Hibernate概念初探
Posted 小杜同学的嘚啵嘚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate概念初探相关的知识,希望对你有一定的参考价值。
概述
Hibernate是一个开源代码的对象关系映射(ORM)框架,是基于Java的持久化中间件,它对JDBC进行轻量级的对象封装。
它不仅提供了从Java类到数据表之间的映射,也提供了查询和事务机制。
相对于使用JDBC和SQL操作数据库,Hibernate大大减少了操作数据库的工作量。
作用
作为持久化的中间件,Hibernate采用ORM映射机制,实现Java对象和关系数据库之间的映射,把SQL语句传给数据库,并且把数据库返回的结果封装成对象。
内部封装了JDBC访问数据库的操作,向上层应用提供了面向对象的数据库访问API。从而使程序员使用面向对象的思维来操作数据库。
如图示:

两个重要概念
1)数据持久化
数据持久化就是把内存中的数据(对象)永久保存到数据库中,实际上数据“持久化”包括了与数据库相关的各种操作。比如,保存、更新、删除、查询和加载。
说一下“加载”:
根据特定对象OID,把一个对象从数据库中加载到内存中。为了在系统中能够找到所需的对象,需要为每一个对象分配一个唯一的标识号。关系型数据库中称之为主键,而在对象术语中则称为对象标识(Object identifier-OID)。
数据持久化负责封装数据的访问操作,为业务逻辑提供面向对象的数据操作接口。
在Hibernate框架中,提供了访问数据库的方法,在使用时候直接调用即可。
2)ORM
全称Object/Relation Mapping,即对象/关系映射,是一种数据持久化技术,其基本思想是把对象模型(如JavaBean对象)与关系数据库的表建立映射关系。
在JDBC中,我们要做的是使用SQL语句操作数据库中的表;
而在Hibernate中我们不再需要直接操作数据库,而是转化为了对JavaBean对象的操作,就可以实现数据的存储、查询、更改和删除等操作。
| ORM中对象与数据库表的映射关系 | |
| 面向对象概念 | 面向关系表(结构)概念 |
| 类 | 数据表 |
| 对象 | 数据表中的行(记录) |
| 属性 | 数据表中的列(字段) |
Hibernate框架的结构体系
基于Hibernate的应用程序是通过配置文件(hibernate.properties或hibernate.cfg.xml)和映射文件(*.hbm.xml)把持久化对象(Persistence Object,PO)映射到数据库的数据表,然后通过操作持久化对象(PO),对数据库中的数据进行增删查改。
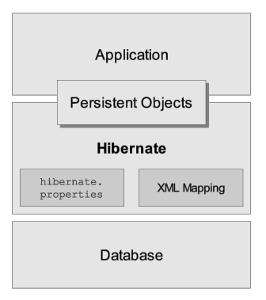
由图中可以看出,使用Hibernate的开发人员的主要任务就是编写Hibernate配置文件(对应图中hibernate.properties)、设计PO类及对象-关系映射文件(对应图中XML Mapping),然后利用HibernateAPI来操作数据库。
Hibernate的核心组件
Hibernate全面解决方案体系架构:
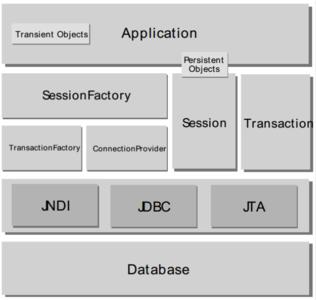
Hibernate组件层次架构:

这些组件按被使用的次序分为5层,上层可对下层进行调用和使用。
1)Hibernate配置文件:主要用来配置数据库连接参数。如数据库驱动程序、URL、用户名和密码等。
它有两种格式:hibernate.properties和hibernate.cfg.xml。两者配置内容基本相同,通常使用后者。
2)持久化对象(PO):可以是普通的JavaBean。
3)映射文件:用来把PO与数据库中的数据表映射起来,是Hibernate的核心文件。
4)Configuration类:用来读取Hibernate配置文件和映射文件,并创建SessionFactory对象。
5)SessionFactory接口:产生Session实例的工厂,是Hibernate的容器。(该接口是线程安全的,可以被多个线程调用。因为构造SessionFactory很消耗资源,所以多数情况下应用中只初始化一个SessionFactory对象,为不同的线程提供Session。当客户端发送一个请求时,从SessionFactory中获取Session对象,由Session对象处理客户请求)
6)Session接口:用来操作PO,它有get()、save()、update()、delete()等方法,用来对PO进行加载、保存、更新及删除等操作。它是Hibernate的核心接口。(持久化对象 的生命周期、事务管理,以及持久化对象的查询、更新和删除等操作都是通过Session对象完成)
7)Transaction接口:用来管理Hibernate事务,主要的方法有commit()和rollback(),可从Session的beginTransaction()方法生成。
8)Query接口:对PO进行查询操作。它可以从Session的createQuery()方法生成。
Hibernate运行过程

1)应用程序先调用Configuration类,该类读取配置文件和映射文件,根据这些信息生成SessionFactory对象。
//创建Configuration对象:加载Hibernate的基本配置信息和对象关系映射 Configuration configuration=new Configuration.configure(); //创建一个ServiceRegistry对象:Hibernate 4.x新添加的对象,Hibernate的任何配置和服务都需要在该对象中注册后才能生效 ServiceRegistry serviceRegistry=new StandardServiceRegistryBuilder().applySettings(configuration.getProperties()).build();
2)每次执行数据库事务时,先从SessionFactory中获取一个Session实例。
//创建SessionFactory对象 SessionFactory sessionFactory=configuration.buildSessionFactory(serviceRegistry);
3)由Session对象启动事务,并生成Transaction对象。
//创建一个Session Session session=sessionFactory.openSession(); //开启事务 Transaction transaction=session.beginTransaction();
4)通过Session对象的方法对PO进行加载、保存、更新和删除等操作。在查询的情况下,通过Session对象生成Query对象,执行查询操作。
//执行保存操作——通过实体对象实现对数据库表的操作,是数据库的核心 //例如有一个实体类Book Book book=new Book(); book.setBookId("1"); book.setBookName("java编程思想"); session.save(book);//通过对象实现向数据库中的数据表存放信息
5)若没有异常,Transaction对象将提交操作结果到数据库中,否则事务将回滚。
//提交事务 transaction.commit();
6)当事务操作完成后,关闭Session实例对象。
//关闭Session对象 session.close();
设计PO类及对象-关系映射文件(*.hbm.xml)
1)建立持久化对象模型(即实体类,包括相应的setter/getter方法),自不必多说;
2)建立对象-关系映射文件(*.hbm.xml)。
这里的*要与对应的持久化类类名相同,即“持久化类类名.hbm.xml”。且映射文件要求与持久化实体类在同一个包内。
该文件给出了“实体类”与“数据库表”,以及“类属性”与“表字段”之间的映射关系。
以实体类Person.java为例。
右击Person.java选项,在弹出的快捷菜单中选择New——Other——Hibernate——Hibernate XML Mapping file(hbm.xml)命令。在弹出的对话框中单击Next按钮,选择类Person,单击Next按钮两次,再单击Finish按钮,即可生成映射文件。
<hibernate-mapping> <!--实体类Person与数据库表PERSON之间的对应关系--> <class name="com.entity.Person" table="PERSON"> <!--主键配置定义--> <id name="id" type="java.lang.Tnteger"> <column name="ID"/> <!--设置主键生成的方式,该元素的作用是指定主键的生成器,通过class属性指定生成器对应的类,这里使用的Hibernate提供的常用内置生成器--> <generator class="native"> </id> <!--配置一般属性与字段配置--> <property name="name" type="java.lang.String"> <column name="NAME"/> </property> <property name="sex" type="java.lang.String"> <column name="SEX"/> </property> <property name="age" type="int"> <column name="AGE"/> </property> </class> </hibernate-mapping>
建立数据库配置文件hibernate.cfg.xml。
该文件建立在src目录下。
其配置信息:采用mysql数据库为例,数据库的基本配置有:驱动类、数据库url、数据库操作用户名、密码、所采用数据库的方言(必须指定,表示连接的是哪种数据库)。
同时利用映射文件信息,自动创建数据库表PERSON。
具体步骤:
右击src选项,在弹出的快捷菜单中选择New——Other——Hibernate——Hibernate Configuration File(cfg.xml)命令。在弹出的对话框中单击Next按钮两次,再单击Finish按钮,即可生成配置文件。
<hibernate-configuration> <session-factory> <!--数据库基本配置--> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql:///javaee数据库名</property> <property name="connection.username">root</property> <property name="connection.password">123456</property> <property name="dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property> <!--非数据库基本配置--> <!--表示可由类和映射文件自动生成数据库表--> <property name="hbm2ddl.auto">update</property> <!--显示运行中执行的sql语句,一般调试时设置为true,便于观察代码执行的SQL语句的细节--> <property name="show_sql">true</property> <!--在控制台按格式显示SQL语句--> <property name="format_sql">true</property> <!--配置实体类的映射文件,指定路径名,可以配置多组--> <mapping resource="com/entity/Person.hbm.xml"/> </session-factory> </hibernate-configuration>
Hibernate 核心组件详解
1)Hibernate配置文件。
主要用来设置访问数据库所需要的参数,最基本的有3类:
1.JDBC连接参数的基本配置。
2.Hibernate连接池的参数配置(可以不配置,但在实际应用项目中必须配置,以提高系统性能)
3.注册ORM映射文件的配置参数。
在Hibernate中使用C3P0数据源来支持连接池。
2)Hibernate的PO对象
原则:
1.无参构造方法(必须);
2.提供一个标识属性(OID):通常映射为数据库表的主键字段;
3.每个属性都有getter/setter方法
Hibernate的PO的状态及转换条件
与普通的JavaBean对象不同的是PO对象与Session(缓存)相关联。PO在Hibernate中存在下列4种状态。
1.瞬时(Transient):数据库中没有数据与之对应,超过作用域会被JVM垃圾回收器回收,一般是new创建,且与session没有关联的对象,OID为0或null。
2.持久(Persistent):数据库中有数据与之对应,当前与session有关联,并且相关联的session没有关闭,事务没有提交。
3.删除(Removed):在数据库中没有与OID对应的记录,不再处于Session缓存中,一般情况下,应用程序不该再使用被删除的对象。
4.脱管(Detached):数据库中有数据与之对应,但当前没有session与之关联。

3)Hibernate的映射文件
Hibernate的映射文件把一个PO类和数据库表联系起来。通常一个PO类对应一个映射文件,其命名规范为:PO类名称.hbm.xml,且与PO类在同一包下。
主键使用<id>标签来配置。Hibernate使用OID(对象标识符)来标识对象的唯一性。在运行时,Hibernate根据OID来维持Java对象和数据库中记录的对应关系。
HQL语言与Query接口应用
1)Hibernate提供了一种功能强大的查询语言——HQL(Hibernate Query Language),直接使用实体类名及属性实现查询。
与SQL语言类似。只不过SQL是针对表中的字段进行查询,而HQL是一种完全面向对象的语言,能够直接查询实体类及属性。
语法与SQL语言类似。是一种“select...from...”的结构。其中,from后面跟的是实体类名,而不是表名。select后面跟的可以是实体对象,也可以是实体对象的属性或者其他的值。
String hql="select person.name from Person as persons"; //查询所有的Person //创建Query对象 Query query =session.createQuery(hql); //执行查询,返回List List list=query.list();
2)设置分页
分页是查询中最常用的功能,当查询结果很多时,通常要将查询结果分页显示。
在Hibernate中,查询结果的分页主要是通过以下方法来实现的。
setFirstResult();//设置起始位置(索引位置是从0开始)
setMaxResults();//设置返回最大记录数
Hibernate的QBC查询
当查询数据时,通常都需要设置查询条件,例如在SQL语句或HQL语句中,查询条件常常放在where子句中,当查询参数较多时,使用SQL语句或HQL语句过长、复杂、极易出错。
为此,Hibernate把查询条件封装为一个Criteria对象,基于Criteria对象实现查询——Query By Criteria查询(QBC查询)//创建查询条件的查询对象 Crieria cr=session.createCriteria(student.class); //向查询对象中添加查询条件:性别sex为“男”,可以连续添加多个查询条件 cr.add(Restrictions.eq("sex","男")); //实现查询,获取查询对象集合studentList List<student> studentList=cr.list();
Hibernate的Native SQL查询
Hibernate提供的Native SQL,可以使用标准的SQL语句实现对数据库的操作。
String sql="select * from t_studnet"; //创建SQLQuery实例 SQLQuery sqlQuery=session.createSQLQuery(sql); //还需要传入查询的实体类 sqlQuery.addEntity(student.calss); //实现查询,获得查询结果集合 List<Student> list=sqlQuery.list();
Hibernate实体关联关系映射
在一个应用系统中通常有多个实体,并且实体之间存在互相关联。
实体关系要从方向性和数量性两个方面来考虑。
实体间关系从方向上可分为单向关联和双向关联。单向关联只需在一方进行映射配置,而双向关联则需要在关联的双方进行映射配置。
实体间的关系从引用的数量上分为:一对一、一对多、多对一、多对多。
实体之间的关联关系的实现方式有:基于外键、基于主键和基于关联表的实现。
实体之间的各种关联关系分类:

1)一对一映射
例子:一个人拥有一个身份证。
一对一关系在Hibernate中的实现有两种方式,分别是主键关联和外键关联,并且既可以是单向关联,也可以是双向关联。
1.共享主键方式双向关联
就是两个相关联的数据表,使用相同的主键实现映射。
在实体关系中,由于双向关联,每个实体类都有对另一方的对象引用。
在数据表关系中,两个表的主键名称一样(主键名称也可以不同),但对应记录的两个主键取值是一样的(由一方产生主键值,然后提供给另一方的主键值)
由于两个表要共享主键,那么在映射时,如何创建主键,由谁来创建?在Hibernate的映射文件中使用主键的foreign生成机制。
(以Person(人)和IdCard(身份证)为例)
在本例中,主键由Person产生,然后,利用foreign生成机制,赋值给IdCard的主键,从而保证两个主键具有相同的值。
package com.entity.one2one; public class Person{ private int id; private String name; private IdCard idCard;//与另一方关联,需要使用对方的对象属性 }
package com.entity.one2one; public class IdCard{ private int id; private String cardNo; private Person person;//与另一方关联,需要使用对方的对象属性 }
Person映射文件:
<hibernate-mapping> <!--lazy="true"是配置延迟加载--> <class name="com.entity.one2one.Person" lazy="true"> <id name="id" type="int"> <column name="ID"/> <generator class="native"/> </id> <property name="name"/> <!--双向关联,需要在两个配置文件中都配置one-to-one--> <!--通过cascade="all"配置了级联操作,当“人”更新时,自动对“身份证”信息进行更新--> <one-to-one name="idCard" class="com.entity.one2one.IdCard" fetch="join" cascade="all"> </one-to-one> </class> </hibernate-mapping>
说明,
代码中配置了延迟加载,若其值配置为false,则表示立即加载。
立即加载:表示Hibernate在从数据库中取得数据,组装成一个对象后,会立即再从数据库取得所关联的对象。
延迟加载:表示Hibernate在从数据库中取得数据,组装成一个对象后,不会立即再从数据库取得所关联的对象,而是等到需要时再从数据库取得关联对象。
cascade属性表明操作是否从父对象级联到被关联的对象(称为“级联”)。
fetch属性的值是join或select,默认值是select。
当fetch="join"时,表示连接抓取(Join fetching):Hibernate通过在SELECT语句使用OUTER JOIN(外连接)来获取对象的关联实例或者关联集合。
当fetch="select"时,表示查询抓取(Select fetching):需要另外发送一条SELECT语句抓取当前对象的关联实体或集合。
当cascade="all",表示增加、删除及修改Student对象时,都会级联增加、删除和修改Card对象。
Id_Card映射文件:
<class name="com.entity.one2one.Id_Card" table="IDCARD" lazy="true"> <id name="id" type="int"> <column name="ID"/> <!--主键id使用外键(foreign)生成机制,引用代号为person对象的主键作为IdCard表的主键和外键--> <generator class="foreign"> <param name="property">person</param> </generator> </id> <property name="cardNo"/> <!--person在该标签中进行了定义--> <!--constrained="true"表示IdCard引用了person的主键作为外键--> <one-to-one name="person" class="com.entity.one2one.Person" constrained="true"> </one-to-one> </class>
2.基于外键实现一对一双向关联
要点:两个数据表各自有不同的主键,但其中一个数据表包含有一个新字段——对另一个数据表主键的引用(外键)。
这种一对一的关系其实就是多对一关系的一种特殊情况(外键取值是唯一的)
(本部分未给出代码和上面实例一致)
Id_Card映射文件:
对于Id_Card的映射,实际上要添加外键字段,该外键就是Person的主键。在配置映射时,将实体类Id_Card中的person,对应于实体类Person的主键即可。
<many-to-one name="person" class="com.entity.one2one.Person" column="person_id" unique="true"> </many-to-one>
2)多对一单向外键映射
其中,“多方”是主动方,“一方”是被动方,而“多方”的外键是由“一方”产生并提供给“多方”的。
(以Employee(雇员)和Department(部门)为例)
两个实体类之间关系:在“多方(employee)”中必须含有对“一方(Department)”的对象的引用,才能实现多对一的单向关联。
两个数据表之间的关系:采用外键关联,且外键字段为depart_id。
实现的关键:
在“多方(Employee)”含有对“一方(Department)”的对象引用。
在“多方(Employee)”的映射文件内,使用<many-to-one>标记进行关联关系映射并制定外键。
<many-to-one name="depart" class="com.entity.Department" fetch="join"> <column name="depart_id"/> </many-to-one>
3)一对多单向外键映射
其中,“一方”是主动方,“多方”是被动方,而“多方”的外键是由“一方”产生并提供给“多方”的。
(以Employee(雇员)和Department(部门)为例)(一个部门里有多个雇员)
实现关键:
在“一方(Department)”有对“多方(Employee)”集合类型的引用。
例:
public class Department{ //... private Set<Employee> employees; }
由于“一方(Department)”是主动方,需要在Department的映射文件中使用<set>、<one-to-many> 和<key>标记进行映射,给出多方的相关联的外键。
在Department映射文件中,由于Department是主动方,需要在该映射文件中使用<one-to-many>标记进行映射,给出相关联的外键。
<set name="employees" lazy="true"> <key><column name="DEPART_ID"></key> <one-to-many class="com.entity.one2many.Employee"/> </set>
说明,
使用<key>指定关联外键。
4)一对多双向外键映射
“一对多双向外键映射”与“多对一双向外键映射”一样,因为双方既是主动方也是被动方。双方都需要给出映射关系的配置,并制定主控方,用于控制“外键”。
(以Employee(雇员)和Department(部门)为例)
实现关键:
在“一方(Department)”有对“多方(Employee)”集合类型的引用。
在“多方(Employee)”有对“一方(Department)”对象的引用。
双方都需要给出映射关系的配置,并制定主控方,用于控制“外键”。
在Employee映射文件中:
<many-to-one name="depart" class="com.entity.Department" fetch="join"> <column name="DEPART_ID"/> </many-to-one>
在Department映射文件中:
<set name="employees" table="EMPLOYEE" inverse="true" lazy="true"> <key> <column name="DEPART_ID"/> </key> <one-to-many class="com.entity.Emplyee"/> </set>
说明,
inverse="false"
inverse属性用在”一对多“和”多对多“双向关联上,inverse默认为false,表示本端可以维护关系,若inverse为true,则本端不能维护关系,交给另一端维护关系。
5)多对多映射
需要通过”关联表“实现。
(以学生(Student)选课(Course)为例)
实体类之间的关系:在Student中必须含有对Course的对象集合的引用;在Course中必须含有对Student的对象集合的引用,这样才能实现双向关联。
数据表之间的关系:使用连接表(Student_Course)实现,Student_Course表包含两个字段:CourseId和StuId。
实现关键:
两个实体类的设计,在一方都含有另一方的对象集合的引用。
因为双方既是主动方也是被动方。双方都需要给出映射关系的配置,并制定主控方,用于控制“外键”。
Student实体类的映射文件Student.hbm.xml。
<!--使用关联表Student_Course--> <!--配置inverse="false"--> <set name="course" table="Student_Course" inverse="false" lazy="true"> <!--使用<key>指定关联表外键:StuId--> <key><column name="StuId"></key> <many-to-many class="com.entity.Course" column="CourseId"/> </set>
Course实体类的映射文件Course.hbm.xml。
<!--使用关联表Student_Course--> <!--配置inverse="true"--> <set name="students" table="Student_Course" inverse="true" lazy="true"> <!--使用<key>指定关联表外键:CourseId--> <key><column name="CourseId"></key> <many-to-many class="com.entity.Student" column="StuId"/> </set>
使用inverse指定Student为关联对象的主控方。
以上是关于Hibernate概念初探的主要内容,如果未能解决你的问题,请参考以下文章