基于Hibernate-release 5.2.6 final.
所有演示代码在码云上的hellohibernate工程下:https://git.oschina.net/laideju/hellohibernate .
1. Hibernate开发步骤
(1). 创建持久化类;
(2). 创建对象-关系映射文件;
(3). 创建Hibernate配置文件;
(4). 通过Hibernate API编写访问数据库的代码。
1.1. 创建持久化类,该类必须是JavaBean风格的
> 具有无参的构造器
> 提供一个标识属性(ID),通常会被映射为数据库表的主键字段,如果没有该属性某些功能将不起作用
> 对需要持久化的属性提供getter/setter
> 使用非final类(在运行时生成代理是 Hibernate 的一个重要的功能,如果持久化类没有实现任何接口,Hibnernate 使用 CGLIB 生成代理,如果使用的是 final 类,则无法生成 CGLIB 代理)
> 重写 eqauls 和 hashCode 方法,如果需要把持久化类的实例放到Set中(当需要进行关联映射时),则应该重写这两个方法
1.2. 创建对象-关系映射文件
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN""http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><!-- Generated 2017-1-7 21:17:10 by Hibernate Tools 3.5.0.Final --><hibernate-mapping><class name="hellohibernate.helloword.News" table="NEWS"><id name="id" type="java.lang.Integer"><column name="ID" /><generator class="native" /></id><property name="title" type="java.lang.String"><column name="TITLE" /></property><property name="author" type="java.lang.String"><column name="AUTHOR" /></property><property name="date" type="timestamp"><column name="DATE" /></property></class></hibernate-mapping>
1.3. 创建Hibernate配置文件
该文件必须在类路径的根目录下,即在项目的src目录下,默认的文件名是:hibernate.cfg.xml。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"><hibernate-configuration><session-factory><!-- 配置数据库连接相关的信息 --><property name="connection.username">root</property><property name="connection.password">123</property><property name="connection.driver_class">com.mysql.jdbc.Driver</property><property name="connection.url">jdbc:mysql://localhost:3306/hellohibernate</property><!-- 配置hibernate的基本信息 --><!-- 配置数据库方言 --><property name="dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property><!-- 是否在控制台打印SQL --><property name="show_sql">true</property><!-- 是否格式化SQL --><property name="format_sql">true</property><!-- 指定自动生成数据表的策略 --><property name="hbm2ddl.auto">update</property><!-- 指定关联的对象-数据关系映射文件,.hbm.xml文件 --><mapping resource="hellohibernate/helloword/News.hbm.xml"/></session-factory></hibernate-configuration>
注意:在配置数据库方言时,如果使用MySQL5.1+版本,并且dialect设置为org.hibernate.dialect.MySQLInnoDBDialect,则会报 org.hibernate.exception.SQLGrammarException: could not execute statement 异常,生成的建表语句为:
Hibernate:create table NEWS (ID integer not null auto_increment,TITLE varchar(255),AUTHOR varchar(255),DATE datetime,primary key (ID)) type=InnoDB
这是因为type=InnoDB在5.0以前是可以使用的,但5.1之后就不行了。如果我们把type=InnoDB改为engine=InnoDB就不会有这个问题。对于使用Hibernate来说就是要把dialect设成 org.hibernate.dialect.MySQL5InnoDBDialect 即可。
1.4. 通过Hibernate API编写访问数据库的代码
//1. 创建一个 SessionFactory 对象SessionFactory sessionFactory = null;// configure方法默认Hibernate的配置文件是类根目录下的hibernate.cfg.xml文件StandardServiceRegistry registry = new StandardServiceRegistryBuilder().configure().build();sessionFactory = new MetadataSources(registry).buildMetadata().buildSessionFactory();//2. 创建一个Session对象Session session = sessionFactory.openSession();//3. 开启事务Transaction transaction = session.beginTransaction();//4. 执行保存操作News news = new News("Java", "ljy", new java.util.Date());session.save(news);//5. 提交事务transaction.commit();//6. 关闭Session对象session.close();//7. 关闭SessionFactory对象sessionFactory.close();
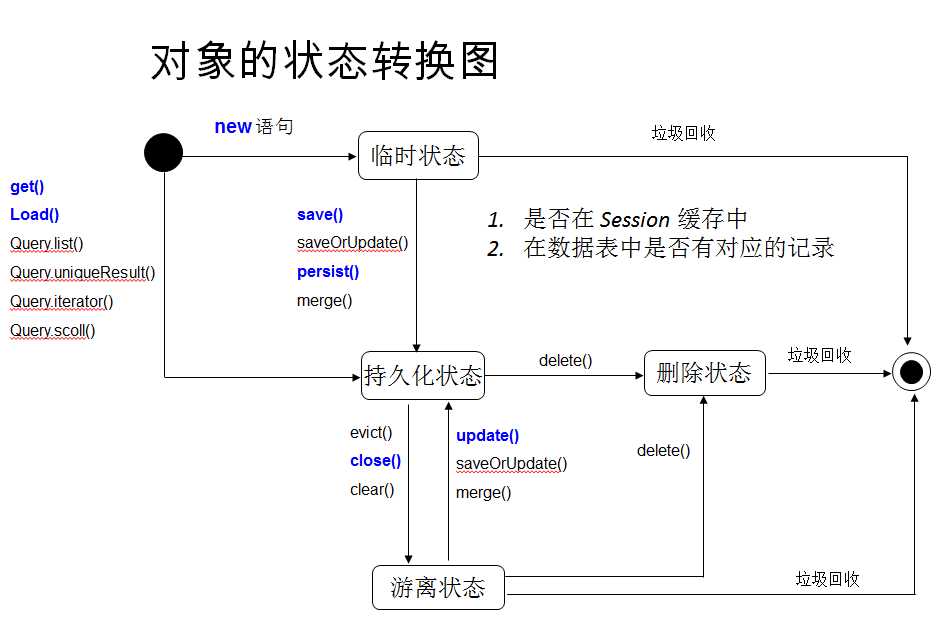
2. Hibernate中对象的四种状态
①. 临时对象(Transient)
> 在使用代理主键的情况下, OID 通常为 null
> 不处于 Session 的缓存中
> 在数据库中没有对应的记录
②. 持久化对象(Persist,也叫托管对象)
> OID 不为 null
> 位于 Session 缓存中
> 若在数据库中已经有和其对应的记录,持久化对象和数据库中的相关记录对应
> Session 在 flush 缓存时,会根据持久化对象的属性变化,来同步更新数据库
> 在同一个 Session 实例的缓存中,数据库表中的每条记录只对应唯一的持久化对象
③. 删除对象(Removed)
> 在数据库中没有和其 OID 对应的记录
> 不再处于 Session 缓存中
> 一般情况下, 应用程序不该再使用被删除的对象
④. 游离对象(Detached,也叫脱管)
> OID 不为 null
> 不再处于 Session 缓存中
> 一般情况需下,游离对象是由持久化对象转变过来的,因此在数据库中可能还存在与它对应的记录
只有持久化对象才可能在Hibernate的Session缓存中。
3. Hibernate的关键API
3.1. Session
(1). save,persist,saveOrUpdate
save()方法会:
> 使使一个临时对象变为持久化对象
> 为对象分配 ID
> 在 flush 缓存时会发送一条 INSERT 语句
> 在 save 方法之前的 id 是无效的
> 持久化对象的 ID 是不能被修改的!
persist():也会执行 INSERT 操作,和 save() 的区别: 在调用 persist 方法之前,若对象已经有 id 了,则不会执行 INSERT,而抛出异常!
saveOrUpdate():
> 若 OID 不为 null,但数据表中还没有和其对应的记录,则会抛出一个异常
> [了解] OID 值等于 id 的 unsaved-value 属性值的对象, 也被认为是一个游离对象
(2). update,merge
update():
> 若更新一个持久化对象,不需要显示的调用 update 方法,因为在调用Transaction的 commit() 方法时,会先执行 session 的 flush 方法.
> 更新一个游离对象,需要显式的调用 session 的 update 方法,可以把一个游离对象变为持久化对象.
> 若仅仅需要更新数据表中的某一列,需要在.hbm.xml文件中为 <class> 配置节指定 dynamic_upate="true" 属性.
需要注意的:
> 无论要更新的游离对象和数据表的记录是否一致,都会发送 UPDATE 语句。
如何能让 updat 方法不再盲目的出发 update 语句呢?
在 .hbm.xml 文件的 class 节点设置 select-before-update=true (默认为 false)。但通常不需要设置该属性。
> 若数据表中没有对应的记录,但还调用了 update 方法,会抛出异常。
> 当 update() 方法关联一个游离对象时,如果在 Session 的缓存中已经存在相同 OID 的持久化对象,则会抛出异常。 因为在 Session 缓存中不能有两个 OID 相同的对象!
(3). get,load
都是从数据表中加载一个记录到内存中,但有区别:
①. 执行 get 方法会立即加载对象。
执行 load 方法,若不使用该对象,则不会立即执行查询操作,而返回一个代理对象。
即:get 是 立即检索,load 是延迟检索。
②. load 方法可能会抛出 LazyInitializationException 异常,即在需要初始化代理对象之前已经关闭了 Session。
③. 若数据表中没有对应的记录,且Session 也没有被关闭,则
get 返回 null。
load 若不使用该对象则不会有问题,若需要使用该对象则会抛出异常。
(4).
delete:执行删除操作。
只要 OID 和数据表中一条记录对应,就会准备执行 delete 操作。
若 OID 在数据表中没有对应的记录,则抛出异常。
可以通过设置 hibernate 配置文件 hibernate.use_identifier_rollback 为 true,使删除对象后,把其 OID 置为 null。
flush:使数据表中的记录和 Session 缓存中的对象的状态保持一致。为了保持一致,则可能会发送对应的 SQL 语句。
> 在 Transaction 的 commit() 方法中,先调用 session 的 flush 方法,再提交事务。
> flush() 方法会可能会发送 SQL 语句,但不会提交事务。
注意,在未提交事务或显式的调用 session.flush() 方法之前,也有可能会进行 flush() 操作:
> 执行 HQL 或 QBC 查询,会先进行 flush() 操作,以得到数据表的最新的记录。
> 若记录的 ID 是由底层数据库使用自增的方式生成的,则在调用 save() 方法时,
就会立即发送 INSERT 语句,因为 save 方法后,必须保证对象的 ID 是存在的。
refresh:会强制发送 SELECT 语句,以使 Session 缓存中对象的状态和数据表中对应的记录保持一致。
clear:清理缓存。
evict:从 Session 缓存中把指定的持久化对象移除。
(5). 通过Session获取JDBC原生的Connection对象
public void testDoWork(){session.doWork(new Work() {@Overridepublic void execute(Connection connection) throws SQLException {// connection 即是JDBC原生的连接对象}});}
3.2. Transaction 事务
(1). 常用方法
commit():提交相关联的session实例
rollback():撤销事务操作
wasCommitted():检查事务是否提交
(2). commit 与 flush 的区别
单纯的flush并不会立刻写入数据库,而commit时会立刻写库。
4. 为 Hibernate 配置 C3P0 数据源
先导jar包,再配置。
将 hibernate-release-5.2.6.Final\\lib\\optional\\c3p0 目录下的 jar 包添加到项目中去。
再在 Hibernate 的配置文件(默认下是 hibernate.cfg.xml )中的 <session-factory> 配置节下添加如下子配置节。
<!-- 数据库连接池的最大连接数 --><property name="hibernate.c3p0.max_size">10</property><!-- 数据库连接池的最小连接数 --><property name="hibernate.c3p0.min_size">5</property><!-- 当连接池中的连接耗尽时,向数据库申请连接的数量 --><property name="c3p0.acquire_increment">2</property><!-- 连接池检测池中连接是否已超时的时间间隔 --><property name="c3p0.idle_test_period">2000</property><!-- 池中连接允许空闲的最长时间,超时后会被销毁 --><property name="c3p0.timeout">2000</property><!-- 允许缓存 Statement 对象的最大数量 --><property name="c3p0.max_statements">10</property>
即可完成 c3p0 的配置,更多的配置可以参考 hibernate 的文档。需要注意的是 c3p0.idle_test_period 配置项,连接池会有一个专门的线程按照一定的时间间隔(即由这个配置项配置的时间间隔)来检测池中各个连接是否已达到空闲的最大时间,进而决定是否销毁连接。
另外还可以进行一些数据库相关的配置:
<!-- 设定 JDBC 的 Statement 读取数据的时, 每次从数据库中取出的记录条数 --><property name="hibernate.jdbc.fetch_size">100</property><!-- 设定对数据库进行批量删除/更新/插入时, 批量的大小 --><property name="jdbc.batch_size">30</property>
5. 对象-关系映射文件
即 .hbm.xml 文件,其结构如下。
------------------------------------------BEGIN------------------------------------------
- hibernate-mapping
- 类层次:class
- 主键: id
- generator
- 基本类型: property
- 实体引用类: many-to-one | one-to-one
- 集合: set | list | map | array
- one-to-many
- many-to-many
- 子类: subclass | joined-subclass
- 其它: component | any 等
- 查询语句:query(用来放置查询语句,便于对数据库查询的统一管理和优化)
-------------------------------------------END-------------------------------------------
每个 Hibernate-mapping 中可以同时定义多个类,但更推荐为每个类都创建一个单独的映射文件。
5.1. hibernate-mapping
hibernate-mapping 是 hibernate 映射文件的根元素, 它具有如下属性。

schema:指定所映射的数据库 schema 的名称。若指定该属性,则表明会自动添加该 schema 前缀
catalog:指定所映射的数据库 catalog 的名称。
default-cascade(默认为 none):设置 hibernate 默认的级联风格。若配置 Java 属性,集合映射时没有指定 cascade 属性,则 Hibernate 将采用此处指定的级联风格。
default-access (默认为 property):指定 Hibernate 的默认的属性访问策略。默认值为 property,即使用 getter,setter 方法来访问属性。若指定 access,则 Hibernate 会忽略 getter/setter 方法,而通过反射访问成员变量。
default-lazy(默认为 true):设置 Hibernat morning 的延迟加载策略。该属性的默认值为 true,即启用延迟加载策略。若配置 Java 属性映射, 集合映射时没有指定 lazy 属性,则 Hibernate 将采用此处指定的延迟加载策略。
auto-import (默认为 true):指定是否可以在查询语言中使用非全限定的类名(仅限于本映射文件中的类)。
package (可选):指定一个包前缀,如果在映射文档中没有指定全限定的类名,就使用这个作为包名。
5.2. class
class 元素用于指定类和表的映射,它具有如下属性。

name:指定该持久化类映射的持久化类的类名。
table:指定该持久化类映射的表名,Hibernate 默认以持久化类的类名作为表名。
dynamic-insert:若设置为 true,表示当保存一个对象时,会动态生成 insert 语句,insert 语句中仅包含所有取值不为 null 的字段。默认值为 false 。
dynamic-update:若设置为 true,表示当更新一个对象时,会动态生成 update 语句,update 语句中仅包含所有取值需要更新的字段。默认值为 false 。
select-before-update:设置 Hibernate 在更新某个持久化对象之前是否需要先执行一次查询。默认值为 false 。
batch-size:指定根据 OID 来抓取实例时每批抓取的实例数。
lazy:指定是否使用延迟加载。
mutable:若设置为 true,等价于所有的 <property> 元素的 update 属性为 false,表示整个实例不能被更新。默认为 true。
discriminator-value:指定区分不同子类的值。当使用 <subclass/> 元素来定义持久化类的继承关系时需要使用该属性。
5.3. id
id 设定持久化类的 OID 和表的主键的映射。

name:标识持久化类 OID 的属性名。
column:设置标识属性所映射的数据表的列名(主键字段的名字)。
unsaved-value:若设定了该属性,Hibernate 会通过比较持久化类的 OID 值和该属性值来区分当前持久化类的对象是否为临时对象。
type:指定 Hibernate 映射类型。
Hibernate 映射类型是 Java 类型与 SQL 类型的桥梁。如果没有为某个属性显式设定映射类型,Hibernate 会运用反射机制先识别出持久化类的特定属性的 Java 类型,然后自动使用与之对应的默认的 Hibernate 映射类型。
Java 的基本数据类型和包装类型对应相同的 Hibernate 映射类型。基本数据类型无法表达 null,所以对于持久化类的 OID 推荐使用包装类型。
5.3.1. generator
设定持久化类设定标识符生成器。

class:指定使用的标识符生成器全限定类名或其缩写名。通常取用“native”。
5.4. Property
用于指定类的属性和表的字段的映射。

name:指定该持久化类的属性的名字。
column:指定与类的属性映射的表的字段名。如果没有设置该属性,Hibernate 将直接使用类的属性名作为字段名。
type:指定 Hibernate 映射类型。Hibernate 映射类型是 Java 类型与 SQL 类型的桥梁。如果没有为某个属性显式设定映射类型,Hibernate 会运用反射机制先识别出持久化类的特定属性的 Java 类型,然后自动使用与之对应的默认的 Hibernate 映射类型。
not-null:若该属性值为 true,表明不允许为 null,默认为 false 。
access:指定 Hibernate 的默认的属性访问策略。默认值为 property,即使用 getter,setter 方法来访问属性。若指定 field,则 Hibernate 会忽略 getter/setter 方法,而通过反射访问成员变量。
unique: 设置是否为该属性所映射的数据列添加唯一约束。
index: 指定一个字符串的索引名称。当系统需要 Hibernate 自动建表时,用于为该属性所映射的数据列创建索引,从而加快该数据列的查询。
length: 指定该属性所映射数据列的字段的长度。
scale: 指定该属性所映射数据列的小数位数,对 double,float,decimal 等类型的数据列有效。
formula:设置一个 SQL 表达式,Hibernate 将根据它来计算出派生属性的值。
派生属性: 并不是持久化类的所有属性都直接和表的字段匹配,持久化类的有些属性的值必须在运行时通过计算才能得出来,这种属性称为派生属性。
使用 formula 属性时:
> formula=“(sql)” 的英文括号不能少
> Sql 表达式中的列名和表名都应该和数据库对应,而不是和持久化对象的属性对应
> 如果需要在 formula 属性中使用参数,这直接使用 where cur.id=id 形式,其中 id 就
是参数,和当前持久化对象的 id 属性对应的列的 id 值将作为参数传入。
6. 日期时间类型映射
在 Java 中,代表时间和日期的类型包括:java.util.Date 和 java.util.Calendar。此外, 在 JDBC API 中还提供了 3 个扩展了 java.util.Date 类的子类:java.sql.Date、java.sql.Time 和 java.sql.Timestamp,这三个类分别和标准 SQL 类型中的 DATE、TIME 和 TIMESTAMP 类型对应。
因为 java.util.Date 是 java.sql.Date、java.sql.Time 和 java.sql.Timestamp 的父类,所以 java.util.Date可以对应标准 SQL 类型中的 DATE、TIME 和 TIMESTAMP。基于此,在设置持久化类时,应将其 Date 类型属性设置为 java.util.Date。
可以通过 property 的 type 属性来进行精准映射,例如:
<property name="date" type="timestamp"><column name="DATE" /></property><property name="date" type="data"><column name="DATE" /></property><property name="date" type="time"><column name="DATE" /></property>
其中 timestamp,date,time 既不是 Java 类型,也不是标准 SQL 类型,而是 hibernate 映射类型。
7. Java 大对象类型的 Hiberante 映射
在 Java 中,java.lang.String 可用于表示长字符串(长度超过 255),字节数组 byte[] 可用于存放图片或文件的二进制数据。
此外,在 JDBC API 中还提供了 java.sql.Clob 和 java.sql.Blob 类型,它们分别和标准 SQL 中的 CLOB 和 BLOB 类型对应。
CLOB 表示字符串大对象(Character Large Object),BLOB表示二进制对象(Binary Large Object)。
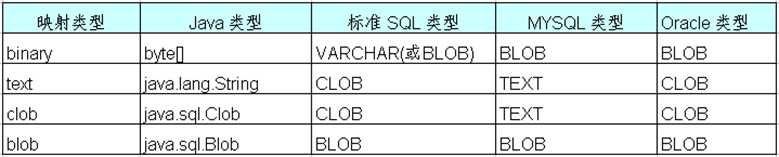
Mysql 不支持标准 SQL 的 CLOB 类型,在 Mysql 中,用 TEXT、MEDIUMTEXT 及 LONGTEXT 类型来表示长度操作 255 的长文本数据。
在持久化类中,二进制大对象可以声明为 byte[] 或 java.sql.Blob 类型;字符串可以声明为 java.lang.String 或 java.sql.Clob 。
实际上在 Java 应用程序中处理长度超过 255 的字符串,使用 java.lang.String 比 java.sql.Clob 更方便。
8. 映射组成关系
Hibernate 把持久化类的属性分为两种:
①. 值(value)类型,即没有 OID,不能被单独持久化,生命周期依赖于所属的持久化类的对象的生命周期;
②. 实体(entity)类型,即有 OID,可以被单独持久化,有独立的生命周期。
Hibernate 在对象-关系映射文件中使用 <component> 元素来映射组成关系,称之为组件。示例如下。
Worker实体类
package hellohibernate.helloword;public class Worker {private Integer id;private String name;private Pay pay;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Pay getPay() {return pay;}public void setPay(Pay pay) {this.pay = pay;}}
Pay实体类
package hellohibernate.helloword;public class Pay {private int monthlyPay;private int yearPay;private int vocationWithPay;private Worker worker;public Worker getWorker() {return worker;}public void setWorker(Worker worker) {this.worker = worker;}public int getMonthlyPay() {return monthlyPay;}public void setMonthlyPay(int monthlyPay) {this.monthlyPay = monthlyPay;}public int getYearPay() {return yearPay;}public void setYearPay(int yearPay) {this.yearPay = yearPay;}public int getVocationWithPay() {return vocationWithPay;}public void setVocationWithPay(int vocationWithPay) {this.vocationWithPay = vocationWithPay;}}
Worker的对象-关系映射文件(由于Pay是值类型,没有OID,所以没有它的映射文件)
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN""http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><hibernate-mapping package="hellohibernate.helloword"><class name="Worker" table="WORKERS"><id name="id" type="java.lang.Integer"><column name="ID" /><generator class="native" /></id><property name="name" type="java.lang.String"><column name="NAME" /></property><!-- 映射组成关系 --><component name="pay" class="Pay"><parent name="worker"/><property name="monthlyPay"></property><property name="yearPay"></property><property name="vocationWithPay"></property></component></class></hibernate-mapping>
9. 映射关联关系
关联关系总的说来有一对一、一对多和多对多几种关系,细分起来又有单向和双向之分。
9.1. 映射1-n关联关系
细分起来,可以分为单向一对多、单向多对一、双向一对多(双向多对一)三种。
9.1.1. 单向一对多(1-n)
注意:这种映射模式在实践中并不推荐!
域模型:1端持有n端对象的集合,n端对象不含有1端对象的引用。
映射方向:从1端追溯到n端。
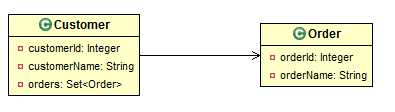
关系数据库模型:hibernate会自动在n端对应的数据表中引用1端对应的数据表,即以1端数据表的主键作为n端数据表的外键。
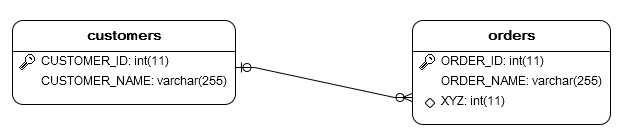
hbm文件配置说明:
(1). 1端对应的配置文件中使用<set>标签,该标签包含几个重要的属性:
name,1端对象中包含n端对象集合的属性的名字;
table,n端对象对应的数据表名字(可不指定,因为可以通过<set>的子标签<one-to-many>来指定n端对应的持久化类,通过其对应的hbm文件可以找到对应的数据表)。
(2). <set>标签还包含两个重要的子标签:
<one-to-many class=[classNameWithPackage]>,指定n端持久化类的全类名。
<key column="[foreignKeyName]">,指定n端对应的数据表中引用1端数据表的外键的名称;
(3). n端对应的配置文件不需作特殊的配置。
配置实例如下:
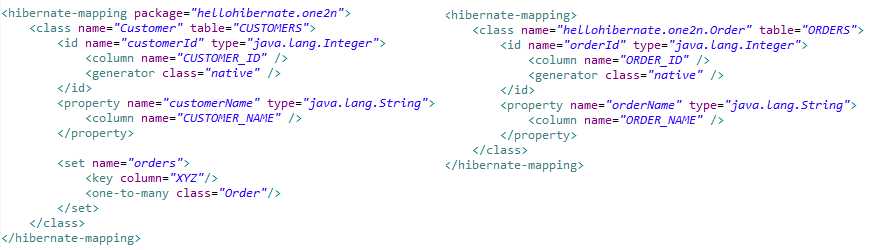
9.1.2. 单向多对一(n-1)
模型:n端持久化类中包含1端对象的引用,而1端不含n端的引用。
映射方向:从n端对象追溯到1端对象。
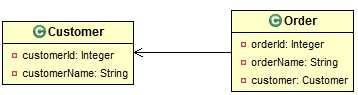
关系数据模型:hibernate会自动在n端对应的数据表中引用1端对应的数据表,即以1端数据表的主键作为n端数据表的外键。(同1-n)
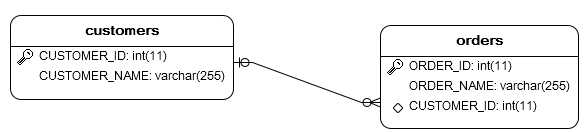
hbm文件配置说明:
(1). n端对应的配置文件中使用<many-to-one>标签,该标签包含几个重要属性:
name,指定n端持久化类中引用的1端对象的实例名称;
class,指定被n端引用的1端对应的持久化类的全类名;
column,指定n端对应的数据表参考的1端对应的数据表的外键的列名。
(2). 1端对应的配置文件不需作任何特殊配置。
配置实例:

9.1.3. 映射双向一对多、多对一关联关系
双向 1-n 与 双向 n-1 是完全相同的两种情形。域模型:1端含有n端的集合的属性,n端含有1端的一个引用。映射方向:既可以从n端追溯到1端,也可以从1端追溯到n端。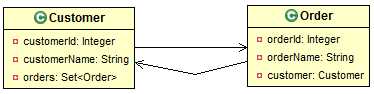
关系数据库模型:n端对应的数据表包含一个外键列,其参考的外键即是1端对应的数据表的主键。(同1-n)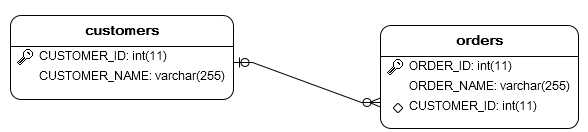
hbm文件配置说明:
(1). 1端使用<set>标签,配置同单向1-n(2). n端使用<many-to-one>标签,配置同单向n-1配置实例:
9.1.4. 需要注意的小点
9.1.3. 映射双向一对多、多对一关联关系
9.1.4. 需要注意的小点
(1). 关联关系中的两方在保存持久化对象时的先后顺序对生成的SQL语句的影响。
@Testpublic void testMany2OneSave(){Customer customer = new Customer();customer.setCustomerName("BB");Order order1 = new Order();order1.setOrderName("ORDER-3");Order order2 = new Order();order2.setOrderName("ORDER-4");//设定关联关系order1.setCustomer(customer);order2.setCustomer(customer);//执行 save 操作: 先插入 Customer, 再插入 Order, 3 条 INSERT//先插入 1 的一端, 再插入 n 的一端, 只有 INSERT 语句.// session.save(customer);// session.save(order1);// session.save(order2);//先插入 Order, 再插入 Customer. 3 条 INSERT, 2 条 UPDATE//先插入 n 的一端, 再插入 1 的一端, 会多出 UPDATE 语句!//因为在插入多的一端时, 无法确定 1 的一端的外键值. 所以只能等 1 的一端插入后, 再额外发送 UPDATE 语句.//推荐先插入 1 的一端, 后插入 n 的一端session.save(order1);session.save(order2);session.save(customer);}
(2). 若查询n端的一个对象,则默认情况下,只查询了n端的对象,而没有查询关联的1那一端的对象。
@Testpublic void testManyToOneGet(){//1. 若查询多n端的一个对象, 则默认情况下, 只查询了n端的对象. 而没有查询关联的1那一端的对象!Order order = session.get(Order.class, 1);System.out.println(order.getOrderName());System.out.println(order.getCustomer().getClass().getName());//3. 在查询 Customer 对象时, 由多的一端导航到 1 的一端时,//若此时 session 已被关闭, 则默认情况下会发生 LazyInitializationException 异常// session.close();Customer customer = order.getCustomer();//2. 在需要使用到关联的对象时, 才发送对应的 SQL 语句.System.out.println(customer.getCustomerName());}
(3). 在不设定级联关系的情况下,且 1 这一端的对象有 n 端的对象在引用,则不能直接删除 1 这一端的对象。
@Testpublic void testDelete(){Customer customer = session.get(Customer.class, 1);// 在不设定级联关系的情况下,且 1 这一端的对象有 n 端的对象在引用,- // 则不能直接删除 1 这一端的对象,否则会引发
// org.hibernate.exception.ConstraintViolationException 异常session.delete(customer);}
(4). 在1端持久化类中声明n端的集合的属性时,集合类型需用接口类型。因为hibernate在获取集合类型时,返回的是hibernate内置的集合类型而不是JavaSE的标准集合实现类型。需要对该集合属性进行初始化,避免发生空引用异常。
9.2. 映射一对一(1-1)关联关系
9.2.1. 单向一对一
域模型:一方(称为关系发起方)拥有另一方(称为关系的接收方)的一个引用,接收方并不持有发起方的引用。
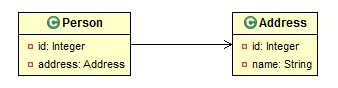
映射方向:仅可以从拥有方追溯到对方。
关系数据库模型:
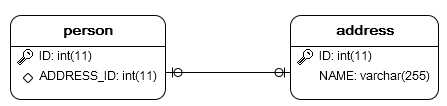
hbm文件配置说明:
(1). 关系发起方使用<many-to-one>标签,配置同n-1,且还需设置“unique=true”属性;
(2). 关系接收方不作任何特殊配置。
配置实例:

9.2.2. 双向一对一
域模型:双方都持有对方的一个引用。
映射方向:可以从任何一方追溯到对方。
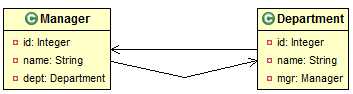
关系数据库模型:
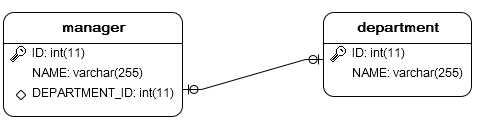
hbm文件配置说明:
(1). 一方使用<many-to-one>标签,配置同单向一对一;
(2). 另外一方使用<one-to-one>标签,需设置property-ref属性,该属性的值为被关联的一方所持有的对方的实例引用。
配置实例:
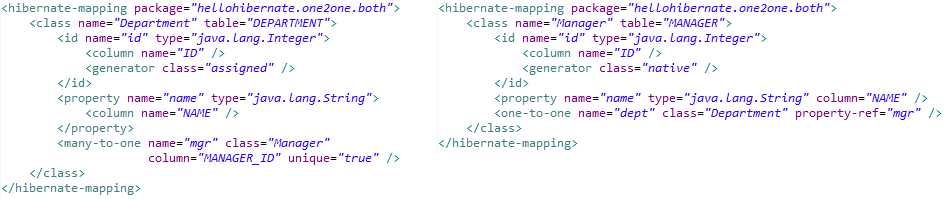
9.2.3. 基于主键映射的1-1关联关系
基于主键的映射策略,指一端的主键生成器使用 foreign 策略,表明根据“对方”的主键来生成自己的主键,自己并不能独立生成主键。
<param> 子元素指定使用当前持久化类的哪个属性作为“对方”,以便将“对方”的主键作为自身的主键。
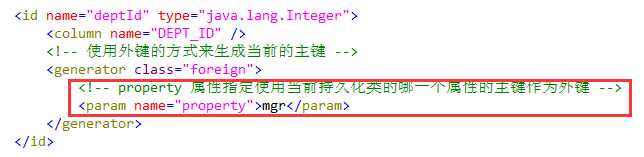
采用foreign主键生成器策略的一端增加 one-to-one 元素映射关联属性,其 one-to-one 属性还应增加 constrained=“true” 属性;另一端增加one-to-one元素映射关联属性。

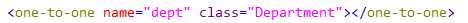
constrained(约束):指定为当前持久化类对应的数据库表的主键添加一个外键约束,引用被关联的对象(“对方”)所对应的数据库表主键。
9.3. 映射多对多(n-n)关联关系
9.3.1. 单向n-n
域模型:
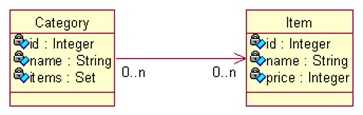
关系数据库模型:
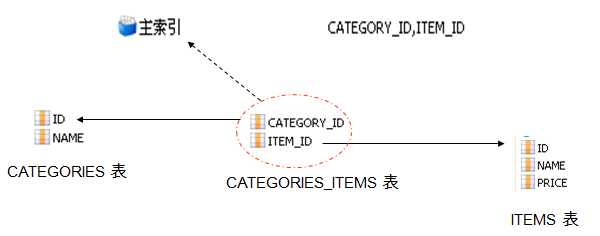
n-n 的关联必须使用连接表。
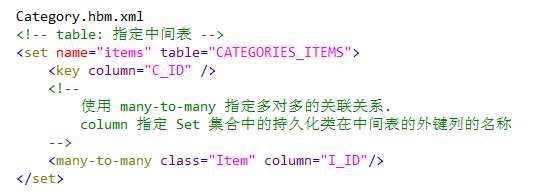
与 1-n 映射类似,必须为 set 集合元素添加 key 子元素,指定 CATEGORIES_ITEMS 表中参照 CATEGORIES 表的外键为 CATEGORIY_ID。
与 1-n 关联映射不同的是,建立 n-n 关联时,集合中的元素使用 many-to-many。
many-to-many 子元素的 class 属性指定 items 集合中存放的是 Item 对象,column 属性指定 CATEGORIES_ITEMS 表中参照 ITEMS 表的外键为 ITEM_ID 。

9.3.2. 双向n-n
域模型:
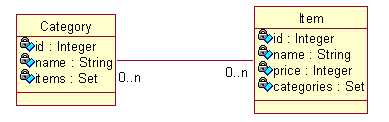
关系数据库模型:
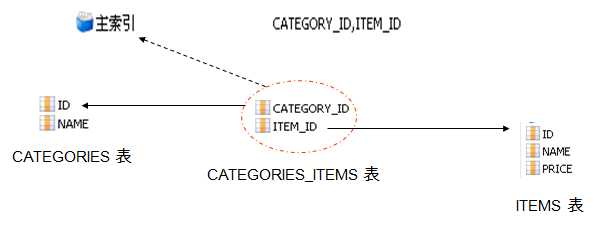
双向 n-n 关联需要两端都使用集合属性。
双向n-n关联必须使用连接表。
集合属性应增加 key 子元素用以映射外键列,集合元素里还应增加many-to-many子元素关联实体类。
在双向 n-n 关联的两边都需指定连接表的表名及外键列的列名。两个集合元素 set 的 table 元素的值必须指定,而且必须相同。set元素的两个子元素:key 和 many-to-many 都必须指定 column 属性,其中,key 和 many-to-many 分别指定本持久化类和关联类在连接表中的外键列名,因此两边的 key 与 many-to-many 的column属性交叉相同。也就是说,一边的set元素的key的 cloumn值为a,many-to-many 的 column 为b;则另一边的 set 元素的 key 的 column 值 b,many-to-many的 column 值为 a。
对于双向 n-n 关联,必须把其中一端的 inverse 设置为 true,否则两端都维护关联关系可能会造成主键冲突。

10. 映射继承关系
Hibernate支持三种继承映射策略:
(1)使用 subclass 进行映射:将域模型中的每一个实体对象映射到一个独立的表中,也就是说不用在关系数据模型中考虑域模型中的继承关系和多态。
(2)使用 joined-subclass 进行映射:对于继承关系中的子类使用同一个表,这就需要在数据库表中增加额外的区分子类类型的字段。
(3)使用 union-subclass 进行映射:域模型中的每个类映射到一个表,通过关系数据模型中的外键来描述表之间的继承关系。这也就相当于按照域模型的结构来建立数据库中的表,并通过外键来建立表之间的继承关系。
10.1. 使用 subclass 进行映射
采用 subclass 的继承映射可以实现对于继承关系中父类和子类使用同一张表。因为父类和子类的实例全部保存在同一个表中,因此需要在该表内增加一列,使用该列来区分每行记录到低是哪个类的实例——这个列被称为辨别者列(discriminator)。
在这种映射策略下,使用 <class> 或 <subclass> 的 discriminator-value 属性指定辨别者列的值。
所有子类定义的字段都不能有非空约束。如果为那些字段添加非空约束,那么父类的实例在那些列其实并没有值,这将引起数据库完整性冲突,导致父类的实例无法保存到数据库中。
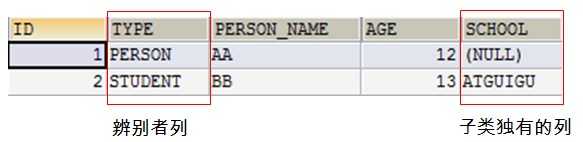
实例如下,POJO:
public class Person {private Integer id;private String name;private int age;//...}public class Student extends Person{private String school;//...}
.hbm.xml文件:
<hibernate-mapping package="hellohibernate.subclass"><class name="Person" table="PERSON" discriminator-value="PERSON"><id name="id" type="java.lang.Integer"><column name="ID" /><generator class="native" /></id><!-- 配置辨别者列,该配置应在其它property配置之前 --><discriminator column="TYPE" type="string" /><property name="name" type="java.lang.String"><column name="NAME" /></property><property name="age" type="int"><column name="AGE" /></property><!-- 映射子类 Student, 使用 subclass 进行映射 --><subclass name="Student" discriminator-value="STUDENT"><property name="school" column="SCHOOL" type="java.lang.String"></property></subclass></class></hibernate-mapping>
10.2. 使用 joined-subclass 元素的继承映射
采用 joined-subclass 元素的继承映射可以实现每个子类一张表。
采用这种映射策略时,父类实例保存在父类表中,子类实例由父类表和子类表共同存储。因为子类实例也是一个特殊的父类实例,因此必然也包含了父类实例的属性。于是将子类和父类共有的属性保存在父类表中,子类增加的属性,则保存在子类表中。
在这种映射策略下,无须使用鉴别者列,但需要为每个子类使用 key 元素映射共有主键。
子类增加的属性可以添加非空约束。因为子类的属性和父类的属性没有保存在同一个表中。

实例如下,POJO:
public class Person {private Integer id;private String name;private int age;//...}public class Student extends Person{private String school;//...}
.hbm.xml文件:
<hibernate-mapping package="hellohibernate.subclass.joined"><class name="Person" table="PERSON"><id name="id" type="java.lang.Integer"><column name="ID" /><generator class="native" /></id><property name="name" type="java.lang.String"><column name="NAME" /></property><property name="age" type="int"><column name="AGE" /></property><joined-subclass name="Student" table="STUDENT"><key column="STUDENTID"/><property name="school" type="java.lang.String" column="SCHOOL"/></joined-subclass></class></hibernate-mapping>
10.3. 采用 union-subclass 元素的继承映射
采用 union-subclass 元素可以实现将每一个实体对象映射到一个独立的表中。
子类增加的属性可以有非空约束 --- 即父类实例的数据保存在父表中,而子类实例的数据保存在子类表中。
子类实例的数据仅保存在子类表中,而在父类表中没有任何记录。
在这种映射策略下,子类表的字段会比父类表的映射字段要多,因为子类表的字段等于父类表的字段加子类增加属性的总和。
在这种映射策略下,既不需要使用鉴别者列,也无须使用 key 元素来映射共有主键。
使用 union-subclass 映射策略是不可使用 identity 的主键生成策略,因为同一类继承层次中所有实体类都需要使用同一个主键种子,即多个持久化实体对应的记录的主键应该是连续的。受此影响,也不该使用 native 主键生成策略,因为 native 会根据数据库来选择使用 identity 或 sequence。

实例如下,POJO:
public class Person {//因为要使用uuid主键生成策略,所以要改成字符串类型private String id;private String name;private int age;//...}public class Student extends Person{private String school;//...}
.hbm.xml文件:
<hibernate-mapping package="hellohibernate.subclass.union"><class name="Person" table="PERSON"><id name="id" type="java.lang.Integer"><column name="ID" /><!-- 注意主键的生成策略 --><generator class="uuid" /></id><property name="name" type="java.lang.String"><column name="NAME" /></property><property name="age" type="int"><column name="AGE" /></property><union-subclass name="Student" table="STUDENT"><property name="school" column="SCHOOL" type="java.lang.String"/></union-subclass></class></hibernate-mapping>
10.4. 三种继承映射方式的比较

11.Hibernate 检索策略
检索数据时的 2 个问题:
(1)不浪费内存:当 Hibernate 从数据库中加载 Customer 对象时,如果同时加载所有关联的 Order 对象,而程序实际上仅仅需要访问 Customer 对象,那么这些关联的 Order 对象就白白浪费了许多内存。
(2)更高的查询效率:发送尽可能少的 SQL 语句。
Hibernate的检索策略包含三种:立即检索、延迟检索、迫切左外连接检索。而其作用域包括类级别和关联级别,总结如下表所示:
| 检索策略的作用域 | 可选的检索策略 | 默认的检索策略 | 运行时行为受影响的Session的检索方法 |
| 类级别 | 立即检索 延迟检索 | 立即检索 | 仅影响load方法 |
| 关联级别 | 立即检索 延迟检索 迫切左外连接检索 | n-1和1-1关联为迫切左外连接检索 1-n和n-n关联为立即检索 | 影响load、get和find方法 |
迫切左外链接:使用左外链接进行查询,且把集合属性进行初始化。优点在于比立即检索策略使用的 SELECT 语句更少。
三种检索策略的运行机制:
| 检索策略类型 | 类级别 | 关联级别 |
| 立即检索 | 立即加载检索方法指定的对象 | 立即加载与检索方法指定的对象关联的对象 |
| 延迟检索 | 延迟加载检索方法指定的对象 | 延迟加载与检索方法指定的对象关联的对象 |
| 迫切左外连接检索 | 不适用 | 使用左外链接进行查询并加载与检索方法指定的对象关联的对象 |
lazy、fetch、batch-size属性的影响:
| 类级别 | 一对多关联级别(set标签) | 多对多关联级别(many-to-one标签) | |
| lazy | true(默认):延迟检索 false:立即检索 | true(默认):延迟检索 extra①:增强的延迟检索 false:立即检索 | proxy(默认):延迟检索 no-proxy④:无代理延迟检索 false:立即检索 |
| fetch | 没有此属性 | select(默认):使用select查询语句 subselect②:使用带子查询的select查询语句 join③:使用迫切左外连接检索 | select(默认):使用select查询语句 join③:使用迫切左外连接检索 |
| batch-size | 设定批量检索的数量。可选值为一个正整数,默认值为1,合理取值为[3, 10]。仅适用于立即检索和延迟检索,仅可在<set>和 <class>标签中设置。 | ||
①. 增强的延迟检索:尽可能延迟对象的集合的初始化时机。比如在使用聚合函数(min、max、avg、count等)时,该策略不会对集合进行初始化,而延迟检索会立即初始化集合。而当程序第一次(显式或隐式的)访问集合的iterator()时,才对集合进行初始化。
②. 对于<set>,当fetch=subselect时,将忽略batch-size的设置。
③. 对于<set>,当fetch=join时,将忽略lazy的设置。HQL的查询会忽略fetch=join的设置。
④. 无代理延迟检索需要增强持久化类的字节码才能实现。
12. Hibernate检索方式 Hibernate 提供了以下几种检索对象的方式:- 导航对象图检索方式: 根据已经加载的对象导航到其他对象;
- OID 检索方式:按照对象的 OID 来检索对象;
- HQL 检索方式:使用面向对象的 HQL 查询语言;
- QBC 检索方式:使用 QBC(Query By Criteria)API 来检索对象,这种 API 封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口;
- 本地 SQL 检索方式:使用本地数据库的 SQL 查询语句。
本节中涉及到的持久化类如下图所示: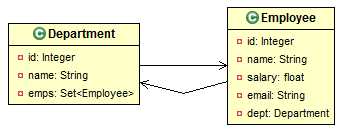
12.1. HQL检索方式
HQL 检索方式包括以下步骤:(1). 通过 Session 的 createQuery() 方法创建一个 Query 对象,它包括一个 HQL 查询语句,HQL 查询语句中可以包含命名参数。 注意:HQL中看似是表名的位置其实不是表名,而是持久化类名,例如
“from Employee e where e.salary > :minSal and e.salary < :maxSal” 中 Employee 是持久化类名而非SQL中的的表名。
(2). 动态绑定参数: 按参数名字绑定,在 HQL 查询语句中定义命名参数,命名参数以 “:” 开头;
Hibernate 提供了以下几种检索对象的方式:
- 导航对象图检索方式: 根据已经加载的对象导航到其他对象;
- OID 检索方式:按照对象的 OID 来检索对象;
- HQL 检索方式:使用面向对象的 HQL 查询语言;
- QBC 检索方式:使用 QBC(Query By Criteria)API 来检索对象,这种 API 封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口;
- 本地 SQL 检索方式:使用本地数据库的 SQL 查询语句。
本节中涉及到的持久化类如下图所示:
12.1. HQL检索方式
HQL 检索方式包括以下步骤:
(1). 通过 Session 的 createQuery() 方法创建一个 Query 对象,它包括一个 HQL 查询语句,HQL 查询语句中可以包含命名参数。
注意:HQL中看似是表名的位置其实不是表名,而是持久化类名,例如
“from Employee e where e.salary > :minSal and e.salary < :maxSal”
中 Employee 是持久化类名而非SQL中的的表名。
(2). 动态绑定参数:
按参数名字绑定,在 HQL 查询语句中定义命名参数,命名参数以 “:” 开头;
按参数位置绑定,在 HQL 查询语句中用 “?” 来定义参数位置。
(3). 调用 Query 相关方法执行查询语句。
Qurey 接口支持方法链编程风格,它的 setXxx() 方法返回自身实例,而不是 void 类型。
HQL vs SQL:HQL 查询语句中的主体是域模型中的类及类的属性;SQL 查询语句中的主体是数据库表及表的字段。
12.1.1. 在映射文件(hbm文件)中定义命名查询语句
(1). <query> 元素用于定义一个 HQL 查询语句,它和 <class> 元素并列:
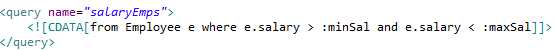
它可以放在同包下的任意一个.hbm.xml文件中。
(2). 在程序中通过 Session 的 getNamedQuery() 方法获取查询语句对应的 Query 对象,该方法的参数即是<query>标签的name属性的值。
12.1.2. 常用查询
(1). 分页查询
setFirstResult(int firstResult): 设定检索的起始位置(从0开始计)。 默认情况下,Query 从查询结果中的第一个对象开始检索。
setMaxResults(int maxResults): 设定一次最多检索出的对象的数目。在默认情况下,Query 和 Criteria 接口检索出查询结果中所有的对象。
(2). 投影查询
查询结果仅包含持久化类的部分属性的查询称之为投影查询。
为了支持投影查询,持久化需要提供对应的构造器以使Hibernate可以进行反射。
使用select关键字实现投影,可以使用distinct去除重复结果。
(3).报表查询
报表查询用于对数据分组和统计,与 SQL 一样,HQL 利用 GROUP BY 关键字对数据分组,用 HAVING 关键字对分组数据设定约束条件。
在 HQL 查询语句中可以调用以下聚集函数:count()、min()、max()、sum()、avg() 。
@Testpublic void testGroupBy(){String hql = "select min(e.salary), max(e.salary) "+ "from Employee e "+ "group by e.dept "+ "having min(salary) > :minSal";Query query = session.createQuery(hql).setParameter("minSal", 8000.0f);List<Object[]> results = query.list();for(Object[] objs : results){System.out.println(Arrays.asList(objs));}}
报表查询、投影查询中查询结果是对象数组的List,每一个数组即是一个查询结果行。
12.1.3. HQL (迫切)左外连接
(1). 迫切左外连接
LEFT JOIN FETCH 关键字表示迫切左外连接检索策略。
Query.list() 方法返回的集合中存放实体对象的引用,每个 Department 对象关联的 Employee 集合都被初始化,存放所有关联的 Employee 的实体对象。
查询结果中可能会包含重复元素,可以通过一个 HashSet 来过滤重复元素,或者在 SELECT 语句中使用 DISTINCT 关键字过滤重复的记录。
(2). 左外连接
LEFT JOIN 关键字表示左外连接查询。
Query.list() 方法返回的集合中存放的是对象数组类型(例如 [[department_1, employee_1], ... [department_n, employee_n]])。
根据配置文件来决定 Employee 集合的检索策略。
如果希望 list() 方法返回的集合中仅包含 Department 对象,可以在HQL 查询语句中使用 SELECT 关键字。
(3). 迫切左外连接和普通的左外连接的区别是,迫切左外连接会在连接查询结束后立即对左表对应的持久化类中与右表对应的持久化类的集合进行初始化。
12.1.4. HQL (迫切)内连接
(1). 迫切内连接
INNER JOIN FETCH 关键字表示迫切内连接,也可以省略 INNER 关键字。
Query.list() 方法返回的集合中存放 Department 对象的引用,每个 Department 对象的 Employee 集合都被初始化,存放所有关联的 Employee 对象。
(2). 内连接
INNER JOIN 关键字表示内连接,也可以省略 INNER 关键字。
Query.list() 方法的集合中存放的每个元素对应查询结果的一条记录,每个元素都是对象数组类型(例如 [[department_1, employee_1], ... [department_n, employee_n]])。
如果希望 list() 方法的返回的集合仅包含 Department 对象,可以在 HQL 查询语句中使用 SELECT 关键字。
12.1.5. 关联级别运行时的检索策略
如果在 HQL 中没有显式指定检索策略,将使用映射文件配置的检索策略。
HQL 会忽略映射文件中设置的迫切左外连接检索策略,如果希望 HQL 采用迫切左外连接策略,就必须在 HQL 查询语句中显式的指定它。
若在 HQL 代码中显式指定了检索策略,就会覆盖映射文件中配置的检索策略。
12.2. QBC 检索和本地 SQL 检索
12.2.1. QBC 检索
QBC 查询就是通过使用 Hibernate 提供的 Query By Criteria API 来查询对象,这种 API 封装了 SQL 语句的动态拼装,对查询提供了更加面向对象的功能接口。
(1). QBC基本用法
public void testQBC(){//1. 创建一个 Criteria 对象Criteria criteria = session.createCriteria(Employee.class);//2. 添加查询条件: 在 QBC 中查询条件使用 Criterion 来表示//Criterion 可以通过 Restrictions 的静态方法得到criteria.add(Restrictions.eq("email", "SKUMAR"));criteria.add(Restrictions.gt("salary", 5000F));//3. 执行查询Employee employee = (Employee) criteria.uniqueResult();System.out.println(employee);}
(2). 利用QBC实现SQL中的AND / OR
public void testQBC2(){Criteria criteria = session.createCriteria(Employee.class);//1. AND: 使用 Conjunction 表示//Conjunction 本身就是一个 Criterion 对象//且其中还可以添加 Criterion 对象Conjunction conjunction = Restrictions.conjunction();conjunction.add(Restrictions.like("name", "a", MatchMode.ANYWHERE));Department dept = new Department();dept.setId(80);conjunction.add(Restrictions.eq("dept", dept));System.out.println(conjunction);//2. ORDisjunction disjunction = Restrictions.disjunction();disjunction.add(Restrictions.ge("salary", 6000F));disjunction.add(Restrictions.isNull("email"));criteria.add(disjunction);criteria.add(conjunction);criteria.list();}
(3). 统计查询
public void testQBC3(){Criteria criteria = session.createCriteria(Employee.class);//统计查询: 使用 Projection 来表示: 可以由 Projections 的静态方法得到criteria.setProjection(Projections.max("salary"));System.out.println(criteria.uniqueResult());}
(4). 排序、翻页
public void testQBC4(){Criteria criteria = session.createCriteria(Employee.class);//1. 添加排序criteria.addOrder(Order.asc("salary"));criteria.addOrder(Order.desc("email"));//2. 添加翻页方法int pageSize = 5;int pageNo = 3;criteria.setFirstResult((pageNo - 1) * pageSize).setMaxResults(pageSize).list();}
12.2.2. 本地 SQL 检索
本地SQL查询来完善HQL不能涵盖所有的查询特性。
public void testNativeSQL(){String sql = "INSERT INTO gg_department VALUES(?, ?)";Query query = session.createSQLQuery(sql);query.setInteger(0, 280).setString(1, "ATGUIGU").executeUpdate();}
public void testHQLUpdate(){String hql = "DELETE FROM Department d WHERE d.id = :id";session.createQuery(hql).setInteger("id", 280).executeUpdate();}
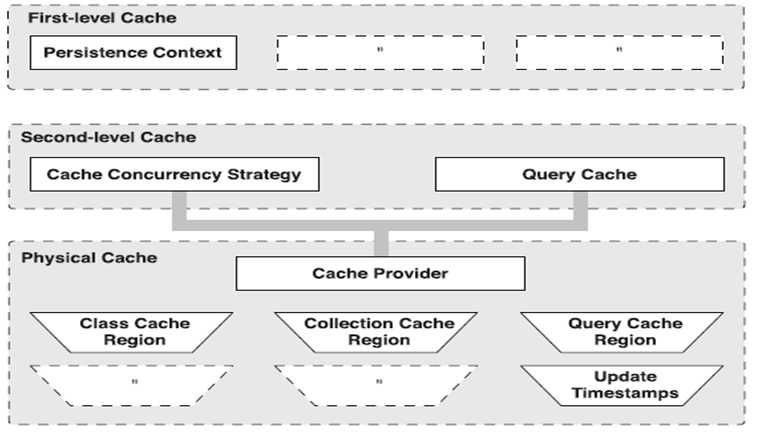
13. 二级缓存
Hibernate中提供了两个级别的缓存:
(1). 第一级别的缓存是 Session 级别的缓存,它是属于事务范围的缓存,这一级别的缓存由 hibernate 管理的;
(2). 第二级别的缓存是 SessionFactory 级别的缓存,它是属于进程范围的缓存。
其中SessionFactory的缓存可以分为两类:内置缓存,外置缓存。
(1). 内置缓存:Hibernate 自带的,不可卸载。通常在 Hibernate 的初始化阶段,Hibernate 会把映射元数据和预定义的 SQL 语句放到 SessionFactory 的缓存中,映射元数据是映射文件中数据(.hbm.xml 文件中的数据)的复制。该内置缓存是只读的。
(2). 外置缓存(即二级缓存):一个可配置的缓存插件。默认情况下,SessionFactory 不会启用这个缓存插件。外置缓存中的数据是数据库数据的复制,外置缓存的物理介质可以是内存或硬盘。
适合放入二级缓存中的数据:
- 很少被修改
- 不是很重要的数据, 允许出现偶尔的并发问题
- 经常被修改
- 财务数据, 绝对不允许出现并发问题
- 与其他应用程序共享的数据
Hibernate缓存架构:
13.1. 二级缓存的并发访问策略
两个并发的事务同时访问持久层的缓存的相同数据时,也有可能出现各类并发问题。
二级缓存可以设定以下 4 种类型的并发访问策略,每一种访问策略对应一种事务隔离级别。
(1). 非严格读写(Nonstrict-read-write):不保证缓存与数据库中数据的一致性。提供 Read Uncommited 事务隔离级别,对于极少被修改,而且允许脏读的数据,可以采用这种策略。
(2). 读写型(Read-write): 提供 Read Commited 数据隔离级别。对于经常读但是很少被修改的数据,可以采用这种隔离类型,因为它可以防止脏读。
(3). 事务型(Transactional): 仅在受管理环境下适用。它提供了Repeatable Read 事务隔离级别。对于经常读而很少被修改的数据,可以采用这种隔离类型,因为它可以防止脏读和不可重复读。
(4). 只读型(Read-Only):提供 Serializable 数据隔离级别,对于从来不会被修改的数据,可以采用这种访问策略。
13.2. 二级缓存的种类
二级缓存是可配置的的插件,Hibernate 允许选用以下类型的缓存插件:
EHCache: 可作为进程范围内的缓存,存放数据的物理介质可以使内存或硬盘,对 Hibernate 的查询缓存提供了支持;
OpenSymphony OSCache:可作为进程范围内的缓存,存放数据的物理介质可以使内存或硬盘,提供了丰富的缓存数据过期策略,对 Hibernate 的查询缓存提供了支持;
SwarmCache: 可作为集群范围内的缓存,但不支持 Hibernate 的查询缓存;
JBossCache:可作为集群范围内的缓存,支持 Hibernate 的查询缓存。
以上4 种缓存插件支持的并发访问策略(x 代表支持, 空白代表不支持):

13.3. 配置 Hibernate 的二级缓存
以EHCache为例进行说明。
1. 加入二级缓存插件的 jar 包及配置文件:
复制 hibernate-release-5.2.6.Final\\lib\\optional\\ehcache\\ 目录下的所有jar包到当前 Hibernate 应用的类路径下;
复制 hibernate-release-5.2.6.Final\\project\\etc\\ehcache.xml 文件到到当前 Hibernate 应用的类路径下。
2. 配置 hibernate.cfg.xml
2.1. 配置启用 hibernate 的二级缓存
<property name="cache.use_second_level_cache">true</property>
2.2. 配置hibernate二级缓存使用的产品
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
2.3. 配置对哪些类使用 hibernate 的二级缓存,其中usage属性指定并发访问策略
<class-cache usage="read-write" class="hellohibernate.cache.Employee"/>
<class-cache>配置节需要放到<mapping>之后。
也可以在该持久化类对应的映射文件中进行配置(作为<class>标签的直接子标签):
<cache usage="read-write"/>
2.4. 配置对集合使用二级缓存
<collection-cache usage="read-write" collection="hellohibernate.cache.Department.emps"/>
<collection-cache>配置节需要放到<mapping>之后。
也可以在集合所在持久化类对应的映射文件中进行配置(作为<set>标签的直接子标签):
<cache usage="read-write"/>
注意:还需要配置集合中的元素对应的持久化类也使用二级缓存,否则将会多出 n 条 SQL 语句。
3. ehcache 的 配置文件:ehcache.xml
<ehcache><!--Sets the path to the directory where cache .data files are created.If the path is a Java System Property it is replaced byits value in the running VM.The following properties are translated:user.home - User‘s home directoryuser.dir - User‘s current working directoryjava.io.tmpdir - Default temp file path--><!--指定一个目录, 当 EHCache 需要 把数据写到硬盘上时, 将把数据写到该目录下.--><diskStore path="java.io.tmpdir"/><!--Default Cache configuration. These will applied to caches programmatically created throughthe CacheManager.The following attributes are required for defaultCache:maxInMemory - Sets the maximum number of objects that will be created in memoryeternal - Sets whether elements are eternal. If eternal, timeouts are ignored and the elementis never expired.timeToIdleSeconds - Sets the time to idle for an element before it expires. Is only usedif the element is not eternal. Idle time is now - last accessed timetimeToLiveSeconds - Sets the time to live for an element before it expires. Is only usedif the element is not eternal. TTL is now - creation timeoverflowToDisk - Sets whether elements can overflow to disk when the in-memory cachehas reached the maxInMemory limit.--><!--设置缓存的默认数据过期策略.--><defaultCachemaxElementsInMemory="10000"eternal="false"timeToIdleSeconds="120"timeToLiveSeconds="120"overflowToDisk="true"/><!--设定具体的命名缓存的数据过期策略.每个命名缓存代表一个缓存区域.缓存区域(region): 一个具有名称的缓存块, 可以给每一个缓存块设置不同的缓存策略。如果没有设置任何的缓存区域, 则所有被缓存的对象, 都将使用默认的缓存策略。即: <defaultCache.../>.Hibernate 在不同的缓存区域保存不同的类/集合。对于类而言, 区域的名称是类名。如: hellohibernate.cache.Employee.对于集合而言, 区域的名称是类名加属性名。如: hellohibernate.cache.Department.emps.--><cache name="hellohibernate.cache.Employee"maxElementsInMemory="1"eternal="false"timeToIdleSeconds="300"timeToLiveSeconds="600"overflowToDisk="true"/><cache name="hellohibernate.cache.Department.emps"maxElementsInMemory="1000"eternal="true"timeToIdleSeconds="0"timeToLiveSeconds="0"overflowToDisk="false"/></ehcache>
4. 查询缓存
默认情况下,设置的缓存对 HQL 及 QBC 查询时无效的,但可以通过以下方式使其生效。
(1). 配置二级缓存,因为查询缓存依赖于二级缓存;
(2). 在 hibernate 配置文件中启用查询缓存 <property name="cache.use_query_cache">true</property> ;
(3). 对于希望启用查询缓存的查询语句,调用 Query 或 Criteria 的 setCacheable(true) 方法。
5. 时间戳缓存区域
时间戳缓存区域存放了对于查询结果相关的表进行插入,更新或删除操作的时间戳。
Hibernate 通过时间戳缓存区域来判断被缓存的查询结果是否过期,其运行过程如下。
(1). T1 时刻执行查询操作,把查询结果存放在 QueryCache 区域,记录该区域的时间戳为 T1;
(2). T2 时刻对查询结果相关的表进行更新操作,Hibernate 把 T2 时刻存放在 UpdateTimestampCache 区域。
注意:T1可能发生在T2前,也可能在其之后。
(3). T3 时刻执行查询结果前,先比较 QueryCache 区域的时间戳和 UpdateTimestampCache 区域的时间戳:
若 T2 >T1,那么就丢弃原先存放在 QueryCache 区域的查询结果,重新到数据库中查询数据,再把结果存放到 QueryCache 区域;
若 T2 < T1,直接从 QueryCache 中获得查询结果。
Query 接口的 iterate() 方法
同 list() 一样也能执行查询操作。list() 方法执行的 SQL 语句包含实体类对应的数据表的所有字段,而iterator() 方法执行的SQL 语句中仅包含实体类对应的数据表的 ID 字段。
当遍历访问结果集时,iterator() 方法先到 Session 缓存及二级缓存中查看是否存在特定 OID 的对象。如果存在,就直接返回该对象;如果不存在该对象就通过相应的 SQL Select 语句到数据库中加载特定的实体对象。
大多数情况下,应考虑使用 list() 方法执行查询操作。 iterator() 方法仅在满足以下条件的场合,可以稍微提高查询性能:
要查询的数据表中包含大量字段;
启用了二级缓存,且二级缓存中可能已经包含了待查询的对象。
14. 管理 Session
Hibernate 自身提供了三种管理 Session 对象的方法:
(1). Session 对象的生命周期与本地线程绑定;
(2). Session 对象的生命周期与 JTA 事务绑定;
(3). Hibernate 委托程序管理 Session 对象的生命周期。
在 Hibernate 的配置文件中,hibernate.current_session_context_class 属性用于指定 Session 管理方式,可选值包括:
thread,Session 对象的生命周期与本地线程绑定;
jta*,Session 对象的生命周期与 JTA 事务绑定;
managed,Hibernate 委托程序来管理 Session 对象的生命周期;
最佳实践:当单独使用Hibernate框架时,使用本地线程绑定的方式来管理Session。
Hibernate 按以下规则把 Session 与本地线程绑定:
当一个线程(threadA)第一次调用 SessionFactory 对象的 getCurrentSession() 方法时,该方法会创建一个新的 Session(sessionA) 对象,把该对象与 threadA 绑定,并将 sessionA 返回。
当 threadA 再次调用 SessionFactory 对象的 getCurrentSession() 方法时,该方法将返回 sessionA 对象。
当 threadA 提交 sessionA 对象关联的事务时,Hibernate 会自动flush sessionA 对象的缓存,然后提交事务,关闭 sessionA 对象. 当 threadA 撤销 sessionA 对象关联的事务时,也会自动关闭 sessionA 对象。
若 threadA 再次调用 SessionFactory 对象的 getCurrentSession() 方法时,该方法会又创建一个新的 Session(sessionB) 对象,把该对象与 threadA 绑定,并将 sessionB 返回。
15. 批量处理数据
在应用层进行批量操作,主要有以下方式:
- 通过 Session
- 通过 HQL
- 通过 StatelessSession
- 通过 JDBC API
最佳实践是,涉及批量处理时,使用原生的 JDBC API。
HIBERNATE 学习笔记 END at 2017-01-30 19:41:40.