SQL中where和group by可以连用吗?having算是对检索条件的补充吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL中where和group by可以连用吗?having算是对检索条件的补充吗?相关的知识,希望对你有一定的参考价值。
前几天面试一家公司,有这么一道笔试题:查询出信息表中,name字段值的重复次数大于1的name字段值和该字段的重复次数?当时写的是:select name,count(name) from table where count(name)>1当时就感觉不对劲,回来一查,应该这么写:select name,count(name) from table group by name having count(name)>1.加上where字句反而出错。为什么??
首先要分清几个概念1.count() 在SqlServer中式属于聚合函数.聚合函数要求不能出现在where中2.where 可以和 group by连用 但效果和having是不同的 where要求必须在group by 前面..意思是先过滤再分组 而having是必须在group by后面连用 是分组后的过滤 所以过滤条件在什么位置是有很大区别的3.sql中 要求前面有聚合函数和其他字段的,group by中必须把不是聚合函数的字段 加进去 参考技术Awhere 可以和 group by连用 但效果和having是不同的 。
一、group by all语法解析:
- 如果使用 ALL 关键字,那么查询结果将包括由 GROUP BY 子句产生的所有组,即使某些组没有符合搜索条件的行。
没有 ALL 关键字,包含 GROUP BY 子句的 SELECT 语句将不显示没有符合条件的行的组。
select DepartmentID,DepartmentName as '部门名称',COUNT(*) as '个数' from BasicDepartment group by all DepartmentID,DepartmentName。
二、group by 和having 解释:前提必须了解sql语言中一种特殊的函数:聚合函数,
例如SUM, COUNT, MAX, AVG等。这些函数和其它函数的根本区别就是它们一般作用在多条记录上。having是分组(group by)后的筛选条件,分组后的数据组内再筛选。
三、having和where含义:
- having是分组(group by)后的筛选条件,分组后的数据组内再筛选;where则是在分组前筛选。
where子句中不能使用聚集函数,而having子句中可以,所以在集合函数中加上了HAVING来起到测试查询结果是否符合条件的作用。即having子句的适用场景是可以使用聚合函数。
having 子句限制的是组,而不是行。having 子句中的每一个元素也必须出现在select列表中。有些数据库例外,如oracle。参考技术B 因为where和group by不能连用,并且count(*)而不是count(name),这样写语句肯定报错啊 参考技术C 没有试过,你可以试试啊,编程这个东西就是要自己动手做,不懂的,你在做的过程中,会明白很多
SQL语句之order by group byhavingwhere
百度知道:
1.order by是 按字段进行排序.. 字段后面可跟desc降序..asc升序..默认为升序
2.group by是进行分组查询
3.having和where都属于条件过滤
区别在于一般having是和group by连用... group by...having... 表示先分组再条件过滤
而如果在group by前面有where,则是表示先条件过滤再分组
这个在实际中特殊的查询会影响到查询结果。
PS: 这几条关键字是有先后顺序的,where...group by...having...order by 都是可选,但是如果全部写出来,必须是这个顺序。
================================
言归正传!
一、Where
select * from tableName where id="2012";
就是查找tableName中,id=2012的记录。
这里的where对查询的结果进行了筛选。只有满足where子句中条件的记录才会被查询出来。
二、Group By
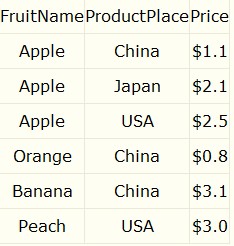
根据上表,需求:求出Apple在China,Japan,USA的平均价格,你怎么办?
可以这么做:select avg(price) from tablename where fruitname="apple";
Group By 一般是和一些聚合函数一起使用,比如上面我们用到的求平均的函数avg,还有求和sum,求个数count,求最大max,求最小min。
对于上表,求每种水果的最大的价格:select fruitname,productplace,max(price) from tablename group by fruitname
Group By 还有一个重要的合作对象,就是having。
三、Having
用Group By 进行分组后,如何对分组后的结果进行筛选呢?having可解决这个难题。
1.首先看一个例子:求平均价格在3.0以上的水果
如果使用:
select fruitname,avg(price) from tablename where avg(price)>=3.0 group by fruitname ;
这样能否达到我们的要求呢?
答案是否定的,因为where子句不能使用聚合函数。为了解决这个问题,我们来用下我们的杀手锏,他就是Having;
改写如下:select fruitname,avg(price) from tablename group by fruitname having avg(price)>=3.0;
2.我们继续看Having的另外一个匪夷所思
select fruitname,avg(price) from tablename group by fruitname having price<2.0;
这个查询的结果你们觉得会是什么呢?
没错,就是 orange 0.8 ;只有这一条记录
为什么呢?为什么Apple没有被查到呢,因为apple的有的价格超出了2.0.
另外运算符in也可以用在having 子句。
select fruitname,avg(price) from tablename group by fruitname having fruitname in ("orange","apple");
四、Order By
Order By是对查询的结果进行一个再排序的过程,一般放在查询语句的最后,可以是单列,也可以实现多列的排序。
分为升序asc和降序desc,默认的为升序。
Order By单列的排序比较简单,多列的也不麻烦。
select * from tablename group by friutname order by fruitname asc,price desc.
以上是关于SQL中where和group by可以连用吗?having算是对检索条件的补充吗?的主要内容,如果未能解决你的问题,请参考以下文章