音视频基础知识-时间戳的理解
Posted LceChan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音视频基础知识-时间戳的理解相关的知识,希望对你有一定的参考价值。
问题背景:
凡是和流媒体和音视频打交道,时间戳基本是一个必须深刻理解的概念。你会在各种各样的传输协议和封装格式中看到这个东西,而且表现形式还不一样。其次这个概念会涉及到音视频播放的同步问题,也会影响音视频播放的控制问题。前者说的是音画同步,后者说的是类似快进,随机点播放等。如果要理解好这个概念,需要掌握下面几个名词的含义。
基本概念:
采样率
音视频现在采用的数字编码方法,简单说就是把音视频这种波形和图像进行采集,量化,编码,传输,解码。所以采样率就是每秒钟抽取图像或者声波幅度样本的次数。比如音频采样率8k,就是表示把波形进行每秒8000次采样。
我们看到一秒的采样频率其实挺大的,至于这个值是多少合理,其实无论视频还是音频都和人的视觉特征和听觉特征有关系。
对于人的视觉而言,只要1秒钟播放的视频达到25帧以上,我们就看到了连续的图像即为视频。如果低于这个值,我们人眼就能感觉出来卡顿。
对于人的听觉而言,正常的听觉频率范围在20Hz-20kHz,根据奎斯特采样理论,为了保证音频不失真,我们的采样频率应该在40kHz左右。为什么采样率不是越高越好呢,因为采样率越高意味着你传输的数据量越多,这样给编码和传输都带了极大的负担,成本也是个重要考虑因素。
帧率
帧率就是每秒显示的帧数,比如30fps就是1秒显示30帧图像。但是对于音频可能理解帧率不太好理解,这有点抽象。对于音频,不同的编码方式比如AAC和mp3分别就规定1024采样sample,mp3每帧为1152采样,如果一个采样用一个字节表示,那就是1024字节AAC编码音频为一帧,1152字节为MP3编码方式的音频一帧。
时间戳单位
前面我们提到采样率,感觉到采样率是个很大的单位,一般标准的音频AAC采样率达到了44kHz,视频采样率也规定在90000Hz.所以我们衡量时间的单位不能再是秒,毫秒这种真实的时间单位,我们的单位应该转换为采样率,也就是一个采样的时间为音视频的时间单位,这就是时间戳的真实值。当我们要播放和控制时,我们再将时间戳根据采样率转换为真实的时间即可。
一句话,时间戳不是真实的时间是采样次数。比如时间戳是160,我们不能认为是160秒或者160毫秒,应该是160个采样。要换算真实时间,我们必须知道采样率,比如8000,那么说明1秒被划分成8000分之一,如果你要明确160个采样占用的时间,则160*(1/8000)即可,即20毫秒。
时间戳增量
就是一帧图像和另外一帧图像之间的时间戳差值,或者一帧音频和一帧音频的时间戳差值。同理时间戳增量也是采样个数的差值不是真实时间差值,还是要根据采样率才能换算成真实时间。
所以对于视频和音频的时间戳计算要一定明确帧率是多少,采样率是多少。
比如视频而言,帧率25,那么对于90000的采样率来说,一帧占用的采样数就是90000/25也就是3600,说明每帧图像的时间戳增量应该是3600,换算成实际时间就是3600*(1/90000)=0.04秒=40毫秒,这也和1/25=0.04秒=40毫秒一致。
对于AAC音频,一帧1024个采样,采样频率是44kHz,所以一帧的播放时间应该是1024*(1/44100)=0.0232秒=23.22毫秒。
同步方法:
上面说了时间戳重要的功能就是来为了音视频的同步,那么这个时间戳到底是如何让音视频同步的呢?
播放器本地需要建立一个系统时钟,这个时钟一般是根据CPU时间计算出来的,当播放开始时时钟时间为0,时间戳决定了一帧解码和渲染的时刻。当播放开始,时钟时间会进行增加,播放器会用系统时钟和当前视频和音频的时间戳进行比较,如果音视频的时间戳小于当前系统时钟,那么就要晚点进行解码和渲染播放。
可以看到播放能否准确进行需要编码器打的时间戳必须精确,同时播放器端的系统时钟也精确,因为播放时要基于时间戳和这个系统时钟对数据流进行控制,也就是对数据块要根据时间戳来采取不同的处理方法。实际无论编码器还是本地播放器都不能非常精确,所以我们说固定帧率25,也有可能编码器一遍打24帧的现象出现。为了解决这个累计误差问题,一般我们需要在播放端有一套反馈机制,能够消除这种误差。其实,同步是一个动态的过程,是一个有人等待、有人追赶的过程。同步只是暂时的,而不同步才是常态。人们总是在同步的水平线上振荡波动,但不会偏离这条基线太远。
视频理解综述:动作识别时序动作定位视频Embedding
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
选自丨机器之心
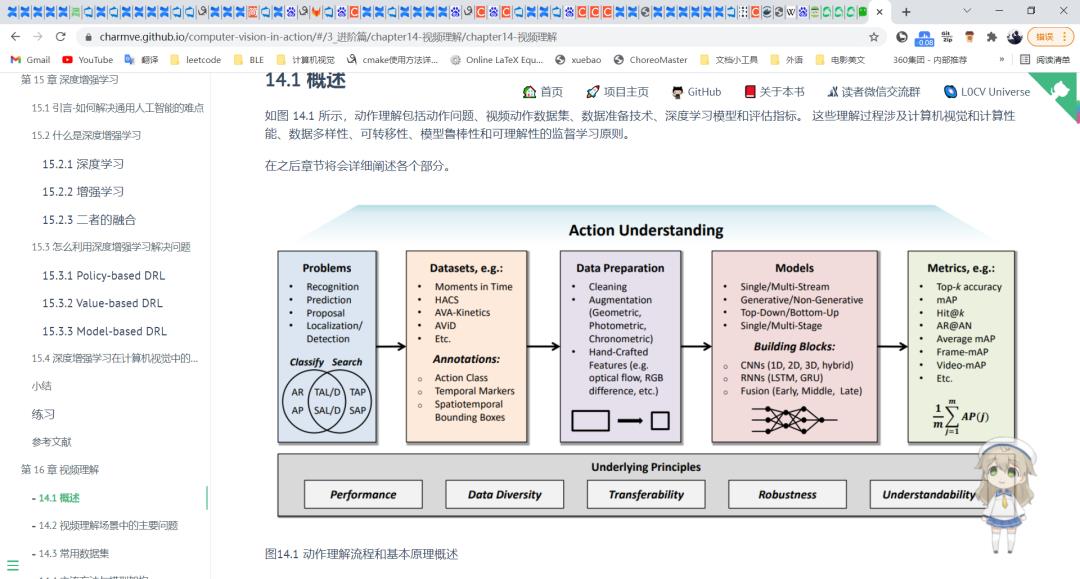
本文将介绍视频理解中的三大基础领域:动作识别(Action Recognition)、时序动作定位(Temporal Action Localization)和视频 Embedding。
1.视频理解背景
根据中国互联网络信息中心(CNNIC)第 47 次《中国互联网络发展状况统计报告》,截至 2020 年 12 月,中国网民规模达到 9.89 亿人,其中网络视频(含短视频)用户规模达到 9.27 亿人,占网民整体的 93.7%,短视频用户规模为 8.73 亿人,占网民整体的 88.3%。
回顾互联网近年来的发展历程,伴随着互联网技术(特别是移动互联网技术)的发展,内容的主流表现形式经历了从纯文本时代逐渐发展到图文时代,再到现在的视频和直播时代的过渡,相比于纯文本和图文内容形式,视频内容更加丰富,对用户更有吸引力。
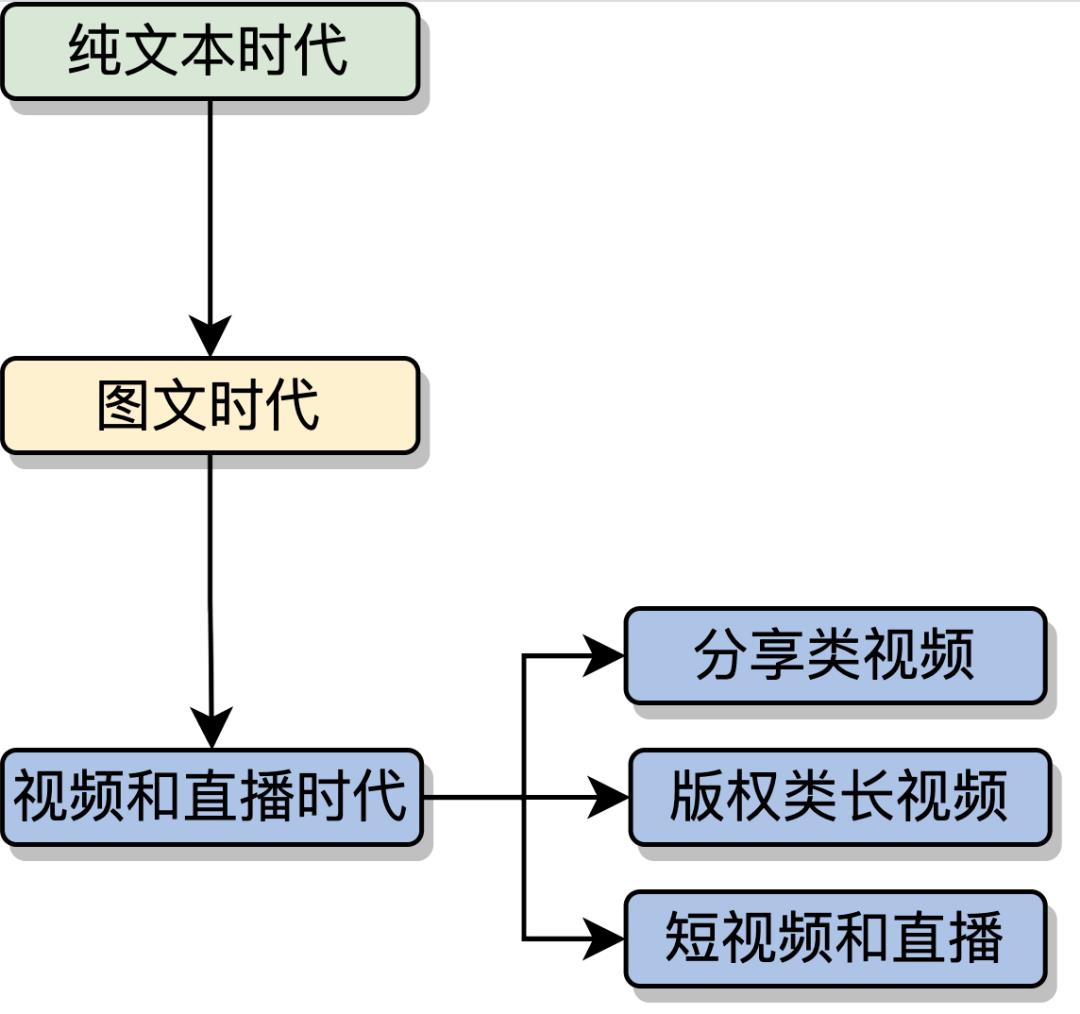
图 1:互联网内容表现形式的 3 个阶段。本图源于《深度学习视频理解》
随着近年来人们拍摄视频的需求更多、传输视频的速度更快、存储视频的空间更大,多种场景下积累了大量的视频数据,需要一种有效地对视频进行管理、分析和处理的工具。视频理解旨在通过智能分析技术,自动化地对视频中的内容进行识别和解析。视频理解算法顺应了这个时代的需求。因此,近年来受到了广泛关注,取得了快速发展。
视频理解涉及生活的多个方面,目前视频理解已经发展成一个十分广阔的学术研究和产业应用方向。受篇幅所限,本文将介绍视频理解中的三大基础领域: 动作识别 (Action Recognition)、时序动作定位(Temporal Action Localization) 和视频 Embedding。

图 2:视频理解涉及的部分任务。本图源于《深度学习视频理解》
2. 动作识别(Action Recognition)
2.1 动作识别简介
动作识别的目标是识别出视频中出现的动作,通常是视频中人的动作。视频可以看作是由一组图像帧按时间顺序排列而成的数据结构,比图像多了一个时间维度。动作识别不仅要分析视频中每帧图像的内容,还需要从视频帧之间的时序信息中挖掘线索。动作识别是视频理解的核心领域,虽然动作识别主要是识别视频中人的动作,但是该领域发展出来的算法大多数不特定针对人,也可以用于其他视频分类场景。
动作识别看上去似乎是图像分类领域向视频领域的一个自然延伸,深度学习尽管在图像分类领域取得了举世瞩目的成功,目前深度学习算法在图像分类上的准确率已经超过普通人的水平,但是,深度学习在动作识别领域的进展并不像在图像分类领域那么显著,很长一段时间基于深度学习算法的动作识别准确率达不到或只能接近传统动作识别算法的准确率。概括地讲,动作识别面临以下几点困难:
训练视频模型所需的计算量比图像大了一个量级,这使得视频模型的训练时长和训练所需的硬件资源相比图像大了很多,导致难以快速用实验进行验证和迭代;
在 2017 年,Kinetics 数据集 (Carreira & Zisserman, 2017) 诞生之前, 缺少大规模通用的视频基准 (Benchmark) 数据集。在很长一段时间里,研究者都是在如 UCF-101 数据集 (Soomro et al., 2012) 上比较算法准 确率,而 UCF-101 只有 1.3 万条数据,共 101 个类别,平均每个类别只有约 100 个视频,相比于图像分类领域的 ImageNet 数据集有 128 万 条数据,共 1000 个类别,平均每个类别约有 1,000 个视频,UCF-101 数据集显得十分小。数据集规模制约了动作识别领域的发展;
学习视频中帧之间的时序关系,尤其是长距离的时序关系,本身就比较难。不同类型的动作变化快慢和持续时长有所不同,不同的人做同一个动作的方式也存在不同,同时相机拍摄角度和相机自身的运动也会对识别带来挑战。此外,不是视频中所有的帧对于动作识别都有相同的作用,有许多帧存在信息冗余;
网络结构设计缺少公认的方案。图像分类领域的网络结构设计有一些公认的指导理念,例如,端到端训练、小卷积核、从输入到输出空间分辨率不断降低且通道数不断增大等。然而,在动作识别领域,同时存在多个网络设计理念,例如,帧之间的时序关系应该如何捕捉、使用 2D 卷积还是 3D 卷积、不同帧的特征应该如何融合等都还没有定论。
2.2 基于 2D 卷积的动作识别
视频是由一系列图像帧(Frame)组成的,图像分类模型经过这些年的发展已经相对成熟。如何进行视频分类呢?一种直观的想法是将图像分类的模型直接运用到视频分类中。如下图所示,一个简单的想法是先把视频各帧提取出来,每帧图像各自前馈(Feedforward)一个图像分类模型,不同帧的图像分类模型之间相互共享参数。得到每帧图像的特征之后,对各帧图像特征进行汇合(Pooling),例如采用平均汇合,得到固定维度的视频特征,最后经过一个全连接层和 Softmax 激活函数进行分类以得到视频的类别预测。
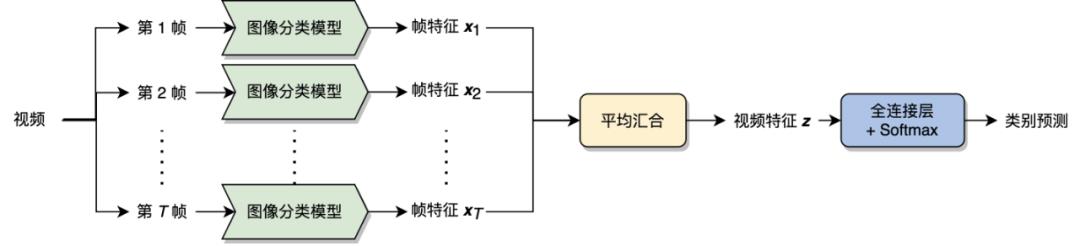
图 3:利用图像分类模型和平均汇合进行动作识别网络结构图。本图源于《深度学习视频理解》
平均汇合方法十分简单,其视频分类的准确率与其他同时期专门为动作识别设计的深度学习模型相比差距并不大 (Karpathy et al., 2014) ,但是与传统动作识别算法的准确率相比还有很大差距,不过后来专门为动作识别设计的深度学习模型的准确率高了很多。
最直观的想法是先把视频拆成一帧帧的图像,每帧图像各自用一个图像分类模型得到帧级别的特征,然后用某种汇合方法从帧级别特征得到视频级别特征,最后进行分类预测,其中的汇合方法包括: 平均汇合、NetVLAD/NeXtVLAD、NetFV、RNN、3D 卷积等。另外,我们可以借助一些传统算法来补充时序关系,例如,双流法利用光流显式地计算帧之间的运动关系,TDD 利用 iDT 计算的轨迹进行汇合等。基于 2D 卷积的动作识别方法的一个优点是可以快速吸收图像分类领域的最新成果,通过改变骨架网络,新的图像分类模型可以十分方便地迁移到基于 2D 卷积的动作识别方法中。

图 4:基于 2D 卷积的动作识别算法。本图源于《深度学习视频理解》
2.3 基于 3D 卷积的动作识别
另一方面,图像是三维的,而视频比图像多了一维,是四维。图像使用的是 2D 卷积,因此视频使用的是 3D 卷积。我们可以设计对应的 3D 卷积神经网络,就像在图像分类中利用 2D 卷积可以从图像中学习到复杂的图像表示一样,利用 3D 卷积可以从视频片段中同时学习图像特征和相邻帧之间复杂的时序特征,最后利用学到的高层级特征进行分类。
相比于 2D 卷积,3D 卷积可以学习到视频帧之间的时序关系。我们可以将 2D 卷积神经网络扩展为对应的 3D 卷积神经网络,如 C3D、Res3D/3D ResNet、LTC、I3D 等。由于 3D 卷积神经网络的参数量和计算量比 2D 卷积神经网络大了很多,不少研究工作专注于对 3D 卷积进行低秩近似,如 FSTCN、P3D、R(2+1)D、S3D 等。TSM 对 2D 卷积进行改造以近似 3D 卷积的效果。3D 卷积 + RNN、ARTNet、Non-Local、SlowFast 等从不同角度学习视频帧之间的时序关系。此外,多网格训练和 X3D 等对 3D 卷积神经网络的超参数进行调整,使网络更加精简和高效。

图 5:基于 3D 卷积的动作识别算法。本图源于《深度学习视频理解》
3. 时序动作定位(Temporal Action Localization)
时序动作定位 (Temporal Action Localization) 也称为时序动作检测 (Temporal Action Detection),是视频理解的另一个重要领域。动作识别可以看作是一个纯分类问题,其中要识别的视频基本上已经过剪辑(Trimmed),即每个视频包含一段明确的动作,视频时长较短,且有唯一确定的动作类别。而在时序动作定位领域,视频通常没有被剪辑(Untrimmed),视频时长较长,动作通常只发生在视频中的一小段时间内,视频可能包含多个动作,也可能不包含动作,即为背景(Background) 类。时序动作定位不仅要预测视频中包含了什么动作,还要预测动作的起始和终止时刻。相比于动作识别,时序动作定位更接近现实场景。
时序动作定位可以看作由两个子任务组成,一个子任务是预测动作的起止时序区间,另一个子任务是预测动作的类别。由于动作识别领域经过近年来的发展,预测动作类别的算法逐渐成熟,因此时序动作定位的关键是预测动作的起止时序区间,有不少研究工作专注于该子任务,ActivityNet 竞赛除了每年举办时序动作定位竞赛,还专门组织候选时序区间生成竞赛(也称为时序动作区间提名)。
既然要预测动作的起止区间,一种最朴素的想法是穷举所有可能的区间,然后逐一判断该区间内是否包含动作。对于一个 T 帧的视频,所有可能的区间为 ,穷举所有的区间会带来非常庞大的计算量。
时序动作检测的很多思路源于图像目标检测 (Object Detection),了解目标检测的一些常见算法和关键思路对学习时序动作定位很有帮助。相比于图像分类的目标是预测图像中物体的类别,目标检测不仅要预测类别,还要预测出物体在图像中的空间位置信息,以物体外接矩形的包围盒(Bounding Box) 形式表示。
3.1 基于滑动窗的算法
这类算法的基本思路是预先定义一系列不同时长的滑动窗,之后滑动窗在视频上沿着时间维度进行滑动,并逐一判断每个滑动窗对应的时序区间内具体是什么动作类别。图 6 (a) 中使用了 3 帧时长的滑动窗,图 6 (b) 中使用了 5 帧时长的滑动窗,最终汇总不同时长的滑动窗的类别预测结果。可以知道,该视频中包含的动作是悬崖跳水、动作出现的起止时序区间在靠近视频结尾的位置。

图 6:基于滑动窗的算法流程图。本图源于《深度学习视频理解》
如果对目标检测熟悉的读者可以联想到,Viola-Jones 实时人脸检测器 (Viola & Jones, 2004) 中也采用了滑动窗的思想,其先用滑动窗在图像上进行密集滑动,之后提取每个滑动窗对应的图像区域的特征,最后通过 AdaBoost 级联分类器进行分类。Viola-Jones 实时人脸检测器是计算机视觉历史上具有里程碑意义的算法之一,获得了 2011 年 CVPR(Computer Vision and Pattern Recognition,计算机视觉和模式识别)大会用于表彰十年影响力的 Longuet-Higgins 奖。
3.2 基于候选时序区间的算法
目标检测算法中的两阶段 (Two-Stage) 算法将目标检测分为两个阶段: 第一阶段产生图像中可能存在目标 的候选区域(Region Proposal),一般一张图像可以产生成百上千个候选区域,这一阶段和具体的类别无关; 第二阶段逐一判断每个候选区域的类别并对候选区域的边界进行修正。
类比于两阶段的目标检测算法,基于候选时序区间的时序动作定位算法也将整个过程分为两个阶段: 第一阶段产生视频中动作可能发生的候选时序区间; 第 二阶段逐一判断每个候选时序区间的类别并对候选时序区间的边界进行修正。最终将两个阶段的预测结果结合起来,得到未被剪辑视频中动作的类别和起止时刻预测。

图 7:Faster R-CNN 和基于候选时序区间的方法类比。本图源于《深度学习视频理解》
3.3 自底向上的时序动作定位算法
基于滑动窗和基于候选时序区间的时序动作定位算法都可以看作是自顶向下的算法,其本质是预先定义好一系列不同时长的滑动窗或锚点时序区间,之后判断每个滑动窗位置或锚点时序区间是否包含动作并对边界进行微调以产生候选时序区间。这类自顶向下的算法产生的候选时序区间会受到预先定义的滑动窗或锚点时序区间的影响,导致产生的候选时序区间不够灵活,区间的起止位置不够精确。
本节介绍自底向上的时序动作定位算法,这类算法首先局部预测视频动作开始和动作结束的时刻,之后将开始和结束时刻组合成候选时序区间,最后对每个候选时序区间进行类别预测。相比于自顶向下的算法,自底向上的算法预测的候选时序区间边界更加灵活。了解人体姿态估计 (Human Pose Estimation) 的读者可以联想到,人体姿态估计也可以分为自顶向下和自底向上两类算法,其中自顶 向下的算法先检测出人的包围盒,之后对每个包围盒内检测人体骨骼关键点,如 (Chen et al., 2018) 等; 自底向上的算法先检测所有的人体骨骼关键点,之后再组合成人,如 (Cao et al., 2021) 等。
BSN(Boundary Sensitive Network,边界敏感网络)(Lin et al., 2018b)是自底向上的时序动作定位算法的一个实例,BSN 获得了 2018 年 ActivityNet 时序动作定位竞赛的冠军和百度综艺节目精彩片段预测竞赛的冠军。
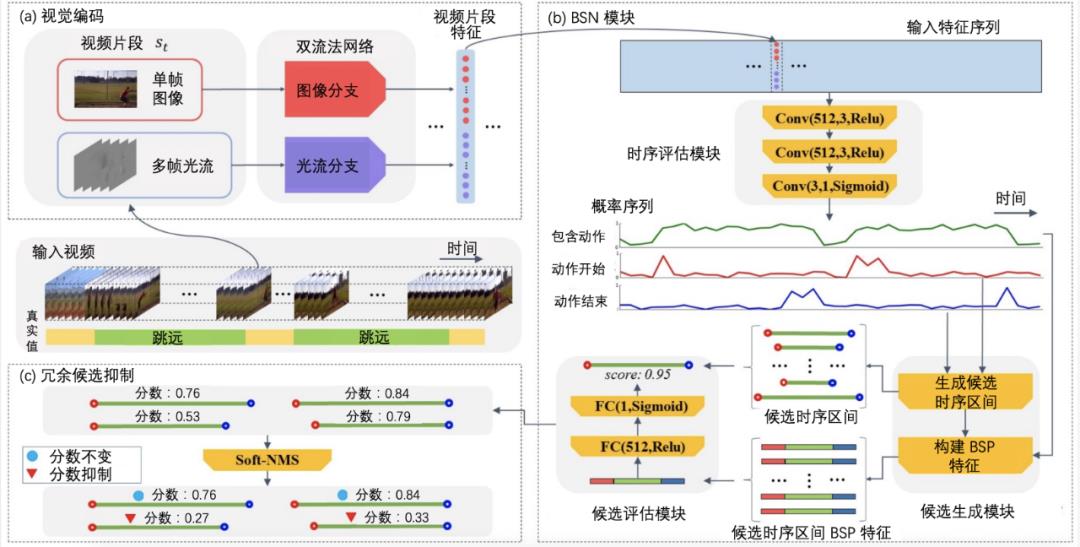
图 8:BSN 网络结构图。本图源于《深度学习视频理解》
3.4 对时序结构信息建模的算法
假设我们的目标是识别视频中的体操单跳 (Tumbling) 动作和对应的动作起止区间,见图 9 中的绿色框。图 9 中的蓝色框表示模型预测的候选时序区间,有的候选时序区间时序上并不完整,即候选时序区间并没有覆盖动作完整的起止过程。图 9 上半部分的算法直接基于候选时序区间内的特征对候选时序区间内的动作类别进行预测,导致模型一旦发现任何和单跳动作有关的视频片段,就会输出很高的置信度,进而导致时序定位不够精准。

图 9:SSN 对动作不同的阶段进行建模。本图源于(Zhao et al., 2020)
SSN(Structured Segment Network,结构化视频段网络)算法 (Zhao et al., 2020) 对动作不同的阶段 (开始、过程、结束) 进行建模,SSN 不仅会预测候选时序区间内的动作类别,还会预测候选时序区间的完整性,这样做的好处是可以更好地定位动作开始和结束的时刻,SSN 只在候选时序区间和动作真实起止区间对齐的时候输出高置信度。
3.5 逐帧预测的算法
我们希望模型对动作时序区间的预测能够尽量精细。CDC (Convolutional-De-Convolutional networks,卷积 - 反卷积网络)算法 (Shou et al., 2017) 和前文介绍的其他算法的不同之处在于,CDC 可以对未被剪辑的视频逐帧预测动作的类别,这种预测粒度十分精细,使得对动作时序区间边界的定位更加精确。
如图 10 所示,输入一个未被剪辑的视频,首先利用动作识别网络提取视频特征,之后利用多层 CDC 层同时对特征进行空间维度的下采样和时间维度的上采样,进而得到视频中每帧的预测结果,最后结合候选时序区间得到动作类别和起止时刻的预测。CDC 的一个优点是预测十分高效,在单 GPU 服务器下,可以达到 500 FPS(Frames per Second,帧每秒)的预测速度。

图 10:CDC 网络结构图。本图源于《深度学习视频理解》
3.6 单阶段算法
目标检测算法可以大致分为两大类,其中一大类算法为两阶段算法,两阶段算法会先从图像中预测可能存在目标的候选区域,之后逐一判断每个候选区域的类别,并对候选区域边界进行修正。时序动作定位中也有一些算法采用了两阶段算法的策略,先从视频中预测可能包含动作的候选时序区间,之后逐一判断每个候选时序区间的类别,并对候选时序区间的边界进行修正,这部分算法已在 3.2 节介绍过。
另一大类算法为单阶段 (One-Stage) 算法,单阶段算法没有单独的候选区域生成的步骤,直接从图像中预测。在目标检测领域中,通常两阶段算法识别精度高,但是预测速度慢,单阶段算法识别精度略低,但是预测速度快。时序动作定位中也有一些算法采用了单阶段算法的策略。
到此为止,我们了解了许多时序动作定位算法,一种直观的想法是预先定义一组不同时长的滑动窗,之后滑动窗在视频上进行滑动,并逐一判断每个滑动窗对应的时序区间内的动作类别,如 S-CNN。TURN 和 CBR 以视频单元作为最小计算单位避免了滑动窗带来的冗余计算,并且可以对时序区间的边界进行修正; 受两阶段目标检测算法的启发,基于候选时序区间的算法先从视频中产生一些可能包含动作的候选时序区间,之后逐一判断每个候选时序区间内的动作类别,并对区间边界进行修正,如 R-C3D 和 TAL-Net; 自底向上的时序动作定位算法先预测动作开始和结束的时刻,之后将开始和结束时刻组合为候选时序区间,如 BSN、TSA-Net 和 BMN;SSN 不仅会预测每个区间的动作类别,还会 预测区间的完整性; CDC 通过卷积和反卷积操作可以逐帧预测动作类别。此外,单阶段目标检测的思路也可以用于时序动作定位中,如 SSAD、SS-TAD 和 GTAN。

图 11:时序动作定位算法。本图源于《深度学习视频理解》
4. 视频 Embedding
Embedding 直译为嵌入,这里译为向量化更贴切。视频 Embedding 的目标是从视频中得到一个低维、稠密、浮点的特征向量表示,这个特征向量是对整个视频内容的总结和概括。其中,低维是指视频 Embedding 特征向量的维度比较低,典型值如 128 维、256 维、512 维、1024 维等; 稠密和稀疏 (Sparse) 相对,稀疏是指特征向量中有很多元素为 0,稠密是指特征向量中很多元素为非 0; 浮点是指特征向量中的元素都是浮点数。
不同视频 Embedding 之间的距离 (如欧式距离或余弦距离) 反映了对应视频之间的相似性。如果两个视频的语义内容接近,则它们的 Embedding 特征之间的距离近,相似度高; 反之,如果两个视频不是同一类视频,那么它们的 Embedding 特征之间的距离远,相似度低。在得到视频 Embedding 之后,可以用于视频推荐系统、视频检索、视频侵权检测等多个任务中。
动作识别和时序动作定位都是预测型任务,即给定一个视频,预测该视频中出现的动作,或者更进一步识别出视频中出现的动作的起止时序区间。而视频 Embedding 是一种表示型任务,输入一个视频,模型给出该视频的向量化表示。视频 Embedding 算法可以大致分为以下 3 大类。
第一类方法基于视频内容有监督地学习视频 Embedding。我们基于视频的类别有监督地训练一个动作识别网络,之后可以从网络的中间层 (通常是全连接层) 提取视频 Embedding。这类方法的重点在于动作识别网络的设计。
第二类方法基于视频内容无监督地学习视频 Embedding。第一类方法需要大量的视频标注,标注过程十分耗时、耗力,这类方法不需要额外的标注,从视频自身的结构信息中学习,例如,视频重建和未来帧预测、视频帧先后顺序验证、利用视频 和音频信息、利用视频和文本信息等。
第三类方法通过用户行为学习视频 Embedding。如果我们知道每个用户的视频观看序列,由于用户有特定类型的视频观看喜好,用户在短时间内一起观看的视频通常有很高的相似性,利用用户观看序列信息,我们可以学习得到视频 Embedding。
其中,第一类和第二类方法基于视频内容学习视频 Embedding,它们的优点是没有视频冷启动问题,即一旦有新视频产生,就可以计算该视频的 Embedding 用于后续的任务中。例如,这可以对视频推荐系统中新发布的视频给予展示机会; 基于内容的视频 Embedding 的另一个优点是对所有的视频“一视同仁”,不会推荐过于热门的视频。另外,也可以为具有小众兴趣爱好的用户进行推荐。
一旦新视频获得了展示机会,积累了一定量的用户反馈 (即用户观看的行为数据) 之后,我们就可以用第三类方法基于用户行为数据学习视频 Embedding, 有时视频之间的关系比较复杂,有些视频虽然不属于同一个类别,但是它们之间存在很高的相似度,用户常常喜欢一起观看。基于用户行为数据学习的视频 Embedding 可以学习到这种不同类别视频之间的潜在联系。
第三大类方法通过用户行为学习视频 Embedding,其中 Item2Vec 将自然语言处理中经典的 Word2Vec 算法用到了用户行为数据中,并在后续工作中得到了优化,DeepWalk 和 Node2Vec 基于图的随机游走学习视频 Embedding,是介于图算法和 Item2Vec 算法之间的过渡,LINE 和 SDNE 可以学习图中结点的一阶和二阶相似度,GCN GraphSAGE 和 GAT 等将卷积操作引入到了图中,YouTube 召回模型利用多种信息学习视频 Embedding。
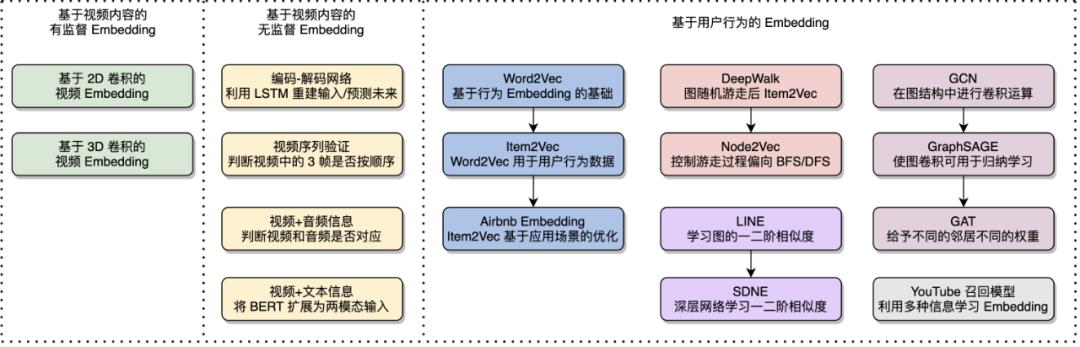
图 12:视频 Embedding 算法。本图源于《深度学习视频理解》
更多精彩内容可参考我开源的《Computer Vision in Action》第16章节,
https://charmve.github.io/computer-vision-in-action/#/3_进阶篇/chapter14-视频理解/chapter14-视频理解

扫码直达
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于音视频基础知识-时间戳的理解的主要内容,如果未能解决你的问题,请参考以下文章