如何搭建chatGPT4.0模型-国内如何用chatGPT4.0
Posted 147SEO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何搭建chatGPT4.0模型-国内如何用chatGPT4.0相关的知识,希望对你有一定的参考价值。
国内如何用chatGPT4.0
在国内,目前可以通过以下途径使用 OpenAI 的 ChatGPT 4.0:
-
自己搭建模型:如果您具备一定的技术能力,可以通过下载预训练模型和相关的开发工具包,自行搭建 ChatGPT 4.0 模型。OpenAI提供了相关的软件开发工具,包括Python API,也有为一些主流应用框架提供可用的API接口。
-
使用在线应用程序:目前许多国内公司和平台都提供了 ChatGPT 4.0 的在线服务,包括文本生成、语音合成、智能客服、智能聊天等,比如阿里云、腾讯云等均提供这样的 API 服务,可以直接在其平台上使用。
-
租赁服务:一些国内云服务商和人工智能提供商,如百度、华为、阿里云等也提供了ChatGPT 4.0的租赁服务,用户可以租用这些服务以获得更好的性能和更高质量的结果。

无论您选择哪种途径使用 ChatGPT 4.0,都需要注意保护您的数据隐私,以及了解相关的服务条款和条件,遵守各种法律法规和规定。需要注意的是,ChatGPT 4.0 仅仅是一个工具,需要结合人工策略与想象来确保所生成的文本准确性、有价值性、可读性等多方面因素的合理性。
chatGPT可以免费体验多少次
OpenAI 目前提供了 GPT-3 的免费体验计划,该计划允许用户免费使用 GPT-3 的一部分能力,但具体使用次数会根据应用场景和需求而有所不同。免费计划包括了 API 访问和在线 Playground,也有一些社区成员构建了开源工具来免费体验或者购买 v3 的更完整计算能力,但免费体验的次数、可用性、功能等因素是根据 OpenAI 的具体政策和服务条款来变化的,免费体验时间或次数会因用户需求而不同,一般来说,每个免费账户每月可以免费进行一些有限的文本生成、问答、语音合成和翻译等操作。
需要注意的是,这些免费体验仅能让用户快速了解和了解 ChatGPT 的基本功能和性能,如需实现更加定制化的应用场景和更高质量的生成结果,还需要进行额外的投资和开发。同时, OpenAI 也提供了更高级的 GPT-3 计划,以供商业用途和需要定制化服务的用户使用,可以根据实际需求来选择适合自己的方案。
如何搭建chatGPT4.0模型
搭建 ChatGPT 4.0 模型是一项较为复杂的任务,需要有一定的机器学习、自然语言处理和系统管理的知识和经验。以下是一个搭建 ChatGPT 4.0 模型的详细教程:
-
准备环境:搭建 ChatGPT 4.0 需要使用 GPU、Python 3.X、TensorFlow 等技术。您需要安装 CUDA、cuDNN 以及其他相关的包和依赖库,并设置相应的环境变量和配置。
-
下载预训练模型:下载预训练的 GPT-4 模型,包括检查点、配置文件和词表等,可以从 OpenAI 官网获得,在深度学习领域公认好用的代码托管平台 Github 上也有一些第三方作者搭建训练好的仓库,可以提供已经训练好的模型文件,省去您训练模型的过程。它们通常会提供合适版本的 TensorFlow 和 NVIDIA 依赖库,以便您正确地运行模型。
-
配置训练环境:在搭建模型前,您需要为模型配置训练环境,包括超参数、优化算法、学习速率以及其他训练参数。这些参数可以通过 TensorFlow API 进行设置和配置。
-
训练模型:在下载和配置好模型以及训练环境后,您可以开始训练模型。通过运行适当的脚本或者代码,可以启动训练过程并指定训练的时长、文件路径、数据源等。
-
优化模型:在训练完成后,您可能需要对模型进行优化和调整,以提供更好的性能和结果。优化可能包括减小模型的大小、改进测试集性能等。
以上是简单的搭建教程,总体来说搭建 ChatGPT 4.0 模型比较复杂,需要一定的技术经验和知识储备,如果您是一个初学者建议可以从别人基于开源代码的模型搭建拿到体验和学习经验,再逐渐探索 Tensorflow 等深度学习框架和原始模型搭建,因为这些框架和模型要求对模型训练技巧、参数调整、数据预处理等方向有更深入的理解,才能更好地训练出高质量、可消费的模型。
ChatGPT教你搭建多任务模型
ChatGPT教你搭建多任务模型
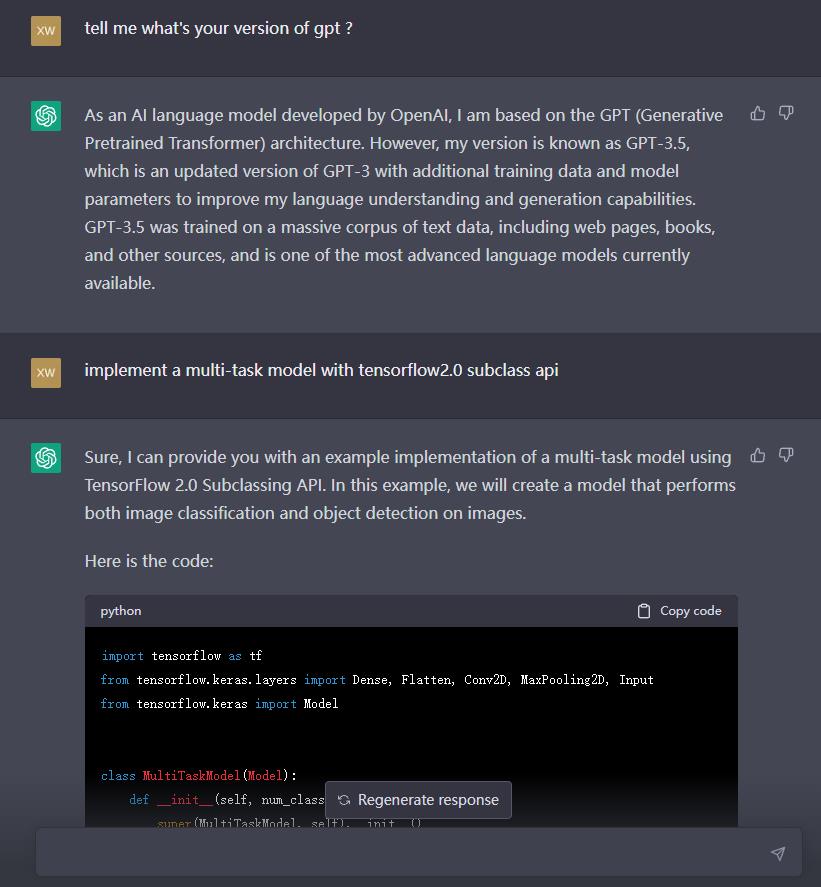
You:
tell me what’s your version of gpt ?
ChatGPT:
As an AI language model developed by OpenAI, I am based on the GPT (Generative Pretrained Transformer) architecture. However, my version is known as GPT-3.5, which is an updated version of GPT-3 with additional training data and model parameters to improve my language understanding and generation capabilities. GPT-3.5 was trained on a massive corpus of text data, including web pages, books, and other sources, and is one of the most advanced language models currently available.
You:
implement a multi-task model with tensorflow2.0 subclass api
ChatGPT:
Sure, I can provide you with an example implementation of a multi-task model using TensorFlow 2.0 Subclassing API. In this example, we will create a model that performs both image classification and object detection on images.
Here is the code:
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Input
from tensorflow.keras import Model
class MultiTaskModel(Model):
def __init__(self, num_classes, num_boxes):
super(MultiTaskModel, self).__init__()
self.num_classes = num_classes
self.num_boxes = num_boxes
# Shared layers
self.conv1 = Conv2D(32, 3, activation='relu')
self.maxpool1 = MaxPooling2D()
self.conv2 = Conv2D(64, 3, activation='relu')
self.maxpool2 = MaxPooling2D()
self.conv3 = Conv2D(128, 3, activation='relu')
self.maxpool3 = MaxPooling2D()
# Classification head
self.flat1 = Flatten()
self.dense1 = Dense(64, activation='relu')
self.dense2 = Dense(self.num_classes, activation='softmax')
# Detection head
self.flat2 = Flatten()
self.dense3 = Dense(256, activation='relu')
self.dense4 = Dense(self.num_boxes * 4, activation='linear')
def call(self, inputs):
# Shared layers
x = self.conv1(inputs)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
# Classification head
y1 = self.flat1(x)
y1 = self.dense1(y1)
y1 = self.dense2(y1)
# Detection head
y2 = self.flat2(x)
y2 = self.dense3(y2)
y2 = self.dense4(y2)
return y1, y2
In this example, we define a MultiTaskModel class that extends the tf.keras.Model class. The MultiTaskModel class takes two arguments, num_classes and num_boxes, which represent the number of classes for image classification and the number of bounding boxes for object detection, respectively.
We then define the shared layers of the model, which include three convolutional layers followed by max pooling layers. We define two separate heads for the model: one for image classification and another for object detection.
The classification head consists of a flatten layer, followed by two dense layers with relu and softmax activations, respectively. The detection head consists of a flatten layer, followed by two dense layers with relu and linear activations, respectively. The output of the detection head is a tensor of shape (batch_size, num_boxes * 4), where 4 represents the number of parameters needed to define a bounding box (x-coordinate, y-coordinate, width, and height).
In the call method of the model, we pass the inputs through the shared layers and then through the two separate heads to obtain the outputs for classification and detection. Finally, we return the two outputs as a tuple.
To train this model, you would need to define appropriate loss functions for each task and combine them into a joint loss. You would also need to provide training data that includes both labeled images and bounding box annotations.
You:
how can I train the model you built above? and how to generate sample for this model?
ChatGPT:
To train the multi-task model that I provided earlier, you can follow these steps:
-
Prepare the training data: You would need a dataset of labeled images and bounding box annotations. You can use popular datasets such as COCO, Pascal VOC, or OpenImages for this purpose.
-
Define the loss functions: For the classification task, you can use cross-entropy loss, and for the detection task, you can use mean squared error loss or smooth L1 loss. You can combine these losses into a joint loss using a weighting factor or a more complex scheme such as multi-task learning.
-
Compile the model: You can compile the model using the
compilemethod of theMultiTaskModelclass. You would need to specify the optimizer, the loss functions, and any metrics you want to track during training. -
Train the model: You can train the model using the
fitmethod of theMultiTaskModelclass. You would need to pass in the training data, the number of epochs, and any other relevant parameters such as batch size and validation data.
Here is some sample code that demonstrates these steps:
# Load the data
train_data = ...
val_data = ...
# Define the loss functions
class_loss_fn = tf.keras.losses.CategoricalCrossentropy()
detect_loss_fn = tf.keras.losses.MeanSquaredError()
# Define the optimizer
optimizer = tf.keras.optimizers.Adam()
# Compile the model
model = MultiTaskModel(num_classes=10, num_boxes=5)
model.compile(optimizer=optimizer, loss=[class_loss_fn, detect_loss_fn], metrics=['accuracy'])
# Train the model
model.fit(train_data, epochs=10, validation_data=val_data)
# Generate a sample output
input_image = ...
output_classes, output_boxes = model.predict(input_image)
To generate a sample output for the model, you can use the predict method of the MultiTaskModel class. The input to the predict method should be an image tensor of shape (batch_size, height, width, num_channels). The output of the predict method will be a tuple of two tensors: one for the classification probabilities and one for the bounding box parameters.
Here is some sample code that demonstrates how to generate a sample output:
# Generate a sample output
input_image = ...
output_classes, output_boxes = model.predict(input_image)
# Print the predicted classes and bounding boxes
print('Predicted classes:', output_classes)
print('Predicted boxes:', output_boxes)
Note that the output of the predict method will depend on the specific dataset and training data that you used to train the model, so the results may vary.
You:
ok, can you regenerate the model for recommendation scene with a clarified example?
ChatGPT:
Sure, here is an example of how to build a multi-task model for a recommendation system using TensorFlow 2.0’s Subclassing API. This model will have two tasks: rating prediction and item embedding prediction.
Assuming we have a dataset of user-item interactions with ratings, where each user has interacted with multiple items, we can define the following inputs and outputs for our model:
Inputs:
- User ID (integer)
- Item ID (integer)
Outputs:
- Rating (float)
- Item Embedding (vector of floats)
We will use an embedding layer to learn the representations of the users and items, and a shared neural network to predict the rating and item embedding.
import tensorflow as tf
class RecommendationModel(tf.keras.Model):
def __init__(self, num_users, num_items, embedding_size, hidden_units):
super(RecommendationModel, self).__init__()
self.user_embedding = tf.keras.layers.Embedding(num_users, embedding_size)
self.item_embedding = tf.keras.layers.Embedding(num_items, embedding_size)
self.shared_nn = tf.keras.Sequential([
tf.keras.layers.Dense(hidden_units, activation='relu'),
tf.keras.layers.Dense(hidden_units, activation='relu')
])
self.rating_head = tf.keras.layers.Dense(1)
self.embedding_head = tf.keras.layers.Dense(embedding_size)
def call(self, inputs):
user_ids, item_ids = inputs
user_embeddings = self.user_embedding(user_ids)
item_embeddings = self.item_embedding(item_ids)
concatenated = tf.concat([user_embeddings, item_embeddings], axis=-1)
shared = self.shared_nn(concatenated)
rating = self.rating_head(shared)
embedding = self.embedding_head(shared)
return rating, embedding
In the RecommendationModel class, we define the __init__ method to create the layers of the model. We first create two embedding layers, one for the users and one for the items, with the specified embedding size. We then create a shared neural network with two hidden layers, each with the specified number of units and ReLU activation. Finally, we create two output heads: one for rating prediction with a single output neuron, and one for item embedding prediction with an output size of the embedding size.
In the call method, we define how to forward pass the inputs through the model. We first look up the embeddings of the users and items using the corresponding embedding layers. We then concatenate these embeddings along the last dimension, and pass the concatenated embeddings through the shared neural network. Finally, we pass the output of the shared network through the rating and embedding output heads, respectively.
To train the model, we need to define the loss functions for each task and the optimizer. Assuming we have a training dataset of user-item interactions with corresponding ratings and item embeddings, we can define the following:
# Load the data
train_data = ...
val_data = ...
# Define the loss functions
mse_loss_fn = tf.keras.losses.MeanSquaredError()
cosine_loss_fn = tf.keras.losses.CosineSimilarity()
# Define the optimizer
optimizer = tf.keras.optimizers.Adam()
# Instantiate the model
model = RecommendationModel(num_users=1000, num_items=10000, embedding_size=32, hidden_units=64)
# Compile the model
model.compile(optimizer=optimizer, loss=[mse_loss_fn, cosine_loss_fn], metrics=['mae', 'cosine_similarity'])
# Train the model
model.fit(train_data, epochs=10, validation_data=val_data)
In this example, we use mean squared error loss for the rating prediction task and cosine similarity loss for the item embedding prediction task. We compile the model with the specified optimizer,
You:
convert above two task with ctr prediction and cvr prediction task? build the training and predicting pipline with python again.
ChatGPT:
Sure, here’s an example of how to modify the recommendation system multi-task model to predict click-through rate (CTR) and conversion rate (CVR) instead.
Assuming we have a dataset of user-item interactions with the following features: user ID, item ID, timestamp, and a binary label indicating whether the user clicked on the item and another binary label indicating whether the user converted after clicking on the item.
We can define the following inputs and outputs for our model:
Inputs:
- User ID (integer)
- Item ID (integer)
- Timestamp (float)
Outputs:
- Click Probability (float)
- Conversion Probability (float)
We will use an embedding layer to learn the representations of the users and items, and a shared neural network with two output heads to predict the click and conversion probabilities.
import tensorflow as tf
class CTRCVRModel(tf.keras.Model):
def __init__(self, num_users, num_items, embedding_size, hidden_units):
super(CTRCVRModel, self).__init__()
self.user_embedding = tf.keras.layers.Embedding(num_users, embedding_size)
self.item_embedding = tf.keras.layers.Embedding(num_items, embedding_size)
self.timestamp_embedding = tf.keras.layers.Dense(embedding_size, activation='relu')
self.shared_nn = tf.keras.Sequential([
tf.keras.layers.Dense(hidden_units, activation='relu'),
tf.keras.layers.Dense(hidden_units, activation='relu')
])
self.click_head = tf.keras.layers.Dense(1, activation='sigmoid')
self.conversion_head = tf.keras.layers.Dense(1, activation='sigmoid')
def call(self, inputs):
user_ids, item_ids, timestamps = inputs
user_embeddings = self.user_embedding(user_ids)
item_embeddings = self.item_embedding(item_ids)
timestamp_embeddings = self.timestamp_embedding(timestamps)
concatenated = tf.concat([user_embeddings, item_embeddings, timestamp_embeddings], axis=-1)
shared = self.shared_nn(concatenated)
click_probability = self.click_head(shared)
conversion_probability = self.conversion_head(shared)
return click_probability, conversion_probability
In the CTRCVRModel class, we define the __init__ method to create the layers of the model. We first create three input layers: one for the users, one for the items, and one for the timestamps. We then create two embedding layers, one for the users and one for the items, with the specified embedding size. We also create a dense layer for the timestamp feature. We then create a shared neural network with two hidden layers, each with the specified number of units and ReLU activation. Finally, we create two output heads: one for click probability prediction with a single output neuron and sigmoid activation, and one for conversion probability prediction with a single output neuron and sigmoid activation.
In the call method, we define how to forward pass the inputs through the model. We first look up the embeddings of the users and items using the corresponding embedding layers. We also pass the timestamps through the timestamp embedding layer. We then concatenate these embeddings and the timestamp embeddings along the last dimension, and pass the concatenated embeddings through the shared neural network. Finally, we pass the output of the shared network through the click and conversion output heads, respectively.
To train the model, we need to define the loss functions for each task and the optimizer. Assuming we have a training dataset of user-item interactions with the corresponding labels, we can define the following:
# Load the data
train_data = ...
val_data = ...
# Define the loss functions
bce_loss_fn = tf.keras.losses.BinaryCrossentropy()
# Define the optimizer
optimizer = tf.keras.optimizers.Adam()
# Instantiate the model
model = C
You:
continue
ChatGPT:
# Compile the model with two loss functions
model.compile(optimizer=optimizer, loss=[bce_loss_fn, bce_loss_fn])
# Define the training and validation datasets
train_dataset = tf.data.Dataset.from_tensor_slices((train_user_ids, train_item_ids, train_timestamps,
train_click_labels, train_conversion_labels))
train_dataset = train_dataset.shuffle(buffer_size=len(train_data)).batch(batch_size)
val_dataset = tf.data.Dataset.from_tensor_slices((val_user_ids, val_item_ids, val_timestamps,
val_click_labels, val_conversion_labels))
val_dataset = val_dataset.batch(batch_size)
# Train the model
history = model.fit(train_dataset, epochs=num_epochs, validation_data=val_dataset)
In the compile method, we specify the optimizer and the loss functions for each task. We use binary crossentropy as the loss function for both tasks.
In the training and validation datasets, we combine all the input features and labels into tuples, and create tf.data.Dataset objects from them. We shuffle the training dataset and batch both datasets. We then use the fit method to train the model, specifying the training dataset, the number of epochs, and the validation dataset.
To generate predictions for new user-item interactions, we can use the following code:
# Load the test data
test_data = ...
# Extract the input features
test_user_ids = test_data['user_id'].values
test_item_ids = test_data['item_id'].values
test_timestamps = test_data['timestamp'].values
# Generate predictions
click_probabilities, conversion_probabilities = model.predict((test_user_ids, test_item_ids, test_timestamps))
# Save the predictions
test_data['click_probability'] = click_probabilities
test_data['conversion_probability'] = conversion_probabilities
test_data.to_csv('predictions.csv', index=False)
In this code, we load the test data and extract the input features. We then use the predict method of the model to generate the click and conversion probabilities for each interaction. Finally, we save the predictions to a CSV file.
You:
great. something may be wrong. how can i solve user or item cold-start problem due to the unseen ids occuring in embedding table?
ChatGPT:
Good question! Cold-start is a common problem in recommender systems, where new users or items have no or very few interactions in the training data, making it difficult to generate accurate recommendations.
One way to handle the cold-start problem is to use a hybrid approach, where we use not only collaborative filtering based on user-item interactions, but also content-based filtering based on item features. This allows us to make recommendations for new items based on their features, even if they have no interactions in the training data.
Another approach is to use pre-trained embeddings for the user and item features. We can use a pre-trained language model like BERT or GPT to generate embeddings for textual features like item titles or user profiles. These pre-trained embeddings can be fine-tuned on the training data to generate task-specific embeddings for our recommender system.
To handle unseen users or items at inference time, we can use a fallback strategy, such as recommending popular items to new users or recommending items similar to the ones the user has interacted with to new items.
Another approach is to use a multi-armed bandit algorithm, where we balance exploration and exploitation by recommending a mix of popular items and items similar to the ones the user has interacted with. As the user interacts more with the system, we can adjust the balance towards exploitation to generate more personalized recommendations.
You:
sounds great.but talk is cheap, show me the code.
ChatGPT:
Sure! Here’s an example of how to implement a hybrid recommender system with user and item embeddings for handling the cold-start problem:
# Import necessary libraries
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Concatenate, Dense, Dropout
from tensorflow.keras.models import Model
# Define the input and embedding sizes
num_users = len(user_id_encoder.classes_)
num_items = len(item_id_encoder.classes_)
embedding_size = 32
# Define the user and item input layers
user_input = Input(shape=(1,), name='user_input')
item_input = Input(shape=(1,), name='item_input')
# Define the user and item embedding layers
user_embedding = Embedding(input_dim=num_users, output_dim=embedding_size, name='user_embedding')
item_embedding = Embedding(input_dim=num_items, output_dim=embedding_size, name='item_embedding')
# Generate the user and item embeddings
user_embedding_output = user_embedding(user_input)
item_embedding_output = item_embedding(item_input)
# Define the MLP layers
concatenated_embeddings = Concatenate(name='concatenated_embeddings')([user_embedding_output, item_embedding_output])
dropout_layer_1 = Dropout(0.2, name='dropout_layer_1')(concatenated_embeddings)
dense_layer_1 = Dense(64, activation='relu', name='dense_layer_1')(dropout_layer_1)
dropout_layer_2 = Dropout(0.2, name='dropout_layer_2')(dense_layer_1)
dense_layer_2 = Dense(32, activation='relu', name='dense_layer_2')(dropout_layer_2)
# Define the output layer
output_layer = Dense(1, activation='sigmoid', name='output_layer')(dense_layer_2)
# Define the model
model = Model(inputs=[user_input, item_input], outputs=output_layer)
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# Train the model
model.fit([train_data['user_id'], train_data['item_id']], train_data['label'], epochs=10, validation_split=0.2)
In this code, we define the input and embedding sizes for the user and item features, and define the user and item input layers. We then define the user and item embedding layers using the Embedding class, and generate the embeddings for the user and item features using these layers.
We then define an MLP model using the Concatenate, Dropout, and Dense layers, and concatenate the user and item embeddings as input to this model. We define a sigmoid activation function on the output layer, since we are performing binary classification to predict user-item interactions.
We compile the model using the Adam optimizer and binary crossentropy loss function, and train the model on the training data, using 20% of the data for validation. Note that we use the fit method of the model, and pass the user and item features as a list to the inputs parameter of the method.
To handle the cold-start problem, we can incorporate content-based filtering by including item features, such as the item title or description, in the input to the model. We can use pre-trained language models like BERT or GPT to generate embeddings for these features, or use simpler models like TF-IDF or word2vec.
To handle unseen users or items at inference time, we can use a fallback strategy, such as recommending popular items to new users or recommending items similar to the ones the user has interacted with to new items. We can also use a multi-armed bandit algorithm to balance exploration and exploitation and generate personalized recommendations for cold-start users and items.
You:
can you show the main coding logic for the last two strategy you mentioned above?
ChatGPT:
Sure, here are some code snippets to illustrate the two strategies:
Strategy 1: Recommending popular items to new users
# Get the top N most popular items
popular_items = train_data['item_id'].value_counts().head(N).index.tolist()
# Get the user's interactions
user_interactions = train_data[train_data['user_id'] == user_id]['item_id'].tolist()
# Remove the items the user has already interacted with
popular_items = [item for item in popular_items if item not in user_interactions]
# Recommend the remaining popular items to the user
recommendations = popular_items[:K]
In this code, we first compute the top N most popular items from the training data based on their frequency of interaction. We then get the user’s interactions from the training data, and remove the items that the user has already interacted with from the list of popular items. We then recommend the top K remaining popular items to the user.
Strategy 2: Recommending similar items to new items
# Define the similarity function
def cosine_similarity(vector1, vector2):
dot_product = np.dot(vector1, vector2)
norm1 = np.linalg.norm(vector1)
norm2 = np.linalg.norm(vector2)
return dot_product / (norm1 * norm2)
# Get the embedding of the new item
new_item_embedding = item_embedding.predict(np.array([new_item_id]))
# Compute the cosine similarity between the new item and all other items
similarities = []
for item_id in item_id_encoder.classes_:
if item_id == new_item_id:
continue
item_embedding = item_embedding_layer(np.array(以上是关于如何搭建chatGPT4.0模型-国内如何用chatGPT4.0的主要内容,如果未能解决你的问题,请参考以下文章