结构方程模型(SEM)在生态学领域中的实践
Posted xiao5kou4chang6kai4
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结构方程模型(SEM)在生态学领域中的实践相关的知识,希望对你有一定的参考价值。
结构方程模型(Sructural Equation Model)是一种建立、估计和检验研究系统中多变量间因果关系的模型方法,它可以替代多元回归、因子分析、协方差分析等方法,利用图形化模型方式清晰展示研究系统中变量间的因果网络关系,是近年来地学、生态、进化、环境、医学、社会、经济领域中应用十分广泛的统计方法。然而,自Wright在1920年美国科学院院刊(PNAS)提出第一个通径/路径(Path Analysis)分析(即结构方程模型中的结构模型)方法发展至今的100多年时间里,结构方程模型已发展出有较为庞大的理论体系和复杂多变的形式,使初学者往往无所适从。
本次将利用开源软件R平台,以生态学研究领域问题为主线,筛选出大量经典案例,通过理论讲解和实际操作相结合的方式,由浅入深地系统介绍结构方程模型的建立、拟合、评估、筛选和结果展示的全过程,使学员能够利用结构方程模型方法解决实际研究和工作中遇到的相关科学问题
R入门及Rstudio与结构方程模型(SEM)生态领域应用
1) R及Rstudio介绍:背景、软件及程序包安装、基本设置等
2) R语言基本操作,包括向量、矩阵、数据框及数据列表等生成和数据提取等
3) R语言数据文件读取、整理(清洗)、结果存储等(含tidverse)
4) R语言基础绘图(含ggplot):基本绘图、排版、发表质量绘图输出存储



1) SEM的定义、生态学领域应用及历史回顾
2) SEM的基本结构
3) SEM的估计方法
4) SEM的路径规则
5) SEM路径参数的含义
6) SEM分析样本量及模型可识别规则
7) SEM构建基本流程

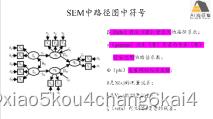

R语言SEM分析入门:lavaan VS piecewiseSEM
1) 结构方程模型在生态学研究中的应用介绍及模型要点回顾
2) 结构方模型估计方法:局域估计和全局估计的基本工作原理、主要区别及应用情景分析
3) 案例群落物种丰富度恢复的直接及间接效应(direct and indirect effects):SEM分析基本流程-lavaan vs piecwiseSEM
(1)模型建立
(2)模型拟合
(3)模型评估
(4)结果展示

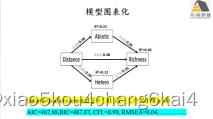
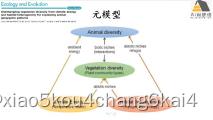
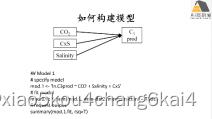
练习:1.根据元模型(meta-model)构建模型
练习:火烧干扰后植物群落恢复直接、间接及调节效应分析

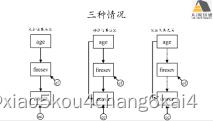

基于lavaan的SEM在生态学领域高阶应用
案例1:湿地生态系统初级生产力的直接和间接效应分析
(1)问题提出、元模型构建
(2)模型构建及模型估计
(3)模型评估:路径增加和删减原则、最优模型筛选方法
(4)结果表达
案例2:火烧干扰后植物群落恢复效果评估-数据缺失和正态性不足数据处理-
案例3:放牧对海拔与生物量关系的影响分析-数据分组分析
案例4:农业用地比例对河口水草多度影响-数据分层/嵌套分析

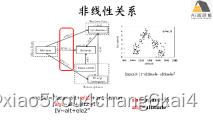
练习:环境异质性和资源可获得性对不同演替阶段林下维管植物多样性的影响

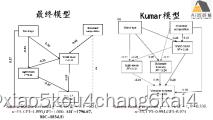
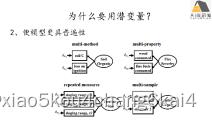
基于lavaan的SEM潜变量分析在生态学领域应用
(1) 潜变量的定义、优势及应用背景分析
(2) 潜变量分析lavaan实现基本原理
(3) 案例1:海岸带米草群落生态恢复表现预测-单潜变量模型构建
(4) 案例2:城市景观中土地利用对有花植物资源和访华昆虫的直接与间接影响-多个潜变量模型构建
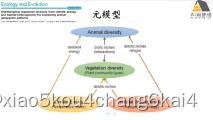
练习案例:植物多样性、能量梯度及环境梯度对动物多样性格局的影响-构建动物多样性潜变量

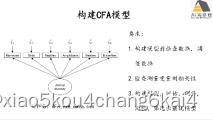
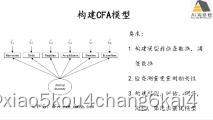
基于lavaan的SEM复合变量分析在生态学领域应用
(1) 复合变量的定义及在生态学领域应用情景分析
(2) 复合变量分析lavaan实现途径
(3) 案例1:生态力与生物多样性形成机制分析-土壤理化因子的多复合变量构建
(4) 案例2:火烧后植被恢复对物种丰富度影响-复合变量解决非线性问题
(5) 案例3:气候暖化、海平面上升对湿地植物群落的复合影响-复合变量解决交互作用问题
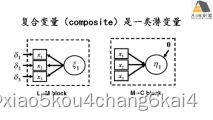

实例 :植物群落物种多样性是否会提高其对入侵植物的抵抗力(Oikos, 2017)-多复合变量实现



局域估计SEM -piecewiseSEM及生态学领域高阶应用
(1) piecewiseSEM对内生变量为二项及泊松分布数据的分析
(2) 案例1:气候波动对海草床生态系统食物网结构影响-数据分层和嵌套、时间和空间自相关对结果影响
(3) 案例2:物种属性、社会性进化特征对海虾领域范围和多度影响-系统发育相关修正
(4) 案例3-5:分组数据、交互作用、非线性关系等piecewiseSEM实现(实例数据同专题3)
练习案例:人类活动、环境条件、物种属性对动物领域大小相对贡献-分组分析和分类变量处理



贝叶斯SEM在生态学领域应用
(1) 贝叶斯(bayes)方法简介
(2) R语言贝叶斯SEM实现程序包blavaan和brms介绍
(3) 案例1:气候及生态位重叠程度对田鼠物种丰富度影响:模型比较、直接和间接效应计算(blavaan)
(4) 案例2:火烧后对植被恢复影响因素-模型拟合、模型比较和评估(brms)



案例:生物地理历史因素对北半球森林的初级生产力的影响(brms)


R语言Meta分析【全流程、不确定性分析】方法与Meta机器学习
基于R语言BIOMOD2模型的物种分布模拟
Meta分析在生态环境领域中的实践技术
MATLAB在生态环境数据处理与分析中的应用
Biome-BGC生态系统模型建模方法与实践技术
基于GIS探究环境和生态因子对水体、土壤、大气污染物的影响
InVEST实践与进阶及在生态系统服务供需、固碳、城市热岛、论文写作
基于MAXENT模型的生物多样性生境模拟与保护优先区甄选、自然保护区布局优化评估
《结构方程模型的原理与应用》的读书笔记
《结构方程模型的原理与应用》是学习结构方程的必读的著作。全书总共11章。
第一章:结构方程模型概说。
上个世纪,影响社会科学研究最大的统计方法是因素分析和回归分析。潜在结构因素分析模型和路径模型的结合,形成了结构方程模型。结构方程模型是用来处理复杂的多变量研究数据的探究和分析的方法,已经成为现在社会与行为科学中最重要的一个统计方法范式。
SEM的特性1能对抽象的构念进行估计和检定。对于变量因果关系的证明或构念内在结构的确认,均有赖于研究变量的性质与内容的厘清,并清除描述变量的假设性关系,由此提出具体的结构性关系的假设命题,寻求统计上的检证来确认,结构方程模型。
SEM的特性2是模组化分析的应用。模组化应用的策略:1单纯的验证,2模型的产生,3替代模型的竞争比较。此举提供了一套严谨的程序。
SEM的特性3必须建立在一定理论的基础上。SEM以协方差的运用为核心,适用大样本的分析。
SEM对于统计显著性的依赖程度低于一般统计。
结构方程模型的执行的过程具体来说有:理论发展、模型界定、模型识别、抽样与统计、参数与估计(模型拟合评鉴、模型修饰)、讨论与结论。
SEM的执行重点:
a. 模型的描述与设定。重视概念路径图的运用。
b. 资料的准备,SEM分析最好的是协方差数据。原始数据而非矩阵数据有助于多阶段SEM分析的进行,对数据进行运算时,必须说明数据的正态性及峰度等。
c. 报表的整理与分析。这包括两个部分,过程性资料和最终解。在估计方法的选择上,最常用的是最大概似法。在磨合你和指数的选择上,一个是绝对拟合,一个是增量你和,绝对拟合使用GFI,增量拟合使用NNFI。参数的报告上,要说明参数的合理性、显著性检验、标准化解。
d. 替代模型的使用,替代模型分为演绎取向和归纳取向。
第二章:结构方程模型的组成。
结构方程模型由变量和参数构成。
变量分为连续变量和分类变量,结构模型的基本单位是连续变量。
连续变量有两种形态,测量变量与潜在变量,在SEM中,测量变量为长方形,潜在变量为椭圆形,潜在变量必须有两个以上的测量变量估计得到,潜在变量具有测量误差,即无法被潜在变量解释的部分。连续变量还可以分为内生和外生,内生即受到其他影响,外生反之。
参数即未知而需要推断的数据。在SEM中,参数与潜变量是讨论的重点。参数还可以分为自由参数、固定参数与限定参数。对于不被估计的参数设置为0,为固定参数。限定参数多用于多样本比较,其数据由估计得到。参数还有直接与非直接关系两种,用→表示。而非直接采用双箭头表示。
模型参数与方程式。完整的SEM模型包含测量模型与结构模型。潜在变量与观察变量的强度采用lambda,即因素载荷,外源与内生潜在变量之间的关系用gamma表示,内生潜在变量之间的关系用beta表示,有gamma与beta调试的即是结构模型。Delta与epslon分别表示外源观察变量与内生观察变量被潜在变量解释不完全的测量残差,而theta则为内生潜在变量无法被完全解释的估计误差。
在SEM中,如果单独使用测量模型,即为验证性因素分析,即是一个传统的路径分析模型。
共变结构关系的分析是SEM最主要的核心概念,涉及复杂的变量关系的探究时,一个重要的基本原则是如何将这些共变关系以最符合理论意义且最简单扼要的方式加以界定,最能够符合实际观测的数据结构。
等值模型即不同的SEM模型具有相同的模型拟合度。
第三章:参数估计与识别问题
结构方程模型最核心的计量程序就是参数估计。
决定模型识别性的具体步骤是计算用以产生共变结构的观测值数目,衡量识别性的必要非充分的识别计算条件是T法则,T值代表模型中的自由估计参数数目。T与三个判断法则,过度识别、充分识别、识别不足。
| 过度识别 | 饱和模型,完美你和,无法评估整体模型的适切性 |
| 充分识别 | 可以利用不同的参数估计方法,对于参数进行优化的估计,找出最佳解 |
| 识别不足 | 无法顺利进行,只有将部分参数设定为定制,才可以进行 |
虚伪B矩阵法则,是反映模型识别性的充分条件,若符合不必计算识别数值。B为回归系数矩阵。
B矩阵呈现三角形状态,呈现对角线状态,为递归模型,饱和法则。
对于无法识别的情况,尽量简化SEM模型,如果持续存在,将潜在变量的残差设定为1,或是将信度理想的测量模式的参数设定为1,或去除不良的变量,或许能够获得识别。
测量模型决定的是整体模型中的外显变量与潜在变量之间的关系。对于个别测量模型的识别中,设计到潜在变量的量尺的问题,有的以潜在变量的方差设定为1,有的制定一个变量的因素载荷为1。
结构模型的识别度,结构模型的识别性与测量模型识别性是两个独立的判断过程,它主要牵涉结构模型的结构参数的设定,无关乎测量模型的参数设定。结构模型的识别性决定于内生变量之间的关系的假设。非递归模型的谁别设计到过多参数,无法识别,必须使用别的策略使模型能够识别。
潜在变量尺度的设定上,外源潜在变量设定为方差为一个常数,通常为1,对于潜在内生变量是将其中一个测量变量与潜在变量的因素载荷设定为常数,为1。内生变量的尺度策略有三种,内生潜在变量的方差为1,进行设限的参数估计程序,其次是内生潜在变量的方差设定为1,仅用于递归模型的设定,再次是取内生潜在变量的因素载荷为固定参数,进行参数估计后,将潜在变量尺度固定再进行潜在变量尺度的方差估计。
参数估计,相关系数。协方差与相关系数之间相差一个标准化关联系数。
SEM共变推到有四大定理,某一个变量与自己的共变即等于该变量的方差。
经过线性整合后的变量的协方差为![]() 定理3、定理4省略。
定理3、定理4省略。
观察变量的方差等于各观察变量的因素载荷的平方加上误差项的方差。
参数估计的策略,加权最小平方策略,无加权最小平方法,一般化最小平方法,最大概似法(最常用的参数估计法,变量正态性),渐进分布自由法(无须正态,处理的丰台,必须使用原始数据,样本高达2500),最大概似法需要500样本,低于500,一般化最小平均法,小样本(6--120)使用Yuan-Bentler‘s T,违反正态至少需要2500的样本。
对于计算中出现的不正常终止即正定问题,原因有,矩阵中对角在线的数据(方差或自身相关系数)不为正值、对角在线的数据是其他元素的基本条件(违反三角不均等条件)、举证不符合非奇异的要件(导致分母项为零)等。
第四章:模型拟合评鉴
在完成了参数估计之后,结构方程模型分析的另一个重要工作是进行模型的评估与检验,以决定研究者所提出的假设模型是否能够用以描述实际观测到的变量关系,此过程称为模型拟合评鉴。拟合评鉴的方法是用不显著的卡方值来反映理想的模型拟合值。
在SEM分析中,必须小心谨慎处理测量的信效度的问题,即研究者在进入模型评鉴阶段时需要解决测量的问题。SEM的使用者不但必须谨记统计方法学本身的限制,也必须避免过度推论的陷阱。
在SEM中卡方值是由拟合函数所转换而来的统计量,反映了SEM假设模型的导出举证与观测矩阵的差异。在卡方检验的概念下,自由度越大的模型在卡方统计上处于不利的地位。
卡方自由度比,用来进行模型间拟合度的比较。卡方自由度比越小,模型拟合度越高,一般而言,卡方自由度比小于2时,表示模型具有理想的拟合度。英文单词是Normal TheoryWeighted Least Squares Chi-Square/df
模拟拟合指数,GFI、AGFI,GFI为拟合指数,通常可以认为是可解释的变量,AGFI为调整后的拟合指数,两者0到1间,越接近1越好。PGFI指数,是GFI的一个变形,体现参数的多寡,反映的SEM假设模型的简效程度,越接近1,模型越简单,良好的模型一般都在0.5以上。NFI与NNFI指数,一个为正规拟合指数,一个为非正规拟合指数,这两个指数是利用嵌套模型的比较原理计算出来的一种相对性指数,反映了假设模型与一个观察变量之间没有任何共变假设的独立模型的差异程度。独立模型是一种拟合状况最不理想的模型,反映了所有的观察变量之间没有任何关联,自由度最大。IFI是一个增量拟合指数,用来处理NNFI波动的问题以及样本大小对于NFI指数的影响。IFI、NFI、NNFI都会介于0-1间,数值越大拟合度越好,系数值大于0.9认为拟合理想。
替代指数与模拟拟合指数的主要不同在于替代指数不是以卡方统计量的假设检验进行模型拟合度的评估。替代性指数不在关心虚无假设是否成立,而是去直接估计假设模型与由抽样理论到处的卡方值的差异程度。非集中性参数NCP表示的是计算SEM模型估计得到的卡方统计量,距离理论预期的中央卡方分布的离散成都。模型越不理想,距离中心点的卡方分布越远,越接近0的NCP表示越好。RMSEA为平均概似平方误根系数,RMSEA不受到样本数大小和模型复杂度的影响,当模型趋近完美拟合时,指数接近0,一般认为低于0.06才是一个好模型,小样本时慎用。CFI指数,反映了假设模型与无任何共变关系的独立模型差异成都的量数,也考虑到被检验模型与中央卡方分布的离散性。越接近1,拟合度越好,0.95为通用的门槛,在小样本中表示稳定。ECVI和AIC指数,这是一个期望交叉效度指数,反映了再相同的总体下,不同样本所重复获得同一个假设模型的拟合度的期望值,是用来诊断模型的复核效化的良好指数,其值越小,模型拟合度越好。ECVI、AIC、CAIC指数越小,模型越简效。CN指数,特别的拟合统计量,关键样本指数,说明样本规模的适切性,即若要产生一个适当的模型拟合度,所需要的样本统计量为多少,一般认为200是一个门槛。
残差分析指数,SEM分析提供两种残差数据,非标准化残差和标准化残差,非标准化残差就是假设模型与观测数据之间差距的原始量数,可以用来了解其具体意义,但是不利于相互比较。残差反映了不良拟合的成都,SEM提供残差均方根指数RMR和标准化残差均方根指数SRMR来反映理论假设模型的整体残差。其中RMR越小,模型拟合度越小,SRMR低于0.08,表示模型拟合度佳。
以上是关于结构方程模型(SEM)在生态学领域中的实践的主要内容,如果未能解决你的问题,请参考以下文章