Spring Boot Actutaur + Telegraf + InFluxDB + Grafana 构建监控平台之应用数据分析
Posted appleYang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Boot Actutaur + Telegraf + InFluxDB + Grafana 构建监控平台之应用数据分析相关的知识,希望对你有一定的参考价值。
本节将引入完美的granafa仪表板,在上节的基础上,并提出自己的一些监控数据的总结和看法
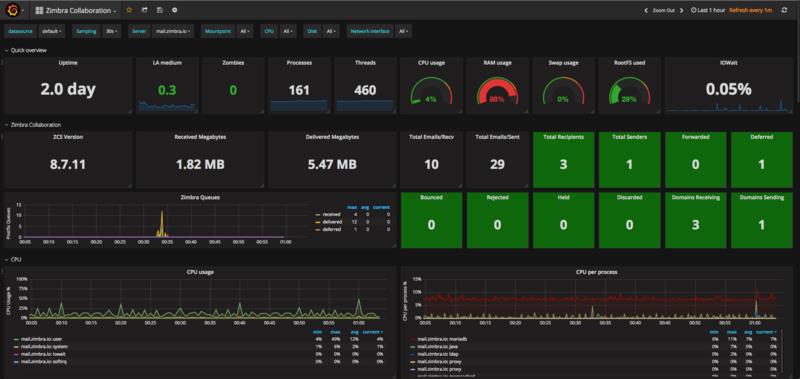
你可以有一个类似于这个的Dashboard,会引入监控Zimbra协作
本节环境采用的是centos7系统,配置跟上节介绍的一样,但是Telegraf是企业级监控加入很多可靠的监控插件,非常有用的一些参数,随之也给自
己的监控数据分析带来了复杂度。
- Telegraf:它负责收集我们通过配置文件传递的所有数据,Telegraf收集我们配置的输出结果,例如CPU / RAM / LOAD或nginx,MariaDB等服务。
- InfluxDB:这是Telegraf发送所有这些信息的地方,InfluxDB专门设计用于高效存储大量信息,此外,可以定义信息保留期以防万一出现性能问题
- Grafana:它是仪表板,负责显示InfluxDB存储在数据库中的所有信息
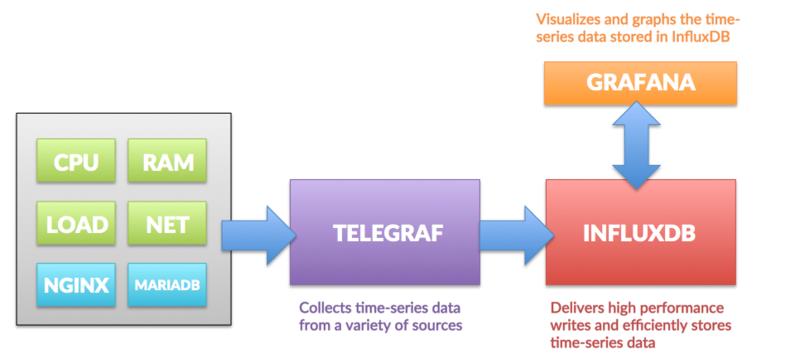
在Grafana中导入仪表板
你可以从这里下载:https://grafana.com/dashboards/2846/ 导入它们的步骤如下,转到我们的仪表板,然后按导入

输入Zimbra仪表板的ID:2846,我们将自动显示以下内容,选择我们的数据源并将其提供给导入
几分钟后,我们可以开始看到一个生动的仪表板,如下所示

数据分析
Grafana将系统和应用程序的的数据展示出来,就要开始分析数据的意图。
- 应用程序数据:SpringBoot Actutaur中的metrics收集到的数据指标,通过jolokia拉取数据到telegrafa上代理转给输入到时间序列数据库中(我尝试过直接将指标存入influxdb中,但未找到解决方案,有知道的伙伴可以给我留言)

补充:jolokia是一个JMX-HTTP桥梁,可替代JSR-160连接器。它是一种基于代理的方法,支持许多平台。
除了基本的JMX操作外,它还通过独特的功能(如批量请求和细粒度的安全策略)增强了JMX远程处理能力,应用程序的监控直接扩展到jvm。

特别注意:代理模式只能在需要时使用。代理servlet自身比代理模式更强大,因为它消除了增加整体复杂性和性能的附加层。此外,在代理模式下,某些功能(如合并MBeanServers)也不可用。
在telegrafa中,开启对应的数据,jolokia采用拉取数据,所以都会在[inputs.jolokia]更改
[[inputs.jolokia.metrics]]
name = "类加载次数"
mbean = "java.lang:type=ClassLoading"
attribute = "LoadedClassCount,UnloadedClassCount,TotalLoadedClassCount"
[[inputs.jolokia.metrics]]
name = "metrics数据"
mbean="org.springframework.boot:type=Endpoint,name=metricsEndpoint"
attribute = "Data"
grafana中在数据库中查到的就会有对应由jolokia拉去的数据做下拉列表
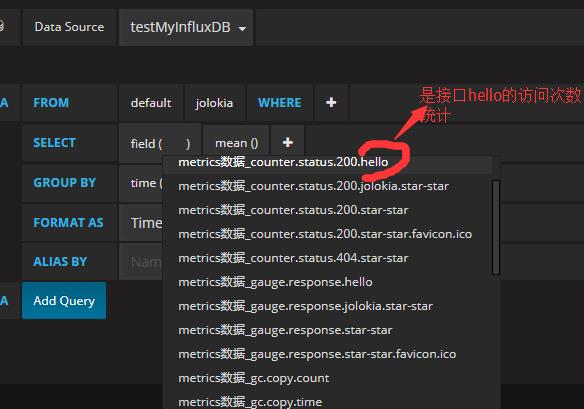
- 系统信息:包括处理器数量processors、运行时间uptime和instance.uptime、系统平均负载systemload.average。
- mem.*:内存概要信息,包括分配给应用的总内存数量以及当前空闲的内存数量。这些信息来自java.lang.Runtime。
- heap.*:堆内存使用情况。这些信息来自java.lang.management.MemoryMXBean接口中getHeapMemoryUsage方法获取的java.lang.management.MemoryUsage。
- nonheap.*:非堆内存使用情况。这些信息来自java.lang.management.MemoryMXBean接口中getNonHeapMemoryUsage方法获取的java.lang.management.MemoryUsage。
- threads.*:线程使用情况,包括线程数、守护线程数(daemon)、线程峰值(peak)等,这些数据均来自java.lang.management.ThreadMXBean。
- classes.*:应用加载和卸载的类统计。这些数据均来自java.lang.management.ClassLoadingMXBean。
- gc.*:垃圾收集器的详细信息,包括垃圾回收次数gc.ps_scavenge.count、垃圾回收消耗时间gc.ps_scavenge.time、标记-清除算法的次数gc.ps_marksweep.count、标记-清除算法的消耗时间gc.ps_marksweep.time。这些数据均来自java.lang.management.GarbageCollectorMXBean。
- httpsessions.*:Tomcat容器的会话使用情况。包括最大会话数httpsessions.max和活跃会话数httpsessions.active。该度量指标信息仅在引入了嵌入式Tomcat作为应用容器的时候才会提供。
- gauge.*:HTTP请求的性能指标之一,它主要用来反映一个绝对数值。比如上面示例中的gauge.response.hello: 5,它表示上一次hello请求的延迟时间为5毫秒。
- counter.*:HTTP请求的性能指标之一,它主要作为计数器来使用,记录了增加量和减少量。如上示例中counter.status.200.hello: 11,它代表了hello请求返回200状态的次数为11。
- double asterisks(
star-star)来自与Spring MVC匹配的请求/**(通常是静态资源)。 - /trace:该端点用来返回基本的HTTP跟踪信息
- /dump:该端点用来暴露程序运行中的线程信息。

在应用层面只能监控到接口的200,response,400的状态,时间响应上,需要的信息量还不足。可以在telegraf.conf中开启net监控网络等,使用正确的插件帮助我们实现监控需求。
以上都是我个人在实践中的总结和资料整理,如有疑问可以给我留言,我会及时回复您的。
以上是关于Spring Boot Actutaur + Telegraf + InFluxDB + Grafana 构建监控平台之应用数据分析的主要内容,如果未能解决你的问题,请参考以下文章