分库分表sharding-jdbc实践—分库分表入门
Posted Mr.yang.localhost
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分库分表sharding-jdbc实践—分库分表入门相关的知识,希望对你有一定的参考价值。
一、准备工作
1、准备三个数据库:db0、db1、db2
2、每个数据库新建两个订单表:t_order_0、t_order_1
DROP TABLE IF EXISTS `t_order_x`; CREATE TABLE `t_order_x` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_id` bigint NOT NULL, `order_id` bigint NOT NULL, `order_no` varchar(30) NOT NULL, `isactive` tinyint NOT NULL DEFAULT \'1\', `inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
二、分库分表配置
数据源的配置可以使用任何链接池,本例用druid为例。
1、引言依赖包:
引用最新的maven包
<sharding-jdbc.version>2.0.1</sharding-jdbc.version>
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
2、配置DataSource:
@Bean(name = "shardingDataSource", destroyMethod = "close") @Qualifier("shardingDataSource") public DataSource getShardingDataSource() { // 配置真实数据源 Map<String, DataSource> dataSourceMap = new HashMap<>(3); // 配置第一个数据源 DruidDataSource dataSource1 = createDefaultDruidDataSource(); dataSource1.setDriverClassName("com.mysql.jdbc.Driver"); dataSource1.setUrl("jdbc:mysql://localhost:3306/db0"); dataSource1.setUsername("root"); dataSource1.setPassword("root"); dataSourceMap.put("db0", dataSource1); // 配置第二个数据源 DruidDataSource dataSource2 = createDefaultDruidDataSource(); dataSource2.setDriverClassName("com.mysql.jdbc.Driver"); dataSource2.setUrl("jdbc:mysql://localhost:3306/db1"); dataSource2.setUsername("root"); dataSource2.setPassword("root"); dataSource2.setName("db1-0001"); dataSourceMap.put("db1", dataSource2); // 配置第三个数据源 DruidDataSource dataSource3 = createDefaultDruidDataSource(); dataSource3.setDriverClassName("com.mysql.jdbc.Driver"); dataSource3.setUrl("jdbc:mysql://localhost:3306/db2"); dataSource3.setUsername("root"); dataSource3.setPassword("root"); dataSourceMap.put("db2", dataSource3); // 配置Order表规则 TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration(); orderTableRuleConfig.setLogicTable("t_order"); orderTableRuleConfig.setActualDataNodes("db${0..2}.t_order_${0..1}"); //orderTableRuleConfig.setActualDataNodes("db0.t_order_0,db0.t_order_1,db1.t_order_0,db1.t_order_1,db2.t_order_0,db2.t_order_1"); // 配置分库策略(Groovy表达式配置db规则) orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "db${user_id % 3}")); // 配置分表策略(Groovy表达式配置表路由规则) orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_${order_id % 2}")); // 配置分片规则 ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig); // 配置order_items表规则... // 获取数据源对象 DataSource dataSource = null; try { dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), new Properties()); } catch (SQLException e) { e.printStackTrace(); } return dataSource; }
可以使用Druid监控db。
三、示例验证
1、新增数据
@Slf4j @RestController @RequestMapping("/order") public class OrderController { @Autowired private OrderMapper orderMapper; @RequestMapping("/add") public void addOrder() { OrderEntity entity10 = new OrderEntity(); entity10.setOrderId(10000L); entity10.setOrderNo("No1000000"); entity10.setUserId(102333001L); orderMapper.insertSelective(entity10);
OrderEntity entity11 = new OrderEntity(); entity11.setOrderId(10001L); entity11.setOrderNo("No1000000"); entity11.setUserId(102333000L); orderMapper.insertSelective(entity11); } }
依据配置的分片规则
- DB路由规则:user_id % 3:
102333001 % 3 = 1
102333000 % 3 = 0
- 表路由规则:order_id % 2:
10000 % 2 = 0
10001 % 2 = 1
userid=102333001,orderId=10000的数据落地到db1.t_order_0
userid=102333000,orderId=10001的数据落地到db0.t_order_1
2、未指定分片规则字段的查询
/**广播遍历所有的库和表*/ @RequestMapping("get") public void getOrder() { List<Integer> ids = new ArrayList<>(); ids.add(4); List<OrderEntity> orderEntities = orderMapper.selectByPrimaryIds(ids); log.info(JSON.toJSONString(orderEntities)); }
由druid监控sql得知,查询被广播到db0、db1、db2的各个表里,如下监控所示:
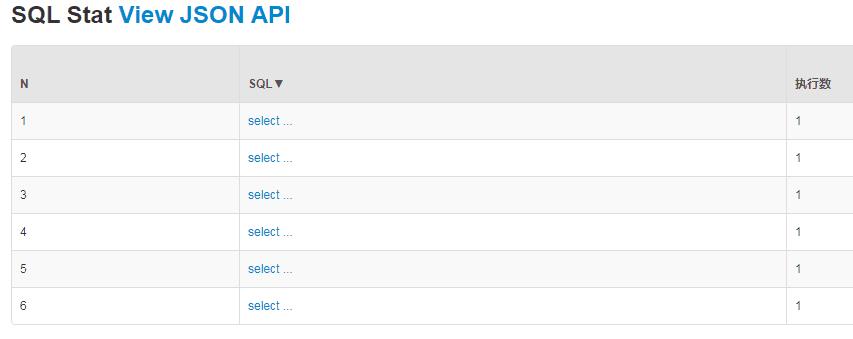
3、不能执行批量插入操作
不支持对不同分片规则的字段值进行批量插入操作,类似sql:insert into t_order values(x,x,x,x),(x,x,x,x),(x,x,x,x)
4、谨慎修改分片规则字段
如果修改了分片规则的字段,比如本例的user_id或order_id,因为路由规则会造成数据存在,却查不到数据的情况。
@RequestMapping("/upd")
public void update() {
OrderEntity orderWhere = new OrderEntity();
orderWhere.setOrderId(10001L);
orderWhere.setUserId(102333001L);
orderWhere.setId(4L);
OrderEntity orderSet = new OrderEntity();
orderSet.setOrderId(10002L);
orderSet.setOrderNo("修改订单号");
orderMapper.updateByPredicate(orderSet, orderWhere);
/**查不到,orderId更改会引起路由查询失败*/
OrderEntity predicate = new OrderEntity();
predicate.setOrderId(10002L);
OrderEntity entity = orderMapper.selectSingleByPredicate(predicate);
log.info("after update orderEntity:"+JSON.toJSONString(entity));
}
四、sharding建表
目前配置并验证了3个库,每库2个order表的场景:
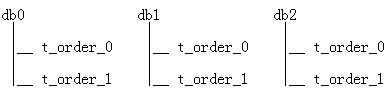
如果分库分表数量比较多,仅仅创建表就是一件很繁琐的事情。sharding查询数据不指定分片规则字段时,会自动路由到各个库的各个表里查询,不知道大家有没有想到:如果配置要创建表的路由规则,用sharding来执行一条创建sql的语句,会不会就自动路由到各个库去执行了,也就代替人工去各个库建表了呢?下面来验证一下这个想法,以创建t_order_items表为例:
1、配置t_order_items的规则
在上面配置t_order规则下面补充t_order_items的规则配置:
// 省略配置order_item表规则... TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration(); orderItemTableRuleConfig.setLogicTable("t_order_items"); orderItemTableRuleConfig.setActualDataNodes("db${0..2}.t_order_items_${0..1}");// 配置分库策略 orderItemTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "db${order_id % 3}")); // 配置分表策略 orderItemTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_items_${order_id % 2}")); shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRuleConfig);
2、t_order_items建表sql语句
<update id="createTItemsIfNotExistsTable">
CREATE TABLE IF NOT EXISTS `t_order_items` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_id` bigint NOT NULL,
`unique_no` varchar(32) NOT NULL,
`quantity` int NOT NULL DEFAULT \'1\',
`is_active` tinyint NOT NULL DEFAULT 1,
`inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
</update>
3、OrderItemsMapper方法
Integer createTItemsIfNotExistsTable();
4、执行方法
orderItemsMapper.createTItemsIfNotExistsTable();
查看db0、db1、db2:
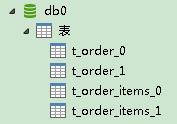


验证了我们上面的想法,建表成功了。
附录
如果没有配置t_order_items规则,执行建表sql会报错:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error updating database. Cause: io.shardingjdbc.core.exception.ShardingJdbcException: Cannot find table rule and default data source with logic table: \'t_order_items\'
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: CREATE TABLE IF NOT EXISTS `t_order_items` ( `id` bigint NOT NULL AUTO_INCREMENT, `order_id` bigint NOT NULL, `unique_no` varchar(32) NOT NULL, `quantity` int NOT NULL DEFAULT \'1\', `is_active` tinyint NOT NULL DEFAULT 1, `inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
### Cause: io.shardingjdbc.core.exception.ShardingJdbcException: Cannot find table rule and default data source with logic table: \'t_order_items\'
以上是关于分库分表sharding-jdbc实践—分库分表入门的主要内容,如果未能解决你的问题,请参考以下文章