JAVAWeb01-BS架构简述HTML
Posted 程序员 DELTA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVAWeb01-BS架构简述HTML相关的知识,希望对你有一定的参考价值。
1. B/S 软件开发架构简述
1.1 Java Web 技术体系图

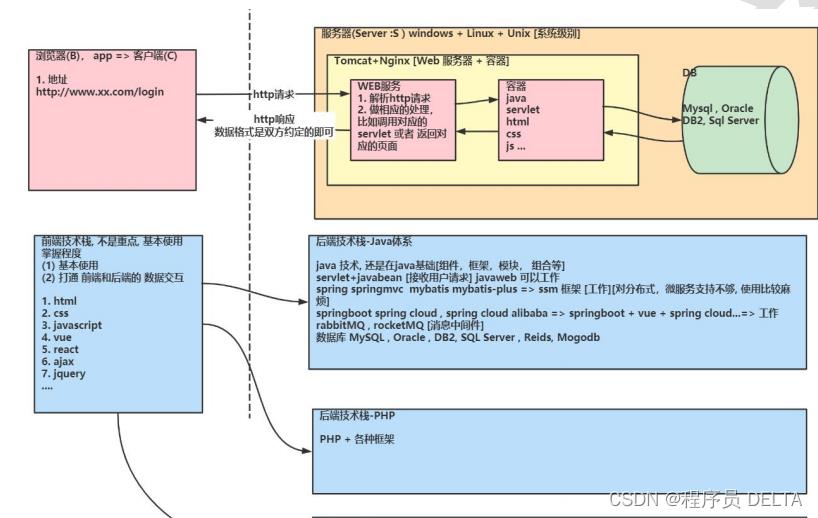


1.2 B/S 软件开发架构简述
- B/S架构
- B/S框架,意思是前端(Browser 浏览器)和服务器端(Server)组成的系统的框架结构。
- B/S架构也可理解为web架构,包含前端、后端、数据库三大组成部分。
- 示意图 , 看前面的图即可
-
前端
前端开发技术工具包括三要素:html、CSS 和 javascript,还有很多高级的前端框架,如bootstrap、jquery,VUE 等。三要素是核心,新瓶装旧酒,所有的前端技术都是围绕三要素进行扩展 -
后端
后端开发技术工具主要有:Net、JAVA、php, Go 等 -
数据库
主流的三种关系型数据库:mysql、SQLserver、Oracle ,还有 Nosql 非关系型数据库:Redis、Mogodb 等。
2. HTML
2.1 官方文档
地址: https://www.w3school.com.cn/html/index.asp
2.2 网页
2.2.1 网页的组成

2.2.2 案例演示:https://www.jd.com/

说明
谷歌浏览器 进入到 调试页面 ctrl + shift + i 或 f12
2.3 HTML 介绍
2.3.1 HTML 是什么
- HTML(HyperText Mark-up Language)即超文本标签语言(可以展示的内容类型很多)
- HTML 文本是由 HTML 标签组成的文本,可以包括文字、图形、动画、声音、表格、链接等
- HTML 的结构包括头部(Head)、主体(Body)两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。
2.3.2 HTML 运行方式
2.3.2.1 本地运行
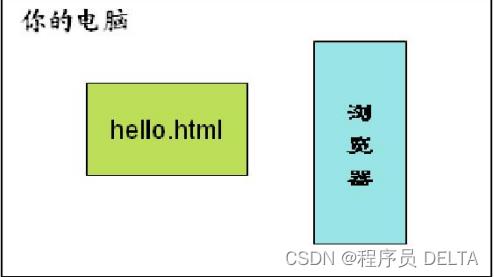
直接打开电脑上html后缀的文件,较少使用,一般用于快速预览
2.3.2.2 远程访问

通过请求,服务器响应文件的方式
2.4 HTML 快速入门
2.4.1 使用 idea 编写 hello.html,运行效果

<!--文档类型说明 注释 -->
<!DOCTYPE html>
<!--使用语言的地区 en 表示英国美国 en-US-->
<html lang="en">
<!--html 头-->
<head>
<!--charset 文件的字符集-->
<meta charset="UTF-8">
<!--文件标题-->
<title>入门案例</title>
</head>
<!--body 体,主体部分-->
<body>
<!--内容-->
hello,开始学习HTML啦
</body>
</html>
2.4.2 注意事项和细节
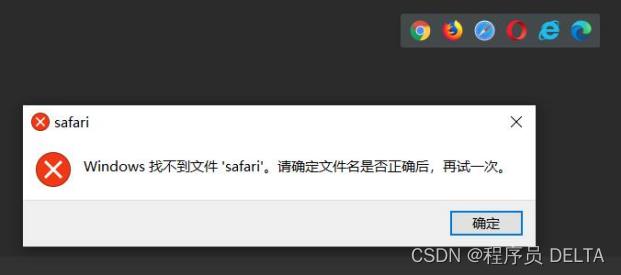
- HTML 文件不需要编译,直接由浏览器进行解析执行
- 可以选择的浏览器,是你电脑安装有的浏览器, 如果没有安装这个浏览器,会报错
2.5 HTML 基本结构

2.6 HTML 标签
2.6.1 html 的标签/元素 文档
在线文档学习:https://www.w3school.com.cn
2.6.2 html 的标签/元素-说明
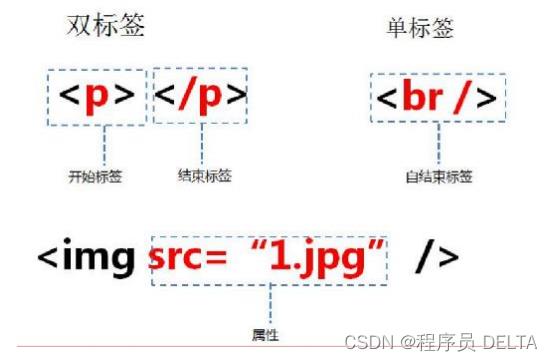
- HTML 标签用两个尖括号”<>”括起来
- HTML 标签一般是双标签,如
<b>和</b>, 前一个标签是起始标签, 后一个标签为结束标签 - 两个标签之间的文本是 html 元素的内容
- 某些标签称为"单标签",因为它只需单独使用就能完整地表达意思,如
<br/> <hr/> - HTML 元素指的是从开始标签到结束标签的所有代码。
2.6.3 html 标签注意事项和细节
- 创建 html文件,说明标签使用的细节, (html命名规范 xx.yy.html , xx-yy.html xx_yy.html 根据公司规范要求即可)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签使用细节</title>
</head>
<body>
<!--
标签使用细节:
1.标签不能交叉嵌套
2.标签必须正确关闭
3.注释不能嵌套
4. html 语法不严谨。有时候标签不闭合,属性值不带””也不报错
-->
<!--标签不能交叉嵌套-->
<!--<div><span>tom</div></span> 错误用法-->
<div><span>tom</span></div>
<!--标签必须正确关闭-->
<span>jack</span>
<!--注释不能嵌套 -->
<!--html 语法不严谨。有时候标签不闭合,属性值不带””也不报错-->
<font color="red">张飞</font>
<font color=blue>关羽</font>
<br/>
</body>
</html>
- 细节说明
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签使用细节</title>
</head>
<body>
<!-- 标签使用细节:
1.标签不能交叉嵌套
2.标签必须正确关闭
3.注释不能嵌套
-->
正确: <div><span>hello</span></div>
<!-- 错误: <div><span>hello</div></span>-->
正确: <div>hello</div>
<!-- 错误: <div>hello-->
正确:<!-- 这是一个注释内容 -->
错误: <!-- 这是一个注释内容 <!-- 这是一个注释内容 --> -->
<!-- 4. html 语法不严谨。有时候标签不闭合,属性值不带””也不报错
-->
严谨: <font color="blue">hello, HTML</font>
不严谨: <font color=blue>hello, HTML</font>
<br />
<br>
hello,world~
</body>
</html>
2.6.4 font 字体标签
应用实例
创建 font.html :在网页上显示 北京 ,并修改字体为 微软雅黑,颜色为蓝色
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>font标签</title>
</head>
<body>
<!-- 字体标签
应用实例 1:在网页上显示 北京 ,并修改字体为 微软雅黑,颜色为蓝色。
font 标签是字体标签,它可以用来修改文本的字体,颜色,大小(尺寸)
(1)color 属性修改颜色
(2)face 属性修改字体
(3)size 属性修改文本大小
多说一句,对应标签的属性,顺序不做要求
-->
<font size="40px" face="微软雅黑" color="blue">北京</font>
</body>
</html>
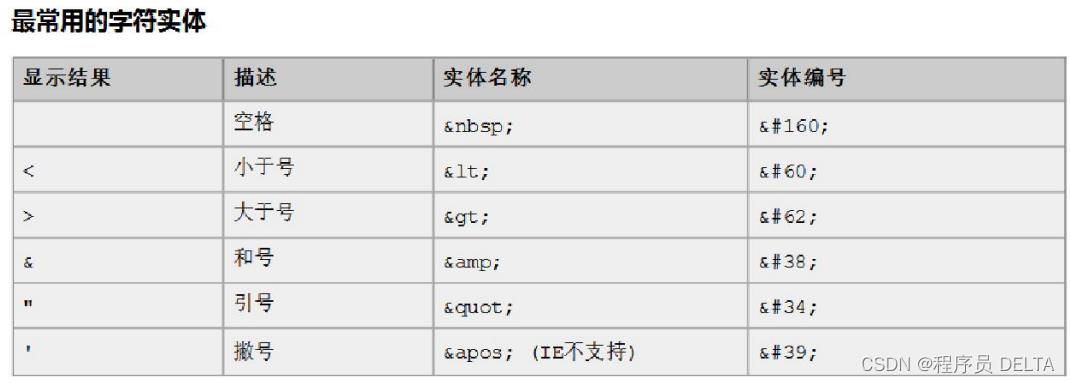
2.6.5 字符实体
- 在网页上显示一些特殊的符号,称为字符实体(也叫符号实体)。
- 应用实例 创建 html文件呢:将
<hr />标签以文本方式显示在页面

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>字符实体</title>
</head>
<body>
<!-- 特殊字符 应用实例:
把 <hr /> 变成文本 显示在页面上
常用的特殊字符:
< : <
> : >
空格 : 或者 
-->
jack
<!--浏览器会将 <hr/>解析成一条线-->
<hr/>
<!--拓展:也可以使用实体编号,例如<也表示小于号-->
<hr />标签 : 表示线条 <br/>
<hr/>
hello~  HTML!<br/>
</body>
</html>
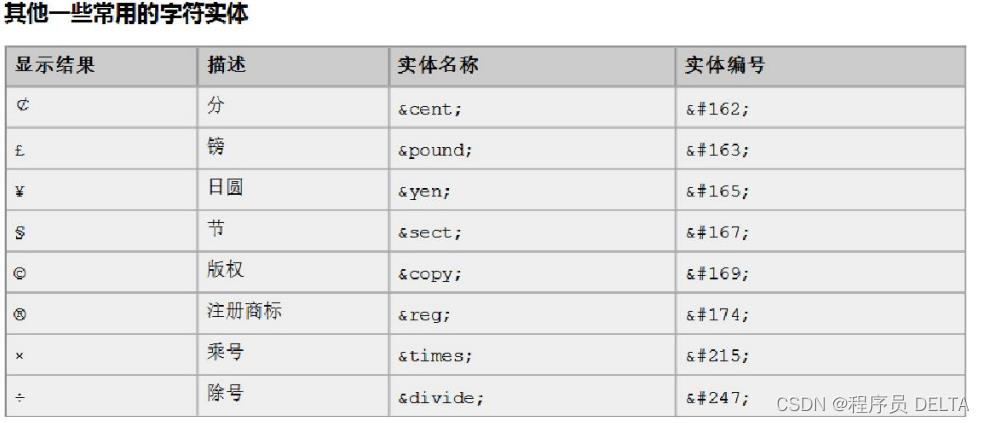
2.6.6 字符实体一览表
2.6.7 标题标签
- 标题使用
<h1> - <h6>标签进行定义。<h1>定义最大的标题。<h6>定义最小的标题
应用实例 创建 title.html

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题标签</title>
</head>
<body>
<!-- 标题标签
应用实例:演示标题 1 到 标题 6 的
h1 - h6 都是标题标签 h1 : 最大 h6 : 最小
align: 属性是对齐属性
left: 左对齐(默认)
center :居中
right : 右对齐
-->
<h1>标签1</h1>
<h2 align="center">标签2</h2>
<h3 align="right">标签3</h3>
<h4>标签4</h4>
<h5>标签5</h5>
<h6>标签6</h6>
</body>
</html>
2.6.8 超链接标签
- 超链接是指从一个网页指向一个目标的链接关系,这个目标可以是另一个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮件地址,一个文件,甚至是一个应用程序。
应用实例:
创建 link.html,链接到 搜狐网站

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>超链接标签</title>
</head>
<body>
<!--
老韩说明:
a 标签是 超链接
href 属性设置连接的地址
target 属性设置哪个目标进行跳转
_self : 表示当前页面(默认值), 即使用当前替换目标页
_blank : 表示打开新页面来进行跳转
点击超链接,打开邮件
mailto:效果是可能会打开电脑上的邮箱软件
-->
<a href="http://www.sohu.com">搜狐</a><br/>
<a href="http://www.sohu.com" target="_blank">搜狐2</a><br/>
<a href="mailto:tom@sohu.com">联系管理员</a>
</body>
</html>
2.6.9 无序列表 ul/li
ul全称:unorder list
li全称: list item
1)ul/li 基本语法

2)应用实例 创建: ul_li.html

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>ul li标签</title>
</head>
<body>
<!--
ul : 表示无序列表
li : 列表项
type属性:指定列表项前的符号
-->
<h1>五虎将</h1>
<ul type="circle">
<li>jack</li>
<li>tom</li>
<li>smith</li>
<li>mary</li>
<li>milan</li>
</ul>
</body>
</html>
2.6.10 有序列表 ol/li
1)ol/li 基本语法
ol:全称为order list

2)应用实例 创建: ol-li.html

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>有序列表ol-li</title>
</head>
<body>
<!--
ol : 表示有序列表
li : 列表项
type属性:指定列表项前排序方式
type 设定数目款式,其值有五种,默认为 start="1"。
i可以取以下值中的任意一个:
1 阿拉伯数字 1, 2, 3, ...
a 小写字母 a, b, c, ...
A 大写字母 A, B, C, ...
i 小写罗马数字 i, ii, iii, ...
I 大写罗马数字 I, II, III, ... 。
-->
<h1>五虎将</h1>
<!-- start 的值只能是整数 代表从第几个开始-->
<ol type="I" start="3">
<li>关羽</li>
<li>张飞</li>
<li>赵云</li>
<li>马超</li>
<li>黄忠</li>
</ol>
</body>
</html>
2.6.11 图像标签(img)
1)img 标签可以在 html 页面上显示图片
2)应用实例:
创建 img.html:如图

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>图像标签</title>
</head>
<body>
<!--
应用实例:使用 img 标签显示一张美女的照片。
img: 标签是图片标签,用来显示图片
src: 属性可以设置图片的路径
width: 属性设置图片的宽度
height: 属性设置图片的高度
border: 属性设置图片边框大小
alt: 属性设置当指定路径找不到图片时,用来代替显示的文本内容
相对路径:从工程名开始算
绝对路径:盘符:/目录/文件名
路径:在 web 中路径分为相对路径和绝对路径两种
相对路径: . 表示当前文件所在的目录
.. 表示当前文件所在的上一级目录
文件名 : 表示当前文件所在目录的文件,相当于 ./文件名 ./ 可以省略
绝对路径: 正确格式是: http://IP地址:port/工程名/资源路径 , 即使用url方式定位资源
错误格式是: 盘符:/目录/文件名
-->
<h1>图片标签的演示</h1>
<!-- ./imgs/1.png 表示当前路径下的 imgs文件夹下的 1.png-->
<!-- 在进行图片缩放时,建议指定 width 或者 height 即可,浏览器会按照比例显示-->
<img src="./imgs/1.png" height="150" width="400" > <br/>
<img src="./imgs/1.png" height="150" border="10px"><br/>
<img src="./imgs/2.png" alt="美女找不到"><br/>
</body>
</html>
3)应用实例:将图片做成超链接
2.6.12 表格(table)标签
1)基本语法

2)应用实例
修改: table.html: 显示 3 行 3 列的表格

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>表格标签</title>
</head>
<body>
<!-- 说明:
table: 标签是表格标签 border: 设置表格标签
width: 设置表格宽度 height: 设置表格高度
align: 设置表格相对于页面的对齐方式
cellspacing: 设置单元格间距
tr :是行标签 th :是表头标签 td :是单元格标签
align: 设置单元格文本对齐方式 b :是加粗标签
px:表示像素 - java 坦克大战
ctrl +shift + 下光标
-->
<table width="500" border="6" align="center">
<h1 align="center">表格标签的使用</h1>
<tr>
<th>名字</th>
<th>住址</th>
<th>邮件</th>
</tr>
<tr>
<td>第1行第1列</td>
<td>第1行第2列</td>
<td>第1行第3列</td>
</tr>
<tr>
<td>第2行第1列</td>
<td>第2行第2列</td>
<td>第2行第3列</td>
</tr>
<tr>
<td>第3行第1列</td>
<td>第3行第2列</td>
<td>第3行第3列</td>
</tr>
</table>
</body>
</html>
2.6.13 表格标签-跨行跨列表格
1)编写如下网页: 修改: table2.html

<!DOCTYPE html>
<html lang="Spark简述及基本架构
Spark简述
Spark发源于美国加州大学伯克利分校AMPLab的集群计算平台。它立足
于内存计算。从多迭代批量处理出发,兼收并蓄数据仓库、流处理和图计算等多种计算范式。
特点:
1、轻
Spark 0.6核心代码有2万行,Hadoop1.0为9万行,2.0为22万行。
2、快
Spark对小数据集能达到亚秒级的廷迟,这对于Hadoop MapReduce是无法想象的(因为”心跳”间隔机制,仅任务启动就有数秒的延迟)
3、灵
在实现层,它完美演绎了Scala trait动态混入策略(如可更换的集群调度器、序列化库);
在原语层,它同意扩展新的数据算子、新的数据源、新的language bindings(Java和Python)。
在范式层,Spark支持内存计算、多迭代批星处理、流处理和图计算等多种范式。
4、巧
巧在借势和借力。
Spark借Hadoop之势,与Hadoop无缝结合。
为什么Spark性能比Hadoop快?
1、Hadoop数据抽取运算模型
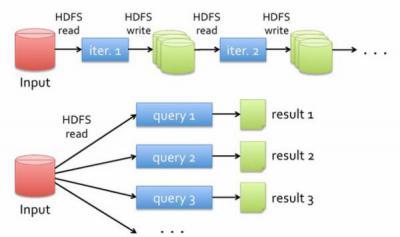
数据的抽取运算基于磁盘,中间结果也是存储在磁盘上。MR运算伴随着大量的磁盘IO。
2、Spark则使用内存取代了传统HDFS存储中间结果
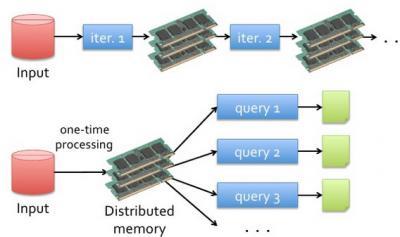
第一代的Hadoop全然使用hdfs存储中间结果,第二带的Hadoop增加了cache来保存中间结果。而Spark则是基于内存的中间数据集存储。能够将Spark理解为Hadoop的升级版本号,Spark兼容了Hadoop的API,而且能够读取Hadoop的数据文件格式,包含HDFS,Hbase等。
Spark on Standalone执行过程(client模式)
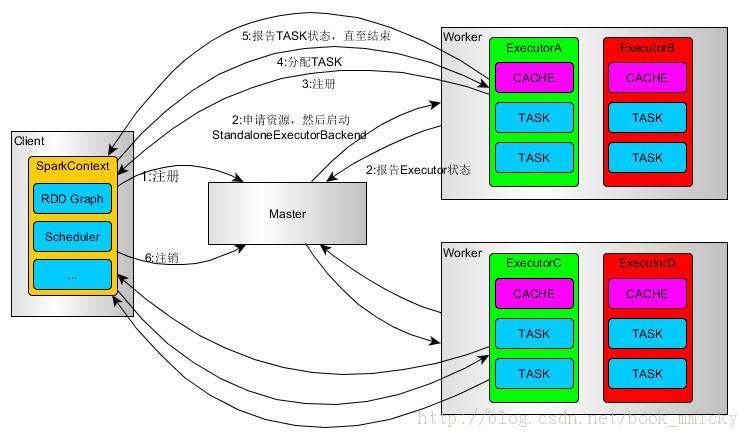
1、SparkContext连接到Master,向Master注冊并申请资源(CPU Core 和Memory)
2、Master依据SparkContext的资源申请要求和worker心跳周期内报告的信息决定在哪个worker上分配资源。然后在该worker上获取资源,然后启动StandaloneExecutorBackend。
3、StandaloneExecutorBackend向SparkContext注冊。
4、SparkContext将Applicaiton代码发StandaloneExecutorBackend;而且SparkContext解析Applicaiton代码,构建DAG图。并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job。每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。然后以Stage(或者称为TaskSet)提交给Task Scheduler,
Task Scheduler负责将Task分配到对应的worker,最后提交给StandaloneExecutorBackend执行;
5、StandaloneExecutorBackend会建立executor 线程池。開始执行Task,并向SparkContext报告。直至Task完毕。
6、全部Task完毕后。SparkContext向Master注销。释放资源。
Spark on YARN 执行过程(cluster模式)
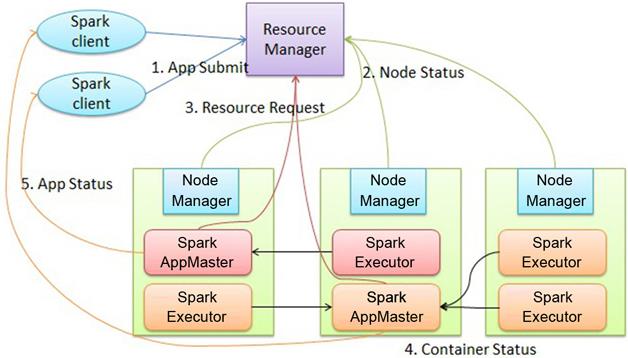
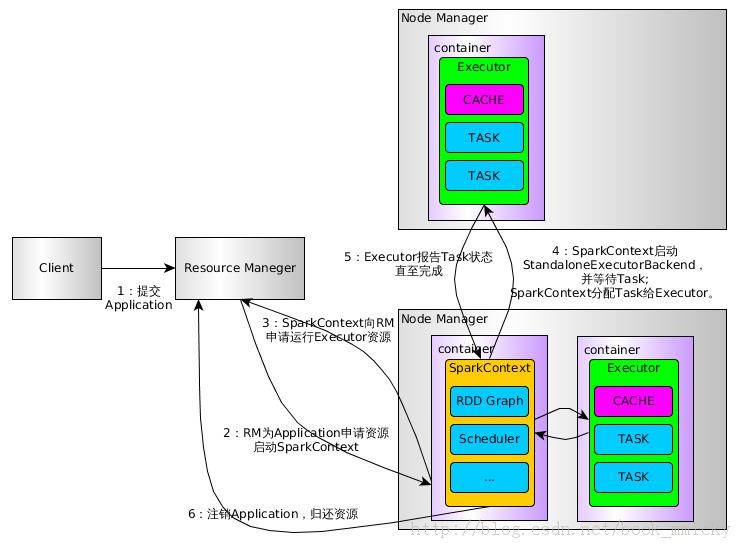
1、用户通过bin/spark-submit( Spark1.0.0 应用程序部署工具spark-submit)或 bin/spark-class 向YARN提交Application。
2、RM为Application分配第一个container,并在指定节点的container上启动SparkContext。
3、SparkContext向RM申请资源以执行Executor。
4、RM分配Container给SparkContext,SparkContext和相关的NM通讯,在获得的Container上启动StandaloneExecutorBackend,StandaloneExecutorBackend启动后,開始向SparkContext注冊并申请Task。
5、SparkContext分配Task给StandaloneExecutorBackend执行StandaloneExecutorBackend**执行Task**并向SparkContext汇报执行状况
6、Task执行完毕。SparkContext归还资源给RM,并注销退出。
RDD简单介绍
RDD(Resilient Distributed Datasets)弹性分布式数据集,有例如以下几个特点:
1、它在集群节点上是不可变的、已分区的集合对象。
2、通过并行转换的方式来创建。如map, filter, join等。
3、失败自己主动重建。
4、能够控制存储级别(内存、磁盘等)来进行重用。
5、必须是可序列化的。
6、是静态类型的。
RDD本质上是一个计算单元。能够知道它的父计算单元。
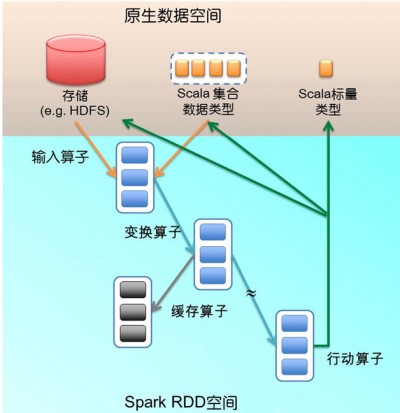

RDD 是Spark进行并行运算的基本单位。
RDD提供了四种算子:
1、输入算子:将原生数据转换成RDD,如parallelize、txtFile等
2、转换算子:最基本的算子,是Spark生成DAG图的对象。
转换算子并不马上执行,在触发行动算子后再提交给driver处理,生成DAG图 –> Stage –> Task –> Worker执行。
按转化算子在DAG图中作用。能够分成两种:
窄依赖算子
输入输出一对一的算子,且结果RDD的分区结构不变,主要是map、flatMap;
输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union、coalesce;
从输入中选择部分元素的算子。如filter、distinct、subtract、sample。
宽依赖算子
宽依赖会涉及shuffle类,在DAG图解析时以此为边界产生Stage。
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组。如join、cogroup。
3、缓存算子:对于要多次使用的RDD,能够缓冲加快执行速度,对关键数据能够採用多备份缓存。
4、行动算子:将运算结果RDD转换成原生数据,如count、reduce、collect、saveAsTextFile等。
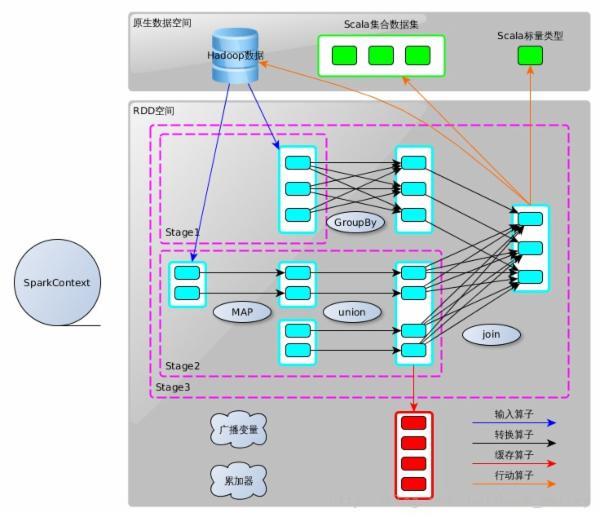
wordcount样例:
1、初始化。构建SparkContext。
val ssc=new SparkContext(args(0),"WordCount",System.getenv("SPARK_HOME"),Seq(System.getenv("SPARK_EXAMPLES_JAR")))
2、输入算子
val lines=ssc.textFlle(args(1))
3、变换算子
val words=lines.flatMap(x=>x.split(" "))
4、缓存算子
words.cache() //缓存
5、变换算子
val wordCounts=words.map(x=>(x,1))
val red=wordCounts.reduceByKey((a,b)=>{a+b})
6、行动算子
red.saveAsTextFile("/root/Desktop/out")
RDD支持两种操作:
转换(transformation)从现有的数据集创建一个新的数据集
动作(actions)在数据集上执行计算后,返回一个值给驱动程序
比如。map就是一种转换,它将数据集每个元素都传递给函数,并返回一个新的分布数据集表示结果。而reduce是一种动作。通过一些函数将全部的元素叠加起来,并将终于结果返回给Driver程序。(只是另一个并行的reduceByKey。能返回一个分布式数据集)
Spark中的全部转换都是惰性的,也就是说,他们并不会直接计算结果。相反的。它们仅仅是记住应用到基础数据集(比如一个文件)上的这些转换动作。仅仅有当发生一个要求返回结果给Driver的动作时,这些转换才会真正执行。这个设计让Spark更加有效率的执行。
比如我们能够实现:通过map创建的一个新数据集,并在reduce中使用,终于仅仅返回reduce的结果给driver,而不是整个大的新数据集。
默认情况下,每个转换过的RDD都会在你在它之上执行一个动作时被又一次计算。
只是。你也能够使用persist(或者cache)方法,持久化一个RDD在内存中。
在这样的情况下,Spark将会在集群中。保存相关元素。下次你查询这个RDD时。它将能更高速訪问。
在磁盘上持久化数据集或在集群间复制数据集也是支持的。
Spark中支持的RDD转换和动作

注意:
有些操作仅仅对键值对可用,比方join。
另外。函数名与Scala及其它函数式语言中的API匹配,比如,map是一对一的映射,而flatMap是将每个输入映射为一个或多个输出(与MapReduce中的map相似)。
除了这些操作以外,用户还能够请求将RDD缓存起来。而且。用户还能够通过Partitioner类获取RDD的分区顺序,然后将另一个RDD依照相同的方式分区。有些操作会自己主动产生一个哈希或范围分区的RDD,像groupByKey,reduceByKey和sort等。
执行和调度
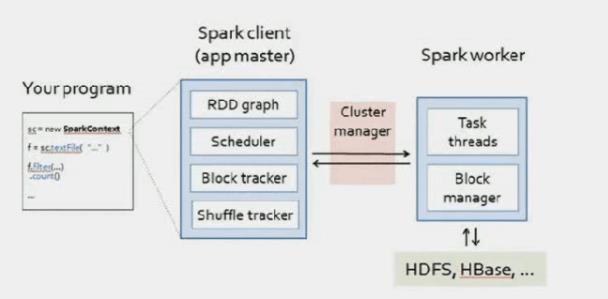
第一阶段记录变换算子序列、增带构建DAG图。
第二阶段由行动算子触发,DAGScheduler把DAG图转化为作业及其任务集。Spark支持本地单节点执行(开发调试实用)或集群执行。对于集群执行,客户端执行于master带点上,通过Cluster manager把划分好分区的任务集发送到集群的worker/slave节点上执行。
配置
Spark生态系统
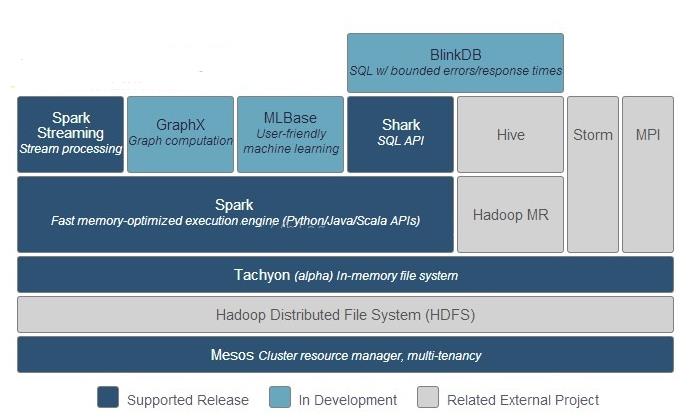
以上是关于JAVAWeb01-BS架构简述HTML的主要内容,如果未能解决你的问题,请参考以下文章