fluent中有好几个cellzone,get_domain取的是哪个
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了fluent中有好几个cellzone,get_domain取的是哪个相关的知识,希望对你有一定的参考价值。
Fluent UDF中经常用到thread*类型的指针,一般可以通过如下函数来获取。Lookup_Thread(Domain*domain, int id)
其中id是边界面的ID或者cell区域的ID,如下图中outlet边界的ID是2。
遗憾的是,网格载入Fluent后,其ID都是无法事先确定的。很多朋友只有在UDF源码开头用如下代码根据事后查到的ID手动定义,每次网格一变化又得重新在源码里面修改,重新编译,十分影响通用性。
#define OUTLET_ID 2 //每次不同网格需要根据情况修改后重新编译
Domain* domain=Get_Domain(1); //非多相流或多相流混合物的domain永远是1
Thread*tf=Lookup_Thread(domain, OUTLET_ID);
有没有一种办法能够一次性源码编译达到适应于所有网格呢?答案当然是肯定的,你可以通过zone名字来获取其ID号,然后画网格的时候只要取相同名字即可。实现该功能的函数源代码如下(插件VC++ UDF Studio 2022R1学术版上编译通过)
#include "udf.h"
#include "SuperUdfExtension.h" //VC++ UDF Studio自带的扩展库头文件,具体参考该软件中的编程手册
#pragma comment(lib, "SuperUdfExtension.lib") //VC++ UDF Studio自带的扩展库的lib文件
int GetZoneIdByName(CString zoneName) //适用于所有Fluent版本
int returnID=-1;
Domain*domain=Get_Domain(1);
CString strCurrentFluentVersion;
strCurrentFluentVersion.Format("%d.%d", RampantReleaseMajor, RampantReleaseMinor);//格式化当前Fluent版本为字符串形式
double fCurrentFluentVersion = atof(strCurrentFluentVersion.GetBuffer()); //当前Fluent版本转为double类型
if(fCurrentFluentVersion<=19.2) // 对于Fluent6.3-19.2,只能调用VC++ UDF Studio扩展库
SuperUdf_Initialize(AfxGetInstanceHandle()); //调用VC++ UDF Studio扩展库中任何函数之前必须调用此初始化函数,具体参考该软件中的编程手册
#if !RP_NODE
returnID=SuperUdf_GetZoneIdByName(zoneName.GetBuffer()); //调用VC++ UDF Studio扩展库中的SuperUdf_GetZoneIdByName函数,具体参考该软件中的编程手册
#endif
host_to_node_int_1(returnID);
else // 对于Fluent version >=19.3,有直接UDF函数可以实现
Thread*tf;
thread_loop_f(tf, domain) //对所有面的thread进行循环查找
if(0==zoneName.CompareNoCase(THREAD_NAME(tf))) //对比名字是否相同
returnID=THREAD_ID(tf);
break;
if(-1==returnID) //如果面的thread中无法找到匹配名字
Thread*tc;
thread_loop_c(tc, domain) //对所有网格的thread进行循环查找
if(0==zoneName.CompareNoCase(THREAD_NAME(tc))) //对比名字是否相同
returnID=THREAD_ID(tc);
break;
return returnID;
DEFINE_EXECUTE_ON_LOADING(get_id, libudf)
int theID=GetZoneIdByName("inlet"); //根据边界名字获取其ID,如果返回-1表示找不到
Message("the zone id of inlet is %d\n",theID);
以上源代码实现了通过zone名字来获取其ID号的功能。对于Fluent19.3或更高版本,可以利用THREAD_NAME与需要的名字进行对比,匹配情况下用THREAD_ID获得其ID。但对于Fluent19.2或更低版本, THREAD_NAME不起作用(可能Fluent的bug),我们只能依赖于插件VC++ UDF Studio中的拓展库函数SuperUdf_GetZoneIdByName来实现。是时候抛弃傻傻的#define ID了。
点击阅读全文
打开CSDN,阅读体验更佳
参与评论 请先 登录 后发表或查看评论
最新发布 FLUENT UDF 入门级代码及解释
FLUENT UDF 入门级代码及解释
继续访问
fluent udf手册_FLUENT并行UDF案例
正文共:2618字9图 预计阅读时间:7分钟1 前言当计算网格数量巨大时,如果还用串行计算的话,可以把人耗死。此时用并行计算可以显著节省时间,笔者在实际应用中深有体会。同样一个案例(网格数量约200万),串行计算大约10秒钟迭代一次,而改用25核并行计算,约2秒钟迭代一次。其实在我看来,模拟计算一定程度上比的就是计算机性能。特别当遇到网格数量巨大,且物理模型复杂的计...
继续访问
【Fluent Meshing】04:计算域提取
1.导入几何模型 2.创建网格尺寸 右键选择模型树节点Model,点击弹出菜单下Sizing → Scoped…弹出尺寸设置对话框 弹出对话框中如下图所示设置参数,点击Create按钮创建全局面尺寸分布 弹出对话框中如下图所示设置参数,点击Create按钮创建全局线尺寸分布 点击按钮Compute计算尺寸分布,待计算完毕后关闭对话框 3.重构网...
继续访问
获取宏定义_ANSYS Fluent:关于 UDF 的数据类型和相关的宏
在写 Fluent UDF 的过程中,我们经常会看到大量的诸如 d,c,f,t 这种变量,以及 domain,cell_t,face_t 等声明。如果自定义 UDF 的需求较高,我们就需要弄明白这些东西的含义。数据类型首先看一下 Fluent 的网格构成。在“ANSYS Fluent UDF Manual”中写道,A mesh is broken up into control volumes, ...
继续访问
Fluent的UDF官方案例(含代码)
8个官方给定的案例(含代码):多孔介质、壁温、粘度、UDS、流化床、非均匀流动、沉降、动网格。121页内容,提供代码供参考,简单易学
halcon算子翻译——get_domain
名称 get_domain - 获取图像的域(ROI)。 用法 get_domain(Image : Domain : : ) 描述 算子get_domain将所有输入图像的定义域作为区域返回。 并行 ● 支持计算设备上的对象。 ● 多线程类型:可重入(与非独占算子并行运行)。● 多线程范围:全局(可以从任何线程调用)。● 在元组级别自动并行化处理。 参数 Image ...
继续访问
圆柱绕流UDF-parallel主动运动
# include "udf.h" //主动运动 static real pretime=0.0; static real timestep; static real y1=0.0; static real prev1=0.0; static int surface_thread_id1=4; static real m1=7.286; static real c1=2.644723; static real k1=600.0; static real p=999.729; static real s=.
继续访问
ansys fluent udf manual 下载_【笔记】使用UDF进行Fluent并行计算时主机与节点之间的数据传递...
导言:在使用Fluent进行大规模并行计算时,难免会遇到主机与节点之间的需要数据传输的情况。Fluent在UDF使用手册中虽然提供了关于并行计算中的数据传输宏的定义与格式表述,但并没有给出相应的示例与详解。此外,在各平台也难以找到较为明晰的用法解释。本文将对Fluent应用UDF进行并行计算时的数据传输方式以及传输宏的使用方法进行详解。1. Fluent 的并行计算架构简介图1. Fluent 并...
继续访问
Fluent UDF中判断壁面热边界类型
我们知道Fluent中壁面可以有不同的换热边界类型,比如给定热流量的类型,给定温度的类型,给定对流条件的类型等等。 UDF中有时候需要根据类型的不同来进行不同的处理。那么在Fluent UDF中该如何判断一个壁面是什么类型的热边界呢?这里为大家解密几个未写入UDF帮助手册的宏。 宏 作用 HEAT_FLUX_WALL(Thread*tf) 判断是否是给定热流量的边界 TEMPERATURE_......
继续访问
UDF学习记录
一、数据结构 Cell thread对应zone Face thread对应边界 Example变量名可以随意定义,变量名不能重复 二、几何宏、循环宏 几何宏 原则:宏(c,t)t指的是cell thread, 宏(f,t)t指的是face thread A[ND_ND] 图形是三维ND_ND=3,二维ND_ND=2 F_AREA(A,f,t) 求面法向量,加上NV_MAG(A)算面的面积 循环宏 Thread_loop_c必须和begin_c_loop一起使用
继续访问
条件include_FLUENT边界条件的引用
正文共:2248字4图 预计阅读时间:6分钟1 前言 太阳能热水器在很多太阳能资源丰富的地区相当常见,笔者老家楼顶就有一台太阳能热水器。在一些大型建筑中,可能是多台设备串并联在一起。对于串联的模块,一台热水器的出口接到另一台的入口。假设不...
继续访问
Fluent UDF中使用智能动态数组
Fluent UDF中使用智能动态数组 Fluent UDF中要使用动态数组在传统编译方法中只能使用纯C语言中的malloc函数。此函数无法自动释放内存,必须手动调用free函数来释放,否则就会造成内存泄漏问题。 要想使用智能动态释放的数组,就必须将UDF语法拓展到C++语言,调用C++内置的智能动态数组vector支持。这里我们借助VC++ UDF Studio的插件来实现对智能动态数组的调用。例如下面例子实现将入口面的压力和温度存入动态数组,然后再将存储的压力值赋值给出口。 #include "u
继续访问
Fluent UDF中沿指定方向获取邻接网格
有朋友在VC++UDF Studio插件群里问Fluent UDF有没有宏可以沿着指定方向搜索到下一个邻接的网格?答案是No,没有现成的宏可以实现这个目的,但是我们可以写一个函数来手动实现。这个思路如下:对于当前的网格,我们可以利用c_face_loop宏配合C_FACE及C_FACE_THREAD宏,对当前网格的所有face进行循环,例如下图中的当前网格循环会有0,1,2,3四个face。然后我们再利用F_C0分别取这四个face的c0,将c0与当前网格比较,如果c0就是当前网格,那么邻接网格就是c1,反
继续访问
udf在服务器上显示语法错误,UDF代码错误在哪里啊? - 仿真模拟 - 小木虫 - 学术 科研 互动社区...
用组分输运模型模拟一个三维圆柱内的组分输运问题,圆柱壁面对组分有吸收。圆柱等分为两段,前一段标为huxi ,后一段标为xiu。由于壁面对组分的吸收缘故,必然使圆柱内从前往后浓度依次降低。从而下面的代码应该huxi2 与xiu2的值不同才是,但我得到的结果是huxi2与xiu2的值完全一样,奇了怪了,#include "udf.h"#define Dm 6.9e-5DEFINE_ON_DEMAND(...
继续访问
msh,fluent格式
# **10:Nodes (10 (zone-id first-index last-index type ND)) 12.Cells (12 (zone-id first-index last-index type element-type)) 13.Faces (13 (zone-id first-index last-index type element-type) (n0 n1 n2 cr cl)) type: element-type: 当element-type
继续访问
热门推荐 Log4j2研究之lookup
一个称得上优秀的框架,必备的要素之一可以通过某种约定的格式读取到所运行环境中的配置信息。本文中我们就来感受下log4j2实现此项功能时的精妙设计。
继续访问
get_domain_ip
#!/bin/bash if[$#-lt1];then echo$0needaparameter exit0 fi ADDR=$1 TMPSTR=`ping$ADDR-c1|sed'1s/.*([]∗[]∗)56.*/\1/;q'` #TMPSTR=`ping$ADDR-c...
继续访问
Fluent UDF 获取组分传输模型中的摩尔分数或分压力
很多朋友在开发Fluent模型中需要用UDF获取组分传输模型中的某气体组分的摩尔分数(或体积分数)或者分压力,但是UDF自带的只有获取质量分数的宏C_YI(c,t),需要自己写额外的代码去转换,有一定难度。已经不止一次看到论坛或者我们UDF编译调试插件群里的朋友问起这个问题,这里做个标准教程记录下来,希望对大家有用。 总体来说,有两种方法,一种是利用内置的函数来转换,另外一种就是自己写代码转换,这里逐一介绍。 1. 利用内置函数转换 内置转换方法参考了Fluent官方解决方案,稍微作了一些修改,并加了
继续访问
Linux功耗管理(17)_Linux PM domain framework(1)_概述和使用流程
1. 前言 在复杂的片上系统(SOC)中,设计者一般会将系统的供电分为多个独立的block,这称作电源域(Power Domain),这样做有很多好处,例如: 1)将不同功能模块的供电分开,减小相互之间的干扰(如模拟和数字分开)。 2)不同功能所需的电压大小不同:小电压能量损耗低,但对信号质量的要求较高;大电压能量损耗高,对信号质量的要求较低。 参考技术A Fluent UDF中经常用到thread*类型的指针,一般可以通过如下函数来获取。 参考技术B 自Python2.7以来,列表推导和生成器表达式的概念就移植到了字典上,从而有了字典推导。字典推导可以从任何以建值对作为元素的可迭代对象中构建出字典。
DIAL_CODES = [(86, 'China'),
(91, 'India')]
country_code = country:code for code, country in DIAL_CODES # 把DIAL_CODES内容反一下
用setdefault处理找不到的键
当字典d[k]不能找到正确的键的时候,Python会抛出异常,这个行为符合Python所信奉的“快速失败”哲学。也许每个Python程序员都知道可以用d.get(k,default)来替代d[k],给找不到的k一个返回默认值。但这不是处理找不到键最好的方法。采用setdefault处理:
复制代码
index =
word = "location"
location = "China"
index.setdefault(word, []).append(location)
# 如果word不存在就会创建一个空列表进去,简单来说就是创建了 word-[] 这样的键值对,所以之后的append是可以直接追加的,因为这时其实word已经出现了
# 如果word存在的话,就直接append,index.setdefault(word, []).append(location) 这种写法等价替代于:
# if key not in my_dict:
# my_dict[key] = []
# my_dict[key].append(new_value)
print(index) # 'location': ['China']
复制代码
映射的弹性键查询
如果某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。通常有两种方法:
defaultdict:处理找不到键的一个选择
复制代码
# defaultdict,如果查找不存在的key会自动生成 key - 'list'(你所定义的类型)
# 但是如果一开始没有指定类型,查找不存在的key则会报错
dd = defaultdict(list)
res = dd.get(list) # 返回none
print(res)
ans = dd["new"] # 返回空列表
print(ans)
复制代码
如果在创建defaultdict的时候没有指定default_factory,查询不存在的键会触发KeyError
特殊方法__missing__
复制代码
class StrKeyDict(dict): # 继承dict类
def __missing__(self, key): # d[k] 找不到会走这个函数
if isinstance(key, str): # 如果key是字符串且又没有找到,抛出KeyError
raise KeyError(key)
return self[str(key)] # 如果不是字符串就转成字符串再找
def get(self, key, default = None):
try:
return self[key] # 把get改造成了self[key],如果找不到会走missing
except KeyError: # 说明确实没有
return default # 返回默认值
def __contains__(self, key): # k in d 这个操作会调用它
return key in self.keys() or str(key) in self.keys() # 先按原来的找,找不到再转成str找
复制代码
字典的变种
说一些其它不同映射类型
collection.OrderedDict
这个类型在添加键的时候会保持顺序,因此键的迭代次序是一定的。其中的popitem默认返回并删除最后一个元素但是如果my_order.popitem(last = False)这样去用它的话,则会返回并删除第一个元素。
collection.ChainMap
容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当做一个整体逐个查找,直到键被找到。
collection.Counter
这个映射类型会给键准备一个整数计数器,简单来说就是方便统计
复制代码
nums = [9, 8, 2, 2, 6, 9, 4, 9, 7, 4, 5, 2, 5, 9, 6, 8, 6, 2,
5, 9, 6, 9, 5, 5, 7, 5, 1, 3, 1, 1, 9, 9, 1, 6, 2, 8,
8, 2, 5, 2, 2, 7, 9]
nums_str = ""
for num in nums:
nums_str += str(num)
print(nums_str)
ct = collections.Counter(nums_str)
print(ct) # Counter('9': 9, '2': 8, '5': 7, '6': 5, '8': 4, '1': 4, '7': 3, '4': 2, '3': 1)
复制代码
子类化UserDict
创建自定义映射类其实通常以UserDict为基类。
更倾向于UserDict而不是dict的原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但UserDict就不会带来这些问题。
复制代码
# 继承UserDict重写StrKeyDict
# UserDict并没有继承dict,而是封装了一个dict的实例
class StrKeyDict(UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data # 这些操作其实都是交给UserDict去完成的
def __setitem__(self, key, value):
self.data[str(key)] = value
复制代码
对比于我们之前写的StrKeyDict类,这次写的就比较简单,清爽。
不可变映射类型
从Python3.3开始,types模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图,虽然是个只读视图,但它是动态的。简单来说就是你改了原来的,这个也会跟着变。但是只读就意味着不能对其修改。
d = 1:'A'
d_proxy = MappingProxyType(d)
print(d_proxy)
# d_proxy[2] = 'x' 会报错
d[2] = 'B'
print(d_proxy) # d_proxy也会跟着变
集合论
“集”这个概念在Python中算是比较年轻的,使用率也不高。通常所说的集以及集合代指set或者frozenset。
集合是许多唯一对象的聚集,因此集合可以去重。
复制代码
address1 = ['BeiJing', 'Tokyo', 'NewYork', 'NewYork']
address1_set = set(address1) # set 去重,无序,概念上和数据结构里的大同小异 frozenset 不可变set
print(address1_set)
address2 = ['Tokyo', 'Paris', 'London']
address2_set = set(address2)
print(address1_set | address2_set) # | 取并集 & 取交集 - 取差集
str_set = 'a', 'a' # 简单构造set,使用 会自动去重
print(str_set)
复制代码
集合推导
前面说了字典推导,这里在简单了解一下集合推导
un_set = chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '') # 把32-255之间的字符其中包含 ‘SIGN’ 的取出来
print(un_set)
关于集合就说到这里,还有一些其他关于集合的操作方法,其实就是离散数学里对集合的操作罢了,这个就查阅官方文档吧。
dict和set的背后
主要解决以下几个问题:
Python里dict和set的效率有多高
为什么它们是无序的
为什么并不是所有的Python对象都可以当做dict的键或者set里的元素
为什么dict的键和set元素的顺序是根据它们被添加的次序而定的,以及为什么在映射对象的生命周期里这个顺序并不是一成不变的
为什么不应该在迭代循环dict或是set的同时往里添加元素
其实只有你懂数据结构,这些问题即使你不懂Python也能回答,因为精髓是一样的。
我们一点一点处理吧,为什么dict和set效率高,因为它们是O(1)的复杂度,这个是牺牲空间换来的,为什么这么说,因为这个和散列表有关系。
散列表其实是一个稀疏的数组,这里先拿Java举个例子,Java中的散列表中有个loadFactor的装载因子,这个值为0.75,也就是说,创建16个元素的表,最多只能容纳12个元素,当13个元素添加时,它就会扩容了。而在Python中这个因子大概是0.66,大体上是保证1/3是空的。
关于散列有一个很重要的关系,就是散列值和相等性,必须要满足的条件是,如果值相同,那么散列值必须相同,散列值不同,值必须不同,但是散列值相同,可以让值不同。尤其要注意一下,如果1.0=1 那么 hash(1.0)也就必须等于hash(1)即便它们内部构造不同。
接着来说散列表中的散列算法。当然这个可能会因为不同的语言或者其他而不同,在Python中,首先会调用hash(search_key)来计算search_key的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)
当然这里就会发生一个问题?如果不同对象产生相同的散列值怎么办,这个就被称为散列冲突。这个时候就要用特殊方法处理,在Java中是一种拉链法去处理的,简单来说就是在这个hash值的位置向下组成链表,当然这有个链表过长的问题,当一定程度长的时候,Java会把它转成红黑树。扯远了,在Python中则是会在散列值中另再取几位,然后用特殊方法处理一下,把新得到的数字再当做索引来寻,这个特殊方法通常又被称为扰动函数。如果发现还是冲突就继续上述步骤。(这也就能解释为什么Python中的负载因子会比较低,如果太高的话,会出现反复计算的情况)
现在我们来解决最开始的问题:
为什么是无序的,因为它是散列的,位置肯定不是顺序的。
为什么不是所有对象都可以用,因为如果拿可变对象当key,会出现key的散列值变化的问题,也就是可能出现找不到的问题,明明就存在却找不到。
第四个问题,感觉有点绕,这里有两个问题,第一个为什么dict的键和set元素的顺序是根据它们被添加的次序而定的(注意,这里的次序并非是顺序),因为存在冲突,如果k1和k2的散列值是一样的,那么先存k1就会存在这个位置,而k2就会重新散列,反过来,如果先存k2,那么位置就会倒过来。为什么在映射对象的生命周期里这个顺序并不是一成不变的,因为有扩容的存在,在Python中扩容是重新开一个空间,然后复制过去,所以可能会发生变化(散列表变大了,它的散列函数是和散了表长度有关的)。
最后一个问题,为什么不应该在迭代循环dict或是set的同时往里添加元素,因为如果你在迭代的过程中添加,就可能产生扩容问题,就可能导致漏元素问题。(这里是指迭代dict,而并非是在循环中使用dict,注意理解上不要有偏差)
杂谈(非正式向)
其实上一次我也有说过,数据结构的重要性,这一节主要的核心部分其实是散列表,如果你理解散列表,其实你很快就能解决最后那5个问题。这再一次充分说明了数据结构的重要性。当然其实在实际的开发中,你可能一辈子都不会去自己写个散列表。但如果有天你要改动时,你就能充分明白可改的位置,以及怎么改,而且也能帮助你更好的学习和充分使用这些底层采用散列表的数据结构。 参考技术C Fluent UDF中经常用到thread*类型的指针,一般可以通过如下函数来获取。 参考技术D Fluent UDF中经常用到thread*类型的指针,一般可以通过如下函数来获取。
[UWP]推荐一款很Fluent Design的bilibili UWP客户端 : 哔哩
原文:[UWP]推荐一款很Fluent Design的bilibili UWP客户端 : 哔哩
UWP已经有好几个Bilibili的客户端,最近又多了一个:
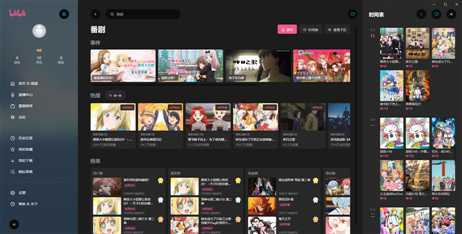
作者云之幻是一位很擅长设计的UWP开发者,我也从他那里学到了很多设计方面的技巧。它还是一位Bilibili的Up主,主打PowerPoint和UWP教学。
既然是一位设计方面的专家,这个UWP客户端当然有出色的设计。和过去几个同类应用不同,它整个UI经过全新设计,包含UWP各种时髦的设计元素,例如acrylic、reveal、connected-animation等都用上了,可以说是十分Fluent Design。
因为这个APP只是作者业余时间的兴趣之作,所以还缺失很多功能,只有最基本的播放、收藏等经典功能。云之幻自己也说因为他喜欢看动画,所以左侧菜单专门放了“番剧推荐”的菜单项;因为他自己不看直播,所以没有直播模块(其它各种复杂的模块也难得做);因为UWP的生态你懂的,所以连“分享”按钮都是假的。可能正是因为功能只打算做一半,所以名字只有“哔哩哔哩”的一半。

云之幻做了具体功能的介绍视频,因为视频里介绍得很全面,我就不再赘述(顺便赞一句,他的声音真好听):
这就是BiliBili桌面客户端吗?i了i了_哔哩哔哩 (゜-゜)つロ 干杯~
我自己的话,最喜欢的是这个APP的三段布局功能,既然现在都是宽屏了,占用多谢横向空间不好吗。另一点让我很喜欢的是它的性能真的很好,我的4代i3 CPU播放同一个视频可以看出明显的差异:

还有“打开新窗口”这个功能,可以在新的窗口中打开正在播放的视频,这样就可以同时看两个视频,达到双倍的快乐:

就算一次撸4条猫,4倍的快乐对我的CPU也是毫无压力(我的老i3 cpu又焕发了第二春):

而且再赞一句,性能真的很不错,:

目前哔哩还没开源,我就暂时不做更深入的技术分析。总的来说这是款颜值十分高又挺好用的bilibili客户端,我们要抱着发展的眼光看待这难得的UWP精品应用(委婉地提醒大家要暂时容忍一些Bug的存在),期待云之幻大佬和愉快的小伙伴们继续将它完善。
以上是关于fluent中有好几个cellzone,get_domain取的是哪个的主要内容,如果未能解决你的问题,请参考以下文章