java数据结构----哈希表
Posted 海的味道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java数据结构----哈希表相关的知识,希望对你有一定的参考价值。
1.哈希表:它是一种数据结构,可以提供快速的插入操作和查找操作。如果哈希表中有多少数据项,插入和删除操作只需要接近常量的时间。即O(1)的时间级。在计算机中如果需要一秒内查找上千条记录,通常使用哈希表。哈希表的速度明显比树快,编程实现也相对容易。但哈希表是基于数组的,数组创建后难于扩展。某些哈希表被填基本填满后性能下降的非常严重,所以程序员必须清除表中需要存储多少数据,而且也没有简便的方式以任意一种顺序(如由大到小)遍历表中的数据项,如果需要这种能力,只能选择其他数据结构。
2.哈希化:把关键字转化成数组下标的过程称为哈希化。在哈希表中这个转换通过哈希函数来完成。而对于特定的关键字,并不需要哈希函数,关键字的值可以直接作为数组下标。
3.冲突:把巨大的数字空间压缩成较小的数字空间必然要付出代价,即不能保证每个单词都映射到数组的空白单元。假设要在数组中插入单词cat,通过哈希函数得到它的数组下标后,发现那个单元已经有一个单词了,对于特定大小的数组,这种情况称为冲突。冲突使得哈希化的方案无法实施,解决的方案有两种,一种是通过系统的方法找到数组的一个空位,并把单词填入,而不再用哈希函数得到的下标,这种方法称为开放地址法,第二种方案是创建一个存放单词链表的数组,数组不直接用来存储单词,这样发生冲突时,新的数据项就直接插入这个数组下标所指向的链表中,这种方法称为链地址法。
3-1.开放地址法的具体实现有三种不同方案,线性探测,二次探测和再哈希法。
3-1-1.线性探测:在线性探测中,线性的查找空白单元,如果5421是要插入的数据位置,它已被占用,那么就使用5422,然后是5423,依次类推,直到找到这个空位。
3-1-1-1.存在的问题:会出现聚集情况。也叫原始聚集
3-1-2.二次探测:二次探测是防止聚集产生的一种尝试,思想是探测相隔较远的单元。而不知和原始单元相邻的单元。在二次探测中,探测的过程是x+1,x+4,x+9,x+16....
3-1-2-1.问题:存在二次聚集。
3-1-3.再哈希法:为了消除原始聚集和二次聚集,引入了再哈希法,二次聚集产生的原因是,二次探测的算法产生的探测序列步长总是固定的:1,4,9,16...现在需要一 种方法是依赖关键字的探测序列,方法是把关键字用相同的哈希函数再做一次哈希化,用这个结果作为步长,对指定的关键字步长在整个探测过程中是不变的,第二个哈希函数必须具备以下特点:a.和第一个哈希函数不同,b.不能输出0(否则就没有步长,将先入死循环)专家发现类似于stepsize = constant - (key % constant)的形式工作的很好,其中个constant是质数,且小于数组容量。(stepsize = 5 - (key % 5)),这种方案最为常用。
3-2.链地址法图示: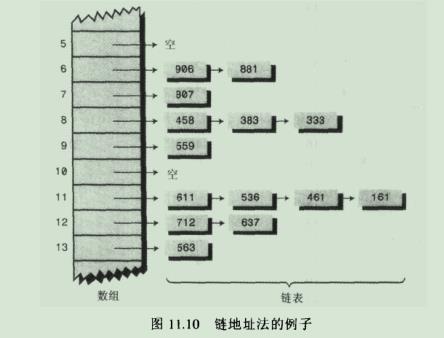
3-2-1.缺点:链地址法在概念上比开放地址法简单,但是代码可能要比其他的长,因为要包含链表机制,这就要求在程序中增加一个类。
4.再哈希法实现代码:
4.1.DataItem.java


1 package com.cn.hashtable; 2 /** 3 * 再哈希法 4 * @author Administrator 5 * 6 */ 7 public class DataItem { 8 private int iData; 9 public DataItem(int id){ 10 iData = id; 11 } 12 public int getkey(){ 13 return iData; 14 } 15 }
4.2.HashTable.java
1 package com.cn.hashtable; 2 /** 3 * 哈希表算法开放地址法---再哈希实现 4 * @author Administrator 5 * 6 */ 7 public class HashTable { 8 private DataItem[] hashArray; 9 private int arraySize; 10 private DataItem nonItem; 11 HashTable(int size){ 12 arraySize = size; 13 hashArray = new DataItem[arraySize]; 14 nonItem = new DataItem(-1); 15 } 16 public void displayTable(){ 17 System.out.print("Table:"); 18 for (int i = 0; i < arraySize; i++) { 19 if (hashArray[i] != null) 20 System.out.print(hashArray[i].getkey()+" "); 21 else 22 System.out.print("** "); 23 } 24 System.out.println(""); 25 } 26 public int hashFunc1(int key){ 27 return key % arraySize; 28 } 29 public int hashFunc2(int key){ 30 return 5 - key % 5; 31 } 32 public void insert(int key,DataItem item){ 33 int hashval = hashFunc1(key); 34 int stepsize = hashFunc2(key); 35 while (hashArray[hashval] != null && hashArray[hashval].getkey() != 1){ 36 hashval += stepsize; 37 hashval %= arraySize; 38 } 39 hashArray[hashval] = item; 40 } 41 public DataItem delete(int key){ 42 int hashval = hashFunc1(key); 43 int stepsize = hashFunc2(key); 44 while (hashArray[hashval] != null){ 45 if (hashArray[hashval].getkey() == key){ 46 DataItem temp = hashArray[hashval]; 47 hashArray[hashval] = nonItem; 48 return temp; 49 } 50 hashval += stepsize; 51 hashval %= arraySize; 52 } 53 return null; 54 } 55 public DataItem find(int key){ 56 int hashval = hashFunc1(key); 57 int stepsize = hashFunc2(key); 58 while (hashArray[hashval] != null){ 59 if (hashArray[hashval].getkey() == key) 60 return hashArray[hashval]; 61 hashval += stepsize; 62 hashval %= arraySize; 63 } 64 return null; 65 } 66 }
4.3.HTTest.java
1 package com.cn.hashtable; 2 /** 3 * 测试类 4 * @author Administrator 5 * 6 */ 7 public class HTTest { 8 public static void main(String[] args) { 9 HashTable t = new HashTable(10); 10 t.insert(1, new DataItem(1)); 11 t.insert(2, new DataItem(2)); 12 t.insert(4, new DataItem(3)); 13 t.insert(3, new DataItem(4)); 14 t.insert(2, new DataItem(5)); 15 t.insert(9, new DataItem(6)); 16 t.displayTable(); 17 t.delete(9); 18 System.out.println(t.find(9)); 19 } 20 }
5.链地址法实现:
5.1.Link.java
1 package com.cn.hashtable; 2 /** 3 * 链地址法实现 4 * @author Administrator 5 * 6 */ 7 public class Link { 8 public int iData; 9 public Link next; 10 public Link(int it){ 11 iData = it; 12 } 13 public int getkey(){ 14 return iData; 15 } 16 public void displayLink(){ 17 System.out.print(iData+" "); 18 } 19 }
5.2.SortedList.java
1 package com.cn.hashtable; 2 3 public class SortedList { 4 private Link first; 5 public void insert(Link thelink){ 6 int key = thelink.getkey(); 7 Link previous = null; 8 Link current = first; 9 while (current != null && key > current.getkey()){ 10 previous = current; 11 current = current.next; 12 } 13 if (previous == null) 14 first = thelink; 15 else 16 previous.next = thelink; 17 thelink.next = current; 18 } 19 public void delete(int key){ 20 Link previous = null; 21 Link current = first; 22 while (current != null && key != current.getkey()){ 23 previous = current; 24 current = current.next; 25 } 26 if (previous == null) 27 first = first.next; 28 else 29 previous.next = current.next; 30 } 31 public Link find(int key){ 32 Link current = first; 33 while (current != null && current.getkey() <= key){ 34 if (current.getkey() == key) 35 return current; 36 current = current.next; 37 } 38 return null; 39 } 40 public void displayList(){ 41 System.out.print("list:first-->last: "); 42 Link current = first; 43 while (current != null){ 44 current.displayLink(); 45 current = current.next; 46 } 47 System.out.println(""); 48 } 49 }
5.3.LHashTable.java
1 package com.cn.hashtable; 2 /** 3 * 链地址法实现哈希表类 4 * @author Administrator 5 * 6 */ 7 public class LHashTable { 8 private SortedList[] hashArray; 9 private int arraySize; 10 public LHashTable(int size){ 11 arraySize = size; 12 hashArray = new SortedList[arraySize]; 13 for (int i = 0; i < arraySize; i++) { 14 hashArray[i] = new SortedList(); 15 } 16 } 17 public void display(){ 18 for (int i = 0; i < arraySize; i++) { 19 System.out.print(i+". "); 20 hashArray[i].displayList(); 21 } 22 System.out.println(""); 23 } 24 public int hashFunc(int key){ 25 return key % arraySize; 26 } 27 public void insert(Link thelink){ 28 int key = thelink.getkey(); 29 int hashval = hashFunc(key); 30 hashArray[hashval].insert(thelink); 31 } 32 public void delete(int key){ 33 int hashval = hashFunc(key); 34 hashArray[hashval].delete(key); 35 } 36 public Link find(int key){ 37 int hashval = hashFunc(key); 38 Link thelink = hashArray[hashval].find(key); 39 return thelink; 40 } 41 }
5.4.LHTTest.java
1 package com.cn.hashtable; 2 /** 3 * 链地址法实现测试类 4 * @author Administrator 5 * 6 */ 7 public class LHTTest { 8 public static void main(String[] args) { 9 LHashTable lt = new LHashTable(10); 10 for (int i = 0; i < 5; i++) { 11 lt.insert(new Link(i)); 12 } 13 lt.display(); 14 } 15 }
6.哈希化的效率:在哈希表中执行插入和搜索操作可以达到O(1)的时间级,如果没有遇到冲突,就只需要使用一次哈希函数和数组的引用。这是最小的存取时间级。如果发生冲突,存取时间就依赖后边的探测长度。因此,一次的查找或插入操作与探测长度成正比,平均探测长度取决于装填因子(表中项数和表长的比率),随着填装因子变大,探测长度也越来越长。
6.1.线性探测时,探测序列(p)和填装因子(L)的关系:成功查找:P = (1 + 1/(1 - L)^2)/2;不成功查找:(1 + 1/(1 - L))/2,随着装填因子变小,存储效率下降而速度上升。
6.2.二次探测和再哈希法:对成功的搜索公式是:-log2(1 - loadfactor)/loadfactor;不成功的查找:1/(1-loadfactor)
6.3.假设哈希表含有arraySize个数据项,每个数据项有一个链表,在表中有N个数据项:averageListLength = N/arraySize;成功查找:1+loadfactor/2;不成功的查找:1+loadfactor
以上是关于java数据结构----哈希表的主要内容,如果未能解决你的问题,请参考以下文章