初学python,感受和C的不同
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初学python,感受和C的不同相关的知识,希望对你有一定的参考价值。
从开始看Python到现在也有半个多月了,前后看了Python核心编程和Dive intoPython两本书。话说半个月看两本,是个人都知道有多囫囵吞枣,这也是因为我暂时没有需求拿这个做大型开发,主要是平时的小程序test用一用。所以
我的策略是,整体浏览,用到时候现查。话说这核心编程第一版太古老了,老在讲2.2之前的东西,我看的翻译电子版,翻译得也不好,很晦涩。看完这个后还有
点云里雾里,看网上人家说DIP好,啄木鸟还有免费电子文档,就找来看这个。怎么说呢,讲的比核心编程好,但不适合第一次看的初学者。我之所以觉得讲得
好,是因为看核心编程,有些概念还有些模糊,看了这本书就明白不少了。要是初学者上来就看这本,保证不好理解。
下面就是在学习的过程中,在翻阅资料的过程中,总结的一些C和python比较明显的不同之处,有大方向的,也有细节的。肯定没有总结完,比如动态
函数,lambda这些,我都懒得往上写了。实际上,作为两种完全不同的语言,下面这些差异只是冰山一角而已。权当抛砖引玉吧,至少应该对和我有相同研究
兴趣,正在考虑是否学习另一门语言的朋友有点帮助。此文也算是DIP的学习笔记吧。顺带说一句,要是有朋友了解,可以帮忙推荐一下实战性强的Python
教材,语言这东西,不多练手,光比划,是不可能学好的。
学习目的
我的以后的研究方向是嵌入式,显然,C语言是我的主要语言。我不是一个语言爱好者,我以前觉得,对于做研究而不是应用的人来说,了解多门语言,不如
精通一门语言。之所以去看python,主要还是因为python更有利于快速开发一些程序,也是因为现在认识到,研究和应用是不能分离的。个人以为,要
想在计算机工程的竞争中立足,必须懂C语言。因为真正要做高性能编程,
不可能将机器的体系架构抛到脑后让Python虚拟机(或Java虚拟机等)帮你搞定所有底层。越来越多的CPU
core,越来越恐怖的内存性能瓶颈,对于上层开发人员来说,无所谓,但是对高性能程序开发人员来说,这些是无法透明的。很多应用,还是自己掌控比较有
效。这些场合中,汇编和C还是不可替代的。但是,光知道C是不够的,掌握一门面向对象语言,相对更高层的语言,不仅对以后的个人发展有利,也会对自己的技
术认识产生帮助。
如果要问对我来说谁更重要,我觉得还是C更重要。C的学习曲线更陡,貌似简单,实际上到处都是陷阱,看上去比较简单低效的程序,也不是学1,2个月
就能搞定的。谈到优化的深层次和难度嘛,需要的功底是按年算的。但是一旦你C语言的基础打好了,对计算机的理解,对其他语言的理解都是大有裨益的。比如,
如果你有C基础,可以说,学过1天python,就能写的出来一些不短的程序。后面的优化也不是什么大不了的算法,都是非常基本的语句换来换去。当然这里
不是说 Python不好,实际上,上层应用,Python比C方便的不是一个层次。
很多人觉得,既然懂C了,那么进一步掌握C++应该是水到渠成,但C++不是C的超集,而我又不喜欢C++的繁琐和巨大,所以才决定看一看Python。我很喜欢Python的优雅与快捷。
语言类型
和C不一样,Python是一种动态类型语言,又是强类型语言。这个分类怎么理解呢?大概是可以按照下列说明来分类的:
静态类型语言
一种在编译期间就确定数据类型的语言。大多数静态类型语言是通过要求在使用任一变量之前声明其数据类型来保证这一点的。Java和 C 是静态类型语言。
动态类型语言
一种在运行期间才去确定数据类型的语言,与静态类型相反。Python 是动态类型的,因为它们确定一个变量的类型是在您第一次给它赋值的时候。
强类型语言
一种总是强制类型定义的语言。Java 和 Python 是强制类型定义的。您有一个整数,如果不明确地进行转换 ,不能将把它当成一个字符串。
弱类型语言
一种类型可以被忽略的语言,与强类型相反。VBScript 是弱类型的。在 VBScript 中,您可以将字符串 ‘12′ 和整数 3 进行连接得到字符串’123′,然后可以把它看成整数 123 ,所有这些都不需要任何的显示转换。
对象机制
具体怎么来理解这个“动态确定变量类型”,就要从Python的Object对象机制说起了。Objects(以下称对象)是Python对于数据
的抽象,Python中所有的数据,都是由对象或者对象之间的关系表示的,函数是对象,字符串是对象,每个东西都是对象的概念。每一个对象都有三种属性:
实体,类型和值。理解实体是理解对象中很重要的一步,实体一旦被创建,那么就一直不会改变,也不会被显式摧毁,同时通常意义来讲,决定对象所支持的操作方
式的类型(type,包括number,string,tuple及其他)也不会改变,改变的只可能是它的值。如果要找一个具体点的说明,实体就相当于对
象在内存中的地址,是本质存在。而类型和值都只是实体的外在呈现。然后Python提供一些接口让使用者和对象交互,比如id()函数用来获得对象实体的
整形表示(实际在这里就是地址),type()函数获取其类型。
这个object机制,就是c所不具备的,主要体现在下面几点:
1 刚才说了,c是一个静态类型语言,我们可以定义int a, char
b等等,但必须是在源代码里面事先规定。比如我们可以在Python里面任意一处直接规定a =
“lk”,这样,a的类型就是string,这是在其赋值的时候才决定的,我们无须在代码中明确写出。而在C里面,我们必须显式规定char *a =
“lk”,也就是人工事先规定好a的类型
2 由于在C中,没有对象这个概念,只有“数据的表示”,比如说,如果有两个int变量a和b,我们想比较大小,可以用a ==
b来判断,但是如果是两个字符串变量a和b,我们就不得不用strcmp来比较了,因为此时,a和b本质上是指向字符串的指针,如果直接还是用==比较,
那比较的实际是指针中存储的值——地址。
在Java中呢,我们通过使用 str1 == str2 可以确定两个字符串变量是否指向同一块物理内存位置,这叫做“对象同一性”。在 Java 中要比较两个字符串值,你要使用 str1.equals(str2)。
然后在Python中,和前两者都不一样,由于对象的引入,我们可以用“is”这个运算符来比较两个对象的实体,和具体对象的type就没有关系
了,比如你的对象是tuple也好,string也好,甚至class也好,都可以用”is”来比较,本质上就是“对象同一性”的比较,和Java中
的==类似,和 C中的pointer比较类似。Python中也有==比较,这个就是值比较了。
3
由于对象机制的引入,让Python的使用非常灵活,比如我们可以用自省方法来查看内存中以对象形式存在的其它模块和函数,获取它们的信息,并对它们进行
操作。用这种方法,你可以定义没有名称的函数,不按函数声明的参数顺序调用函数,甚至引用事先并不知道名称的函数。 这些操作在C中都是不可想象的。
4 还有一个很有意思的细节,就是类型对对象行为的影响是各方面的,比如说,a = 1; b =
1这个语句中,在Python里面引发的,可能是a,b同时指向一个值为1的对象,也可能是分别指向两个值为1的对象。而例如这个语句,c = []; d
= [],那么c和d是肯定指向不同的,新创建的空list的。没完,如果是”c = d =
[]“这个语句呢?此时,c和d又指向了相同的list对象了。这些区别,都是在c中没有的。
最后,我们来说说为什么python慢。主要原因就是function call
overhead比较大。因为所有东西现在都是对象了,contruct 和destroy 花费也大。连1 + 1 都是 function
call,像’12′+’45′ 这样的要 create a third string object, then calls the string
obj’s __add。可想而知,速度如何能快起来?
列表和数组
分析Python中的list和C中的数组总是很有趣的。相信可能一些朋友和一样,初学列表的时候,都是把它当作是数组来学的。最初对于list和数组区别的定性,主要是集中在两点。首先,list可以包含很多不同的数据类型,比如
["this", 1, "is", "an", "array"]
这个List,如果放在C中,其实是一个字符串数组,相当于二维的了。
其次呢,list有很多方法,其本身就是一个对象,这个和C的单纯数组是不同的。对于List的操作很多样,因为有方法也有重载的运算符。也带来一些问题,比如下面这个例子:
加入我们要产生一个多维列表,用下面这个语句
A = [[None] * 2] * 3
结果,A的值会是
[[None, None], [None, None], [None, None]]
初一看没问题,典型的二维数组形式的列表。好,现在我们想修改第一个None的值,用语句
A[0][0] = 5
现在我们再来看看A的值:
[[5, None], [5, None], [5, None]]
发现问题没有?这是因为用 * 来复制时,只是创建了对这个对象的引用,而不是真正的创建了它。 *3 创建了一个包含三个引用的列表,这三个引用都指向同一个长度为2的列表。其中一个行的改变会显示在所有行中,这当然不是你想要的。解决方法当然有,我们这样来创建
A = [None]*3
for i in range(3):
A[i] = [None] * 2
这样创建了一个包含三个不同的长度为2的列表。
所以,还是一直强调的,越复杂的东西,越灵活,也越容易出错。
代码优化
C是一个很简单的语言,当我们考虑优化的时候,通常想得也很简单,比如系统级调用越少越好(缓冲区机制),消除循环的低效率和不必要的系统引用,等
等,其实主要都是基于系统和硬件细节考虑的。而Python就完全不一样了,当然上面说的这些优化形式,对于Python仍然是实用的,但由于
Python的语法形式千差万别,库和模块多种多样,所以对于语言本身而言,就有很多值得注意的优化要点,举几个例子吧。
比如我们有一个list L1,想要构建一个新的list L2,L2包括L1的头4个元素。按照最直接的想法,代码应该是
L2 = []
for i in range[3]:
L2.append(L1[i])
而更加优化和优美的版本是
L2 = L1[:3]
再比如,如果s1..s7是大字符串(10K+),那么join([s1,s2,s3,s4,s5,s6,s7])就会比
s1+s2+s3+s4+s5+s6+s7快得多,因为后者会计算很多次子表达式,而join()则在一次过程中完成所有的复制。还有,对于字符串操作,
对字符串对象使用replace()方法。仅当在没有固定字符串模式时才使用正则表达式。
所以说,以优化为评判标准,如果说C是短小精悍,Python就是博大精深。
include和import
在C语言中的include非常简单,因为形式单一,意义明确,当你需要用到外部函数等资源时,就用include。而Python中有一个相似的
机制,就是import。乍一看,这两个家伙挺像的,不都是我们要用外部资源(最常见的就是函数或者模块(Python))时就用这个来指明么?其实不
然,两者的处理机制本质区别在于,C中的include是用于告诉预处理器,这个include指定的文件的内容,你都给我当作在本地源文件中出现过。而
import呢,不是简单的将后面的内容*直接*插入到本地里面去,这玩意更加灵活。事实上,几乎所有类似的机制,Python都比C灵活。这里不是说C
不好,C很简练,我其实更喜欢C。
简单说说这个灵活性。import在python中有三种形式,import X, from X import *( or a,b,c……),
X = __import__(’x\')。最常用的是第二种,因为比较方便,不像第一种那样老是用X.module来调用模块。from X
import *只是import那些public的module(一般都是不以__命名的模块),也可以指定a,b,c来import。
什么时候用哪一种形式呢?应该说,在大多数的模块文档里,都会明确告诉你应该用哪种形式。如果需要用到很多对象,那么from X import
*可能更合适一些,但是,就目前来看,大多数第三方Python库都不推荐使用from modulename import *
这种格式。这样做会使引入者的namespace混乱。很多人甚至对于那些专门设计用于这种模式的模块(包括Tkinter,
threading和matplot)都不采用这种方式。而如果你仅仅需要某个对象类a,那么用from X import a比用import
X.a更好,因为以后你调用a的函数直接用a.function()既可以了,不用加X。
如果你连自己希望import的模块都不知道怎么办?请注意,此时Python的优势就体现出来了,我们可以用
__import__(module)来调用module,其中这个module是字符串,这样,可以在运行时再决定,你到底要调用什么module。举
个例子:
def classFromModule (module, Name):
mod = __import__ (module)
return getattr (mod, Name)
这里,定义了一个函数classFromModule,你可以在代码的任何时候调用它,
o = classFromModule (ModuleOfTheClass, NameOfTheAttribute)()
只需要传入字符串形式的你希望import的模块ModuleOfTheClass和其中属性的名字NameOfTheAttribute(当然可以是数据也可以是方法),就能调用了,这个名字字符串不用事先指定,而是根据当时运行的情况来判断。
顺带说一句,Python中import的顺序也有默认规定,这个和C中的include有点类似,因为我们一般都是先include系统文件,再
include自己的头文件(而且还有<>和“”的区别)。Python中呢,一般应该按照以下顺序import模块:
1. 标准库模块 — 如 sys, os, getopt 等
2. 第三方模块
3. 本地实现的模块。
全局变量
这里谈全局变量呢,倒不是说Python和c的全局变量概念不同,他们的概念是相同的。只是在使用机制上,是有一些差异的。举个例子:
– module.py –
globalvar = 1
def func():
print globalvar
# This makes someglobal readonly,
# any attempt to write to someglobal
# would create a new local variable.
def func2():
global globalvar
globalvar = 2
# this allows you to manipulate the global
# variable
在 func这个函数中,globalvar是只读的。如果你使用了globalvar =
xxx这种赋值语句,Python会重新创造一个新的本地对象并将新值赋给它,原来的对象值不变。而在func2函数中,由于我们事先申明了
globalvar是global的,那么此时的更改就直接在全局变量上生效。 参考技术A
好吧。
1、python是个怪物。用了10年了,感觉它与其它语言不太一样。所以C语言是必学的。 python语言有些特别。如果同时学可能混淆。 如果你时间不足够,两个同时学也没有大问题。
2、不过最好还是先学习C语言。把它学成优秀,然后紧接着再学习python。
3、C语言学习并不会花多长时间。我曾经教一个没有一点编程基础的女生4天,最多一个星期就掌握C语言。并且能够用C语言设计程序了。
4、当然要掌握好C语言还需要大背的记忆 ,以及练习。上机练习时间不少于30小时。
5、会了C后再学python会明显容易。不过python太自由了。 如果你一开始学习python会觉着很容易,再学习C,就会觉着C好难。
6、如果你认真学习,我个人认为c语言甚至比python还要简单。
8、最初接触C语言时要弄清楚各种变量的定义方法,特别是常用的类型,int、float、char等等,还要掌握各种类型的输入、输出格式。这一步做到后,上机就没有多大的问题了。
9、在对函数的学习过程中,一定要弄明白函数的作用和具体格式。值得强调的是在写循环程序时,一定要弄清楚循环的条件。
10、对每一个知识点,都应该立即编出对应的程序,有时可能还会有语法错误,碰到更好的方法也可以试一下,很多时候你想想代码怎么写和你真的写出来了是有很大的差距的。
11、学习时一定有很多疑惑的,要及时弄清楚。
12、找一本好的课本,我并不推荐谭浩强的《C语言程序设计》,因为这本书把知识点讲的太细碎太理论。我推荐《c语言程序设计:现代方法》这本书,书中奥妙非凡,值得深读体验。
13、不要认为上课认真听课有用,写程序不可能从课堂上学会太多的,伟大的程序员或者是很多的黑客,不是老师教出来的,你的有自己的想法自己的思路自己的,学习一门语言才有用,也才会得到别人传教不了的东西。
参考技术B python相对来讲,更加容易入门些 参考技术C 你拿到这个页面地址后,然后把这个地址中的id解析出来,这个id就是productId,然后就是根据那个接口一页一页的扫描了,页面结构可能会变,但是接口一般不会经常变Java+面向对象初学感想
在先导课之前我未曾接触C和Python之外的语言,在大一学年的课程中,用面向过程的思想方法足以完成绝大多数课程要求,故而我也对面向对象的编程思想知之甚少,虽然多有耳闻但是对它一直没有一个正式的学习了解也没有任何直观感受过。因此,在第一节先导课上,第一次真的去了解到面向对象的思想感觉是很新鲜甚至有点惊叹的。而对于java,在上课之前心里其实是有点畏惧的,毕竟有的代码比起C语言来说要多打很多字(System.out.println....),但上完第一节课后,我对Java的好感度一下子就被提高了不少,通过类和类的方法来构筑程序的编程方法让我仿佛一下子打开了视野,加上Java里很多自带的方法使用起来非常便利,在课程中能逐渐体验到用Java写代码是一个很有趣的过程。
第一次作业我的程序bug非常多,可以debug完成度说是非常低了……大部分的测试点都没有通过,其中一个最严重的问题就是,共计13个测试点,程序输出到第6个就不输出了,MyTest里面的tearDown方法也没有执行,虽然输出了的6个测试点好像都通过了(课上测试的时候测试点输出的看不懂可能有出入……),但是这个输出到第六个点的问题未解决就匆匆忙忙奔向下一节课去了……今天再来看,发现是在
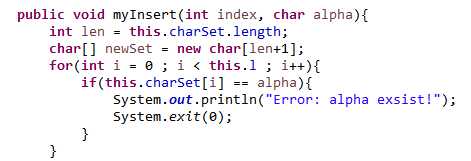
CharSet类的myInsert方法里多了一行在判断字符已存在之后结束运行的代码,当时为什么要加这一行?我现在也想不起来自己当时怎么想的了……在之后的几次作业里依然还有许多诸如此类的bug,多余的操作等等,没有特别记录的价值,我下面就不特别写出来了……
第二次作业的课上测试情况也是一样的惨,一片000,我在debug的过程中出现了另一个错误,如图,
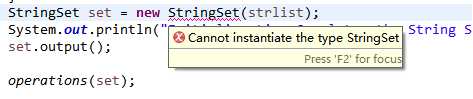
这个错误的意思是‘无法实例化类’,可能的原因有:一、类的构造函数为private,可是我的构造函数是public,排除;二、这个类是抽象类,看到这里我就想起来了,之前有这样的一个报错:
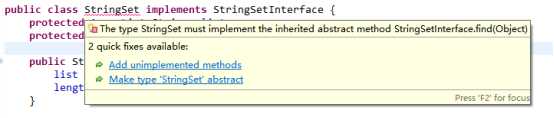
我当时没有多想,也犯懒没有进一步的研究,直接就双击了第二个选项,就把StringSet变成了抽象类,由此得出教训一:不要被Eclipse宠坏了!虽然Eclipse为我们提供了很多这样的便利,但是对于我们这些极为不熟悉的新手,千万不可以图一时之便滥用这些quick fixes,我们应当利用这些信息来研究到底是哪里除了错,并且内化,而不是这样拿来偷懒。
话又说回来,这里告诉了我们,我们在StringSet里缺少了一些它所属的接口的方法,究竟是哪一个呢?万幸接口中只有三个抽象方法,很快就找到了问题所在,在StringSetInterface中
,find方法的参数是一个Object,然而在StringSet中的find方法的参数却是一个String,这样这两个方法就会被认为是两种不同的方法,将二者的参数改成一样的就可以了,这是教训二。

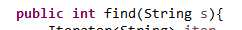
接下来是第三次作业,第三次作业是词频统计,在这个学期的C语言与数据结构课程中我们已经用C语言写过了这道题,但是我的这门课学得很差——这也直接导致了我不会用更加快速的排序算法提升性能,除此之外,我的程序还有很多不达标准的地方,比如说位置的记录、还有单词的表现上,由于我本来试图在读入单词的同时排序,所以想将单词逐个读入,于是利用了一个ArrayList<Character>来储存单词,但是在调用.ToString()方法时会输出奇怪的东西,如图:
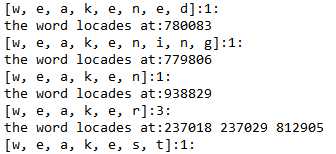
在写第四次作业的时候我才将读入的方法变成整行读入再处理字符串。
在排序等等的算法上我也只能使用自带的方法,关于树之类的查找排序算法我也在这个学期的课程中没有学会……正在补习。
但是在这一次的课上,关于提升性能的方法有了进一步的了解,也是有所收获。
到了第四次也就是最后一次作业,通过前面三次的试错与积累,写代码的过程意外的顺利,几乎没有被卡住的地方,主要的难点就是在HashMap的利用上吧,理解HashMap、Entry等等用了我一些时间,但是最终也顺利的完成了作业。
经过四次课的训练和积累,能够明显感觉到自己运用Java的熟练度有增长,但是也曝露了很多不足,其中有很大一部分可以说是由这个学期缺乏锻炼导致的,会在编程过程中有很多动作很小但是危害不小的错误,还有明显多余累赘的地方,同时,从第一次到最后一次作业在写的过程中效率提升了很多的一个原因就是在最后一次作业中更加妥善利用搜索引擎了,一来是Java的熟练度还是不够高,二来是Java有很多方便的方法可以大大提升编程效率,这些都可以不怕麻烦不断向搜索引擎“不耻下问”的,这也是学习的一环。
这次暑季学期的面向对象先导课是我第一次接触“训练营”形式的课程,在课堂上有自己动手的时间,不必像平时课堂上想要立即试试看就会造成听课分心的困扰,在课堂上立即动手自己写写看,内化的更快。特别是对于我个人而言,虽然作为经常进度太慢,拖后腿的成员,压力不小,但是课堂的氛围还是能令我十分投入。课堂练习的难度对于我来说也比较适中,虽然我属于基础较差的学生,但是课堂人数较少,练习的时间也很充足,无论是向老师助教,还是身边的同学请教,都能都获取足够的答疑资源,所以在课堂上的学习效率是很高的。
如果说有什么地方让我感觉跟不上,就是在课上测试的时候了,当然这与我课下作业写得太不好也有关系,课下作业完成的好的同学很快就能测完,然后做自己的事等像我这样垂死挣扎的同学了。虽然个别同学完成作业的质量无法控制,但是如果在作业要求上对输入输出有更严格的标准说明或者是样例或许能把总体的测试时间缩短一些。
总的来说,虽然说面向对象这门课我们从学长学姐们口中听到的都极为可怕,但是这门先导课的学习体验还是很愉快的,也谢谢老师和助教的付出~
以上是关于初学python,感受和C的不同的主要内容,如果未能解决你的问题,请参考以下文章