






为了解决公司的项目在集群环境下查找日志不便的问题,我在做过简单调研后,选用Elastic公司的Elastic Stack产品作为我们的日志收集,存储,分析工具。
Elastic Stack是ELK(Elasticsearch,Logstash,Kibana)从5版本开始的新名称,那么的他们都能干什么?参见下图:
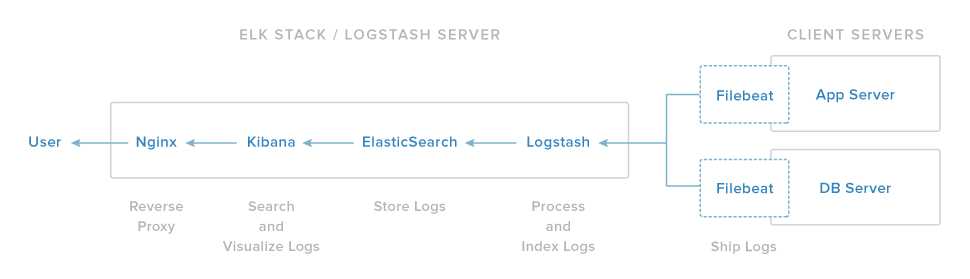
我们使用logstash来收集日志,Elasticsearch存储日志,Kibana用来搜索并展示可视化的页面给用户。
ok,本章重点讲Kibana在linux下的安装,假设你已经安装了Elasticsearch,logstash。
使用cat /etc/centos-release查看系统版本:
CentOS Linux release 7.2.1511 (Core)
使用cat /proc/version 查看系统内核
Linux version 3.10.0-327.el7.x86_64 ([email protected]) (gcc version 4.8.3 20140911 (Red Hat 4.8.3-9) (GCC) ) #1 SMP Thu Nov 19 22:10:57 UTC 2015
由于我的服务器环境无法连接外网,这里采用rpm的方式安装,那么首先我们需要先准备好rpm,从官网下载kibana-6.1.2-x86_64.rpm文件。官网下载页传送门:
https://www.elastic.co/downloads/kibana
下载完成后,使用rpm命令安装
rpm -ivh /elk/kibana-6.1.2-x86_64.rpm
安装完毕,使用systemd来将kibana设置为开机启动
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
如果需要外网访问,将kibaba.yml中的server.host设置为0.0.0.0,接下来我们启动服务
sudo systemctl start kibana.service
使用IP:5601访问kibana,界面如下:
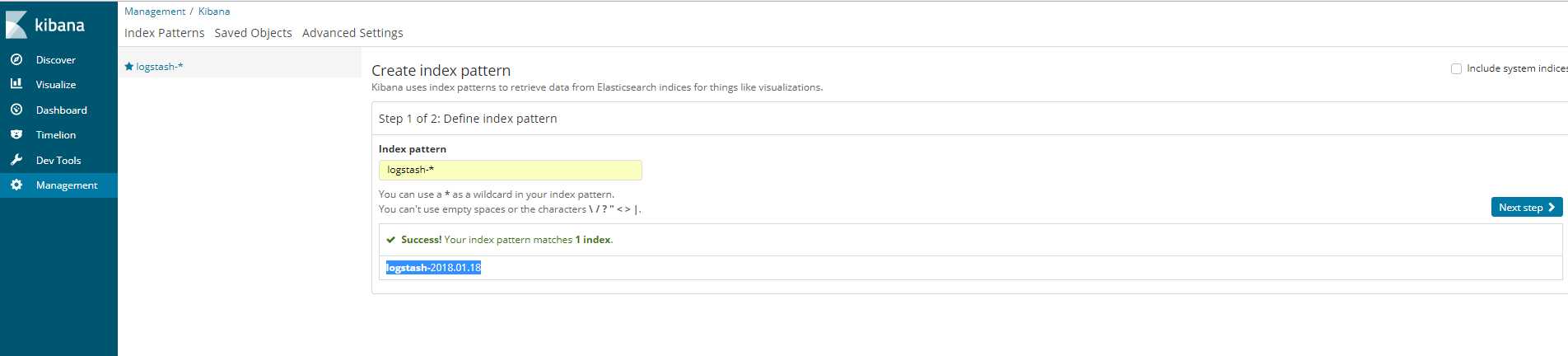
默认打开discover面板。但我们首先需要到management中创建Index Pattern。符合规则的Index Pattern将被用来匹配elasticsearch数据库中的index。例如,我创建了一个logstash-*的Index Pattern,能匹配到logstash-2018.01.18
简单配置后,接下来我们就可以去discover菜单查询数据了。
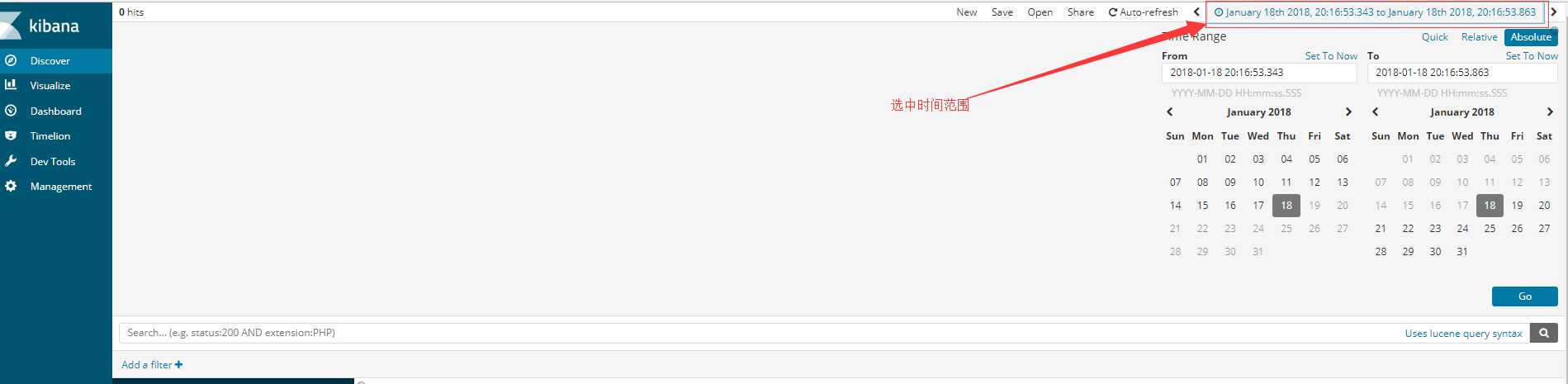
在右上角有时间选项点击可以展开更多选择,默认展示最近15分钟,根据需要选择。
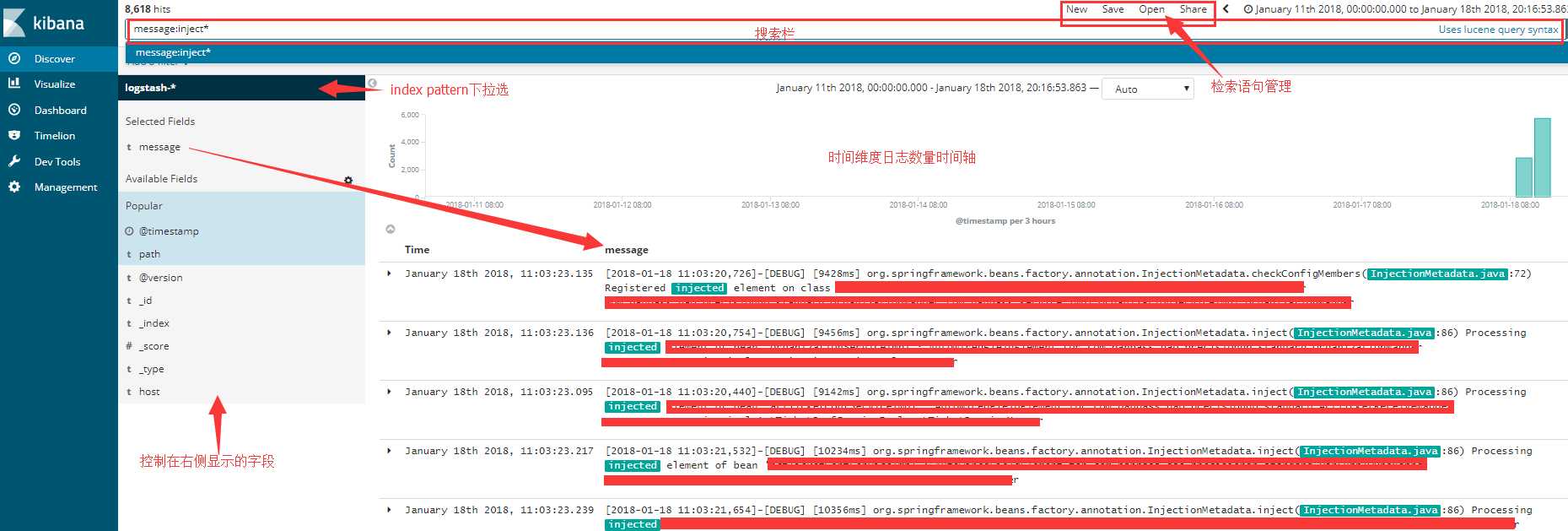
kibana支持Lucene query sysntax,此外Kuery为kibana指定的查询语言。
在搜索栏输入任意字符,Kibana将使用message作为默认字段,将输入字符进行分词检索。注意:如需要使用中文分词,需要使用插件进行相关配置。
指定字段检索:
message:injected
将输入字符使用双引号包起来,则输入字符会作为一个短语搜索:
path:"/logs/xxxx/springframework.log"
如下字符需要使用\\进行转义:
+ - && || ! () {} [] ^" ~ * ? : \\
通配符:
? 匹配单个字符
* 匹配0到多个字符
近似搜索:
"charA charB"~10 表示charA前后10个词内出现charB
范围搜索:
[ ] 表示端点数值包含在范围内,{ } 表示端点数值不包含在范围内
数值类型示例,100到200:length:[100 TO 200]
日期类型示例,6小时之内:date:{"now-6h" TO "now"}
y years
M months
w weeks
d days
h hours
H hours
m minutes
s seconds
相关函数和示例:
and :path:"springframework*" AND @timestamp:["now-1h" TO "now"]
or:path:"springframework*" OR @timestamp:["now-1h" TO "now"]
not:NOT path:"springframework*" 或者 !path:"springframework*"
is: path:"springframework*"
range : @timestamp:["now-1h" TO "now"]
exists: _exists_:path ##必须存在path字段