http协议解析 请求行的信息怎么提取 c语言源码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了http协议解析 请求行的信息怎么提取 c语言源码相关的知识,希望对你有一定的参考价值。
实现步骤:1)用Wireshark软件抓包得到test.pcap文件
2)程序:分析pcap文件头 -> 分析pcap_pkt头 -> 分析帧头 -> 分析ip头 -> 分析tcp头 -> 分析http信息
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<netinet/in.h>
#include<time.h>
#define BUFSIZE 10240
#define STRSIZE 1024
typedef long bpf_int32;
typedef unsigned long bpf_u_int32;
typedef unsigned short u_short;
typedef unsigned long u_int32;
typedef unsigned short u_int16;
typedef unsigned char u_int8;
//pacp文件头结构体
struct pcap_file_header
bpf_u_int32 magic; /* 0xa1b2c3d4 */
u_short version_major; /* magjor Version 2 */
u_short version_minor; /* magjor Version 4 */
bpf_int32 thiszone; /* gmt to local correction */
bpf_u_int32 sigfigs; /* accuracy of timestamps */
bpf_u_int32 snaplen; /* max length saved portion of each pkt */
bpf_u_int32 linktype; /* data link type (LINKTYPE_*) */
;
//时间戳
struct time_val
long tv_sec; /* seconds 含义同 time_t 对象的值 */
long tv_usec; /* and microseconds */
;
//pcap数据包头结构体
struct pcap_pkthdr
struct time_val ts; /* time stamp */
bpf_u_int32 caplen; /* length of portion present */
bpf_u_int32 len; /* length this packet (off wire) */
;
//数据帧头
typedef struct FramHeader_t
//Pcap捕获的数据帧头
u_int8 DstMAC[6]; //目的MAC地址
u_int8 SrcMAC[6]; //源MAC地址
u_short FrameType; //帧类型
FramHeader_t;
//IP数据报头
typedef struct IPHeader_t
//IP数据报头
u_int8 Ver_HLen; //版本+报头长度
u_int8 TOS; //服务类型
u_int16 TotalLen; //总长度
u_int16 ID; //标识
u_int16 Flag_Segment; //标志+片偏移
u_int8 TTL; //生存周期
u_int8 Protocol; //协议类型
u_int16 Checksum; //头部校验和
u_int32 SrcIP; //源IP地址
u_int32 DstIP; //目的IP地址
IPHeader_t;
//TCP数据报头
typedef struct TCPHeader_t
//TCP数据报头
u_int16 SrcPort; //源端口
u_int16 DstPort; //目的端口
u_int32 SeqNO; //序号
u_int32 AckNO; //确认号
u_int8 HeaderLen; //数据报头的长度(4 bit) + 保留(4 bit)
u_int8 Flags; //标识TCP不同的控制消息
u_int16 Window; //窗口大小
u_int16 Checksum; //校验和
u_int16 UrgentPointer; //紧急指针
TCPHeader_t;
//
void match_http(FILE *fp, char *head_str, char *tail_str, char *buf, int total_len); //查找 http 信息函数
//
int main()
struct pcap_file_header *file_header;
struct pcap_pkthdr *ptk_header;
IPHeader_t *ip_header;
TCPHeader_t *tcp_header;
FILE *fp, *output;
int pkt_offset, i=0;
int ip_len, http_len, ip_proto;
int src_port, dst_port, tcp_flags;
char buf[BUFSIZE], my_time[STRSIZE];
char src_ip[STRSIZE], dst_ip[STRSIZE];
char host[STRSIZE], uri[BUFSIZE];
//初始化
file_header = (struct pcap_file_header *)malloc(sizeof(struct pcap_file_header));
ptk_header = (struct pcap_pkthdr *)malloc(sizeof(struct pcap_pkthdr));
ip_header = (IPHeader_t *)malloc(sizeof(IPHeader_t));
tcp_header = (TCPHeader_t *)malloc(sizeof(TCPHeader_t));
memset(buf, 0, sizeof(buf));
//
if((fp = fopen(“test.pcap”,”r”)) == NULL)
printf(“error: can not open pcap file\n”);
exit(0);
if((output = fopen(“output.txt”,”w+”)) == NULL)
printf(“error: can not open output file\n”);
exit(0);
//开始读数据包
pkt_offset = 24; //pcap文件头结构 24个字节
while(fseek(fp, pkt_offset, SEEK_SET) == 0) //遍历数据包
i++;
//pcap_pkt_header 16 byte
if(fread(ptk_header, 16, 1, fp) != 1) //读pcap数据包头结构
printf(“\nread end of pcap file\n”);
break;
pkt_offset += 16 + ptk_header->caplen; //下一个数据包的偏移值
strftime(my_time, sizeof(my_time), “%Y-%m-%d %T”, localtime(&(ptk_header->ts.tv_sec))); //获取时间
// printf(“%d: %s\n”, i, my_time);
//数据帧头 14字节
fseek(fp, 14, SEEK_CUR); //忽略数据帧头
//IP数据报头 20字节
if(fread(ip_header, sizeof(IPHeader_t), 1, fp) != 1)
printf(“%d: can not read ip_header\n”, i);
break;
inet_ntop(AF_INET, (void *)&(ip_header->SrcIP), src_ip, 16);
inet_ntop(AF_INET, (void *)&(ip_header->DstIP), dst_ip, 16);
ip_proto = ip_header->Protocol;
ip_len = ip_header->TotalLen; //IP数据报总长度
// printf(“%d: src=%s\n”, i, src_ip);
if(ip_proto != 0×06) //判断是否是 TCP 协议
continue;
//TCP头 20字节
if(fread(tcp_header, sizeof(TCPHeader_t), 1, fp) != 1)
printf(“%d: can not read ip_header\n”, i);
break;
src_port = ntohs(tcp_header->SrcPort);
dst_port = ntohs(tcp_header->DstPort);
tcp_flags = tcp_header->Flags;
// printf(“%d: src=%x\n”, i, tcp_flags);
if(tcp_flags == 0×18) // (PSH, ACK) 3路握手成功后
if(dst_port == 80) // HTTP GET请求
http_len = ip_len – 40; //http 报文长度
match_http(fp, “Host: “, “\r\n”, host, http_len); //查找 host 值
match_http(fp, “GET “, “HTTP”, uri, http_len); //查找 uri 值
sprintf(buf, “%d: %s src=%s:%d dst=%s:%d %s%s\r\n”, i, my_time, src_ip, src_port, dst_ip, dst_port, host, uri);
//printf(“%s”, buf);
if(fwrite(buf, strlen(buf), 1, output) != 1)
printf(“output file can not write”);
break;
// end while
fclose(fp);
fclose(output);
return 0;
//查找 HTTP 信息
void match_http(FILE *fp, char *head_str, char *tail_str, char *buf, int total_len)
int i;
int http_offset;
int head_len, tail_len, val_len;
char head_tmp[STRSIZE], tail_tmp[STRSIZE];
//初始化
memset(head_tmp, 0, sizeof(head_tmp));
memset(tail_tmp, 0, sizeof(tail_tmp));
head_len = strlen(head_str);
tail_len = strlen(tail_str);
//查找 head_str
http_offset = ftell(fp); //记录下HTTP报文初始文件偏移
while((head_tmp[0] = fgetc(fp)) != EOF) //逐个字节遍历
if((ftell(fp) – http_offset) > total_len) //遍历完成
sprintf(buf, “can not find %s \r\n”, head_str);
exit(0);
if(head_tmp[0] == *head_str) //匹配到第一个字符
for(i=1; i<head_len; i++) //匹配 head_str 的其他字符
head_tmp[i]=fgetc(fp);
if(head_tmp[i] != *(head_str+i))
break;
if(i == head_len) //匹配 head_str 成功,停止遍历
break;
// printf(“head_tmp=%s \n”, head_tmp);
//查找 tail_str
val_len = 0;
while((tail_tmp[0] = fgetc(fp)) != EOF) //遍历
if((ftell(fp) – http_offset) > total_len) //遍历完成
sprintf(buf, “can not find %s \r\n”, tail_str);
exit(0);
buf[val_len++] = tail_tmp[0]; //用buf 存储 value 直到查找到 tail_str
if(tail_tmp[0] == *tail_str) //匹配到第一个字符
for(i=1; i<tail_len; i++) //匹配 head_str 的其他字符
tail_tmp[i]=fgetc(fp);
if(tail_tmp[i] != *(tail_str+i))
break;
if(i == tail_len) //匹配 head_str 成功,停止遍历
buf[val_len-1] = 0; //清除多余的一个字符
break;
// printf(“val=%s\n”, buf);
fseek(fp, http_offset, SEEK_SET); //将文件指针 回到初始偏移
参考技术A // server.c 需要的自己改下···
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <signal.h>
#define MYPORT 80
#define BACKLOG 10
void sigchld_handler(int s)
while(wait(NULL) > 0);
int main(void)
int sockfd, new_fd;
struct sockaddr_in my_addr;
struct sockaddr_in their_addr;
int sin_size;
struct sigaction sa;
int yes=1;
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
perror("socket");
exit(1);
if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(int)) == -1)
perror("setsockopt");
exit(1);
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons(MYPORT);
my_addr.sin_addr.s_addr = INADDR_ANY;
memset(&(my_addr.sin_zero), '\0', 8 ) ;
if (bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr)) == -1)
perror("bind");
exit(1);
if (listen(sockfd, BACKLOG) == -1)
perror("listen");
exit(1);
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART;
if (sigaction(SIGCHLD, &sa, NULL) == -1)
perror("sigaction");
exit(1);
while(1) // main accept() loop
sin_size = sizeof(struct sockaddr_in);
if ((new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size)) == -1)
perror("accept");
continue;
printf("server: got connection from %s\n",inet_ntoa(their_addr.sin_addr));
if (!fork()) // this is the child process
close(sockfd); // child doesn't need the listener
if (send(new_fd, "Hello, world!\n", 14, 0) == -1)
perror("send");
close(new_fd);
exit(0);
close(new_fd);
return 0;
Python网络爬虫与信息提取——HTTP协议及Requests库的方法
HTTP协议及Requests库的方法
HTTP: Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。也就是用户发出请求,服务器给出响应。无状态是指第一次请求与第二次请求之间并没有相关关联。应用层协议工作在TCP协议之上。
HTTP协议采用URL作为定位网络资源的标识。
URL格式:http://host[:port][path]
host域合法的Internet主机域名或IP地址
port域:端口号(可省),缺省端口为80
path域:请求资源的路径。资源在这样的主机或IP地址的服务器上所包含的内部路径
eg: http://www.bit.edu.cn 表示北京理工大学的校园网的首页
http://220.181.111.188/duty 指的是这样一台IP主机上,duty目录下的相关资源
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。就像电脑的一个文件一样,不过这个资源不在电脑上,而在Internet上。
HTTP协议对资源的操作
|
方法 |
说明 |
|
GET |
请求获取URL位置的资源 |
|
HEAD |
请求获取URL位置资源的响应消息报告,即获得该资源的头部信息(当资源很大时,难以完全拿下或者拿下的代价很大时,可以请求HEAD,能够获得头部信息,并且分析资源的大概内容) |
|
POST |
请求向URL位置的资源后附加新的数据。不改变URL位置现有的内容,在后面新增用户提交的资源 |
|
PUT |
请求向URL位置存储一个资源,覆盖原URL位置的资源 |
|
PATCH |
请求局部更新URL位置的资源,即改变该处资源的部分内容 |
|
DELETE |
请求删除URL位置储存的资源 |
这6个方法就是requests库提供的6个主要函数所对应的功能。
HTTP通过这6中方法对资源进行管理,每次操作时是独立的,无状态的。
在HTTP协议的世界里,网络通道和服务器都是黑盒子,它能看到的就是URL链接,以及对URL链接的相关操作。
理解PATCH和PUT的区别:
假设URL位置有一组数据UsreInfo,包括UserI、UserName等20个字段。
需求:用户修改了UserName,其他不变
1:采用PATCH,仅向URL提交UserName的局部更新请求。
2:采用PUT,必须将所有20个字段一并提交到URL,未提交字段将被删除
PATCH最主要好处:节省网络带宽
HTTP协议与Requests库
|
HTTP协议方法 |
Requests库方法 |
功能一致性 |
|
GET |
requests.get() |
一致 |
|
HEAD |
requests.head() |
一致 |
|
POST |
requests.post() |
一致 |
|
PUT |
requests.put() |
一致 |
|
DELETE |
requests.delete() |
一致 |
|
PATCH |
requests.patch() |
一致 |
Requests库的head()方法
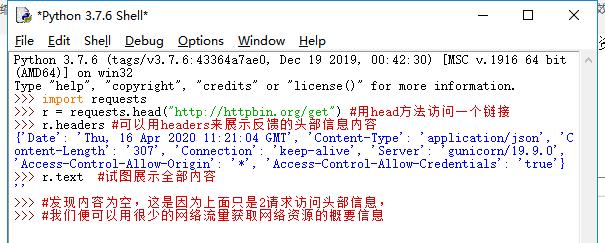
注:倒数第二行多打了一个2(⊙﹏⊙)
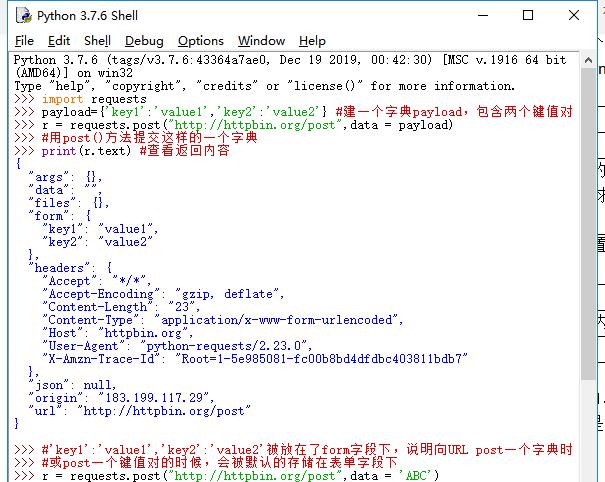
Requests库的post()方法

requests.request(method,url,**kwargs)
method: 请求方式,对应get/put/post等7种
url : 拟获取页面的URL链接
**kwargs: 控制访问参数,共13个
method:请求方式
r=requests.request(‘GET’,url,**kwargs)
r=requests.request(‘HEAD’,url,**kwargs)
r=requests.request(‘POST’,url,**kwargs)
r=requests.request(‘PUT’,url,**kwargs)
r=requests.request(‘PATCH’,url,**kwargs)
r=requests.request(‘delete’,url,**kwargs)
r=requests.request(‘OPTIONS’,url,**kwargs)
OPTIONS:向服务器获取跟服务器打交道的参数,并不与获取资源直接相关,因此使用较少
**kwargs:控制访问参数(13个),均为可选项
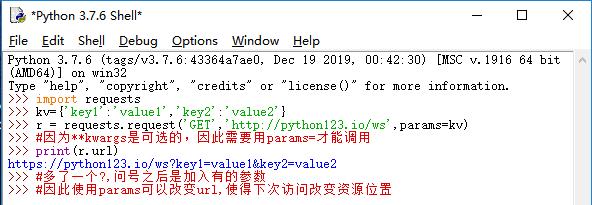
1:params 字典或字节序列,作为参数增加到url中
2:data 字典、字节序列或文件对象,作为Request的内容

3:json : JSON格式的数据,作为Request的内容,向服务器提交
JSON是HTTP,HTML相关的web开发中非常常见,也是HTTP协议最经常使用的数据格式

4:headers : 字典,HTTP定制头。对应于向某个url访问时所发起的HTTP的头字段。
就是可以使用这个字段来定制访问某一个url的HTTP协议头

5:cookies: 字典或CookieJar,Request中的cookie
6:auth : 元组,支持HTTP认证功能
7:files :字典类型,向服务器传输文件
fs={‘file’:open(‘data.xls’,’rb’)} #用file与对应的文件做键值对,用open()方式打开这个文件
r=requests.request(‘POST’,’http://python123.io/ws’,file=fs) #可以向某一个链接提交一个文件
8:timeout: 设定的超时时间,以秒为单位

9: proxies : 字典类型,为爬取网页设定相关的访问代理服务器,可以增加登陆认证
pxs={‘http’:’http://user:pass@10.10.10.1:1234’,’https’:’https://10.10.10.1:4321’}
r=requests.request(‘GET’,’http://www.baidu.com’,proxies=pxs)
#增加两个代理,一个是http访问时使用的代理,在这代理中可以增加用户名和密码的设置;再增加一个https的代理服务器,这样在访问百度时,我们所使用的IP地址就是代理服务器的IP地址,使用这个字段可以有效地隐藏用户爬取网页的原的IP地址信息,能够有效的防止对爬虫的逆追踪
虽然我写的时候显示TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。(⊙﹏⊙)
10:allow_redirects : True/False,默认为True,重定向开关,表示是否允许对url进行重定向
11:stream : True/False ,默认为True,获取内容立即下载开关,表示对获取的内容是否立即下载
12: verify : True/False,默认为True,认证SSl证书开关,
13: cert: 保存本里SSL证书路径的字段
requests.get(url,params=None,**kwargs)
Url :拟获取页面的url链接
params :url中的额外参数,字典或字节流格式,可选
**kwargs :12个控制访问参数(除params外),与request()完全一样
requests.head(url,**kwargs)
**kwargs:13个控制访问参数,与request()一样
requests.post(url,data=None,json=None,**kwargs)
**kwargs:除data,json外,与request()一样
requests.put(url,data=None,**kwargs)
**kwargs:除data外,与request()一样
requests.patch(url,data=None,**kwargs)
**kwargs:除data外,与request()一样
requests.delete(url,**kwargs)
**kwargs: 与request()一样
其实这6个方法都可以使用request()直接实现,不过每个要实现的操作都有经常使用的控制访问参数,那么这6个方式就是将经常使用的控制访问参数显式化
以上是关于http协议解析 请求行的信息怎么提取 c语言源码的主要内容,如果未能解决你的问题,请参考以下文章
Python网络爬虫与信息提取——HTTP协议及Requests库的方法
c语言构造http报文,实现输入一个网址,然后下载网页源码. 比如说输入www.baidu.com,最好是在linux环境下的.