02Transforms使用——.TotensorNormanizeResizeRandomCrop
Posted cocapop
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02Transforms使用——.TotensorNormanizeResizeRandomCrop相关的知识,希望对你有一定的参考价值。
1. Transforms用途
① Transforms当成工具箱的话,里面的class就是不同的工具。例如像totensor、resize这些工具。
② Transforms拿一些特定格式的图片,经过Transforms里面的工具,获得我们想要的结果。
2. Transforms该如何使用
2.1 transforms.Totensor使用
作用:将原始的PILImage格式或者numpy.array格式的数据格式化为可被pytorch快速处理的张量类型。
- 是将输入的数据shape H,W,C ——> C,H,W
- 将所有数除以255,将数据归一化到【0,1】
输入模式为(L、LA、P、I、F、RGB、YCbCr、RGBA、CMYK、1)的PIL Image 或 numpy.ndarray (形状为H x W x C)数据范围是[0, 255] 到一个 Torch.FloatTensor,其形状 (C x H x W) 在 [0.0, 1.0] 范围内。
import torch
import numpy as np
from torchvision import transforms
import cv2
#自定义图片数组,数据类型一定要转为‘uint8’,不然transforms.ToTensor()不会归一化
data = np.array([
[[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]],
[[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]],
[[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]],
[[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]],
[[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]]
],dtype='uint8')
print(data)
print(data.shape) #(5,5,3)
data = transforms.ToTensor()(data)
print(data)
print(data.shape) #(3,5,5)from torchvision import transforms
from PIL import Image
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor() # 创建 transforms.ToTensor类 的实例化对象
tensor_img = tensor_trans(img) # 调用 transforms.ToTensor类 的__call__的魔术方法
print(tensor_img)
--------------------------
结果:
tensor([[[0.5725, 0.5725, 0.5725, ..., 0.5686, 0.5725, 0.5765],
[0.5725, 0.5725, 0.5725, ..., 0.5686, 0.5725, 0.5765],
[0.5686, 0.5686, 0.5725, ..., 0.5686, 0.5725, 0.5765],
...,
[0.5490, 0.5647, 0.5725, ..., 0.6314, 0.6235, 0.6118],
[0.5608, 0.5765, 0.5843, ..., 0.5961, 0.5843, 0.5765],
[0.5725, 0.5843, 0.5922, ..., 0.5647, 0.5529, 0.5490]],
[[0.4471, 0.4471, 0.4471, ..., 0.4235, 0.4275, 0.4314],
[0.4471, 0.4471, 0.4471, ..., 0.4235, 0.4275, 0.4314],
[0.4431, 0.4431, 0.4471, ..., 0.4235, 0.4275, 0.4314],
...,
[0.4000, 0.4157, 0.4235, ..., 0.4706, 0.4627, 0.4510],
[0.4118, 0.4275, 0.4353, ..., 0.4431, 0.4314, 0.4235],
[0.4235, 0.4353, 0.4431, ..., 0.4118, 0.4000, 0.3961]],
[[0.2471, 0.2471, 0.2471, ..., 0.2588, 0.2627, 0.2667],
[0.2471, 0.2471, 0.2471, ..., 0.2588, 0.2627, 0.2667],
[0.2431, 0.2431, 0.2471, ..., 0.2588, 0.2627, 0.2667],
...,
[0.2157, 0.2314, 0.2392, ..., 0.2510, 0.2431, 0.2314],
[0.2275, 0.2431, 0.2510, ..., 0.2196, 0.2078, 0.2000],
[0.2392, 0.2510, 0.2588, ..., 0.1961, 0.1843, 0.1804]]])2.2 需要Tensor数据类型原因
① Tensor有一些属性,比如反向传播、梯度等属性,它包装了神经网络需要的一些属性。
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("Temsor_img",tensor_img)
writer.close()② 在 Anaconda 终端里面,激活py3.6.3环境,再输入 tensorboard --logdir=C:\\Users\\wangy\\Desktop\\03CV\\logs 命令,将网址赋值浏览器的网址栏,回车,即可查看tensorboard显示日志情况。
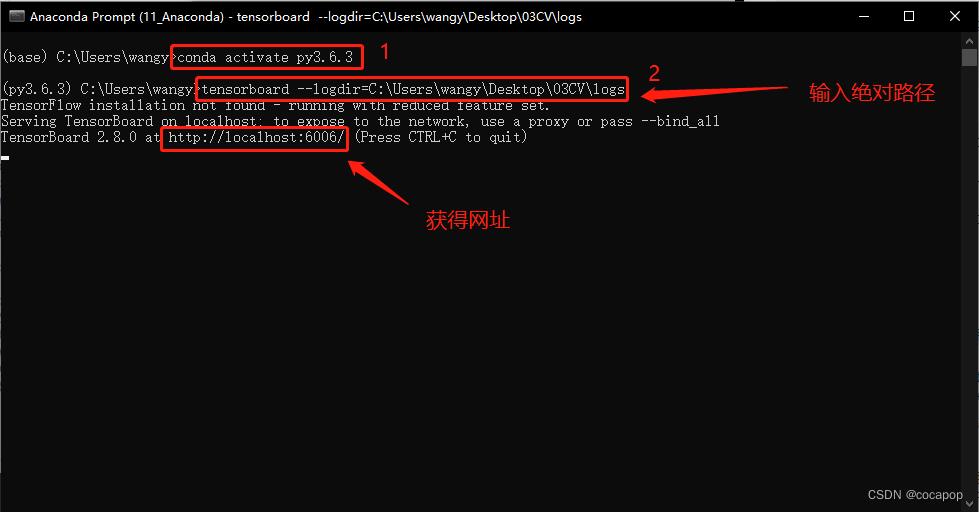
③ 输入网址可得Tensorboard界面。
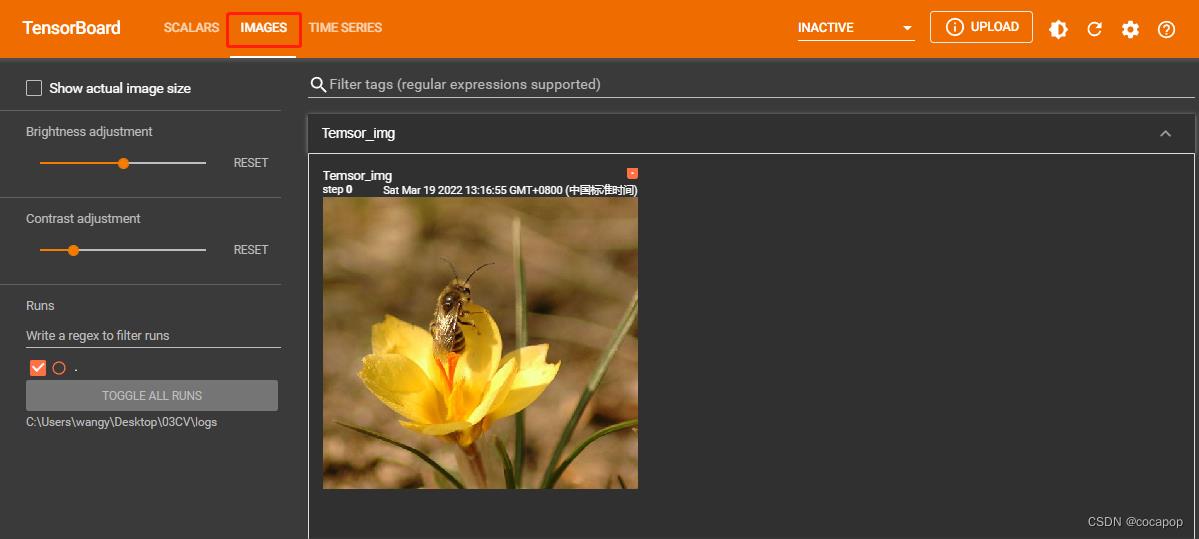
3. 常见的Transforms工具
① Transforms的工具主要关注他的输入、输出、作用。
3.1 __call__魔术方法使用
class Person:
def __call__(self,name):
print("__call__ "+"Hello "+name)
def hello(self,name):
print("hello "+name)
person = Person() # 实例化对象
person("zhangsan") # 调用__call__魔术方法
person.hello("xixi") # 调用hello方法
---------------------------
结果:
__call__ Hello zhangsan
hello xixi3.2 Normanize归一化
transforms.Normalize()
- 功能:逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛
- output = (input - mean) / std
- mean:各通道的均值
- std:各通道的标准差
-
x = (x - mean) / std
#首先求得一批数据的mean和std
import torch
import numpy as np
from torchvision import transforms
# 这里以上述创建的单数据为例子
data = np.array([
[[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]],
[[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]],
[[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]],
[[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]],
[[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]]
],dtype='uint8')
#将数据转为C,W,H,并归一化到[0,1]
data = transforms.ToTensor()(data)
# 需要对数据进行扩维,增加batch维度
data = torch.unsqueeze(data,0)
nb_samples = 0.
#创建3维的空列表
channel_mean = torch.zeros(3)
channel_std = torch.zeros(3)
print(data.shape)
N, C, H, W = data.shape[:4]
data = data.view(N, C, -1) #将w,h维度的数据展平,为batch,channel,data,然后对三个维度上的数分别求和和标准差
print(data.shape)
#展平后,w,h属于第二维度,对他们求平均,sum(0)为将同一纬度的数据累加
channel_mean += data.mean(2).sum(0)
#展平后,w,h属于第二维度,对他们求标准差,sum(0)为将同一纬度的数据累加
channel_std += data.std(2).sum(0)
#获取所有batch的数据,这里为1
nb_samples += N
#获取同一batch的均值和标准差
channel_mean /= nb_samples
channel_std /= nb_samples
print(channel_mean, channel_std)
---------------------------------------------------------
data = np.array([
[[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]],
[[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]],
[[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]],
[[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]],
[[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]]
],dtype='uint8')
data = transforms.ToTensor()(data)
for i in range(3):
data[i,:,:] = (data[i,:,:] - channel_mean[i]) / channel_std[i]
print(data)
输出:
tensor([[[-1.3856, -1.3856, -1.3856, -1.3856, -1.3856],
[-0.6928, -0.6928, -0.6928, -0.6928, -0.6928],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.6928, 0.6928, 0.6928, 0.6928, 0.6928],
[ 1.3856, 1.3856, 1.3856, 1.3856, 1.3856]],
[[-1.3856, -1.3856, -1.3856, -1.3856, -1.3856],
[-0.6928, -0.6928, -0.6928, -0.6928, -0.6928],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.6928, 0.6928, 0.6928, 0.6928, 0.6928],
[ 1.3856, 1.3856, 1.3856, 1.3856, 1.3856]],
[[-1.3856, -1.3856, -1.3856, -1.3856, -1.3856],
[-0.6928, -0.6928, -0.6928, -0.6928, -0.6928],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.6928, 0.6928, 0.6928, 0.6928, 0.6928],
[ 1.3856, 1.3856, 1.3856, 1.3856, 1.3856]]])from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
print(img_tensor[0][0][0])
tensor_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
#input[channel]=(input[chnnel]-mean[channel])/std[channel]
img_norm = tensor_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("img_tensor",img_tensor)
writer.add_image("img_norm",img_norm)
writer.close()
--------------------
结果:
tensor(0.5725)
tensor(0.1451)3.3 Resize裁剪
3.3.1 Resize裁剪方法一
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
print(img) # PIL类型的图片原始比例为 500×464
writer = SummaryWriter("logs")
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
trans_resize = transforms.Resize((512,512))
# PIL数据类型的 img -> resize -> PIL数据类型的 img_resize
img_resize = trans_resize(img)
# PIL 数据类型的 PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
print(img_resize.size()) # PIL类型的图片原始比例为 3×512×512,3通道
writer.add_image("img_tensor",img_tensor)
writer.add_image("img_resize",img_resize)
writer.close()
------------------------------------------------------
结果:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x464 at 0x2C25DF0B320>
torch.Size([3, 512, 512])
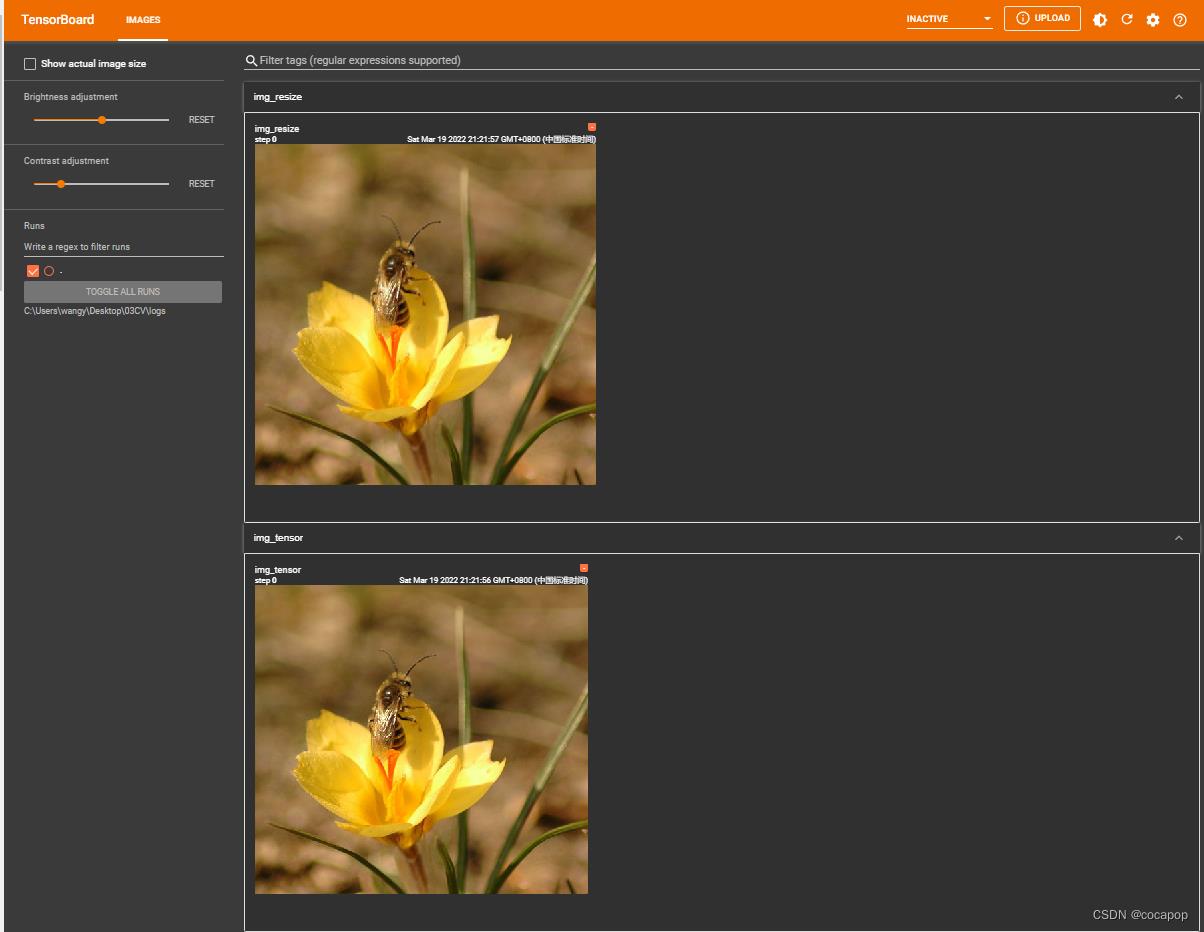
3.3.2 Resize裁剪方法二
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
print(img)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
# Resize 第二种方式:等比缩放
# PIL类型的图片原始比例为 500×464
trans_resize_2 = transforms.Resize(512) # 512/464 = 1.103 551/500 = 1.102
# PIL类型的 Image -> resize -> PIL类型的 Image -> totensor -> tensor类型的 Image
# Compose函数中后面一个参数的输入为前面一个参数的输出
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
print(img_resize_2.size())
writer.add_image("img_tensor",img_tensor)
writer.add_image("img_resize_2",img_resize_2)
writer.close()
-----------------------------------------------------------
结果:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x464 at 0x2C25DF0B6D8>
torch.Size([3, 512, 551])3.4 RandomCrop随即裁剪
3.4.1 RandomCrop随即裁剪方式一
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
print(img)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("img_tensor",img_tensor)
trans_random = transforms.RandomCrop(312) # 随即裁剪成 312×312 的
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
print(img_crop.size())
-------------------------------------------------------------
结果:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x464 at 0x2C25DF0BAC8>
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])
torch.Size([3, 312, 312])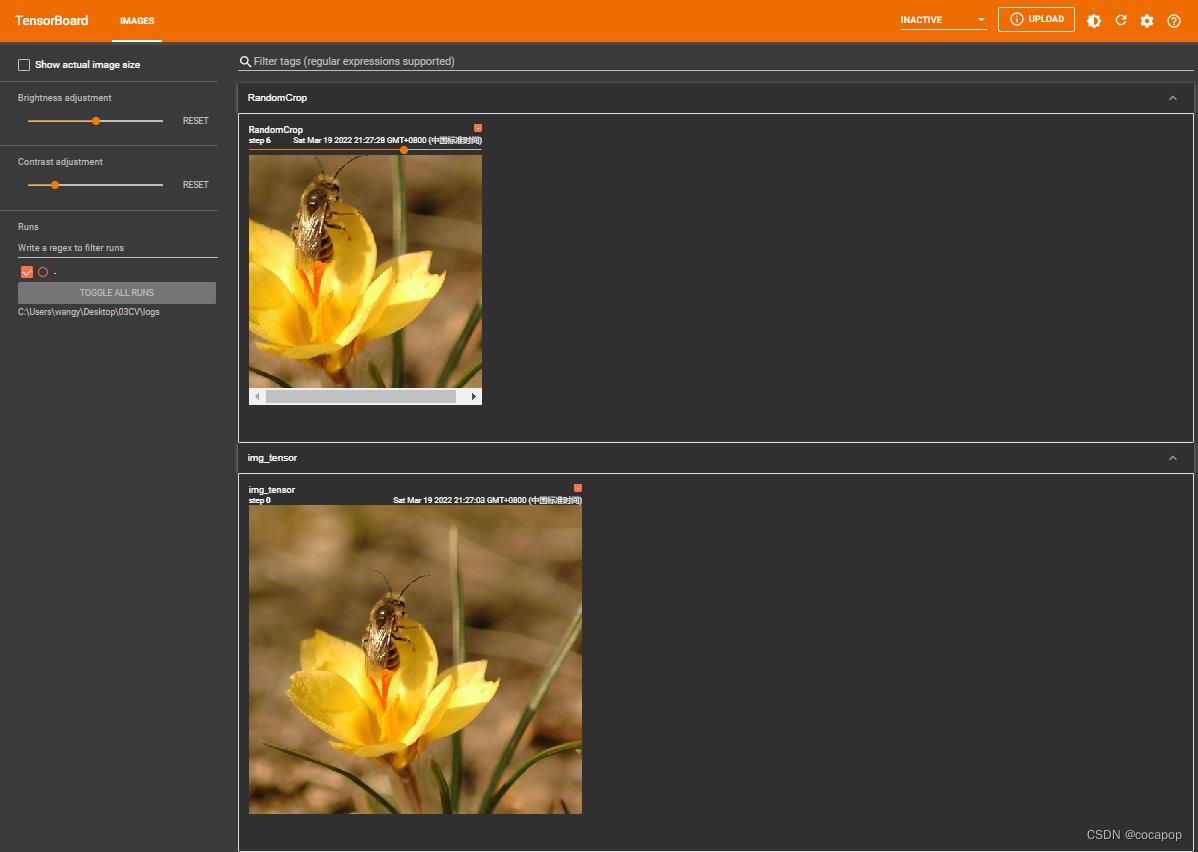
3.4.2 RandomCrop随即裁剪方式二
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2
img_path = "Data/FirstTypeData/val/bees/10870992_eebeeb3a12.jpg"
img = Image.open(img_path)
print(img)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("img_tensor",img_tensor)
trans_random = transforms.RandomCrop((312,100)) # 指定随即裁剪的宽和高
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
print(img_crop.size())
--------------------------------------------------------
结果:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x464 at 0x2C25DF1B390>
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])
torch.Size([3, 312, 100])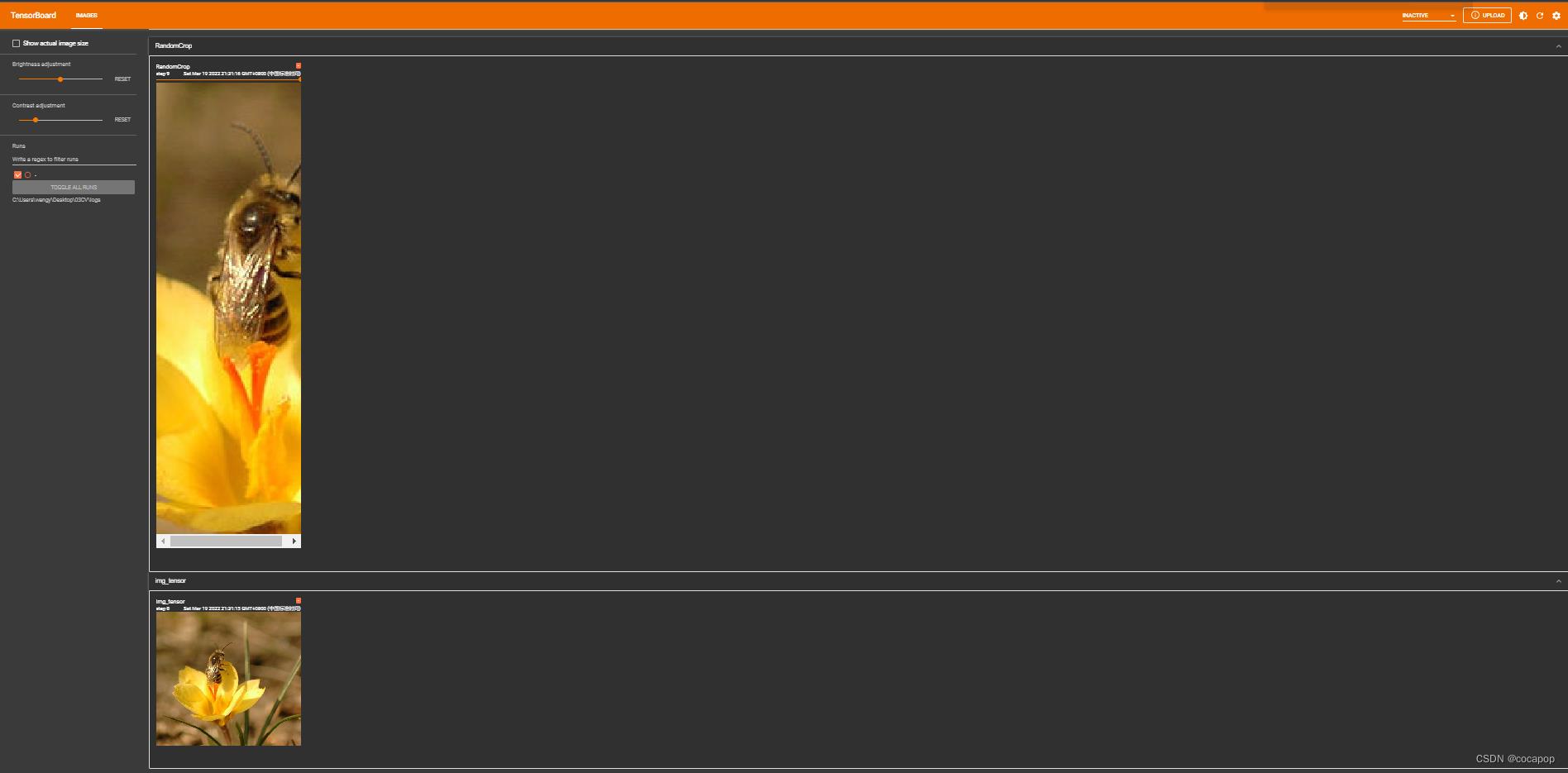
torchvision 笔记:transforms.Normalize()
一般和transforms.ToTensor()搭配使用
作用就是先将输入归一化到(0,1)【transforms.ToTensor()】,再使用公式"(x-mean)/std",将每个元素分布到(-1,1)
很多CV的代码中,是这样使用这一条语句的:torchvision.transforms.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])这一组参数是从ImageNet数据集中获得的
在 torchvision 笔记:ToTensor()_UQI-LIUWJ的博客-CSDN博客的代码基础上我们进行修改
ToTensor 中的代码:
from PIL import Image from torchvision import transforms, utils a=Image.open(b+'img/00000.jpg') a

y=transforms.ToTensor() a=y(a) a ''' tensor([[[0.9255, 0.9255, 0.9255, ..., 0.9176, 0.9176, 0.9176], [0.9255, 0.9255, 0.9255, ..., 0.9176, 0.9176, 0.9176], [0.9255, 0.9255, 0.9255, ..., 0.9176, 0.9176, 0.9176], ..., [0.7882, 0.7882, 0.7882, ..., 0.7922, 0.7922, 0.7922], [0.7882, 0.7882, 0.7882, ..., 0.7922, 0.7922, 0.7922], [0.7882, 0.7882, 0.7882, ..., 0.7922, 0.7922, 0.7922]], [[0.9255, 0.9255, 0.9255, ..., 0.9216, 0.9216, 0.9216], [0.9255, 0.9255, 0.9255, ..., 0.9216, 0.9216, 0.9216], [0.9255, 0.9255, 0.9255, ..., 0.9216, 0.9216, 0.9216], ..., [0.7961, 0.7961, 0.7961, ..., 0.7922, 0.7922, 0.7922], [0.7961, 0.7961, 0.7961, ..., 0.7922, 0.7922, 0.7922], [0.7961, 0.7961, 0.7961, ..., 0.7922, 0.7922, 0.7922]], [[0.9255, 0.9255, 0.9255, ..., 0.9294, 0.9294, 0.9294], [0.9255, 0.9255, 0.9255, ..., 0.9294, 0.9294, 0.9294], [0.9255, 0.9255, 0.9255, ..., 0.9294, 0.9294, 0.9294], ..., [0.7922, 0.7922, 0.7922, ..., 0.8000, 0.8000, 0.8000], [0.7922, 0.7922, 0.7922, ..., 0.8000, 0.8000, 0.8000], [0.7922, 0.7922, 0.7922, ..., 0.8000, 0.8000, 0.8000]]]) '''
Normalize的代码
z=transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
a=z(a)
a
'''
tensor([[[1.9235, 1.9235, 1.9235, ..., 1.8893, 1.8893, 1.8893],
[1.9235, 1.9235, 1.9235, ..., 1.8893, 1.8893, 1.8893],
[1.9235, 1.9235, 1.9235, ..., 1.8893, 1.8893, 1.8893],
...,
[1.3242, 1.3242, 1.3242, ..., 1.3413, 1.3413, 1.3413],
[1.3242, 1.3242, 1.3242, ..., 1.3413, 1.3413, 1.3413],
[1.3242, 1.3242, 1.3242, ..., 1.3413, 1.3413, 1.3413]],
[[2.0959, 2.0959, 2.0959, ..., 2.0784, 2.0784, 2.0784],
[2.0959, 2.0959, 2.0959, ..., 2.0784, 2.0784, 2.0784],
[2.0959, 2.0959, 2.0959, ..., 2.0784, 2.0784, 2.0784],
...,
[1.5182, 1.5182, 1.5182, ..., 1.5007, 1.5007, 1.5007],
[1.5182, 1.5182, 1.5182, ..., 1.5007, 1.5007, 1.5007],
[1.5182, 1.5182, 1.5182, ..., 1.5007, 1.5007, 1.5007]],
[[2.3088, 2.3088, 2.3088, ..., 2.3263, 2.3263, 2.3263],
[2.3088, 2.3088, 2.3088, ..., 2.3263, 2.3263, 2.3263],
[2.3088, 2.3088, 2.3088, ..., 2.3263, 2.3263, 2.3263],
...,
[1.7163, 1.7163, 1.7163, ..., 1.7511, 1.7511, 1.7511],
[1.7163, 1.7163, 1.7163, ..., 1.7511, 1.7511, 1.7511],
[1.7163, 1.7163, 1.7163, ..., 1.7511, 1.7511, 1.7511]]])
'''将tensor反变换回图片,则有
以上是关于02Transforms使用——.TotensorNormanizeResizeRandomCrop的主要内容,如果未能解决你的问题,请参考以下文章