: 400 mm
> color_code: IEC
>
> PTO3-J2_P8: wirecount: 2 gauge: 28 AWG length: 500 mm
> color_code: IEC
>
> PTO3-J2_P8: wirecount: 2 gauge: 30 AWG length: 600 mm
> color_code: IEC
>
>
> connections:
> -
> - Startup-R-J2: [J2-1,J2-2,J2-3]
> - Startup-R-J2_P8: [1-3]
> - P8: [P8-C,P8-D,P8-E]
> -
> - Startup-R-J1: [J1-4,J1-9,J1-3,J1-6,J1-7]
> - Startup-R-J1_P8: [1-5]
> - P8: [P8-G,P8-H,P8-I,P8-J,P8-K]
> -
> - Startup-R-J3: [J3-3,J3-2,J3-1]
> - Startup-R-J3_P8: [1-3]
> - P8: [P8-R,P8-S,P8-T]
> -
> - PTO1-J2: [J2-5,J2-6]
> - PTO1-J2_P8: [1-2]
> - P8: [P8-A,P8-B]
> -
> - PTO3-J2: [J2-8,J2-7]
> - PTO3-J2_P8: [1-2]
> - P8: [P8-N,P8-P]
> -
> - PTO3-J2: [J2-3,J2-4]
> - PTO3-J2_P8: [1-2]
> - P8: [P8-R,P8-S]
【问题讨论】:
@dhnobles 嗨,您能否将输入数据作为文本粘贴到此处?我很乐意提供帮助,但不能 100% 确定输入数据:是第一个工作表屏幕截图上的第 1 行到第 26 行吗?谢谢 当项目不存在时,循环应该将项目添加到字典中,并且您添加的项目应该有足够的元数据以允许下一次迭代找出插入行的位置;通过将Range 对象存储到字典中(以Dn.Value 为关键字,例如“P8”),您将拥有该元数据,然后无需删除任何行,因为您只会输出您需要的行,您在哪里需要他们。另一种解决方法是使用对象对数据进行建模,创建一个收集所有数据的“读取器”循环,然后是一个处理它的“进程”循环,然后是一个输出结果的“写入器”循环
数据是否来自文本文件?那么就没有理由先将其导入 Excel 工作表。这将是某种具有固定结构的数据交换格式,对吧?另一个问题。为什么使用字典如此重要?可能它与它配合得很好,我相信我只是一个对此有想法的人。但可能还有其他同样有效的方法。
我正在用另一种方法起草一份答案草稿,但@Zwenn 是对的,你可能在这里并不需要Dictionary,如果输入实际上是文本文件,然后您可以从代码中打开它并处理原始文本(没有 Excel 修改日期和长数字,尽管这看起来不是这个特定数据的问题)。
dhnobles,如果它现在需要进一步处理,我很确定之前的数据处理不是最佳的。我不知道源数据来自何处以及以何种形式从源中获得。但是,如果使用这些数据追求不同的目标,那么首先将其转换为标准格式是最有意义的。许多人已经为这些格式绞尽脑汁,因此它们可以相对容易地用于不同目的。
【参考方案1】:
我会从一个可能看起来像这样的类模块开始 - 我们暂时称它为 ConnectorInfo:
Option Explicit
Public ConnectorID As String
Public MPN As String
Public PinLabels As New Collection
这个想法是对我们正在查看的数据进行建模;输出中表示的每个“对象”都有一个“ConnectorID”值(“P8”、“Startup-R-J1”、“PTO3-J2”等)、一个 MPN 值(“436450310”、“170-009- 272L000" 等),以及一些需要组合的引脚标签,因此需要有代码可以将这个PinLabels 集合转换为一个字符串,用逗号分隔它们并用方括号将列表包裹起来。
因此,让我们向该类模块添加一个公共函数,它通过将集合复制到一个数组中,然后使用VBA.Strings.Join 函数生成引脚标签列表来实现这一点:
Public Function CombinePinLabels() As String
ReDim result(1 To PinLabels.Count) As String
Dim i As Long
For i = 1 To PinLabels.Count
result(i) = PinLabels(i)
Next
CombinePinLabels = "[" & Join(result, ",") & "]"
End Function
由于输入将读取 PinLabels 作为字符串,我们需要一个过程(因为我们在一个类模块中,我们可以将其称为“方法”)为我们拼接它们,同时确保没有标签重复;我们可以通过键入集合项来做到这一点(不需要字典,因为我们实际上并没有访问键):
Public Sub ParsePinLabels(ByVal inputValue As String)
'expect inputValue to look like "[123,456,ABC-123,XYZ-000-ABC]"; assert that (i.e. break here before we make a mess):
Debug.Assert Left$(inputValue, 1) = "["
Debug.Assert Right$(inputValue, 1) = "]"
'strip the prefix and brackets:
Dim parsed As String
parsed = Mid$(inputValue, 2, Len(inputValue - 2))
Dim values As Variant
values = Strings.Split(parsed, ",")
Dim i As Long
For i = LBound(values) To UBound(values)
On Error Resume Next 'prevent blowing up when key already exists
PinLabels.Add values(i), values(i)
On Error GoTo 0 'important!
Next
End Sub
注意输入逻辑和格式在这里基本上是不相关的:需要进行的处理独立于输入格式和输出格式的。
那么让我们构建输出吧。
[...] 我的最终输出是一个输入另一个程序的 .yml 输入文件。
肯定会折腾操作Excel对象的想法:你想要的是让你的代码生成一个.yml文本文件。
处理输入的代码会将ConnectorInfo 对象的集合提供给产生输出的代码,因此我们已经知道我们需要一个过程。在标准模块(例如Module1)中,您希望有这样的过程:
Public Sub GenerateOutputYML(ByVal connectors As Collection)
Dim connector As ConnectorInfo
For Each connector In connectors
'TODO
Next
End Sub
但是,我们需要它输出到一个特定的文件名——让我们把它作为一个参数来考虑我们以后如何提供它:
Public Sub GenerateOutputYML(ByVal filePath As String, ByVal connectors As Collection)
Dim handle As Long
handle = VBA.FreeFile
On Error GoTo CleanFail 'MUST handle errors when dealing with filesystem I/O
Open filePath For Output As #handle
Print #handle, "connectors:"
'use ForEach..Next loops to iterate object collections
Dim connector As ConnectorInfo
For Each connector In connectors
'each Print # statement writes a line to the text file,
'Spc() function writes the number of specified spaces to control indentation.
Print #handle, Spc(2) & connector.ConnectorID & ":"
Print #handle, Spc(4) & "mpn: " & connector.MPN
Print #handle, Spc(4) & "pinlabels: " & connector.CombinePinLabels
Print #handle 'leaves an empty line between connectors
Next
CleanExit:
Close #handle
Exit Sub
CleanFail:
MsgBox Err.Description
Resume CleanExit
End Sub
现在剩下要做的就是将输入解析为Collection 的ConnectorInfo 对象。您可以通过在 Excel 中打开文本文件然后迭代单元格来执行此操作 - 或者您可以使用类似的 Open 语句以编程方式在内存中打开文本文件,并且它可以存在于一个需要文件名并返回 output 函数想要使用的集合:
Public Function ParseInput(ByVal intputFilePath As String) As Collection
Dim handle As Long
handle = VBA.FreeFile 'gets an available file handle
On Error GoTo CleanFail
Open inputFilePath For Input As #handle 'never hard-code the handle!
Dim currentLine As String
LineInput #handle, currentLine 'read the first line
Debug.Assert currentLine = "connectors:" 'right?
Dim contents As Object 'early-bound: As Scripting.Dictionary (requires library reference)
Set contents = CreateObject("Scripting.Dictionary") 'early-bound: = New Scripting.Dictionary
Dim currentItem As ConnectorInfo
Dim currentKey As String
Do Until EOF(handle)
LineInput #handle, currentLine
currentKey = Left$(currentLine, Len(currentLine) - 1) 'strip the colon char
If contents.Exists(currentKey) Then
'we have seeen this ID before; fetch it
Set currentItem = contents(currentKey)
Else
'new ID; create a new info object
Set currentItem = New ConnectorInfo
contents.Add currentKey, currentItem
End If
'assumes MPN is the same for all duplicates of a given ConnectorID
LineInput#handle, currentLine
currentItem.MPN = Mid$(currentLine, Len("mpn: "))
LineInput#handle, currentLine
currentItem.ParsePinLabels Mid$(currentLine, Len("pinlabels: ["))
Loop
'at this point the items dictionary should contain all the ConnectorInfo objects we want to output.
'GenerateOutputYML wants a Collection, so we iterate the array returned dictionary's Items function
Dim result As New Collection
Dim i As Long 'use a For..Next loop to iterate arrays
For i = LBound(contents.Items) To UBound(contents.Items)
result.Add contents.Items(i)
Next
CleanExit:
Close #handle
Set ParseInput = result
Exit Function
CleanFail:
MsgBox Err.Description 'for debugging; user doesn't need to see this
Set result = New Collection 'return an empty collection on error
Resume CleanFail
End Function
缺少的部分是一个宏,它知道在哪里获取输入文件,在哪里保存输出文件,并调用读取器和写入器过程 - 现在我们已经抽象出所有血腥的细节,我们只剩下一个清晰的高层次故事要讲:
Public Sub ParseYML()
Const inputFile As String = "C:\Path\Input.txt"
Const outputFile As String = "C:\Path\Output.yml"
Dim connectors As Collection
Set connectors = ParseInput(inputFile)
If connectors.Count > 0 Then
GenerateOutputYML outputFile, connectors
MsgBox "File '" & outputFile & "' was generated successfully for " & connectors.Count & " connectors."
Else
MsgBox "No data was read from the specified input file."
End If
End Sub
这不是唯一可行的方法,但作为一般经验法则,将数据本身 (ConnectorInfo) 与输入和输出清楚地分开是一个非常好的主意:将数据与正在输入的输入交织在一起在生成输出时读取所有内容,可能会工作......但之后很容易难以调整。
通过将解析输入与生成输出分开,您可以更轻松地准确隔离需要调整的代码,而不必影响代码的其他部分。
【讨论】:
注意:如果文件路径不能硬编码,您可能需要使用Application.GetOpenFileName 提示用户输入要使用的路径。
所以我这两天一直在搞乱这段代码,我一辈子都无法让它运行。过了一会儿,我发现了一些语法错误(Line Input 作为两个单词而不是 LineInput),但它仍然不断地被一件接一件的事情所困扰。你真的可以将一个变量作为另一个变量进行调暗吗?这会引发类型未定义的错误。 Dim currentItem As ConnectorInfo currentLine 在任何地方都没有变暗,并且引发了一个未定义的错误,所以我将 Dim currentLine 添加为 String '我认为它应该是一个字符串???我正在努力解决这一切。
@dhnobles ConnectorInfo 应该是您项目中的 类模块 的名称,它看起来像顶部的第一个 sn-p。如果您的类模块的名称是 Class1,按 F4 键调出 properties 工具窗口,您将看到一个值为“Class1”的(Name) 属性 - 将其更改为“ConnectorInfo”。
CombinePinLabels 和 ParsePinLabels 过程是 ConnectorInfo 类模块的成员。然后是一个标准模块,它可以是Module1,带有ParseYML 宏和ParseInput 函数(然后可以是Private)和GenerateOutputYML 子(也可以是Private 如果它与 ParseYML 宏/过程在同一个模块中)。
@dhnobles 再次为未经测试的代码道歉(这个想法不是提供可复制粘贴的 100% 工作代码,而是更多地说明如何将事物分解为不同的范围和模块,即如何构建一个小程序,明确分离关注点,避免意大利面混乱;如果你愿意的话,旧的钓鱼竿与鱼故事),但我 assure you currentLine 在这篇文章中声明,尽管有任何拼写错误(注意我是如何系统地在第一次使用之前立即声明本地人的?[循环体中/外是另一场辩论!]);-)【参考方案2】:
使用字典组合字符串
调整常量部分中的值。请注意,如果您使用相同的单元格地址,数据将被覆盖。守则
Option Explicit
Sub AltDictSort()
' Define constants.
Const FirstCell As String = "A2"
Const dstCell As String = "B2"
Const setsLen As Long = 4
' Define Source Range.
Dim rg As Range
Dim wrCount As Long ' Worksheet Rows Count
With Range(FirstCell)
wrCount = .Worksheet.Rows.Count
Set rg = .Resize(wrCount - .Row + 1) _
.Find("pinlabels:*", , xlFormulas, xlPart, , xlPrevious)
If rg Is Nothing Then Exit Sub
Set rg = .Resize(rg.Row - .Row + 2) ' + 1 because last empty row
End With
' Define Sets Count.
Dim SetsCount As Long: SetsCount = rg.Rows.Count / setsLen
If rg.Rows.Count Mod setsLen > 0 Then Exit Sub
' Write values from range to array.
Dim Data As Variant: Data = rg.Value
Dim rCount As Long ' Result Rows Count
' Write values from array to dictionary, and back to array.
With CreateObject("Scripting.Dictionary")
.CompareMode = vbTextCompare
Dim arrString() As String: ReDim arrString(1 To 2)
Dim m As Long: m = 1
Dim n As Long
Dim iniString As String
For n = 1 To SetsCount
iniString = Data(m, 1)
If .Exists(iniString) Then
arrString = .Item(iniString)
arrString(2) = combineString(arrString(2), Data(m + 2, 1))
Else
arrString(1) = Data(m + 1, 1)
arrString(2) = Data(m + 2, 1)
End If
.Item(iniString) = arrString
m = m + setsLen
Next n
rCount = .Count * setsLen
ReDim Data(1 To rCount, 1 To 1)
m = 1
Dim Key As Variant
For Each Key In .Keys
Data(m, 1) = Key
Data(m + 1, 1) = .Item(Key)(1)
Data(m + 2, 1) = .Item(Key)(2)
m = m + setsLen
Next Key
End With
With rg.Worksheet.Range(dstCell)
.Resize(wrCount - .Row + 1).ClearContents
.Resize(rCount).Value = Data
End With
End Sub
Function combineString( _
ByVal str1 As String, _
ByVal str2 As String, _
Optional ByVal lChar As String = "[", _
Optional ByVal rChar As String = "]", _
Optional ByVal Delimiter As String = ",") _
As String
Dim lPos As Long: lPos = InStr(1, str1, lChar)
Dim lStr As String: lStr = Left(str1, lPos)
Dim r1Pos As Long: r1Pos = InStr(1, str1, rChar)
Dim rStr As String: rStr = Right(str1, Len(str1) - r1Pos + 1)
Dim m1str As String: m1str = Mid(str1, lPos + 1, r1Pos - lPos - 1)
Dim r2Pos As String: r2Pos = InStr(1, str2, rChar)
Dim m2str As String: m2str = Mid(str2, lPos + 1, r2Pos - lPos - 1)
combineString = lStr & m1str & Delimiter & m2str & rStr
End Function
【讨论】:
目前没有什么要调试的。该代码对字符串非常敏感。它们必须包含一个开括号[ 和一个闭括号]。如果他们不这样做,代码将失败。另请注意,数据必须在“四单元组”中。第一个单元格将是键,第二个单元格无关紧要(它只是从第一次出现的地方复制),第三个单元格将包含括号,第四个将为空。如果您不能以这种格式生成数据,则代码是无用的。如果您能解释您的数据与图像数据的不同之处,我可以尝试修改。
这是 Google 云端硬盘上my file 的副本。也许看到我的示例数据会给你一个想法。
如果我单击Example 工作表中的按钮,它会创建一个文件。在该文件中,选择第一次出现cables 上方的单元格(表示不同格式的开头),删除到底部,然后就可以走了。请注意cables 上方的单元格不是空的(它是空白的)。 Find 方法会找到它,并执行偏移量,然后退出 sub,因为行数不能被 4 整除。或者,当它找不到它时,您可以将 xlFormulas 更改为 xlValues,或者只是使用+ 1 而不是+ 2。
哈,哈,哈。我找到了一个简单的解决方法:只需更改为.Find("pinlabels:*", , xlFormulas, xlPart, , xlPrevious),它将找到最后一次出现的"pinlabels:"。
我已经编辑了代码。它现在包含我在之前的评论中提出的更改。它仍然适用于我:J2-8,J2-7,J2-3,J2-4.以上是关于如何查找数据库中的重复数据的主要内容,如果未能解决你的问题,请参考以下文章