windows10上Eclipse运行MapReduce wordcount程序遇到的坑
Posted 音译昌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了windows10上Eclipse运行MapReduce wordcount程序遇到的坑相关的知识,希望对你有一定的参考价值。
我的wordcount代码:
1 package com.walloce.wordcount; 2 3 import java.io.IOException; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.conf.Configured; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.util.Tool; 17 import org.apache.hadoop.util.ToolRunner; 18 19 import com.walloce.wordcount.MyMapReduce.myMap.myReduce; 20 21 public class MyMapReduce extends Configured implements Tool { 22 23 /** 24 * KEYIN LongWritable 传入的key类型(偏移量) 25 * VALUEIN Text 传入的value类型(文本) 26 * KEYOUT 传出的key类型 27 * VALUEOUT 传出的value类型 28 * @author Walloce 29 * 2018 30 */ 31 static class myMap extends Mapper<LongWritable, Text, Text, IntWritable> { 32 //输出结果的key 33 Text text = new Text(); 34 //输出结果的value 35 IntWritable mr_value = new IntWritable(1); 36 37 int line_count = 1; 38 39 @Override 40 protected void map(LongWritable key, Text value, Context context) 41 throws IOException, InterruptedException { 42 43 System.out.println("map阶段开始..."); 44 //将获取的文本类型转为字符串类型 45 String line = value.toString(); 46 47 System.out.println("第 "+ line_count +" 行的字符串的偏移量为:" + key.get()); 48 49 //将的到的一行字符串拆解为多个单词的字符串数组 50 String[] words = line.split(" "); 51 52 //遍历得到的所有word 53 for (String word : words) { 54 text.set(word); 55 context.write(text, mr_value); 56 } 57 line_count++; 58 } 59 60 /** 61 * Text, IntWritable, Text, IntWritable 62 * reduce时输入的key-value和输出的key-value. 63 * eg:(hello,2) 64 * @author Walloce 65 * 2018 66 */ 67 static class myReduce extends Reducer<Text, IntWritable, Text, IntWritable> { 68 69 private IntWritable result = new IntWritable(); 70 71 int reduce_time = 0; 72 73 @Override 74 protected void reduce(Text key, Iterable<IntWritable> values, Context context) 75 throws IOException, InterruptedException { 76 System.out.println("这是第"+ reduce_time +"次reduce"); 77 System.out.println("Reduce阶段开始...."); 78 79 int sum = 0; 80 for (IntWritable value : values) { 81 sum += value.get(); 82 } 83 result.set(sum); 84 context.write(key, result); 85 reduce_time++; 86 } 87 88 } 89 90 } 91 92 public int run(String[] args) throws Exception { 93 94 //hadoop的八股文 95 Configuration conf = this.getConf(); 96 Job job = Job.getInstance(conf, this.getClass().getSimpleName()); 97 //对job进行具体的配置 98 99 //当你本地运行,这个设置可以不写,不会报错 100 //当提价到集群上面运行的时候,这个设置不写,会报类找不到的异常 101 job.setJarByClass(MyMapReduce.class); 102 103 //写一个输入路径 104 Path input = new Path(args[0]); 105 FileInputFormat.addInputPath(job, input); 106 //写一个输出路径 107 Path output = new Path(args[1]); 108 FileOutputFormat.setOutputPath(job, output); 109 110 //执行前先判断输出路径是否存在,存在就删除 111 FileSystem fs = output.getFileSystem(conf); 112 if(fs.exists(output)){ 113 fs.delete(output,true); 114 } 115 116 //设置运行的map类的相关参数 117 job.setMapperClass(myMap.class); 118 job.setMapOutputKeyClass(Text.class); 119 job.setMapOutputValueClass(IntWritable.class); 120 //==============shuffle======================= 121 // job.setCombinerClass(MyCombiner.class); 122 123 124 //==============shuffle======================= 125 //设置运行的Reduce的相关参数 126 job.setReducerClass(myReduce.class); 127 job.setOutputKeyClass(Text.class); 128 job.setOutputValueClass(IntWritable.class); 129 130 boolean isSuccess = job.waitForCompletion(true); 131 132 133 return isSuccess?0:1; 134 } 135 136 public static void main(String[] args) { 137 // TODO Auto-generated method stub 138 Configuration conf = new Configuration(); 139 args = new String[]{ 140 "hdfs://bigdata-study-104:8020/testdata/word.txt", 141 "hdfs://bigdata-study-104:8020/testresult/output/" 142 }; 143 144 try { 145 ToolRunner.run(conf, new MyMapReduce(), args); 146 } catch (Exception e) { 147 // TODO Auto-generated catch block 148 e.printStackTrace(); 149 } 150 } 151 152 }
异常信息:
1 18/03/22 20:41:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2 18/03/22 20:41:25 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 3 18/03/22 20:41:25 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 4 18/03/22 20:41:25 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String). 5 18/03/22 20:41:25 INFO input.FileInputFormat: Total input paths to process : 1 6 18/03/22 20:41:26 INFO mapreduce.JobSubmitter: number of splits:1 7 18/03/22 20:41:26 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1064879045_0001 8 18/03/22 20:41:26 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/staging/Walloce1064879045/.staging/job_local1064879045_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 9 18/03/22 20:41:26 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/staging/Walloce1064879045/.staging/job_local1064879045_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 10 18/03/22 20:41:26 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/staging/Walloce1064879045/.staging/job_local1064879045_0001 11 Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z 12 at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method) 13 at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:571) 14 at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977) 15 at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:173) 16 at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:160) 17 at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:94) 18 at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285) 19 at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344) 20 at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150) 21 at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131) 22 at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115) 23 at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131) 24 at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163) 25 at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731) 26 at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:432) 27 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) 28 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) 29 at java.security.AccessController.doPrivileged(Native Method) 30 at javax.security.auth.Subject.doAs(Unknown Source) 31 at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614) 32 at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) 33 at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) 34 at com.walloce.wordcount.MyMapReduce.run(MyMapReduce.java:130) 35 at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) 36 at com.walloce.wordcount.MyMapReduce.main(MyMapReduce.java:145)
修改代码:将570行注释掉,直接return true;

再运行还是报错!!!
1 18/03/22 20:53:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2 18/03/22 20:53:42 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 3 18/03/22 20:53:42 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 4 18/03/22 20:53:43 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String). 5 18/03/22 20:53:43 INFO input.FileInputFormat: Total input paths to process : 1 6 18/03/22 20:53:43 INFO mapreduce.JobSubmitter: number of splits:1 7 18/03/22 20:53:43 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local105563724_0001 8 18/03/22 20:53:43 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 9 18/03/22 20:53:43 INFO mapreduce.Job: Running job: job_local105563724_0001 10 18/03/22 20:53:43 INFO mapred.LocalJobRunner: OutputCommitter set in config null 11 18/03/22 20:53:43 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 12 18/03/22 20:53:43 INFO mapred.LocalJobRunner: Waiting for map tasks 13 18/03/22 20:53:43 INFO mapred.LocalJobRunner: Starting task: attempt_local105563724_0001_m_000000_0 14 18/03/22 20:53:43 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 15 18/03/22 20:53:43 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4a86a3cd 16 18/03/22 20:53:43 INFO mapred.MapTask: Processing split: hdfs://bigdata-study-104:8020/testdata/word.txt:0+210 17 18/03/22 20:53:43 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 18 18/03/22 20:53:43 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 19 18/03/22 20:53:43 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 20 18/03/22 20:53:43 INFO mapred.MapTask: soft limit at 83886080 21 18/03/22 20:53:43 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 22 18/03/22 20:53:43 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 23 map阶段开始... 24 第 1 行的字符串的偏移量为:0 25 map阶段开始... 26 第 2 行的字符串的偏移量为:46 27 map阶段开始... 28 第 3 行的字符串的偏移量为:86 29 map阶段开始... 30 第 4 行的字符串的偏移量为:120 31 map阶段开始... 32 第 5 行的字符串的偏移量为:149 33 map阶段开始... 34 第 6 行的字符串的偏移量为:172 35 map阶段开始... 36 第 7 行的字符串的偏移量为:190 37 map阶段开始... 38 第 8 行的字符串的偏移量为:204 39 18/03/22 20:53:44 INFO mapred.LocalJobRunner: 40 18/03/22 20:53:44 INFO mapred.MapTask: Starting flush of map output 41 18/03/22 20:53:44 INFO mapred.MapTask: Spilling map output 42 18/03/22 20:53:44 INFO mapred.MapTask: bufstart = 0; bufend = 348; bufvoid = 104857600 43 18/03/22 20:53:44 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214256(104857024); length = 141/6553600 44 18/03/22 20:53:44 INFO mapred.MapTask: Finished spill 0 45 18/03/22 20:53:44 INFO mapred.Task: Task:attempt_local105563724_0001_m_000000_0 is done. And is in the process of committing 46 18/03/22 20:53:44 INFO mapred.LocalJobRunner: map 47 18/03/22 20:53:44 INFO mapred.Task: Task \'attempt_local105563724_0001_m_000000_0\' done. 48 18/03/22 20:53:44 INFO mapred.LocalJobRunner: Finishing task: attempt_local105563724_0001_m_000000_0 49 18/03/22 20:53:44 INFO mapred.LocalJobRunner: map task executor complete. 50 18/03/22 20:53:44 INFO mapred.LocalJobRunner: Waiting for reduce tasks 51 18/03/22 20:53:44 INFO mapred.LocalJobRunner: Starting task: attempt_local105563724_0001_r_000000_0 52 18/03/22 20:53:44 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 53 18/03/22 20:53:44 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@66a2f2c4 54 18/03/22 20:53:44 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@7c3f147f 55 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=1323407744, maxSingleShuffleLimit=330851936, mergeThreshold=873449152, iosortFactor=10, memToMemMergeOutputsThreshold=10 56 18/03/22 20:53:44 INFO reduce.EventFetcher: attempt_local105563724_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 57 18/03/22 20:53:44 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local105563724_0001_m_000000_0 decomp: 422 len: 426 to MEMORY 58 18/03/22 20:53:44 INFO reduce.InMemoryMapOutput: Read 422 bytes from map-output for attempt_local105563724_0001_m_000000_0 59 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 422, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->422 60 18/03/22 20:53:44 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 61 18/03/22 20:53:44 INFO mapred.LocalJobRunner: 1 / 1 copied. 62 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 63 18/03/22 20:53:44 INFO mapred.Merger: Merging 1 sorted segments 64 18/03/22 20:53:44 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 413 bytes 65 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: Merged 1 segments, 422 bytes to disk to satisfy reduce memory limit 66 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: Merging 1 files, 426 bytes from disk 67 18/03/22 20:53:44 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 68 18/03/22 20:53:44 INFO mapred.Merger: Merging 1 sorted segments 69 18/03/22 20:53:44 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 413 bytes 70 18/03/22 20:53:44 INFO mapred.LocalJobRunner: 1 / 1 copied. 71 18/03/22 20:53:44 INFO mapred.LocalJobRunner: reduce task executor complete. 72 18/03/22 20:53:44 WARN mapred.LocalJobRunner: job_local105563724_0001 73 java.lang.Exception: java.lang.NoSuchMethodError: org.apache.hadoop.fs.FSOutputSummer.<init>(Ljava/util/zip/Checksum;II)V 74 at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) 75 at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:529) 76 Caused by: java.lang.NoSuchMethodError: org.apache.hadoop.fs.FSOutputSummer.<init>(Ljava/util/zip/Checksum;II)V 77 at org.apache.hadoop.hdfs.DFSOutputStream.<init>(DFSOutputStream.java:1563) 78 at org.apache.hadoop.hdfs.DFSOutputStream.<init>(DFSOutputStream.java:1594) 79 at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1626) 80 at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1488) 81 at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1413) 82 at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:387) 83 at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:383) 84 at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) 85 at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:383) 86 at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:327) 87 at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:908) 88 at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:889) 89 at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:786) 90 at org.apache.hadoop.mapreduce.lib.output.TextOutputFormat.getRecordWriter(TextOutputFormat.java:132) 91 at org.apache.hadoop.mapred.ReduceTask$NewTrackingRecordWriter.<init>(ReduceTask.java:540) 92 at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:614) 93 at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:389) 94 at org.apache.hadoop.mapred.LocalJobRunner$Job$ReduceTaskRunnable.run(LocalJobRunner.java:319) 95 at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) 96 at java.util.concurrent.FutureTask.run(Unknown Source) 97 at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) 98 at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) 99 at java.lang.Thread.run(Unknown Source) 100 18/03/22 20:53:44 INFO mapreduce.Job: Job job_local105563724_0001 running in uber mode : false 101 18/03/22 20:53:44 INFO mapreduce.Job: map 100% reduce 0% 102 18/03/22 20:53:44 INFO mapreduce.Job: Job job_local105563724_0001 failed with state FAILED due to: NA 103 18/03/22 20:53:44 INFO mapreduce.Job: Counters: 38 104 File System Counters 105 FILE: Number of bytes read=175 106 FILE: Number of bytes written=262184 107 FILE: Number of read operations=0 108 FILE: Number of large read operations=0 109 FILE: Number of write operations=0 110 HDFS: Number of bytes read=210 111 HDFS: Number of bytes written=0 112 HDFS: Number of read operations=6 113 HDFS: Number of large read operations=0 114 HDFS: Number of write operations=2 115 Map-Reduce Framework 116 Map input records=8 117 Map output records=36 118 Map output bytes=348 119 Map output materialized bytes=426 120 Input split bytes=112 121 Combine input records=0 122 Combine output records=0 123 Reduce input groups=0 124 Reduce shuffle bytes=426 125 Reduce input records=0 126 Reduce output records=0 127 Spilled Records=36 128 Shuffled Maps =1 129 Failed Shuffles=0 130 Merged Map outputs=1 131 GC time elapsed (ms)=0 132 CPU time spent (ms)=0 133 Physical memory (bytes) snapshot=0 134 Virtual memory (bytes) snapshot=0 135 Total committed heap usage (bytes)=232783872 136 Shuffle Errors 137 BAD_ID=0 138 CONNECTION=0 139 IO_ERROR=0 140 WRONG_LENGTH=0 141 WRONG_MAP=0 142 WRONG_REDUCE=0 143 File Input Format Counters 144 Bytes Read=210 145 File Output Format Counters 146 Bytes Written=0
主要异常信息:
1 java.lang.Exception: java.lang.NoSuchMethodError: org.apache.hadoop.fs.FSOutputSummer.<init>(Ljava/util/zip/Checksum;II)V
好不容易解决一个,又来一个....要崩溃了,继续百度!
问题大致的原因是因为jar包冲突了,所以我buildpath看下导入的jar包有哪些,结果发现问题了。。。。。
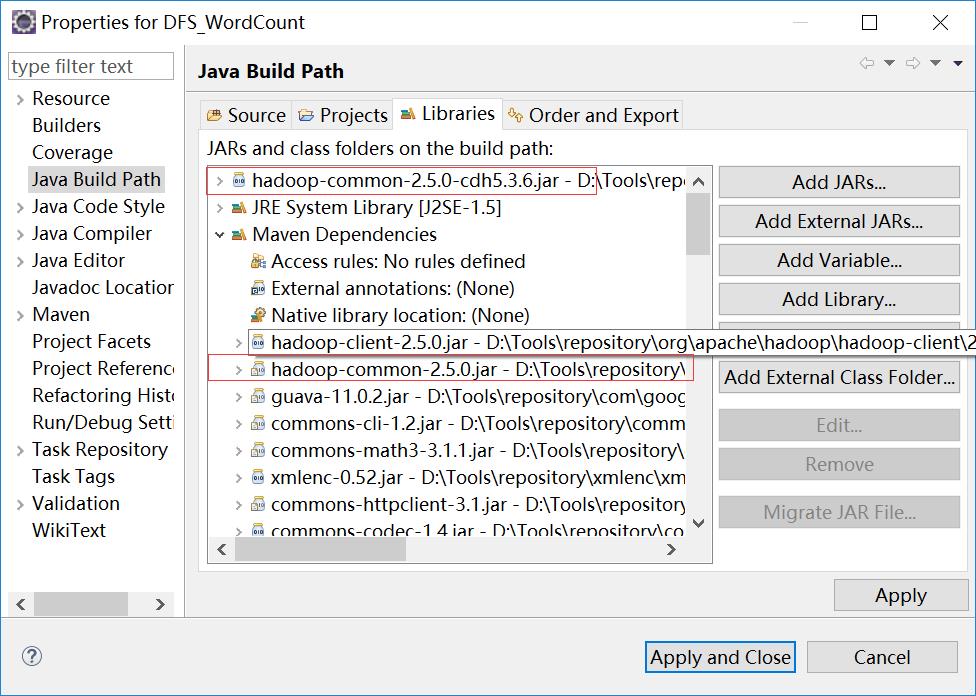
同时存在cdh版本的和apache版本的hadoop-common-2.5.0jar包,删掉cdh版本的后运行结果:
1 18/03/22 20:57:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2 18/03/22 20:57:26 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 3 18/03/22 20:57:26 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 4 18/03/22 20:57:27 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String). 5 18/03/22 20:57:27 INFO input.FileInputFormat: Total input paths to process : 1 6 18/03/22 20:57:27 INFO mapreduce.JobSubmitter: number of splits:1 7 18/03/22 20:57:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1889225814_0001 8 18/03/22 20:57:27 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/staging/Walloce1889225814/.staging/job_local1889225814_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 9 18/03/22 20:57:27 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/staging/Walloce1889225814/.staging/job_local1889225814_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 10 18/03/22 20:57:27 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/local/localRunner/Walloce/job_local1889225814_0001/job_local1889225814_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 11 18/03/22 20:57:27 WARN conf.Configuration: file:/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/temp/mapred/local/localRunner/Walloce/job_local1889225814_0001/job_local1889225814_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 12 18/03/22 20:57:27 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 13 18/03/22 20:57:27 INFO mapreduce.Job: Running job: job_local1889225814_0001 14 18/03/22 20:57:27 INFO mapred.LocalJobRunner: OutputCommitter set in config null 15 18/03/22 20:57:27 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 16 18/03/22 20:57:28 INFO mapred.LocalJobRunner: Waiting for map tasks 17 18/03/22 20:57:28 INFO mapred.LocalJobRunner: Starting task: attempt_local1889225814_0001_m_000000_0 18 18/03/22 20:57:28 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 19 18/03/22 20:57:28 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@73a61b48 20 18/03/22 20:57:28 INFO mapred.MapTask: Processing split: hdfs://bigdata-study-104:8020/testdata/word.txt:0+210 21 18/03/22 20:57:28 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 22 18/03/22 20:57:28 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 23 18/03/22 20:57:28 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 24 18/03/22 20:57:28 INFO mapred.MapTask: soft limit at 83886080 25 18/03/22 20:57:28 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 26 18/03/22 20:57:28 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 27 map阶段开始... 28 第 1 行的字符串的偏移量为:0 29 map阶段开始... 30 第 2 行的字符串的偏移量为:46 31 map阶段开始... 32 第 3 行的字符串的偏移量为:86 33 map阶段开始... 34 第 4 行的字符串的偏移量为:120 35 map阶段开始... 36 第 5 行的字符串的偏移量为:149 37 map阶段开始... 38 第 6 行的字符串的偏移量为:172 39 map阶段开始... 40 第 7 行的字符串的偏移量为:190 41 map阶段开始... 42 第 8 行的字符串的偏移量为:204 43 18/03/22 20:57:28 INFO mapred.LocalJobRunner: 44 18/03/22 20:57:28 INFO mapred.MapTask: Starting flush of map output 45 18/03/22 20:57:28 INFO mapred.MapTask: Spilling map output 46 18/03/22 20:57:28 INFO mapred.MapTask: bufstart = 0; bufend = 348; bufvoid = 104857600 47 18/03/22 20:57:28 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214256(104857024); length = 141/6553600 48 18/03/22 20:57:28 INFO mapred.MapTask: Finished spill 0 49 18/03/22 20:57:28 INFO mapred.Task: Task:attempt_local1889225814_0001_m_000000_0 is done. And is in the process of committing 50 18/03/22 20:57:28 INFO mapred.LocalJobRunner: map 51 18/03/22 20:57:28 INFO mapred.Task: Task \'attempt_local1889225814_0001_m_000000_0\' done. 52 18/03/22 20:57:28 INFO mapred.LocalJobRunner: Finishing task: attempt_local1889225814_0001_m_000000_0 53 18/03/22 20:57:28 INFO mapred.LocalJobRunner: map task executor complete. 54 18/03/22 20:57:28 INFO mapred.LocalJobRunner: Waiting for reduce tasks 55 18/03/22 20:57:28 INFO mapred.LocalJobRunner: Starting task: attempt_local1889225814_0001_r_000000_0 56 18/03/22 20:57:28 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux. 57 18/03/22 20:57:28 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@504037fc 58 18/03/22 20:57:28 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1de1d428 59 18/03/22 20:57:28 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=1323407744, maxSingleShuffleLimit=330851936, mergeThreshold=873449152, ioSortFactor=10, memToMemMergeOutputsThreshold=10 60 18/03/22 20:57:28 INFO reduce.EventFetcher: attempt_local1889225814_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 61 18/03/22 20:57:28 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1889225814_0001_m_000000_0 decomp: 422 len: 426 to MEMORY 62 18/03/22 20:57:28 INFO reduce.InMemoryMapOutput: Read 422 bytes from map-output for attempt_local1889225814_0001_m_000000_0 63 18/03/22 20:57:28 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 422, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->422 64 18/03/22 20:57:28 INFO redu以上是关于windows10上Eclipse运行MapReduce wordcount程序遇到的坑的主要内容,如果未能解决你的问题,请参考以下文章