Redis学习Redis事务
Posted Pycro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习Redis事务相关的知识,希望对你有一定的参考价值。
理论简介
是什么
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。

能干嘛
一个队列中,一次性、顺序性、排他性的执行一系列命令
Redis事务 VS 数据库事务

案例实操
常用命令
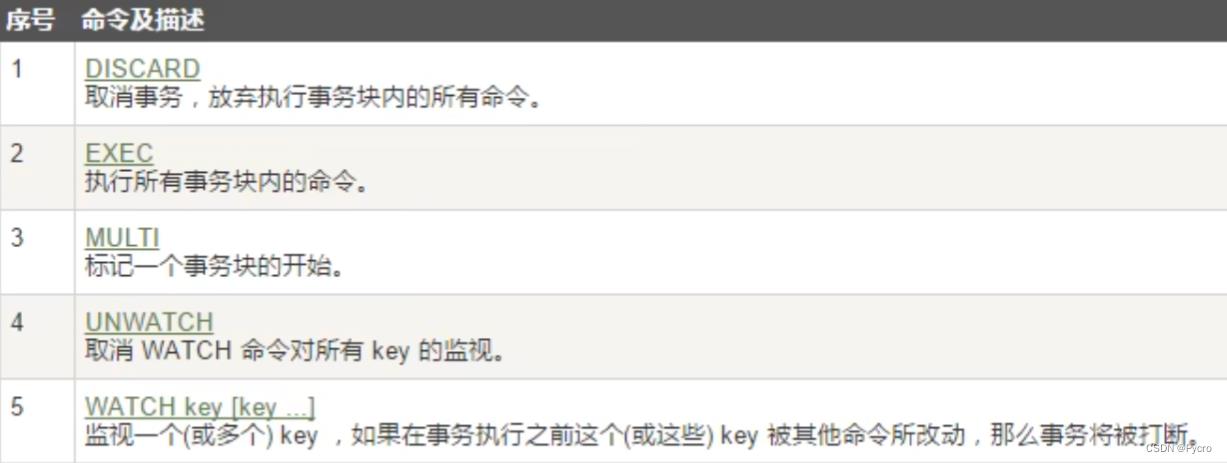
case1:正常执行
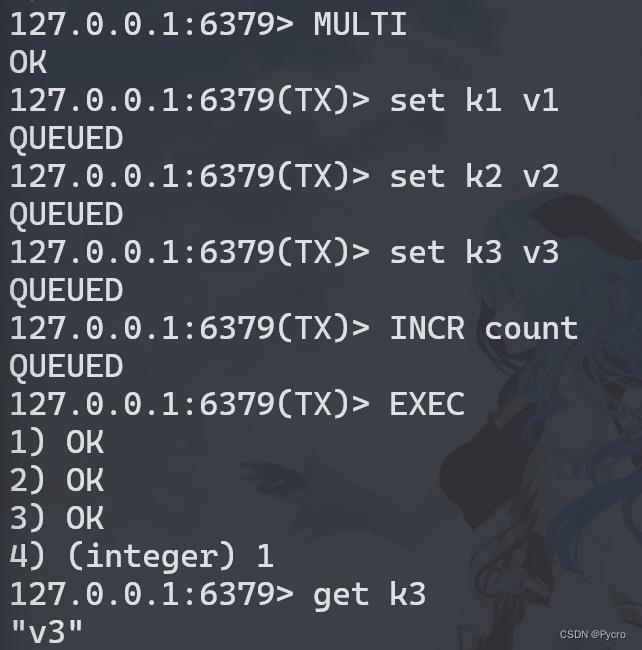
case2:放弃事务
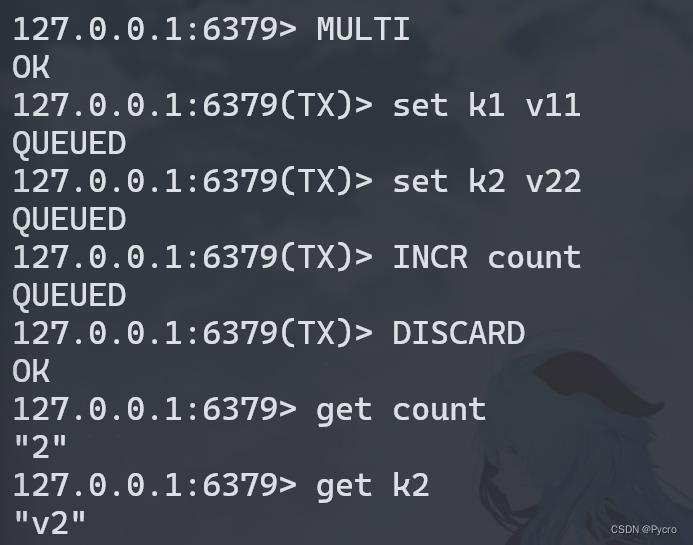
case3:全体连坐
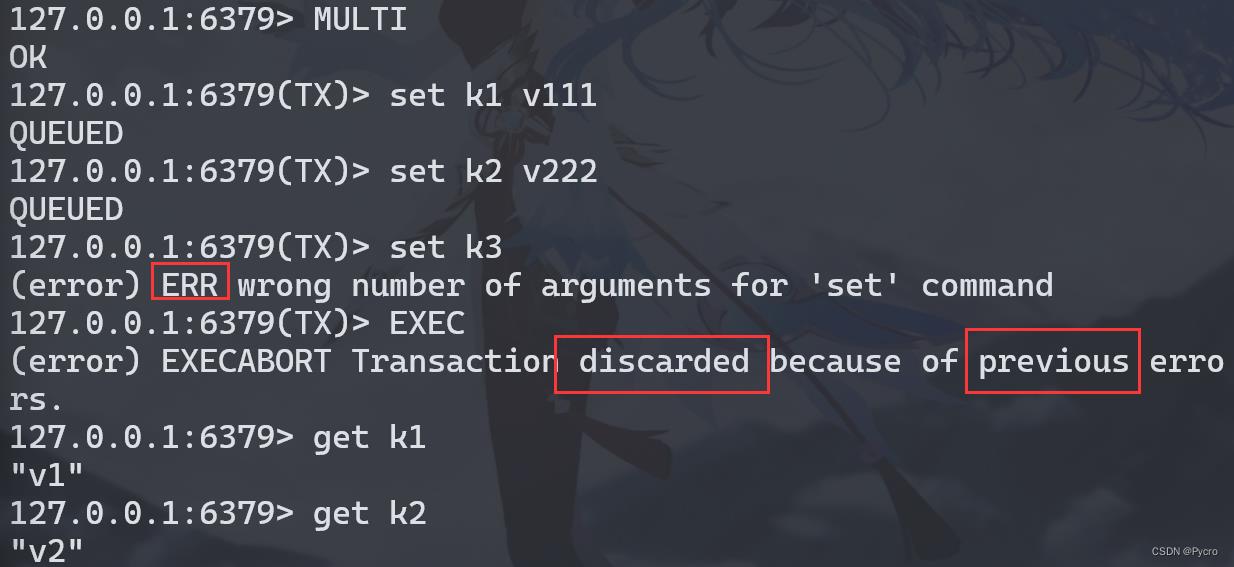
case4:冤头债主
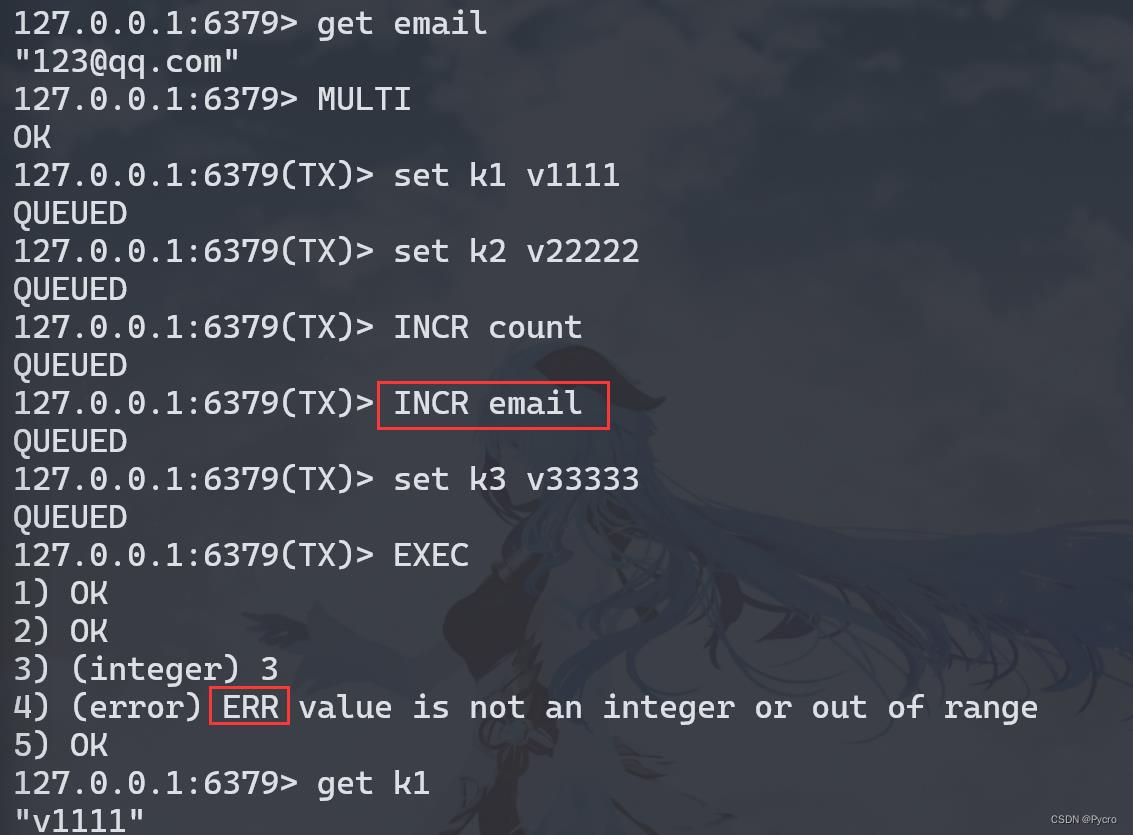
注意和传统数据库事务区别,不一定要么一起成功要么一起失败。
case5:watch监控
Redis使用Watch来提供乐观锁定,类似于CAS(Check-and-Set)
悲观锁
悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
乐观锁
乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
乐观锁策略:提交版本必须大于记录当前版本才能执行更新(Git等版本控制工具采用的策略)。
CAS

watch
初始化k1和balance两个key,先监控再开启multi,保证两key变动在同一个事务内
有加塞篡改,在另一个客户端修改balance,再回到原来的客户端执行exec命令,结果全部失败。

unwatch
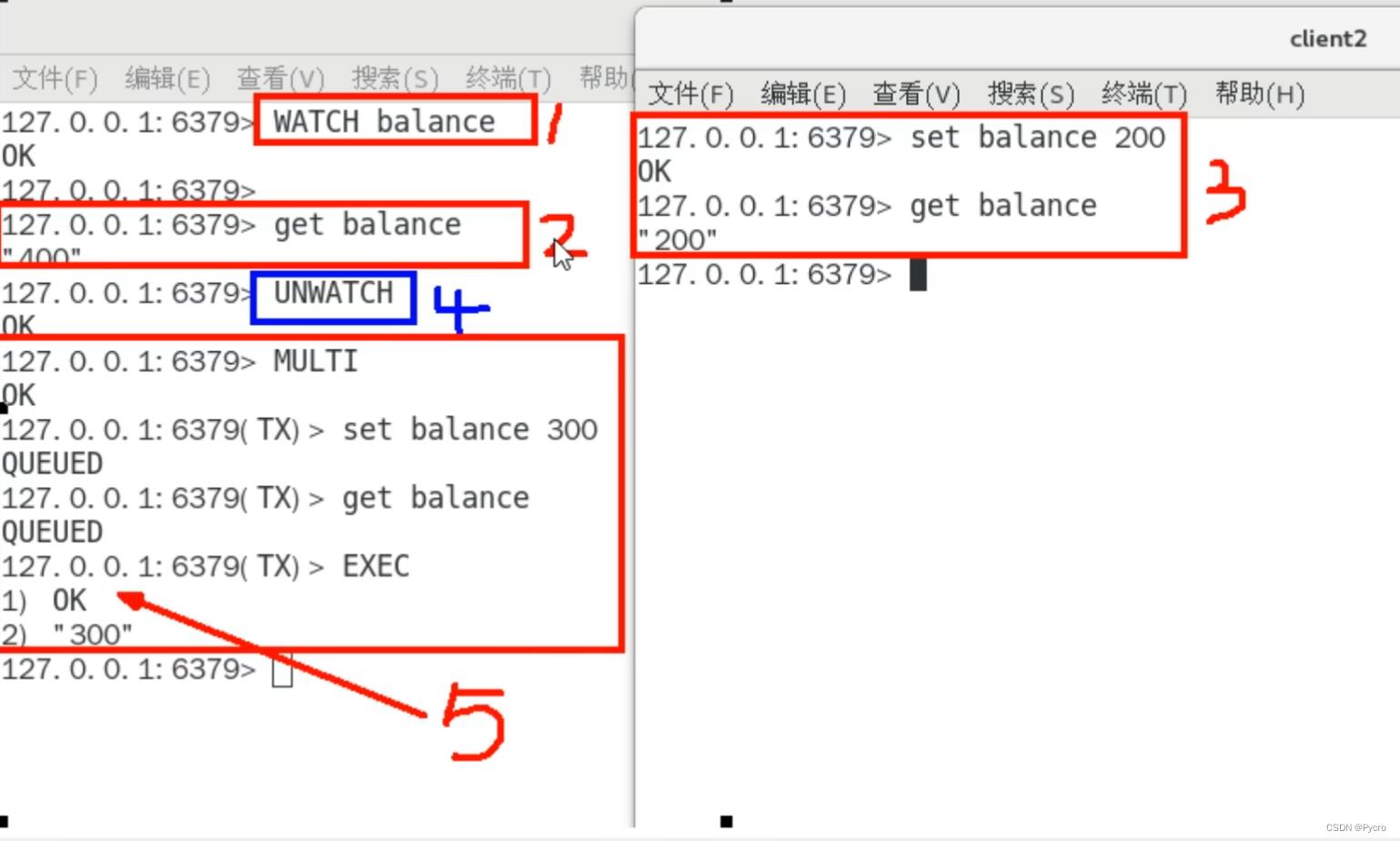
小结
-
一旦执行了exec之前加的监控锁都会被取消掉。
-
当客户端连接丢失的时候(比如退出链接),所有东西都会被取消监视。
总结
开启:以MULTI开始一个事务
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
执行:由EXEC命令触发事务
Redis学习笔记 Redis事务生存时间及排序
1. Redis事务
Redis中的事务(transaction)是一组命令的集合,一个事务中的命令要么都执行,要么都不执行。事务的原理是先将属于一个事务的命令发送给Redis,然后再让Redis依次执行这些命令。
127.0.0.1:6379> multi OK 127.0.0.1:6379> sadd user:1:following 2 QUEUED 127.0.0.1:6379> sadd user:2:followers 1 QUEUED 127.0.0.1:6379> EXEC 1) (integer) 1 2) (integer) 1
multi命令告诉redis,发送的sadd命令属于同一个事务,先将其暂存起来,随后Redis没有执行这些命令,返回QUEUE表示这两条命令已进入等待执行的事务队列。EXEC命令将等待执行的事务队列中的所有命令按发送顺序依次执行,其返回值为这些命令的返回值组成的列表。
若在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令均不执行;客户端若发送了EXEC命令,即使客户端断线,事务队列中的命令也会执行。Redis中的事务也能保证一个事务内的命令依次执行而不被其他命令插入。
(1) 错误处理
1) 语法错误,当命令不存在或命令参数个数不对。只要一个命令有语法错误,执行EXEC命令后Redis就会直接返回错误,语法正确也不会执行。
例:
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> SET key value QUEUED 127.0.0.1:6379> SET key (error) ERR wrong number of arguments for ‘set‘ command 127.0.0.1:6379> ERRORCOMMAND key (error) ERR unknown command ‘ERRORCOMMAND‘ 127.0.0.1:6379> EXEC (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379>
2) 运行错误,指在命令执行时出现的错误,在事务中这样的命令会被Redis接受并执行,若事务中一条命令出现运行错误,其他命令依然会执行。
例:
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> SET key 1 QUEUED 127.0.0.1:6379> SADD key 2 QUEUED 127.0.0.1:6379> SET key 3 QUEUED 127.0.0.1:6379> EXEC 1) OK 2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 3) OK
注:Redis的事务没有关系数据库事务提供的回滚(rollback)功能。
(2) WATCH命令
在某些情况下,需要先获得一条命令的返回值,然后再根据该值执行下一条命令。WAHCH命令可以监控一个或多个键,一旦其中有一个键被修改,之后的事务就不会执行。监控一直持续到EXEC命令(事务中的命令是在EXEC之后才执行的,所以在MULTI命令后可以修改WATCH监控的键值)。
例:
127.0.0.1:6379> SET key 1 OK 127.0.0.1:6379> WATCH key OK 127.0.0.1:6379> SET key 2 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> SET key 3 QUEUED 127.0.0.1:6379> EXEC (nil)
例:通过事务实现incr函数
def incr($key) WATCH $key $value = GET $key if not $value $value = 0 $value = $value + 1 MULTI SET $key $value result = EXEC return result[0]
执行EXEC命令后会取消对所有键的监控,若不想执行事务中的命令也可以使用UNWATCH命令来取消监控。
例:实现与HSETNX命令类似的函数hsetxx
def hsetxx($key,$field,$value) WATCH $key $isFieldExists = HEXISTS $key, $field # 判断要赋值的字段是否存在 if $isFieldExists is 1 MULTI HSET $key, $field, $value EXEC else #不存在时需使用UNWATCH保证下一个事务的执行不回受到影响。 UNWATCH return $isFieldExists
2. 生存时间
(1) 在Redis中可以使用EXPIRE命令设置一个键的生存时间,到时间后Redis会自动删除它。格式为:EXPIRE key seconds,seconds参数表示键的生存时间,单位是秒。
例:
127.0.0.1:6379> set session:29e3d uid1314 OK # 设置键在15分钟被删除,返回1表示设置成功,返回0表示不存在或设置失败 127.0.0.1:6379> EXPIRE session:29e3d 900 (integer) 1 127.0.0.1:6379> del session:29e3d (integer) 1 127.0.0.1:6379> EXPIRE session:29e3d 900 (integer) 0
可以使用TTL命令查询键的剩余时间。注意:返回值为-1时表示没有为键设置生存时间,即永久存在。
例:
127.0.0.1:6379> SET foo bar OK 127.0.0.1:6379> EXPIRE foo 20 (integer) 1 127.0.0.1:6379> TTL foo (integer) 14 #当键不存在时TTL命令会返回-2 127.0.0.1:6379> TTL foo (integer) -2
使用PERSIST命令可以取消键的生存时间设置,生存时间成功清除返回1。
例:
127.0.0.1:6379> set foo bar OK 127.0.0.1:6379> EXPIRE foo 40 (integer) 1 127.0.0.1:6379> ttl foo (integer) 36 127.0.0.1:6379> PERSIST foo (integer) 1 127.0.0.1:6379> TTL foo (integer) -1
使用SET或GETSET命令为键赋值也会同时清除键的生存时间,如:
127.0.0.1:6379> EXPIRE foo 40 (integer) 1 127.0.0.1:6379> TTL foo (integer) 36 127.0.0.1:6379> SET foo bar OK 127.0.0.1:6379> TTL foo (integer) -1
使用EXPIRE命令会重新设置键的生存时间,其余只对键进行操作的命令均不会影响键的生存时间。
EXPIRE命令的seconds参数最小单位是1秒,PEXPIRE命令的单位是毫秒,对应的可以使用PTTL命令以毫秒为单位返回键的剩余时间。
若使用WATCH命令监测一个拥有生存时间的键,该键时间到期自动删除并不会被WATCH命令认为该键被改变。
EXPIREAT(PEXPIREAT)与EXPIRE(PEXPIRE)的差别在于前者使用UNIX时间戳作为生存时间的截止时间,如:
127.0.0.1:6379> SET foo bar OK 127.0.0.1:6379> EXPIRE foo 1455113775 (integer) 1 127.0.0.1:6379> TTL foo (integer) 1455113770 127.0.0.1:6379> PEXPIRE foo 1455113675000 (integer) 1 127.0.0.1:6379> TTL foo (integer) 1455113671
(2) 实现访问频率
限制每分钟每个用户最多只能访问100个页面:
$isKeyExists = EXISTS rate.limiting:$IP if $isKeyExists is 1 $times = INCR rate.limiting:$IP if $times > 100 print 访问频率超过了限制,请稍后再试 exit else MULTI INCR rate.limiting:$IP EXPIRE $keyName, 60 EXEC
3. 排序
(1) 有序集合的集合操作
对于不常用到的或在不损失过多性能的前提下可使用现有命令实现的功能,Redis就不会单独提供命令来实现。
(2) SORT命令
SORT命令可以对列表、集合、有序集合进行排序,并完成与关系数据库中的连接查询相类似的任务。
例:
# 对集合进行排序 127.0.0.1:6379> SADD tag:ruby:posts 2 12 6 26 (integer) 6 127.0.0.1:6379> SORT tag:ruby:posts 1) "2" 2) "6" 3) "12" 4) "26" # 对列表进行排序 127.0.0.1:6379> lpush list 4 2 6 1 3 7 (integer) 6 127.0.0.1:6379> lrange list 0 -1 1) "7" 2) "3" 3) "1" 4) "6" 5) "2" 6) "4" 127.0.0.1:6379> sort list 1) "1" 2) "2" 3) "3" 4) "4" 5) "6" 6) "7" # 对有序集合进行排序,会忽略元素的分数,只针对元素自身的值进行排序 127.0.0.1:6379> ZADD myzset 50 2 40 3 20 1 60 5 (integer) 4 127.0.0.1:6379> ZRANGE myzset 0 -1 withscores 1) "1" 2) "20" 3) "3" 4) "40" 5) "2" 6) "50" 7) "5" 8) "60" 127.0.0.1:6379> SORT myzset 1) "1" 2) "2" 3) "3" 4) "5"
SORT命令也可通过ALPHA参数实现按照字典顺序排列非数字元素:
127.0.0.1:6379> LPUSH mylistalpha a c e d B C A (integer) 7 127.0.0.1:6379> SORT mylistalpha (error) ERR One or more scores can‘t be converted into double 127.0.0.1:6379> SORT mylistalpha ALPHA 1) "a" 2) "A" 3) "B" 4) "c" 5) "C" 6) "d" 7) "e"
SORT命令的DESC参数可以实现将元素按照从大到小的顺序排列:
127.0.0.1:6379> SORT tag:ruby:posts DESC 1) "26" 2) "12" 3) "6" 4) "2"
SORT命令还支持LIMIT参数返回指定范围的结果,格式为LIMIT offset count,表示跳过offset个元素并获取之后的count个元素。
127.0.0.1:6379> SORT tag:ruby:posts DESC LIMIT 1 2 1) "12" 2) "6"
SORT对文章ID排序意义不大,如博客使用散列类型存储文章对象,time字段对应文章的发布时间,ID为2,6,12,26的四篇文章的time字段分别为1452619200,1452619600,1452620100,1452620000,如果按照文章的发布时间递减排序结果应为12,26,6,2,可通过SORT的BY参数可以实现。格式为:BY 参考键,其中参考键可为字符串类型键或散列类型键的某个字段(表示为键名->字段名)。SORT命令对每个元素使用元素的值替换参考键的第一个"*"并获取其值,然后依据该值对元素排序。
127.0.0.1:6379> HSET post:2 time 1452619200 (integer) 1 127.0.0.1:6379> HSET post:6 time 1452619600 (integer) 1 127.0.0.1:6379> HSET post:12 time 1452620100 (integer) 1 127.0.0.1:6379> HSET post:26 time 1452620000 (integer) 1 # 散列类型 127.0.0.1:6379> SORT tag:ruby:posts BY post:*->time DESC 1) "12" 2) "26" 3) "6" 4) "2" #字符串类型 127.0.0.1:6379> LPUSH sortbylist 2 1 3 (integer) 3 127.0.0.1:6379> SET itemscore:1 50 OK 127.0.0.1:6379> SET itemscore:2 100 OK 127.0.0.1:6379> SET itemscore:3 -10 OK 127.0.0.1:6379> LRANGE sortbylist 0 -1 1) "3" 2) "1" 3) "2" 127.0.0.1:6379> SORT sortbylist by itemscore:* DESC 1) "2" 2) "1" 3) "3" # 当参考键名不包含"*"时,SORT命令将不会执行排序操作 127.0.0.1:6379> SORT sortbylist by anytext 1) "3" 2) "1" 3) "2" # 如果几个元素的参考值相同,则SORT命令会再比较元素本身的值来决定元素的顺序 127.0.0.1:6379> SORT sortbylist BY itemscore:* DESC 1) "2" 2) "4" 3) "1" 4) "3" # 当某个元素的值不存在时,会默认参考键的值为0 127.0.0.1:6379> SORT sortbylist BY itemscore:* DESC 1) "2" 2) "4" 3) "1" 4) "5" 5) "3"
注:参考键虽然支持散列类型,但是"*"只能在"->"符号前面(即键名部分)才有用,在"->"后(即字段名部分)会被当成字段名本身而不会作为占位符被元素的值替换,即常量键名,因此如下结果:
127.0.0.1:6379> SORT sortbylist BY itescore:2->itemscore:* 1) "1" 2) "2" 3) "3" 4) "4" 5) "5"
SORT的GET参数不影响排序,它的作用时使SORT命令返回结果不再是元素自身的值,而是GET参数中指定的键值,GET参数也支持字符串类型和散列类型的键,并使用"*"作为占位符。
127.0.0.1:6379> HSET post:2 title Java (integer) 1 127.0.0.1:6379> HSET post:6 title MySQL (integer) 1 127.0.0.1:6379> HSET post:12 title Redis (integer) 1 127.0.0.1:6379> HSET post:26 title Hadoop (integer) 1 127.0.0.1:6379> SORT tag:ruby:posts BY post:*->time DESC GET post:*->title 1) "Redis" 2) "Hadoop" 3) "MySQL" 4) "Java" # SORT命令可以有多个GET参数,BY参数只能有一个 127.0.0.1:6379> SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->time 1) "Redis" 2) "1452620100" 3) "Hadoop" 4) "1452620000" 5) "MySQL" 6) "1452619600" 7) "Java" 8) "1452619200" # "GET #"可以返回文章的ID,"GET #"会返回元素本身的值 127.0.0.1:6379> SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->time GET # 1) "Redis" 2) "1452620100" 3) "12" 4) "Hadoop" 5) "1452620000" 6) "26" 7) "MySQL" 8) "1452619600" 9) "6" 10) "Java" 11) "1452619200" 12) "2"
SORT命令的STORE参数可以将排序结果保存起来,保存后的键的类型为list,返回值为list的个数:
127.0.0.1:6379> SORT tag:ruby:posts BY post:*->time DESC GET post:*->title GET post:*->time GET # STORE sort.result (integer) 12 127.0.0.1:6379> TYPE sort.result list 127.0.0.1:6379> LRANGE sort.result 0 -1 1) "Redis" 2) "1452620100" 3) "12" 4) "Hadoop" 5) "1452620000" 6) "26" 7) "MySQL" 8) "1452619600" 9) "6" 10) "Java" 11) "1452619200" 12) "2"
STORE参数常用来结合EXPIRE命令缓存排序结果:
#判断是否存在之前排序结果的缓存 $isCacheExists = EXISTS cache.sort if $isCacheExists is 1 # 若存在,直接返回 return LRANGE cache.sort 0 -1 else # 若不存在,则使用SORT命令排序并将结果存入cache.sort键中作为缓存 $sortResult = SORT some.list STORE cache.sort # 设置缓存的生存时间为10分钟 EXPIRE cache.sort 600 # 返回排序结果 return $sortResult
注:SORT命令的时间复杂度是O(n+mlogm),其中n表示要排序的列表中元素的个数,m表示要返回的元素个数,所以在开发中使用SORT命令需注意:1)尽可能减少待排序键中元素的数量;2)使用LIMIT参数只获取需要的数据;3)如果要排序的数据数量较大,尽可能使用STORE参数将结果缓存。
以上是关于Redis学习Redis事务的主要内容,如果未能解决你的问题,请参考以下文章