java 怎么提取 txt小说里面的章节目录 并记录位置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 怎么提取 txt小说里面的章节目录 并记录位置相关的知识,希望对你有一定的参考价值。
java 怎么提取 txt小说里面的章节目录 并记录位置
初学习java 弄个自己感兴趣的东西做,选在了txt小说阅读器
在自动提取章节目录的这个功能上就卡住住了
1)怎么提取章节名字,小说里面一般都是 第**章 第**节等等这种形式,用什么方法函数来匹配正则
2)匹配正则了 用什么方法 直接提取这一行
3)提取到了这一行 怎么确定这个一行在全文中的位置!
4)阅读进度到了某个段落 怎么确定这个段在全文本的位置,保证我下次能接着读?
public static void readTxtFile(String filePath)
try
String encoding = "UTF-8";
File file = new File(filePath);
if (file.isFile() && file.exists()) // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
int offset = 0; //章节所在行数
int count = 1; //章节数
List<InfoVo> list = new ArrayList<InfoVo>();
InfoVo infoVo;
while ((lineTxt = bufferedReader.readLine()) != null)
infoVo = new InfoVo();
offset++;
if (lineTxt.contains("第") && lineTxt.contains("章"))
infoVo.setCount(count);
infoVo.setOffset(offset);
infoVo.setTitle(lineTxt);
list.add(infoVo);
count++;
System.out.println(list.size());
System.out.println(list.get(0).getCount());
System.out.println(list.get(0).getOffset());
System.out.println(list.get(0).getTitle());
read.close();
else
System.out.println("找不到指定的文件");
catch (Exception e)
System.out.println("读取文件内容出错");
e.printStackTrace();
public static void main(String[] args)
// Console.mainMenu();
String filePath = "C:\\20130815.txt";
readTxtFile(filePath);
InfoVo结构:
public class InfoVo
private Integer count;
private Integer offset;
private String title;
public Integer getCount()
return count;
public void setCount(Integer count)
this.count = count;
public Integer getOffset()
return offset;
public void setOffset(Integer offset)
this.offset = offset;
public String getTitle()
return title;
public void setTitle(String title)
this.title = title;
爬取小说《重生之狂暴火法》 1~140章
需要使用的库
- requests
- re
1、打开网址“ http://www.17k.com/list/2726194.html ”查看章节目录
按F12查看如下:
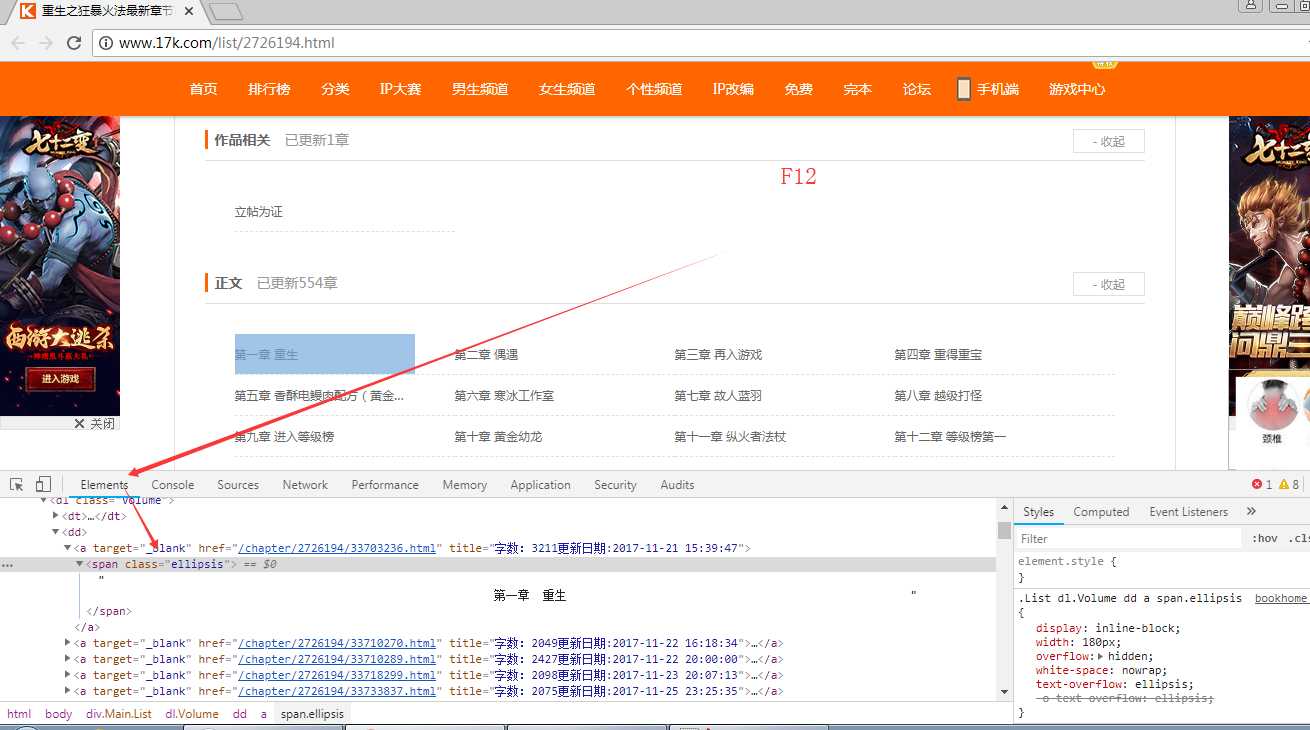
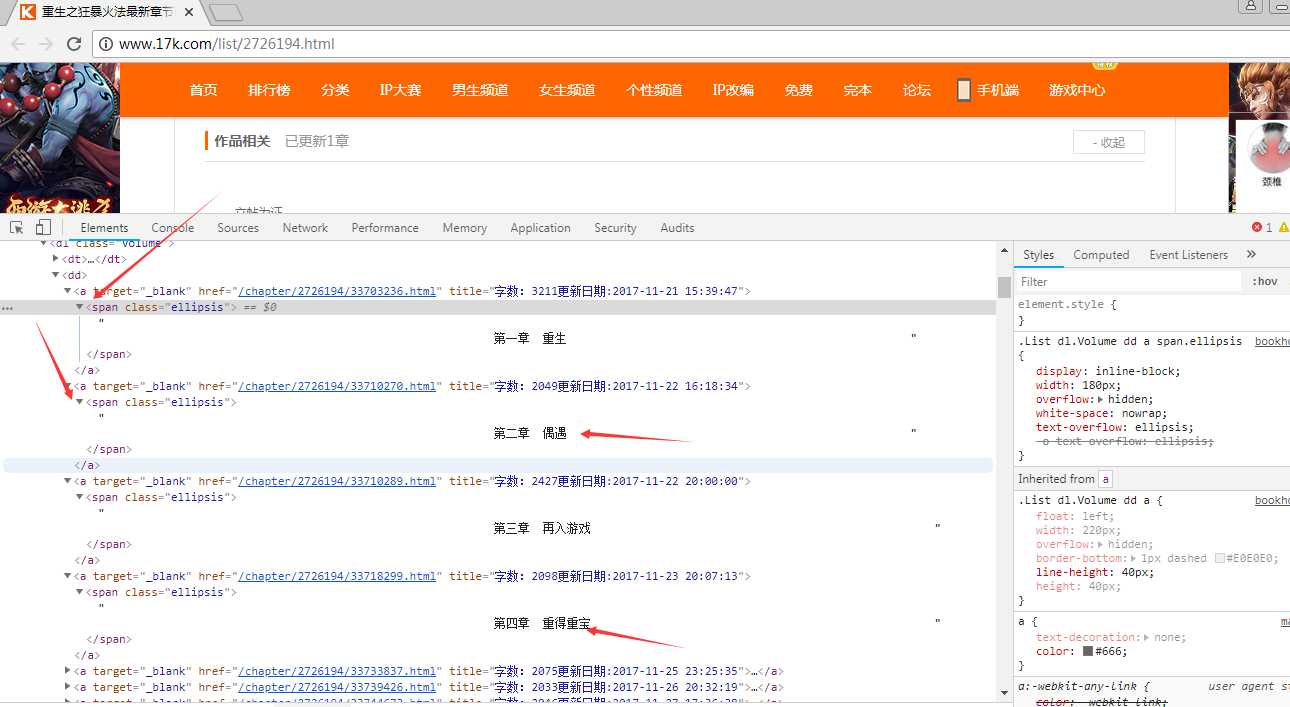
经过分析,我们可以通过简单的正则表达式,提取出每一章的章节名称(源代码第34行)
1 pat = r"(第.+章.+)</h1>"
2、接下来打开第一章通过源代码再次分析
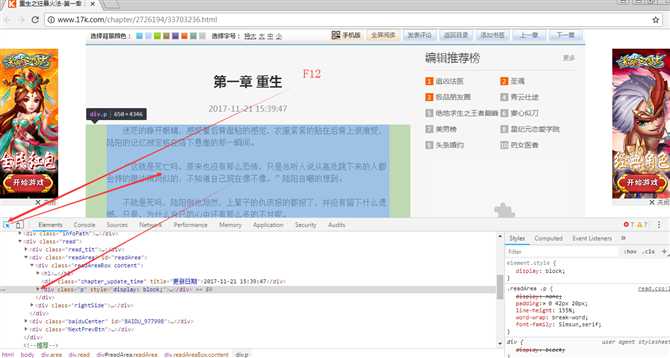
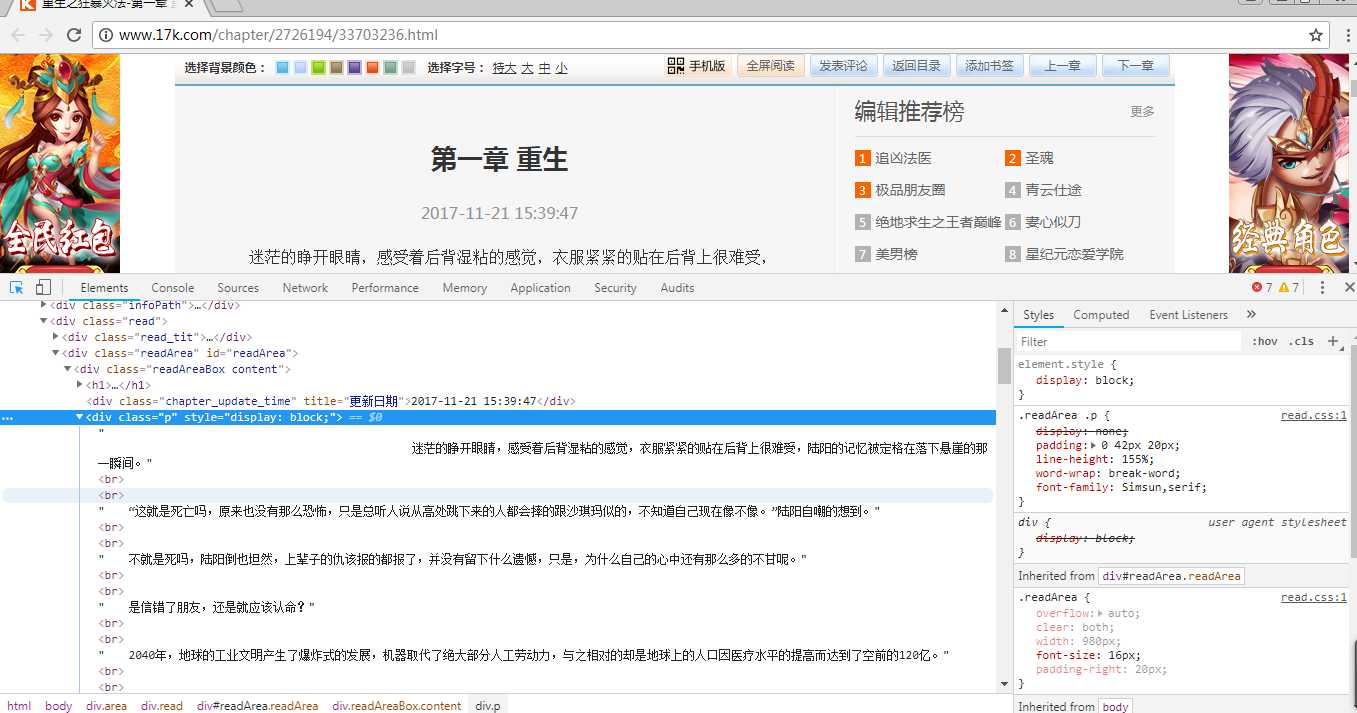
再次通过简单的分析,我们可以可以用简单的正则表达式提取出小说内容(源代码45~47行)
3、源代码如下
1 import requests 2 import re 3 4 5 class Novel(object): 6 url_list = [] 7 chapter_list = [] 8 chapter_title_list = [] 9 10 11 def __init__(self, url): 12 self.url = url 13 14 def obtain_url(self): 15 response = requests.get(self.url) 16 response.encoding = "utf-8" 17 pat = r"/chapter/2726194/(d+).html" 18 ls = [] 19 ls2 = [] 20 for i in re.findall(pat, response.text): 21 ls.append(i) 22 for i in range(1, 141): 23 ls2.append(ls[i]) 24 for i in ls2: 25 new_url = "http://www.17k.com/chapter/2726194/" + i + ".html" 26 Novel.url_list.append(new_url) 27 28 29 30 def obtan_title(self): 31 for i in self.url_list: 32 response = requests.get(i) 33 response.encoding = "utf-8" 34 pat = r"(第.+章.+)</h1>" 35 title = re.findall(pat,response.text) 36 self.chapter_title_list.append(str(title)) 37 38 39 40 def grab_url(self): 41 for i in self.url_list: 42 response = requests.get(i) 43 response.encoding = "utf-8" 44 lst = ‘‘ 45 pat = r"  (.+)<br /><br />" 46 new_text = str(re.findall(pat, response.text))[1:-1] 47 pat2 = r"[^<br /><br />  ]" 48 for j in re.findall(pat2, new_text): 49 if j == "。": 50 j = " " 51 lst = lst + j 52 self.chapter_list.append(lst) 53 54 55 def storage(self): 56 with open("F:\\重生.txt", "a") as f: 57 i = 0 58 while i < 140: 59 f.write(str(" " + self.chapter_title_list[i]) + " ") 60 f.write(self.chapter_list[i]) 61 i += 1 62 63 64 # 主方法 65 def grab(self): 66 # 获取网址 67 self.obtain_url() 68 69 #章节标题 70 self.obtan_title() 71 72 #章节内容 73 self.grab_url() 74 75 #存储 76 self.storage() 77 78 if __name__ == ‘__main__‘: 79 try: 80 spider = Novel("http://www.17k.com/list/2726194.html") 81 spider.grab() 82 except : 83 print("爬取出错~~")
运行后会在F盘生成一个 "重生.txt" 的文件
以上是关于java 怎么提取 txt小说里面的章节目录 并记录位置的主要内容,如果未能解决你的问题,请参考以下文章
word怎么批量将小说章节的全部标题(如第一章 开始,第二章 经过,第三章 结束)设为目录标题?