spark 评估指标
Posted 漠小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark 评估指标相关的知识,希望对你有一定的参考价值。
评估指标
1 Classification model evaluation
1.1 二元分类
1.1.1阈值调整
1.2 Multiclassclassification
1.2.1 Label based metrics
1.3 Muitilabel classification
1.4 Ranking systems
2 Regression model evaluation
Spark mllib 自带了许多机器学习算法,它能够用来进行模型的训练和预测。当使用这些算法来构建模型的时候,我们需要一些指标来评估这些模型的性能,这取决于应用和和其要求的性能。Spark mllib 也提供一套指标用来评估这些机器学习模型。
具体的机器学习算法归入更广泛类型的机器学习应用,例如:分类,回归,聚类等等,每一种类型都很好的建立了性能评估指标。这些指标的具体信息见本节
1 分类模型评估
尽管有许多不同的分类模型,但是分类模型的评估都有相似的原理。在一个监督分类问题中,存在一个真正的输出和模型预测的输出值。由于这个原因,对于每个数据点的结果属于以下四类:
真阳性(TP) - 标签是积极的,预测也为正
真银杏(TN) - 标签为负,预测也为负
假阳性(FP) - 标签是阴性,但预测为正
假阴性(FN) - 标签是积极的,但预测为负
这四个数字是大多数分类评估模型的构建块。当考虑到分类评估是出精度的一个基本点(例如:预测正确或不正确)一般不是一个好的指标。原因就是有可能数据集时高度不平衡的。例如,在男女比例严重不均与的情况下,假如100个人,男生95,女生5人,对于一个人我只要预测他是男生,就能获得极高的准确率。所以在正负样本严重不均匀的情况下,准确率指标失效。由于这个原因,像精确率(TP/(TP+FP))和召回率(TP/(TP+FN)))通常被使用,因为他们考虑到错误的类型。在大多数应用中需要考虑精确率和召回率之间的平衡,她可以有两个组合成单个度量,成为F值。
1.1 二元分类
二元分类用来把给定的数据集分割成两个部分,他是多元分类里面的一个特例。大多数二元分类指标在多元分类中也适合。
1.1.1阈值调整
许多分类模型对每个类实际上输出一个“得分”(很多时候是一个概率),其中分数越高越相似。在二元分类情况下,模型可能对每个类别输出一个概率。P(Y=1|X) P(Y=0|X)。不同于简单地使用较高的概率,在某些情况下,模型需要被调整以便他预测一个类别的时候,属于这个类需要特别高的概率(例如对于二元分类,我们设定的阈值为90%,则>90%则为正,小于<90%都为负),因此,模型的输出的类别取决于模型的阈值。
调整预测阈值将改变准确率和召回率,它是模型优化的重要组成部分,为了直观的观察准确率,召回率或者其他的指标的变化,我们把他的这种变化作为一个阈值函数,通常的做法是绘制出他们之间的相互关系,参数是预测阈值。P-R曲线图(准确率,召回率)是对不同阈值绘制的曲线,ROC曲线绘制的是(召回率,假阳性率)绘制的曲线图。(假阳性率:FP/(FP+TN))
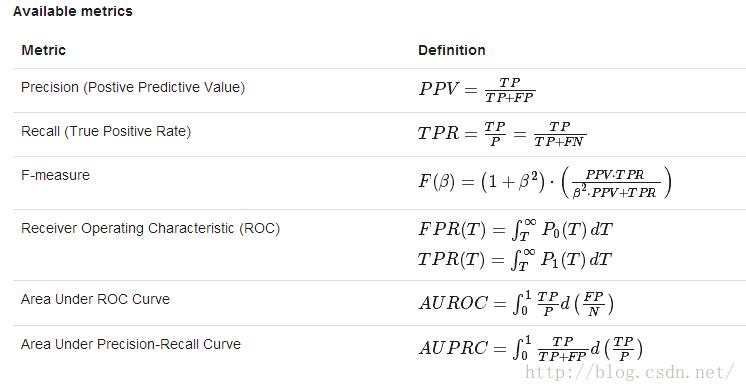
举例:以下程序片段说明了怎么样加载数据集,训练二元分类模型,使用不同的评估指标进行评估。
| importorg.apache.spark.mllib.classification.LogisticRegressionWithLBFGS importorg.apache.spark.mllib.evaluation.BinaryClassificationMetrics importorg.apache.spark.mllib.regression.LabeledPoint importorg.apache.spark.mllib.util.MLUtils
// Load training data in LIBSVM format val data=MLUtils.loadLibSVMFile(sc,"data/mllib/sample_binary_classification_data.txt")
// Split data into training (60%) and test (40%) valArray(training, test)= data.randomSplit(Array(0.6,0.4), seed =11L) training.cache()
// Run training algorithm to build the model val model=newLogisticRegressionWithLBFGS() .setNumClasses(2) .run(training)
// Clear the prediction threshold so the model will return probabilities model.clearThreshold
// Compute raw scores on the test set val predictionAndLabels= test.mapcaseLabeledPoint(label, features)=> val prediction= model.predict(features) (prediction, label)
// Instantiate metrics object val metrics=newBinaryClassificationMetrics(predictionAndLabels)
// Precision by threshold val precision= metrics.precisionByThreshold precision.foreachcase(t, p)=> println(s"Threshold: $t, Precision: $p")
// Recall by threshold val recall= metrics.recallByThreshold recall.foreachcase(t, r)=> println(s"Threshold: $t, Recall: $r")
// Precision-Recall Curve valPRC= metrics.pr
// F-measure val f1Score= metrics.fMeasureByThreshold f1Score.foreachcase(t, f)=> println(s"Threshold: $t, F-score: $f, Beta = 1")
val beta=0.5 val fScore= metrics.fMeasureByThreshold(beta) f1Score.foreachcase(t, f)=> println(s"Threshold: $t, F-score: $f, Beta = 0.5")
// AUPRC val auPRC= metrics.areaUnderPR println("Area under precision-recall curve = "+ auPRC)
// Compute thresholds used in ROC and PR curves val thresholds= precision.map(_._1)
// ROC Curve val roc= metrics.roc
// AUROC val auROC= metrics.areaUnderROC println("Area under ROC = "+ auROC)
|
以上是关于spark 评估指标的主要内容,如果未能解决你的问题,请参考以下文章