数据结构第八站:线性表的变化
Posted 青色_忘川
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构第八站:线性表的变化相关的知识,希望对你有一定的参考价值。
目录
一、线性表
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串... 线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
二、栈和堆
栈和堆这两者,我们其实也已经听过很多次了,但是我们会发现栈和堆我们也产生了一些混淆
我们在C语言中听说过内存会分为栈区堆区静态区等,有函数栈帧,malloc出来的数据都是在堆区上的
而我们在数据结构中,我们所说的栈又变成了一种数据结构,堆其实也是一种数据结构,堆是一颗完全二叉树。
可见我们又被搞混了。
事实上,数据结构中的栈和堆与操作系统中的栈的堆是两种不一样的东西,他们仅仅只是因为不同学科之间而导致的名字一样,但是含义却完全不一样。
总的来说:
在数据结构中:栈和堆是一种数据结构,栈是先进后出,堆是一颗完全二叉树
在操作系统中:栈和堆是内存的划分,栈区用来存放局部变量,函数栈帧等。堆区用来存放malloc、realloc、calloc出来的空间
三、顺序表、链表、栈和队列结构上的区别
而在前面的章节中,我们已经实现了顺序表、链表、栈和队列,但是我们发现,这些结构容易混淆,而且我们特别容易犯一种定势思维,比如说,我们习惯上顺序表是直接定义在栈区的,然后我们对栈区上的顺序表进行初始化就需要传地址了,习惯上单链表是定义在栈区,然后传二级指针,双向链表的初始化又不需要传二级指针了。队列的实现更是需要在构造一个结构体......,可见这些结构特别容易令人混淆。要注意的是,这些数据结构的实现其实并非一种固定的模式,就必须按照这个来实现,只不过这种实现是相对较优的。所以我们习惯上使用它,而我们不能犯定势思维,一定要知道,数据结构是十分灵活的!!!
1.顺序表的变化
顺序表,我们分为静态顺序表和动态顺序表。
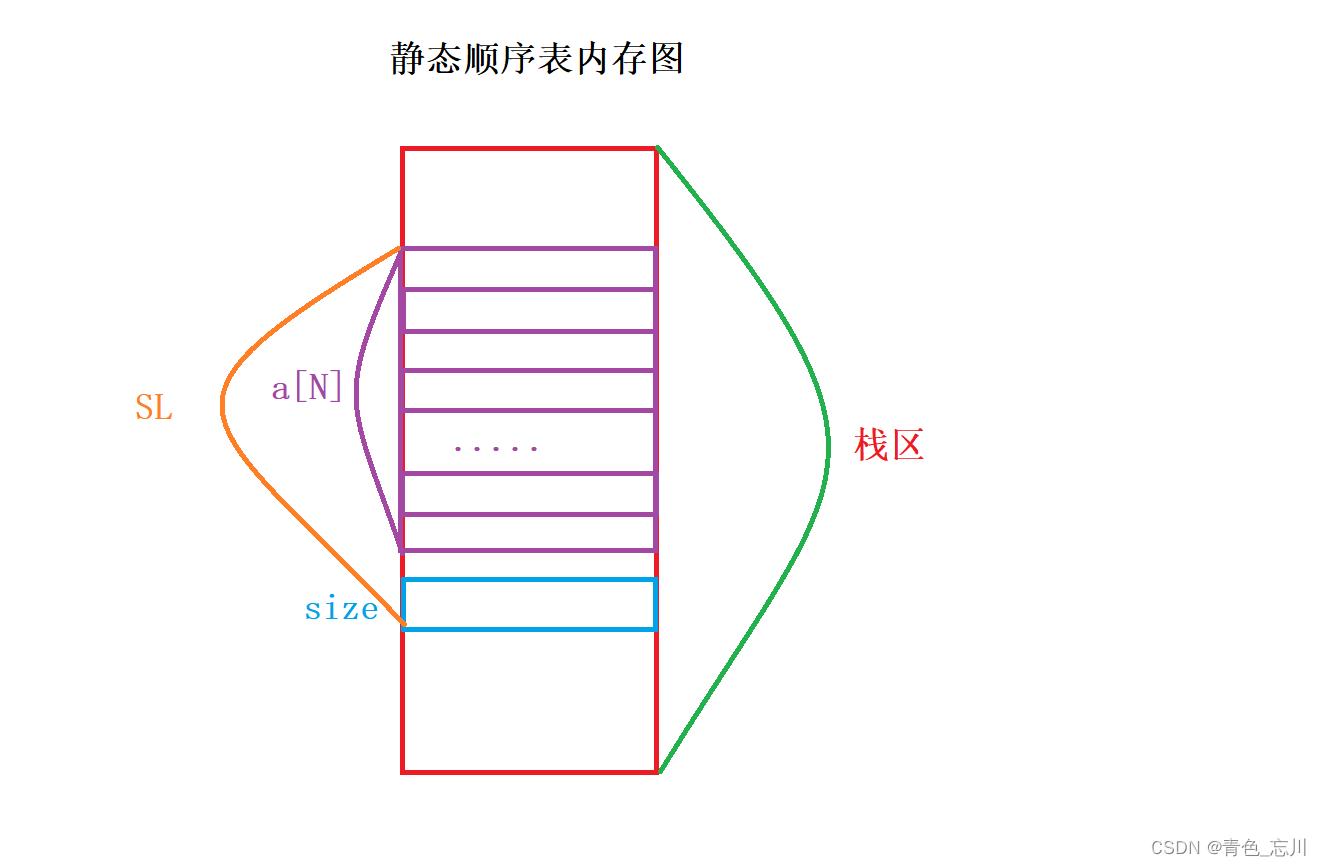
静态顺序表的定义如下
typedef int SLDateType; #define N 10 typedef struct SeqList SLDateType a[N]; int size; SL;对于静态顺序表,我们的结构是这样使用的
1>如果在主函数中直接定义SL seq
也就是说直接定义在栈区上,也就相当于直接在栈区上定义了一个变量名为seq的结构体,这个结构体里面有一个SLDateType类型的,长度为N的数组,还有一个用来记录当前数组有效元素个数size计数器
它的内存图如下所示
上面就是静态顺序表结构上内存图了,而对于静态顺序表我们定义好这个结构体以后,我们想要它的增删查改都封装为一个个函数,那么就需要传这个结构体的地址过去,然后我们才可以进行增删查改等操作。因此静态顺序表函数接口一定是结构体指针。当然对于查找函数,由于我们并不涉及对内存数据修改,所以这个接口我们可以直接将结构体传过去,但是这样的话,会使得函数栈帧中形参的开销过大,而使用指针的话可以大大节省开销。指针只栈四个字节,所以仍然建议传结构体指针,但是若非要传结构体也是没有任何问题的,只是开销比较大
2>如果在主函数中定义的是结构体指针SL* s
如果我们在主函数中定义了一个结构体指针,那么栈区中就只有一个指针变量了。那么结构体的初始化就需要发挥它的作用,它必须得使用堆区的内存了,对于这种情况就有两种办法来进行初始化,要么在堆区开辟好所有的空间并初始化,然后返回这个地址,最后接收这个地址,要么就是通过传这个指针的地址过去,直接为这个原栈区地址进行赋值,这样我们可以不用返回值,但是对应的就需要传二级指针
上图也是静态顺序表的内存图,它是通过只在栈区中定义一个指针来操控堆区的内存的。这种结构不消耗栈区的空间,但是需要使用堆区的空间,在为堆区初始化,有传二级指针和传返回值两种方案,而且还需要注意,这种方法一定要释放空间,否则内存泄漏。而前面在栈区定义的结构体是不需要释放空间的

动态顺序表的定义如下
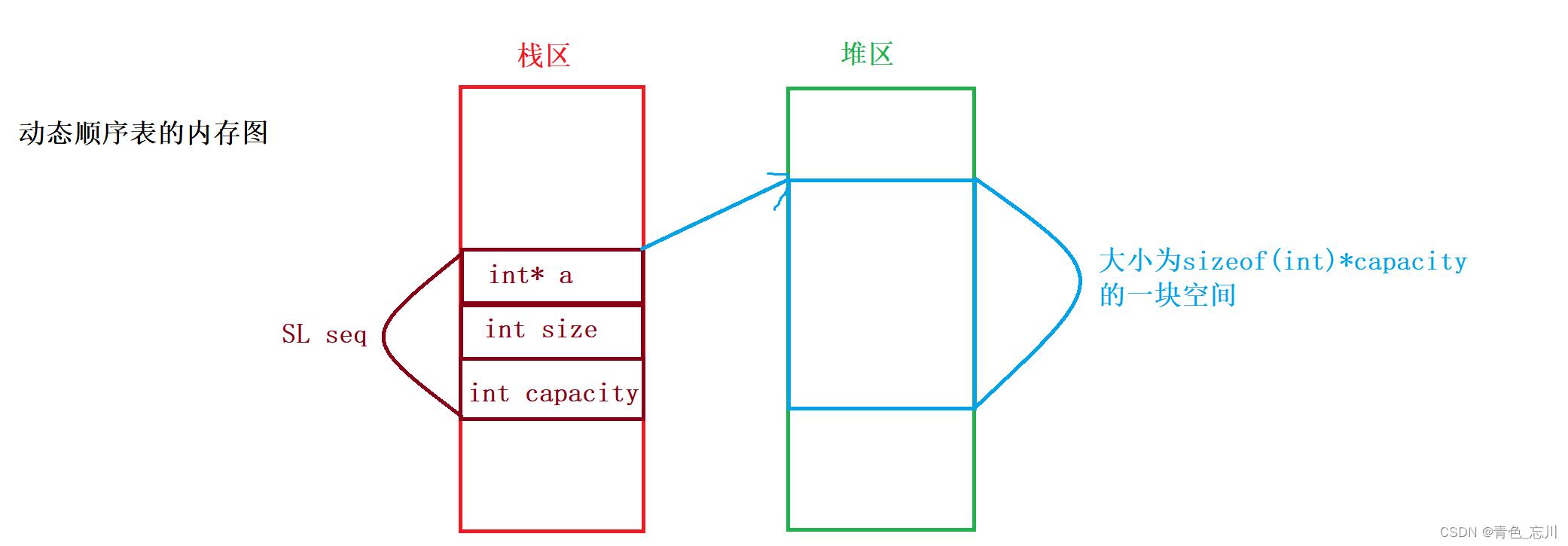
//动态顺序表 typedef int SLDateType; typedef struct SeqList SLDateType* a;//指向数据的指针 int size; int capacity; //容量 SL;对于动态顺序表,我们仍然既可以在主函数中直接定义SL seq,也可以定义结构体指针SL* seq
1>如果直接定义SL seq
那么我们不难得出它的内存图应该如下所示,这样的话,它的每一个函数都需要传入这个结构体的地址过去,也就是说都只需要一级指针即可完成任务
2>如果定义结构体指针SL* seq
对于这种情形,它的内存图仅仅就是将上面栈区的数据搬移到堆区上,然后再栈区定义一个结构体指针,去指向堆区中的数据,然后继续指向存放数据的空间,从而进行增删查改,但是显然,这样的话,会导致很多过程变得十分繁琐。没有这样的必要。
3.总结
可见,顺序表可以分为动态顺序表和静态顺序表,每种顺序表又可以根据它在内存中的分布不同而使得函数的接口有所变化。数据结构的变化是非常之多,我们不能只记住定式,而是需要灵活运用。选择最合适的结构,我们在前面的文章中,我们所选的结构就是动态顺序表,且直接定义结构体的方式去实现的,这样的效率也是相较于其他的实现方式优的
2.链表的变化
我们知道。链表可以分为八种结构,每种结构各具特色,但是我们最常用的两种结构是无头单向不循环链表和带头双向循环链表。
1>无头单向不循环链表
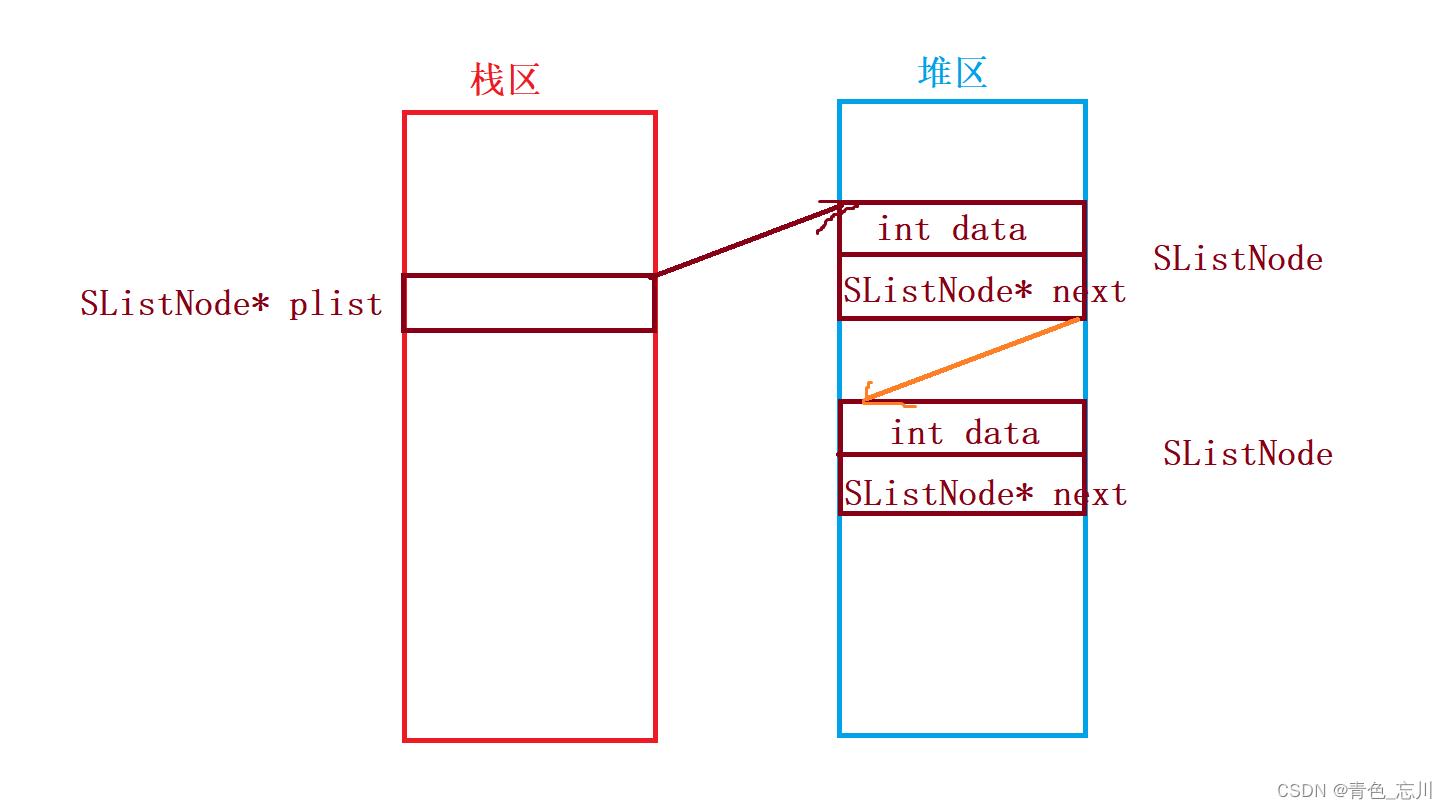
我们对于这种链表的定义是这样的
typedef int SLTDateType; typedef struct SListNode SLTDateType data; struct SListNode* next; SListNode;对于单链表,我们在主函数中可以定义一个指针,也可以直接定义一个节点,但是要注意,如果直接定义成一个节点,那么在栈区的数据,想要在其他的函数栈帧中去使用主函数栈帧中的数据是比较麻烦的。确实,我们可以这样做,但是这样做纯属自找麻烦。因此我们定义一个链表的指针才是最好的方案
对于单链表,由于我们是需要将栈区的数据直接和堆区上的数据链接起来的,所以我们需要传二级指针来解决这个问题,也就是说,它的增删查改都需要使用二级指针了,但是有时候也会使用一级指针来进行操作,如果使用一级指针的话,那么就必须要通过返回头节点的方式来进行处理。
可见单链表的实现也具有十分大的灵活性,而非定式
而且除此之外,为了使得计算链表中每一个节点的个数更加方便,我们可以再次封装一个结构体
这样的变化之后,有一个新的好处就在于,我们可以不需要传二级指针了,我们只需要传SL这个结构体的指针就好了。而且还使得计算节点的方式更快了。
可见链表的变化之多,数据结构是十分灵活的,而非定式

2>带头双向循环链表
对于带头双向循环链表,它的定义是这样的
typedef int LTDateType; typedef struct ListNode struct ListNode* prev; struct ListNode* next; LTDateType data; ListNode;对于这种链表,我们和单链表类似,尽量将数据集中在一个区域内,所以这种链表也需要定义一个指针较优,它的内存分布图与单链表是一样的
而对于这个链表它有一个麻烦之处在于初始化操作,我们可以直接将这个链表的地址传过去,也就是二级指针来进行初始化,也可以使用不传参,通过返回头节点的方式来进行操作。对于其他的操作,由于哨兵位的存在,都可以传一级指针就可以了
它也可以向单链表一样,在使用一个size来与链表指针进行封装成一个新的结构体,这样我们就可以对于任何一个接口传的都是一级指针,实现了大统一。
可见链表的变化是十分灵活的
3.栈的变化
对于栈这种数据结构,我们可以使用链表来完成,也可以使用顺序表来完成。如果使用链表的话,会使得尾删不好处理。时间复杂度较高,所以最优的解法就是通过顺序表来实现,而使用顺序表来实现的话,它的内存分布图就与顺序表一模一样了
typedef int STDateType; typedef struct Stack STDateType* a; int top; int capacity; Stack;因此栈的变化也是十分之多,当然具体使用哪一种方式都是可以的,只不过存在一些效率上的不同。
4.队列的变化
对于队列这种数据结构,我们可以使用链表来完成,也可以使用顺序表来完成。由于队列只涉及头删和尾插,所以相对而言使用链表较优。但是如果非要使用顺序表,也是可以的
对于队列,它的定义如下所示
typedef int QDateType; typedef struct QNode QDateType data; struct QNode* next; QNode; typedef struct Queue QNode* head; QNode* tail; int size; Queue;我们可以看出来,我们是使用了单链表中的一种变化,为了使得尾删方便,计算节点个数效率高,我们使用两个指针和一个size来封装为一个结构体,这样的好处就在于,我们在栈区可以只定义一个队列,然后直接传队列的地址就可以了,不需要使用二级指针。这其实就是单链表变化中最优的一种变化。当然我们也可以直接在主函数中使用队列的地址,这就需要在堆区中为队列申请空间了,其实是自找麻烦。
由此可见,队列也有十分多的变化,我们无需关注它的实现是如何的,我们只需要将接口的功能给实现出来就可以了。切记数据结构不是定式,而是十分灵活的。
5.衍生的变化
上面的变化仅仅只是一些基本的变化,而且由上面的变化,可以进一步生成更多的变化,如两个队列可以完成一个栈,两个栈可以实现一个队列,以及循环队列的变化。这些数据结构的实现都是由前面基本的变化来组成的。
好了本期内容就到这里了
如果对你有帮助的话,不要忘记点赞加收藏哦!!!
打怪升级之小白的大数据之旅(六十七)<Hive旅程第八站:Hive的函数>
打怪升级之小白的大数据之旅(六十七)
Hive旅程第八站:Hive的函数
上次回顾
上一章,我们学习了如何对数据进行拆分–分区表与分桶表,使用分区表与分桶表,可以加快我们的查询效率。。本章节是Hive除了查询之外的另外一个重点,我们的工作中,Hive的操作就是查询和函数组合来做的
Hive的函数
系统内置函数
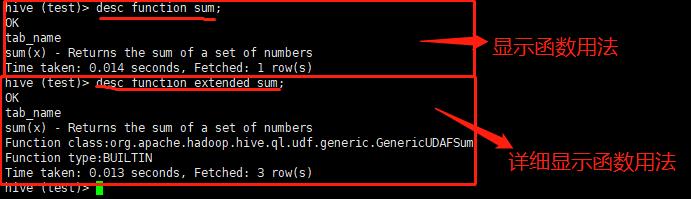
系统内置函数有很多,我们可以使用下面的命令,查看系统自带函数,当我们忘记该函数如何使用,除了度娘和我这个博客外,还可以根据下面的命令进行查看
查看系统自带函数
show functions;
查看自带函数的用法
desc function sum;
详细显示自带函数的用法
desc function extended upper;
常用内置函数
我就介绍几个我经常会使用的几个函数,别的函数,大家有需求可以根据上面命令或者问问度娘
空字段赋值 NVL
当我们需要查询的数据有NULL空字段时,我们可以使用nvl函数为空字段进行赋值
语法格式:
/*
它的功能是如果value为NULL,
则NVL函数返回default_value的值,
否则返回value的值,如果两个参数都为NULL ,则返回NULL
*/
NVL( value,default_value)
下面通过示例来演示一下nvl 的用法
- 我们以前面的员工表为测试数据
如果员工的comm为NULL,则用-1代替
select comm,nvl(comm, -1) from emp;
如果员工的comm为NULL,则用领导id代替
select comm, nvl(comm,mgr) from emp;
CASE 语句
CASE 和 JAVA一样 它用于对一个常量进行条件判断
测试数据结构如下:
| name | dept_id | sex |
|---|---|---|
| 悟空 | A | 男 |
| 八戒 | A | 男 |
| 唐僧 | B | 男 |
| 紫霞 | A | 女 |
| 嫦娥 | B | 女 |
| 观音 | B | 女 |
需求:求出不同部门的男女各多少人
测试数据:
vim /opt/module/hive/dbdata/test/emp_sex.txt
悟空 A 男
八戒 A 男
唐僧 B 男
紫霞 A 女
嫦娥 B 女
观音 B 女
创建表
-- 创建表
create table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\\t";
导入数据
load data local inpath '/opt/module/hive/dbdata/test/emp_sex.txt' into table emp_sex;
使用CASE按照需求查询数据
select
dept_id,
sum(case sex when '男' then 1 else 0 end) man_count,
sum(case sex when '女' then 1 else 0 end) woman_count
from
emp_sex
group by dept_id;

if 函数
和java一样,可以使用case完成的语句,就可以使用if来完成,那么我们直接使用if来完成上面的需求
select
dept_id,
sum(if(sex='男',1,0)) man_count,
sum(if(sex='女',1,0)) woman_count
from emp_sex
group by dept_id;
行转列 CONCAT
行转列就是将一行一行的数据拼接后,生成为一列数据
行转列函数
CONCAT 普通连接
- 返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT(string A/col, string B/col…)
-- 连接 hello world 两个单词
select concat("hello","world");
/*
结果:
helloworld
*/
CONCAT_WS 指定分隔符连接
-
是特殊的CONCAT,它可以指定分隔符
-
第一个参数是剩余参数间的分隔符,分隔符可以是与剩余参数一样的字符串
-
如果分隔符是 NULL,返回值也将为 NULL
-
这个函数会跳过分隔符参数后的任何 NULL 和空字符串
-
分隔符将被加到被连接的字符串之间
-
CONCAT_WS must be “string or array”
CONCAT_WS(separator, str1, str2,...) -- 使用 | 连接 hello world 两个单词 select concat("|", hello","world"); /* 结果: hello|world */
COLLECT_SET 去重连接
- 函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段
- collect_set和collect_list的案例我会在下面演示,简单demo无法实现
COLLECT_LIST 不去重连接
- 函数只接受基本数据类型,它的主要作用是将某字段的值进行不去重汇总,产生array类型字段
行转列案例
数据结构如下:
| name | constellation | blood_type |
|---|---|---|
| 张三 | 白羊座 | A |
| 李四 | 射手座 | A |
| 王五 | 白羊座 | B |
| 赵六 | 白羊座 | A |
| 孙七 | 射手座 | A |
| 周八 | 白羊座 | B |
需求:将星座和血型相同的人归类到一起,最终数据如下
射手座,A 李四|孙七
白羊座,A 张三|赵六
白羊座,B 王五|周八
测试数据
# 创建数据文件
vim /opt/module/hive/dbdata/constellation/constellation.txt
# 数据内容
张三 白羊座 A
李四 射手座 A
王五 白羊座 B
赵六 白羊座 A
孙七 射手座 A
周八 白羊座 B
创建表
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\\t";
加载数据
load data local inpath "/opt/module/hive/dbdata/constellation/constellation.txt" into table person_info;
查询星座和血型相同的人,并归类到一起
SELECT t1.c_b , CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT NAME ,CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b;

列转行 EXPLODE
列转行就是将一列数据转为一行一行的数据,我们通常对列转行操作叫做炸开
列转行函数
Split(str, separator)
- 将字符串按照后面的分隔符切割,转换成字符array
select split("hello,world",",");
/*
输出结果:
["hello","world"]
*/
EXPLODE(col)
- 将hive一列中复杂的array或者map结构拆分成多行
- 大家看清楚了,这里接收的参数是array或者map结构的数据
select explode(split("hello,world",","));
/*
输出结果
hello
world
*/
LATERAL VIEW
- ateral view用于和split, explode等UDTF一起使用
- 它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
- 我们通常称它为侧写表
- lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表,具体演示请看下面的案例
列转行案例
数据结构
| movie | category |
|---|---|
| 《疑犯追踪》 | 悬疑,动作,科幻,剧情 |
| 《Lie to me》 | 悬疑,警匪,动作,心理,剧情 |
| 《战狼2 | 战争,动作,灾难 |
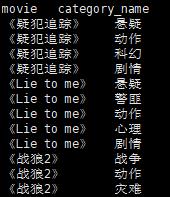
需求:将电影分类进行拆分展示,效果如下
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难```
测试数据:
```sql
# 创建数据文件
vim /opt/module/hive/dbdata/movie/movie.txt
# 数据如下
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
创建表
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\\t";
加载数据
load data local inpath "/opt/module/hive/dbdata/movie/movie.txt" into table movie_info;
使用列转行将电影分类进行拆分
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name;
开窗函数(窗口函数) OVER
开窗函数算是函数中的一个重点,它可以完成使一些复杂的逻辑变得很简单,后面我会通过案例来说明
相关函数
核心的函数:OVER()
- over()函数内部的参数
- CURRENT ROW:当前行
- n PRECEDING:往前n行数据
- n FOLLOWING:往后n行数据
- UNBOUNDED:无边界
- UNBOUNDED PRECEDING 前无边界,表示从前面的起点,
- UNBOUNDED FOLLOWING后无边界,表示到后面的终点
其他函数(over()函数的左边)
- LAG(col,n,default_val):往前第n行数据
- LEAD(col,n, default_val):往后第n行数据
- FIRST_VALUE (col,true/false):当前窗口下的第一个值,第二个参数为true,跳过空值
- LAST_VALUE (col,true/false):当前窗口下的最后一个值,第二个参数为true,跳过空值
- NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型
开窗函数案例
数据结构
| name | orderdate | cost |
|---|---|---|
| 张三 | 2021-01-01 | 10 |
| 李四 | 2021-01-02 | 15 |
| 张三 | 2021-02-03 | 23 |
| 李四 | 2021-01-04 | 29 |
| 张三 | 2021-01-05 | 46 |
| 张三 | 2021-04-06 | 42 |
| 李四 | 2021-01-07 | 50 |
| 张三 | 2021-01-08 | 55 |
| 王五 | 2021-04-08 | 62 |
| 王五 | 2021-04-09 | 68 |
| 赵六 | 2021-05-10 | 12 |
| 王五 | 2021-04-11 | 75 |
| 赵六 | 2021-06-12 | 80 |
| 王五 | 2021-04-13 | 94 |
需求:
- 查询在2021年4月份购买过商品的顾客及总人数
- 查询顾客的购买明细及月购买总额
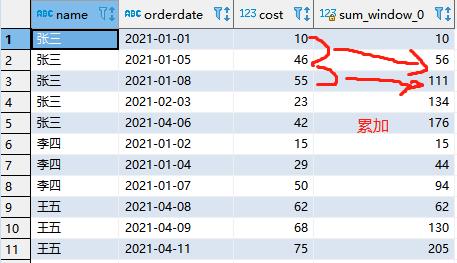
- 上述的场景, 将每个顾客的cost按照日期进行累加
- 查询顾客购买明细以及上次的购买时间和下次购买时间
- 查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
- 查询前20%时间的订单信息
测试数据:
# 创建数据文件
vim /opt/module/hive/dbdata/order/business.txt
# 数据如下
张三 2021-01-01 10
李四 2021-01-02 15
张三 2021-02-03 23
李四 2021-01-04 29
张三 2021-01-05 46
张三 2021-04-06 42
李四 2021-01-07 50
张三 2021-01-08 55
王五 2021-04-08 62
王五 2021-04-09 68
赵六 2021-05-10 12
王五 2021-04-11 75
赵六 2021-06-12 80
王五 2021-04-13 94
创建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t';
加载数据
load data local inpath "/opt/module/hive/dbdata/order/business.txt" into table business;
查询在2021年4月份购买过商品的顾客及总人数
select
name,
count(*) over()
from business
where month(orderdate)=4
group by name ;
查询顾客的购买明细及月购买总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) name_month_cost
from business;
将每个顾客的cost按照日期进行累加
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate )
from business;
查询顾客购买明细以及上次的购买时间和下次购买时间
select
name,orderdate,cost,
lag(orderdate,1,'1970-01-01') over(PARTITION by name order by orderdate) prev_time,
lead(orderdate,1,'1970-01-01') over(PARTITION by name order by orderdate) next_time
from business;
查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
select
name,
orderdate,
cost,
FIRST_VALUE(orderdate) over(partition by name,month(orderdate) order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) first_time,
LAST_VALUE(orderdate) over(partition by name,month(orderdate) order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) last_time
from business;
查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
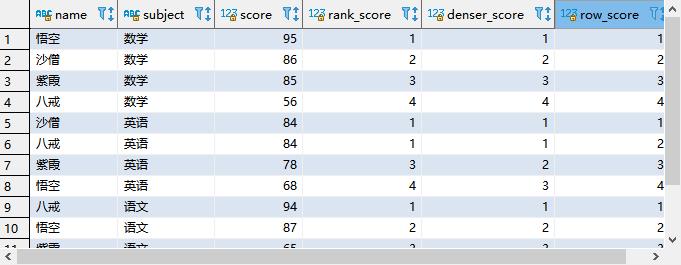
排序 Rank
Rank排序与order by 最大的不同就在于它只能配合over()开窗函数使用
函数说明
rank()
- 排序相同时会重复(考虑并列,会跳号),总数不会变
- rank就相当于我们学校考试时,有两个第一名(分数相同),那么下一个排名就是第三名,没有第二名
dense_rank()
- 排序相同时会重复(考虑并列,不跳号),总数会减少
- 同样以上述举例,分数相同,依旧有两个第一名,但是下一个学生为第二名
ow_number()
- 会根据顺序计算(不考虑并列,不跳号,行号)
- 没有并列第一这一说,可能会根据某个条件,将分数相同的人排为第一、第二名
为了更形象地说明这几个排序,我就按照学校考试成绩来举例
数据结构
| name | subject | score |
|---|---|---|
| 悟空 | 语文 | 87 |
| 悟空 | 数学 | 95 |
| 悟空 | 英语 | 68 |
| 八戒 | 语文 | 94 |
| 八戒 | 数学 | 56 |
| 八戒 | 英语 | 84 |
| 沙僧 | 语文 | 64 |
| 沙僧 | 数学 | 86 |
| 沙僧 | 英语 | 84 |
| 紫霞 | 语文 | 65 |
| 紫霞 | 数学 | 85 |
| 紫霞 | 英语 | 78 |
需求:根据每门学科进行成绩排名
测试数据
# 创建测试数据文件
vim /opt/module/hive/dbdata/score/score.txt
# 数据如下
悟空 语文 87
悟空 数学 95
悟空 英语 68
八戒 语文 94
八戒 数学 56
八戒 英语 84
沙僧 语文 64
沙僧 数学 86
沙僧 英语 84
紫霞 语文 65
紫霞 数学 85
紫霞 英语 78
创建表
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\\t";
加载数据
load data local inpath "/opt/module/hive/dbdata/score/score.txt" into table score;
使用三种排序方式将每科的考试的成绩进行排名
from score;
select name,
subject,
score,
rank() over(partition by subject order by score desc) rank_score,
dense_rank() over(partition by subject order by score desc) denser_score,
row_number() over(partition by subject order by score desc) row_score
from score;
自定义函数
函数分类
- 看到这里,常用的函数就介绍完毕了,当HQL中内置的函数不能满足我们的需求,Hive还为我们提供了自定义函数的方法,学习如何自定义函数前,我们先总结一下函数的分类
- 函数分为三大类
- UDF:一进一出,UDF就类似我们的upper、substr函数
- UDAF:多进一出,UDAF就是我们通常说的聚合函数,例如sum avg
- UDTF:一进多出,UDTF就类似我们前面说的炸开函数,它可以将一行数据炸开为多列
自定义UDF函数
- 我就按照最简单的UDF自定义举例
- 其他自定义函数具体的实现方法可以参考官网的说明文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
编程步骤
- 继承Hive提供的自定义函数类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; - 实现类中抽象方法
- 将创建好的类打包到服务器的hive lib文件夹下
- 在hive命令行窗口创建函数
-- 添加jar包
add jar linux_jar_path
-- 创建函数
create [temporary] function [dbname.]function_name AS class_name;
-- 在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
自定义UDF案例
既然需要添加jar包才可以实现自定义函数,那么必然要进行java编码,我定义一个简单的UDF需求:计算给定字符串的长度
select my_len("hello")
-- 结果:5
创建Maven工程
- 这个就不再演示了,前面写了太多了
导入依赖
// 在pom.xml文件中添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
创建并继承自定义函数类,并实现计算方法
package com.company.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 自定义UDF函数,需要继承GenericUDF类
* 需求: 计算指定字符串的长度
*/
public class MyLength extends GenericUDF {
/**
* 初始化方法,里面要做三件事
* 1.约束函数传入参数的个数
* 2.约束函数传入参数的类型
* 3.约束函数返回值的类型
* @param arguments 函数传入参数的类型
* @return
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//1.约束函数传入参数的个数
if (arguments.length != 1) {
throw new UDFArgumentLengthException("Input Args Num Error,You can only input one arg...");
}
//2.约束函数传入参数的类型
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(0,"Input Args Type Error,You can only input PRIMITIVE Type...");
}
//3.约束函数返回值的类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数逻辑处理方法
* @param arguments 函数传入参数的值
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
//获取函数传入参数的值
Object o = arguments[0].get();
//将object转换成字符串
int length = o.toString().length();
//因为在上面的初始化方法里面已经对函数返回值类型做了约束,必须返回一个int类型
//所以我们要在这个地方直接返回length
return length;
}
/**
* 返回显示字符串方法,这个方法不用管,直接返回一个空字符串
* @param children
* @return
*/
@Override
public String getDisplayString(String[] children) {
return "";
}
}
打包jar并上传到hive的Lib文件夹下(利用xftp/rz等工具上传),并改一个名字
mv
/opt/module/hive/lib/code-1.0-SNAPSHOT.jar /opt/module/hive/lib/my_len.jar
添加jar包t添加到hive中
add jar /opt/module/hive/lib/my_len.jar;
创建临时函数与开发好的java class关联
create temporary function my_len as "com.company.MyLength";
使用自定义的函数查看效果
select my_len("hello");
-- 输出:5
删除临时函数
drop temporary function my_len;
注意:
- 临时函数只是针对当前的hive命令行窗口有用,关闭、退出当前hive界面就失效了
- 下面为大家介绍如何创建永久函数
创建永久函数
- 在$HIVE_HOME下面创建mylib目录,(为了便于管理,就不放在lib下了)
- 将jar包上传到$HIVE_HOME/mylib下,然后重启hive
- 创建永久函数
create function my_len2 as "com.company.MyLength";
使用自定义的函数查看效果
select my_len2("hello");
-- 输出:5
- 即可在hql中使用自定义的永久函数
drop function my_len2;
注意:
- 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
- 永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上 库名.函数名
总结
本章节介绍了一下Hive中的函数以及一些常用的函数,当我们有特殊需求时,可以使用自定义函数来满足我们的业务逻辑,好了,整个Hive的相关使用就到这里,后面几章我为大家介绍一下Hive的优化以及一个综合案例
以上是关于数据结构第八站:线性表的变化的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(六十七)<Hive旅程第八站:Hive的函数>
打怪升级之小白的大数据之旅(六十七)<Hive旅程第八站:Hive的函数>