Nebula 宏设来用不起是为啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nebula 宏设来用不起是为啥相关的知识,希望对你有一定的参考价值。
Nebula释厄传的游戏 我按照网上的方法编了个宏文件放进去 游戏设置里也改了 但游戏里还是没有用 这是为什么啊 我QQ10151022
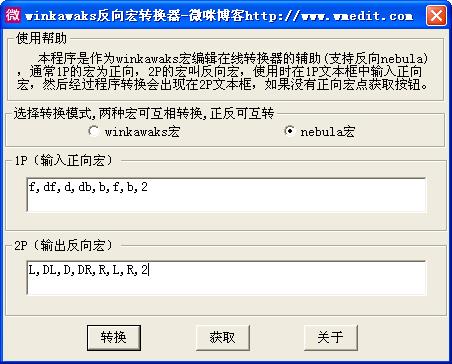
指令出招表要求输入正确、另外要正向宏和反向宏都需要。
http://www.moon-soft.com/program/bbs/readelite759275.htm
我的脚本
[0]
Name=1
Macro1Name=必杀攻击右边
Macro1Move=B,D,DF,F,B,F,1
Macro2Name=必杀攻击左边
Macro2Move=r,d,ld,l,r,d,ld,l,1 参考技术B 你下个nebula宏编辑器,就好啦
分析下为什么spring 整合mybatis后为啥用不上session缓存
因为一直用spring整合了mybatis,所以很少用到mybatis的session缓存。 习惯是本地缓存自己用map写或者引入第三方的本地缓存框架ehcache,Guava
所以提出来纠结下
实验下(spring整合mybatis略,网上一堆),先看看mybatis级别的session的缓存
放出打印sql语句
configuration.xml 加入
<settings>
<!-- 打印查询语句 -->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
测试源代码如下:
dao类
/**
* 测试spring里的mybatis为啥用不上缓存
*
* @author 何锦彬 2017.02.15
*/
@Component
public class TestDao {
private Logger logger = Logger.getLogger(TestDao.class.getName());
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
@Autowired
private SqlSessionFactory sqlSessionFactory;
/**
* 两次SQL
*
* @param id
* @return
*/
public TestDto selectBySpring(String id) {
TestDto testDto = (TestDto) sqlSessionTemplate.selectOne("com.hejb.TestDto.selectByPrimaryKey", id);
testDto = (TestDto) sqlSessionTemplate.selectOne("com.hejb.TestDto.selectByPrimaryKey", id);
return testDto;
}
/**
* 一次SQL
*
* @param id
* @return
*/
public TestDto selectByMybatis(String id) {
SqlSession session = sqlSessionFactory.openSession();
TestDto testDto = session.selectOne("com.hejb.TestDto.selectByPrimaryKey", id);
testDto = session.selectOne("com.hejb.TestDto.selectByPrimaryKey", id);
return testDto;
}
}
测试service类
@Component
public class TestService {
@Autowired
private TestDao testDao;
/**
* 未开启事务的spring Mybatis查询
*/
public void testSpringCashe() {
//查询了两次SQL
testDao.selectBySpring("1");
}
/**
* 开启事务的spring Mybatis查询
*/
@Transactional
public void testSpringCasheWithTran() {
//spring开启事务后,查询1次SQL
testDao.selectBySpring("1");
}
/**
* mybatis查询
*/
public void testCash4Mybatise() {
//原生态mybatis,查询了1次SQL
testDao.selectByMybatis("1");
}
}
输出结果:
testSpringCashe()方法执行了两次SQL, 其它都是一次
源码追踪:
先看mybatis里的sqlSession
跟踪到最后 调用到 org.apache.ibatis.executor.BaseExecutor的query方法
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; //先从缓存中取
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); //注意里面的key是CacheKey
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
贴下是怎么取出缓存数据的代码
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
final Object cachedParameter = localOutputParameterCache.getObject(key);//从localOutputParameterCache取出缓存对象
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}
发现就是从localOutputParameterCache就是一个PerpetualCache, PerpetualCache维护了个map,就是session的缓存本质了。
重点可以关注下面两个累的逻辑
PerpetualCache , 两个参数, id和map
CacheKey,map中存的key,它有覆盖equas方法,当获取缓存时调用.
这种本地map缓存获取对象的缺点,就我踩坑经验(以前我也用map去实现的本地缓存),就是获取的对象非clone的,返回的两个对象都是一个地址
而在spring中一般都是用sqlSessionTemplate,如下
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:configuration.xml" />
<property name="mapperLocations">
<list>
<value>classpath*:com/hejb/sqlmap/*.xml</value>
</list>
</property>
</bean>
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg ref="sqlSessionFactory" />
</bean>
在SqlSessionTemplate中执行SQL的session都是通过sqlSessionProxy来,sqlSessionProxy的生成在构造函数中赋值,如下:
this.sqlSessionProxy = (SqlSession) newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class },
new SqlSessionInterceptor());
sqlSessionProxy通过JDK的动态代理方法生成的一个代理类,主要逻辑在InvocationHandler对执行的方法进行了前后拦截,主要逻辑在invoke中,包好了每次执行对sqlsesstion的创建,common,关闭
代码如下:
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 每次执行前都创建一个新的sqlSession
SqlSession sqlSession = getSqlSession(
SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType,
SqlSessionTemplate.this.exceptionTranslator);
try {
// 执行方法
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// release the connection to avoid a deadlock if the translator is no loaded. See issue #22
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
因为每次都进行创建,所以就用不上sqlSession的缓存了.
对于开启了事务为什么可以用上呢, 跟入getSqlSession方法
如下:
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType, PersistenceExceptionTranslator exceptionTranslator) {
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
notNull(executorType, NO_EXECUTOR_TYPE_SPECIFIED);
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
// 首先从SqlSessionHolder里取出session
SqlSession session = sessionHolder(executorType, holder);
if (session != null) {
return session;
}
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Creating a new SqlSession");
}
session = sessionFactory.openSession(executorType);
registerSessionHolder(sessionFactory, executorType, exceptionTranslator, session);
return session;
}
在里面维护了个SqlSessionHolder,关联了事务与session,如果存在则直接取出,否则则新建个session,所以在有事务的里,每个session都是同一个,故能用上缓存了
留下个下小思考
,CacheKey是怎么作为KEY来判断是否执行的是同一条SQL与参数的呢
以上是关于Nebula 宏设来用不起是为啥的主要内容,如果未能解决你的问题,请参考以下文章